SQLアンチパターン感想その一ーカテゴリーとサブカテゴリーとサブサブカテゴリーと...
最近 こちら の本を読み終わって、ほぼ全部自分が経験していると、非常に共鳴できました。
アンチパターンというのは、ある問題を解決するためにまた別の問題を生み出す傾向があるので、おすすめしない・良い実践(good practice)ではないという意味合いがあります。その代わりにどういうもやり方があるのか、どんなメリットとデメリットがあるのかを説明してくれています。
問題が解決できれば良い、がすべてではなく、良い実践を求めるエンジニアにとってはかなりおすすめできる内容ではないかと思います。よくない設計は技術的負債(technical debt)になってしまい、いずれ「報い」が来るに違いないでしょう。
この本でいくつか自分が特に気になっていた内容についてまとめました。冗長になるのでやはり内容別で分けようと思って、今回はカテゴリー、コメントといったテーブルの設計についての内容です。
カテゴリーとサブカテゴリーはどういう関係なの
これの問題について少し経験のあるエンジニアにはすぐに、サブカテゴリーもカテゴリーと同じテーブルですよ、と答えるかもしれません。これは、仮に無限階層のサブカテゴリーがあっても、親となるカテゴリレコードのidを外部キーとしてつけておけば、サブカテゴリー1、サブカテゴリー2とかのテーブルを作る必要がないと。
CREATE TABLE categories (
cate_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
parent_id BIGINT UNSIGNED,
name VARCHAR(255) NOT NULL,
FOREIGN KEY (cate_id) REFERENCES categories (cate_id) ON DELETE SET NULL ON UPDATE CASCADE
);
実際のプロジェクトに、カテゴリーのテーブル+サブカテゴリーのテーブルを別々で作ることを見かけたことがあります。それで笑ってしまい、同じテーブルで良いじゃん、と自分がかしこいと自慢したことも。
が、そうでもありません。
カテコリーのテーブルに親かとなるレコードIDをつけて、つまり参照先が同じテーブルのやり方は、隣接テーブル(adjacent table)だというらしい。本の中でコメントシステムを例で挙げていましたが、そちらも個人のプロジェクトで実装したことがあります(全く隣接テーブルのやり方)。
それですぐに問題になるのは、とあるカテゴリー・コメントのすべての子カテゴリーを取得したい、もしくは数だけでも取得したい、という時に、少し困ることになります。
ここで再帰が必要となり、SQLレベルでサポートができれば一回で取得できますが、なければバックエンドの言語で再帰でSQLを連発する必要があります(本の出版当時にMySQLはまだサポートできていませんが、今は問題なく再帰クエリーが可能です)。
WITHクローズで再帰のSQLを書く
MySQLで例を出すと( 参照先 、再帰クエリーを作ればこの問題を解決できます。
WITH cate_tree (cate_id, parent_id, name, depth)
AS (
SELECT *, 0 AS depth FROM categories WHERE parent_id IS NULL
UNION ALL
SELECT c.*, ct.depth + 1 AS depth FROM cate_tree ct
JOIN categories c ON ct.cate_id = c.parent_id
)
SELECT * FROM cate_tree WHERE cate_id = 1;
要するに、cate_treeという一時的なテーブルを作り、そこから特定のカテゴリーのすべての子孫レコードを取得すると。depthで階層の深さを表示し、parent_idがNULLからは0、それ以降のparent_idイコールcate_treeのIDの場合はプラス1に。なので事実上この一時的なテーブルは、既存のcategoriesテーブルをツリー構造を考慮して再構築したものとなります。
限界と問題
隣接テーブルのやり方で、新規のレコードの追加が簡単です。また、子孫レコードを全部取得するときは再帰クエリーでなんとかいけそうな気がしました。もし既存のデータの削除があまりない、新規コードの追加と、特定のレコードの直接な親レコードを取得がメイン、というケースに、この設計を利用しても十分かと考えられます。
ただ、もし削除したいときに、かなり面倒になります。カテゴリーは割と固定となるかもしれませんが、コメントシステムだと削除がより頻繁な操作になります。実際に自分がコメントシステムを作った時に、ソフトデリートを前提に、deleted_atカラムを利用して、削除の操作を更新操作に変えてズルしていました。物理削除しようとするとき外部キー制約があるので、参照している子孫レコードが存在すると、ON DELETE SET NULLにして、一旦NULLに戻して削除後また子孫レコードのparent_idを更新しなければなりません。
それこの本からいくつか別の解決策が提案されました。
パス列挙(path enumeration)
これはファイルシステムのファイルパスとたとえて、一番上の親からの「パス」を保存するカラムを追加するやり方です。コメントシステムで例を挙げると、データは以下のように見えます。
| comment_id | path | user_id | content |
|---|---|---|---|
| 1 | 1/ | 101 | hello world |
| 2 | 1/2/ | 103 | hi |
| 3 | 1/3/ | 105 | good post |
| 4 | 1/2/4/ | 102 | LOL |
| 5 | 1/2/4/5/ | 103 | whats so funny? |
つまり、pathカラムで、一番上の祖先レコードのidから自分までのidを文字列として保存することです。
これで、LIKE検索でとあるレコードのすべての子孫レコードの取得が簡単になります。
SELECT * FROM comments AS c WHERE c.path LIKE '1/%';
逆のパターン、あるレコードのすべての祖先レコードの取得も:
SELECT * FROM comments AS c WHERE '1/2/4/5/' LIKE c.path || '%';
簡単にすべての子孫または祖先レコードが取得できるので、数の集計も簡単になります。例えばとあるコメント(2)に対するコメントの数をユーザー別で取得する:
SELECT COUNT(*) FROM comments AS c WHERE c.path LIKE '1/2/%' GROUP BY c.user_id;
もちろん、新しいレコードの挿入も、隣接テーブルと同じく簡単にできます。親となるレコードのpathをコピーして新規のレコードのidをアペンドしておけば良いです。また、削除操作も、すべての子孫レコードのpathを更新するのは、隣接テーブルより簡単になります。
このやり方は、隣接テーブルの「すべての祖先・子孫レコードへの操作」の弱点を克服できていますが、割と欠点もわかりやすいです。
-
pathはDB側ではなく、バックエンドとかのプログラムでメンテナンスしないといけません。仮にSQLでどれかを削除したとしても、制約がないので何の問題も発生しないですが、実際のデータのツリーはすでに破壊されています。 -
pathは文字列なので、長さの上限があります。そのため理論的に無限階層のtree構造を満たすことができません。 -
LIKEクローズに依存するので、インデックスをつけても、外部キーのような整数インデックスと比べて文字列の方はコストが高い
Nested Set
簡単に言えばバイナリーツリー(二分木)を作る考え方です。すべてのレコードに左と右のノードの番号(主キーと関係ない)を保存して、関連のあるレコードをすべてバイナリーツリーのノードとして管理する形です。
CREATE TABLE comments (
comment_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT UNSIGNED NOT NULL,
content VARCHAR(1000) NOT NULL,
nsleft INT UNSIGNED NOT NULL,
nrleft INT UNSIGNED NOT NULL
FOREIGN KEY (user_id) REFERENCES users (user_id) ON DELETE CASCADE ON UPDATE CASCADE
);
左と右のノードの番号は実際のレコードと関係ないですが、nsleftとnsrightが深さ優先探索(depth-first traversal)の順番で番号を振るので、任意のノードに対して、自分のnsleftとnsright番号の間に存在するノードは全部子孫レコードになります。
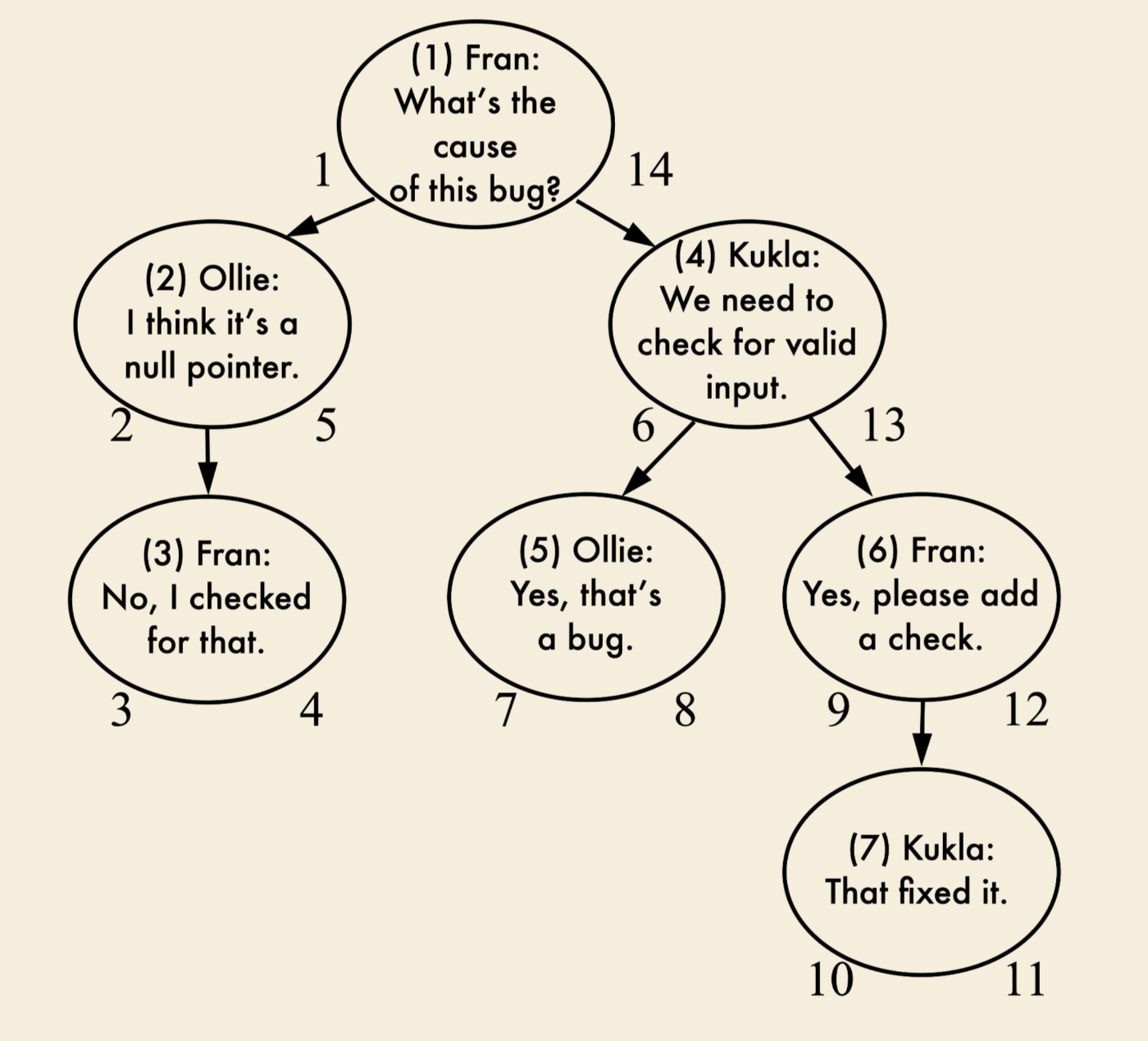
例えば本の例(P45-46)で見ると、コメントID=4のレコードのnsleftが6、nsrightが13、その子孫を取得するには:
SELECT c2.* FROM comments AS c1
JOIN comments as c2
ON c2.nsleft BETWEEN c1.nsleft AND c1.nsright
WHERE c1.comment_id = 4;
すべての祖先の取得する場合、c1とc2を入れ替えて連結すれば良い:
SELECT c2.* FROM comments AS c1
JOIN comments AS c2
ON c1.nsleft BETWEEN c2.nsleft AND c2.nsright
WHERE c1.comment_id = 4;
この方法の一番大きなメリットというのは、バイナリーツリーの構造にすることで、削除操作が非常に簡単になります。どのノードを削除しても、そのノードの子孫レコードの更新操作が不要です。
ただ、隣接テーブルとパスカラムの方法と比べて、直接の親レコードを探すのが少し複雑になります。考え方として、とあるノードに対して、すべての祖先を探して、ターゲットノードとの間に他のノードがなければ、直接の親だと判断できます。
SELECT parent.* FROM comments AS c
JOIN comments AS parent
ON c.nsleft BETWEEN parent.nsleft AND parent.nsright
LEFT JOIN comments AS in_between
ON c.nsleft BETWEEN in_between.nsleft AND in_between.nsright
AND in_between.nsleft BETWEEN parent.nsleft AND parent.nsright
WHERE c.comment_id = 4
AND in_between.comment_id IS NULL;
parentとは、探しているコメントID=4のすべての祖先のテーブルとなります。in_betweenというのは、実質一番上のノードとターゲットを除いた、もう一つのparentテーブルとなります。in_betweenでcomment_idがNULLということは、parentとターゲットの間に何もない=直接の親だということです。
また、新しいレコードの挿入もだいぶ複雑になります。隣接するノードの番号の再計算、リーフノード(子孫がないノード)でない場合に子孫ノードの再計算が必要になります。なので、頻繁に更新、削除の操作がある場合、このやり方はあまりおすすめできないと考えられます。
以前ECサイトを作る際に、DBでは隣接テーブルですが、プログラム側で管理する時はこちらの方法(パッケージ)でした。もちろんツリー構造への理解が必須なので当時は難しいなと思いました。今この本の内容だけ見ても、他の方法と比べて優先順位が下がるのではないか、が率直な感想でした。
クロージャーテーブル(closure table)
最終武器として登場。要するにもう一つのテーブルを作り、祖先と子孫の関係をすべて記録することです。
CREATE TABLE tree_paths (
ancestor BIGINT UNSIGNED NOT NULL,
descendant BIGINT UNSIGNED NOT NULL,
PRIMARY KEY (ancestor, descendant),
FOREIGN KEY (ancestor) REFERENCES comments(comment_id),
FOREIGN KEY (descendant) REFERENCES comments(comment_id)
);
つまり、ツリーの構造は元のcommentsテーブルで管理するのではなく、別途tree_pathsに任せて、外部キー制約を用いて整合性も保証することです。
直接の親子関係だけではなく、すべての祖先と子孫の関係を記録するため、データはこのように見えます:
| ancestor | descendant |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 1 | 4 |
| 1 | 5 |
| 2 | 2 |
| 2 | 3 |
| 2 | 4 |
| 2 | 5 |
| 3 | 3 |
| 3 | 4 |
| 3 | 5 |
| 4 | 4 |
| 4 | 5 |
| 5 | 5 |
これで何ができるかというと、ほとんどのCRUD操作が非常に簡単になるところです。
ターゲットのすべての祖先を取得するときに:
SELECT c.* FROM comments AS c
JOIN tree_paths AS t ON c.comment_id = t.ancestor
WHERE t.descendant = 4;
すべての子孫を取得するときに:
SELECT c.* FROM comments AS c
JOIN tree_paths AS t ON c.comment_id = t.descendant
WHERE t.ancestor = 4;
新規挿入するときは、まずコメントテーブルで挿入し、comment_idを取得でき、そのcomment_idをもってtree_pathsに必要な内容を挿入する。仮にID=5のコメントに対して新規挿入すると、必要なものといえば、今の新規コメントIDまでのすべての祖先(仮に新規ID=8、ターゲットまでIDが連続する場合は1 8, 2 8, 3 8, 4 8, 5 8)+新規コメントID自分自身(8 8)となります。
SET @new = 8;
SET @target = 5;
INSERT INTO tree_paths (ancestor, descendant)
SELECT t.ancestor, @new FROM tree_paths AS t
WHERE t.descendant = @target
UNION ALL
SELECT @new, @new;
一つ削除する場合は、WHERE descendant = @targetで十分。サブツリーごとに削除する場合は、祖先がターゲットのものを含めれば良い(WHERE descendant IN (...WHERE ancestor = @target))。
なお、path_lengthというフィールドを追加し、パスの長さを記録しておけば、直接の子レコードの取得が非常にシンプルになります(WHERE ancestor = @target AND path_length = 1)。
どれを使うべきか
| 設計 | テーブル数 | 子 | 親 | 子孫 | 先祖 | 挿入 | 削除 | 整合性 |
|---|---|---|---|---|---|---|---|---|
| 隣接テーブル | 1 | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ | ✅ |
| 隣接テーブル+再帰クエリー | 1 | ✅ | ✅ | ⚠️ | ⚠️ | ✅ | ✅ | ✅ |
| パス列挙 | 1 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| 二分木 | 1 | ⚠️ | ⚠️ | ✅ | ✅ | ⚠️ | ✅ | ❌ |
| クロージャーテーブル | 2 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
- 隣接テーブルが最もシンプルな解決策となり、再帰クエリーを導入することで多くの場面をカバーできるでしょう。
- パス列挙はプログラマーが整合性を保証しないといけない=必ず問題が発生しやすいという致命傷があります。
- 二分木は賢い解決策で、子孫と先祖のクエリーに特化していますが、他の操作とツリーのメンテナンスが複雑すぎて応用ケースが狭まっています。
- クロージャーテーブルは一番オールマイティな解決策。唯一な「欠点」というか、容量を増やすことで計算時間の短縮を引き換えるというトレードオフがあります(ただ空間と時間のトレードオフはCSの世界で溢れていますし、欠点とは個人的に思っていません)。
結論として、次のプロジェクトはクロージャーテーブルでやります(笑)。
Discussion