RDBMSの基礎を学ぶーインデックス編
エンジニア何年もやって、ちゃんとDB学んでいなかった悔しさがずっとあったので、この間は色々とコースなり、本なりを探って勉強した。
DBMSは非常に大きなトピックで自分もまだまだほんの少ししか触れていなかったが、この記事では、とりあえずはインデックスからスタートしてようと思う。
(結構長くなってしまったので、TL;DRとして節ごとにまとめを置いています)
DBMSのアーキテクチャー概要
データベースによって実装が異なるが、一般的に含まれるDBMSの構成コンポーネントとして、次のように挙げられる[1]。

DBMSはサーバークライエントのモデルを使っている。クライエントはクエリーを構成してトランスポートのレイヤーを経てサーバー側に送られる。クエリーに対してサーバー側が解析や最適化して、適切な実行プランを出す。実行プランは実行エンジンに渡されて、ローカルとリモートの実行結果を集計する。リモートというと、例えばクラスタリングされている複数のDBノードがあるケースで、他のノードにデータを取得したりすることが考えられる。ローカル実行の場合は、ストーレジエンジンに任されて、ディスク上に保存されているデータを実際に読み書きする。ストレージエンジンには、トランザクションやロック、バッファー管理など各種の責務を果たしてくれている。
このような鳥瞰図をまず念頭におくと、どのステージの話になるかはより理解しやすいかもしれない。この記事では、まずはストーレジのレイヤーで、データ保存の仕方(access methods)から入り、なぜインデックスが必要なのかを説明する(what&why)。それで、クエリーがきちんとインデックスをうまく利用するために最適化できるように具体例や注意点などをまとめる(how)。
DBではデータがどう保存されているか
ディスクストレージの最小単位
大前提として、データが保存する媒介によって、メモリーに保存するもの(Redis, Memcacheなど)とディスクに保存する(RDBとNoSQLのDBも色々含め)ものに大きく分けることができる。もちろん、メモリーに保存するとはいえ、データの持続化が不可欠で、最終的にディスクにファイルとして保存されると思われる。ここでは主に、ディスクに保存するケースをコンテキストにする。
昔はHDDがメインに使われているが、近年SSDの普及によってHDDの利用が少なくなっている。いずれにしても、データを保存と読み取りする際に、最小単位が存在し、その最小単位がいわゆるI/Oコストの物理的な単位にもなる。例えば、HDDの場合は通常512byteから4Kbサイズのセクターを最小単位にしている。SSDの場合は、構造自体がmemory cells -> strings -> arrays -> pages -> blocks -> planes -> dies との順で構成されており、書き読みする際の最小単位が2-16Kbのpageとなっている。
この最小単位は何を意味しているかというと、OS的にデータを書き込みする際に、常にこの単位の倍数のデータを書き込みするので、データベースのストレージ設計もこの単位を考慮しなければならない。
データファイルの最小単位
では、DBMSでどういうふうにディスクストレージの最小単位を考慮できるのだろうか。
DBMSでは、データをデータファイルに保存している。1つのテーブル=1つのファイルとなり、ファイルはさらに固定サイズのページに細分化されている。ページのサイズはDBやOSによって多少違うが、通常4-16Kbくらいになる。例えば、postgresqlでは8KB 、MySQLでは16KBのデフォルトのページサイズがある。
このページと後ほど紹介するB木のノードと関連していて、通常1ページ/ブロック=1ノード(一回のIOで取るデータの量と一致する意図がある)となり、DBが読み書きするときにページごとに読み書きするようになっている。これは先ほど紹介したディスク上保存する仕組みが根本的にあって、要はバイト単位での読み書きができないからだ。
ここで一つややこしいのは、「ブロック」と「ページ」との言葉はいろんなところで出回るが、その違いがあまり言及されていない。こちらの記事内容 の記述によると、
ストレージ上のリレーションのデータ切片が「ブロック」で、メモリ上のデータ切片が「ページ」「バッファ」と呼び分けるが、8 KiB は同一のデータ構造を持っているのでブロックとページ(バッファ)は論理的に同一である。
つまり、DBMSの文脈において、ブロックとページという言葉は同一との認識で良いかと思われる。これはSSDの構成要素のページ、ブロックとは軸が若干違うので、そこの一致性が生まれつきにないことは注意したい。とはいえ、ストレージディスクの最小単位と、DBのペースの最小単位と一致させることには、MySQLの 公式ドキュメント にも記載されているように、無駄な書き操作を最小限にできるという最適化観点からのメリットが存在する。
Consider using a page size that matches the internal sector size of the disk. ...
Keeping the page size close to the storage device block size minimizes the amount of unchanged data that is rewritten to disk.
データファイルの中身
データファイルは、中身のデータの構造次第で3つの種類に分けられる。
- index-organized tables (IOT) -> いわゆるクラスターインデックス(詳細は次節)
- heap-organized tables -> いわゆるヒープテーブルまたはヒープファイル
- hash-organized tables -> ハッシュファイル
ヒープファイルはより広く使われていて、中のデータは特定の順番にソートされることはなく、基本書き込み時の順番になっている。新しいデータが追加された時に、シンプルに最後のページに挿入するか、空きがない場合は新しいページをアペンドするだけで良い。この性質のゆえに、直接ヒープテーブルのデータを検索することが難しく、データを特定の基準で並び替えるindexが必要になってくる。
それに対して、IOTの方は、データを特定の順番にソートされることを前提に実装されていて、書き込みの時もその構造と順番を守る必要がある。つまり、IOTの場合は、ヒープファイルのように、インデックスからデータファイルへのアクセス(データファイルとインデックスファイルの分離)がなく、データファイルそのものがインデックスであり、インデックスそのものがデータファイルでもある。
ハッシュファイルの場合は、ハッシュテーブルのデータ構造に同じ考え方で、保存するデータの値に対してハッシュ関数をかけて、ターゲットとなるバケットにアペンドしていくイメージとなる。
rdbmsの文脈で考えると、ほとんどの場合はデータがヒープファイルか、IOTに保存されている。
まとめ
この節のポイントとして
- データがディスク上ではファイルとして保存され、ディスクにはデータ読み書きの最小単位がある
- RDBMSでは、データがデータファイルに保存され、データファイルにはページ・ブロックとのデータ読み書きの最小単位がある
- ディスクの読み書き最小単位と、DBの読み書きの最小単位を一致させると最適化できる
- データファイルにはインデックス、ヒープ、ハッシュとの3つのデータ構造で構築されている
B木インデックスの構造
前節紹介されたデータファイルとは別に、インデックスファイルも存在している。ここでB木を軸にクラスターインデックス(IOT)とヒープテーブルのインデックスについて説明する。
B-木
B-tree はバランス木の一種であり、いくつかの制約・定義に満たさなければならない
- オーダーm(max degreee)のB木に対して、それぞれのノードにはm個以下の枝を持つ
- 一番上の親ノード(根)と、一番下のリーフノード(葉)以外のノードには、少なくともm/2個の枝を持たなければならない
- 根は最低2つの枝を持たないといけない
- 全ての葉は同じレベルにある
- kブランチを持つ、葉以外のノードには、k-1個のキーを持つ
例えば下記の図を例にすると、オーダーが4のB木となっているので、それぞれのノードには、最大3つのキーしか保存できない。データ自体は、key:valueペアの形となっている。バランス木の特徴として、左のキーが右のキーより小さくなる=ソートされている。もちろん、一つのノードにおいても、キーがソートされているため、二分探索で素早くキーを特定できる。一つのノードのブランチは常に保持するデータより1個多い。などの特徴がわかるかと。
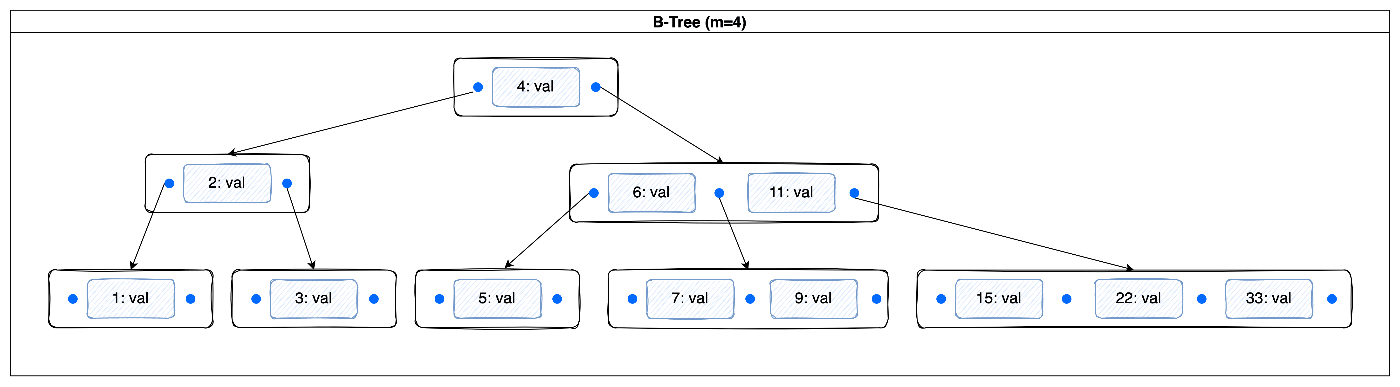
このキーでデータの挿入によって、一つのノードにあるキーが上限を超えることがあるため、ノードの分割などを行うことが必要になる。削除の時も似たような調整が必要。探索、変更の時間複雑度はいずれもO(logN)となるため、インデックスの「素早くデータを特定する」役目には十分達成できているレベルとも言える。その具体的なイメージをより掴めるために、こちらのアニメーションを見て動きを確かめた方が良いでしょう。
B+木
B-木には素早くデータを特定する能力を持つデータ構造になっているが、それには問題が存在している。一回で一つのデータだけを探すなら、key=1で問題ないが、一定のレンジのデータを取り出そうとすると、少し問題となる。例えば、key between 1, 10のデータを取ろうとすると、データはソートされたにも関わらず、key 1からkey 2への繋ぎがないため、都度親ノードから探索をやり直さなければならない。
また、ノード上にkey:valueペアの形でデータを保存している。前節でも触れたが、一回のIOで読み取れるデータ量(ページまたはブロック)が基本一つのノードのサイズに相当するので、ノードで保存できるキーの個数がvalueのサイズに影響されてしまう。例えば、通常valueはディスク上に保存されるデータの場所情報(row_id/tuple_idなど)となっていて、この値を例えば整数ではなくUUIDといったサイズの大きいものになると、この問題が出て来る[2]。また、クラスターインデックスを使うデータベースの場合、データ自体がそのノードで保存されるので、サイズ問題がより著しくなる。
これらの問題を解決するのは、B+木となる。B+木が何が違うかと言うと、
- ノードに保存されるのは常にキーのみとなっている
- 値はリーフノードのみで保存される
- リーフノードでは、ポインターで繋ぎ、双方向の連結リストになる
リーフノードで連結リストになっているのは、レンジクエリーのときに、木の探索が一回だけで終わるメリットがある。なお、双方向なので、逆順(降順)の取得が便利になる。また、ノード上にキーだけ保存されるようになるので、インデックス対象の値のサイズ問題に気にしなくても良くなる。
連結リストの話に触れると、実は一部のB+木の実装では、リーフノードに限らず、同じレベルのノードの間にポインターで連結することがある。これもレンジクエリーに対する最適化で、仮にノードAが1 <= key <= 10のリーフノードを子孫として持っている場合、1, 20でクエリーする際に、一回親ノードに戻って、11, 20のノードを探す必要が出てくる[3]。このような性質もあるゆえに、ノードに保存されているキーを、レンジを分割する意味でseparator keyとしても呼ばれている。
B+木は上記のようなメリットもあり、今時のB木データベースインデックスというと、基本B+木のことを指している。この記事でB木構造、B木インデックスと言及する場合はも慣習に沿ってB+木のことをさす。
クラスターインデックス
データファイルの説で少し触れていたが、クラスターインデックスは、IOT形式でデータを保存するため、テーブル=インデックスになっている。MySQLのInnoDBエンジン を使ったことがある方には詳しいかもしれない。他のデータベースにも同じコンセプトの選択肢が利用できる。ユーザーが指定するクラスターインデックスに使うキー(cluster/primary key)が必要だが、指定がない場合は内部的に行番号などの形で振られることがある。

それで、データは主キーにソートされている。他のインデックス(secondary index)を作ると、インデックスの値はヒープテーブルのような、ディスク上のロケーションを示すrow_idとかではなく、全て主キーとなっている。そのため、上記の図[4]のように、セカンダリーインデックスを利用する際に、secondary index -> cluster/primary index との流れになるので、必ず二回のB木探索が必要となる。
逆にいうと、主キーを使ったクエリーになると、インデックスそのものがテーブルなので、row_idを見つけてヒープテーブルへのアクセスは不要になる。これで非常にIOの節約とのメリットがある。この辺りは、通常のヒープテーブルの保存方式と根本的な違いとなっている。
一つ注意したいのは、クラスターインデックスを利用してテーブルを作成する場合、主キーを何に使うか、とのところだ。容易にソートできるようにする、かつサイズにも気をつけたい。でなければセカンダリーインデックスを作る際に、主キーのサイズが大きいせいで、全てのセカンダリーインデックスの容量も膨らんでしまう。容量が大きくなると、極端の場合メモリーに入れなくなり、OS側でスワップなど色々と作業が増えてさらにクエリーを遅らせることがある。
まとめ
この節のポイントとして
- RDBMSの多くはB木とのデータ構造でインデックスを構築しており、インデックスから素早く検索できるようになっている
- B木では、B-木とB+木の違いがあるが、後者がデータをリーフノードのみに保存するかつ連結することで、B-木の容量やレンジクエリーの探索効率などの欠点を解決している
- 一部のRDBMSでは、ヒープテーブルではなく、index-organized table(IOT)というB木テーブルを構築する選択肢もある
インデックスを利用したデータ検索
これまではテーブルの保存と、B木を軸にインデックスの構造を簡単に説明してきた。この構造がわかれば、B木探索->連結リスト探索->テーブルファイルアクセスという、インデックスを使ったクエリーの流れも大体イメージできただろう。この流れの中で時間効率の良い順で言えば、B木探索 >> 連結リスト探索 >>> テーブルファイルアクセスの順になっている。探索の効率はデータ構造に決められているが、テーブルファイルアクセスのネックはディスクIOになっている。
ディスクIOをなくす、または少なくするのは、インデックスを使う主な目的になっている。この目的にを達成するために、IOT形式のデータファイルを利用するとか、インデックスオンリースキャンとか、様々な工夫と実践が存在する。
I/Oとは
DBのデータは、他でもなくハードディスクに保存されており、そのデータを取得したり、書き込みしたりする時にディスクI/Oが発生する。 大規模データになるほどIOのボトルネックが顕著になる。その発生する主な原因[5]は、IOレスポンス時間=1つ単位のデータ読み書きの所要時間、IOスループット=単位時間あたりの読み書きの量にあるらしい。
IOボトルネックを改善する方針は文脈によってストレージのIO帯域幅とか、ネットワークIOとか色々と考えられる。またOLTPかOLAPか、システム性質によって改善する着目点が異なってくる。この記事では主にOLTPシステムにおけるインデックス利用の観点から話したい。DBのいわゆる「パフォーマンス改善・チューニング」のポイントは、ほとんどディスクIOの削減に尽きるとも言える。
最適化エンジンと統計データ
鳥瞰図でわかるように、クエリーをどう実行していくのかは、Query Processorのレイヤーで決められている。ここはシンタックスの解析と、最適化が行われるところでもある。最適化する際にインデックスの有無が大きな指針になるが、クエリー全体のコスト計算[6]する際に、DBの統計データを参考にし、どのくらいのデータ量になりそうなのかを予測している。
統計データには、テーブル、カラム、インデックスに対して様々なデータが含まれている。例えば、カラム毎のユニークな値の数(cardinality/多重度もしくはselectivity/選択性[7])、最小値と最大値(データのレンジ)、NULL値の数、ヒストグラム(データ分布)、テーブルのサイズ(前述のブロック・ページ数)と行数など。そして、インデックス関連で最も大事なのは、B木の深さ、リーフノードの数、ユニークなキーの数などが挙げられる。その意味で言えば、インデックスの有効性は統計データに含まれて判断されているとも言える。
正しい統計データによって、最適化エンジンが正しくコストを計算し、最適な実行プランを選ぶことができる、というのが根底のロジックとなっている。
ただ、統計データは随時更新ではないかつ毎回テーブルをフルスキャンするわけにはいかないので、一部の場面(例えば頻繁かつ大量なDML操作がある時)で更新に間に合わず精確でなくなる。統計データはクエリプラン作成の根拠であるため、非常に重要なトピックではあるが、また別の機会で詳しく述べたい。
インデックスを使わないクエリー
SQLのクエリーは実際どのくらいのコストがかかるか、どこで時間がかかっているかを調べるためには、EXPLAINが利用できる。例えば、次のPostgreSQL公式例 で見ると、
EXPLAIN SELECT * FROM tenk1;
QUERY PLAN
-------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..458.00 rows=10000 width=244)
Seq Scan on ...との表記が見れれて、カッコの中にクエリー実行のコストとこのクエリーで取れるデータの行数(の予測)が見られる。これは、インデックスを利用していない場合(ここでは何の条件制約もなく、ただ全データを取るのみ)に、シークエンシャルスキャン(sequential scan/full table scan)が実施される。
なお、条件制約を追加しても、絞り込み対象のカラムにインデックスがなければ、同じくseq scanが行われる。その後フィルターリングかけられて、条件に一致しないデータは全部捨てられてしまう。これだけ考えると、ヒープファイルのアクセスがあるため、いっぱいIOを使っていたにも関わらず、取ってきたデータが結局クエリー対象ではないため、無駄なIOが発生してしまう。
インデックスを使うクエリー
実際の開発では、全データ取得のクエリーを飛ばす場面が少ない方で、ほとんどの場合は何かしらの条件制約がかかっている。その代表となっているのは、where文になるだろう。その条件制約のカラムに対して、仮にインデックスがある場合、テーブルアクセスのIOが最小限に制限され、データ取得の効率が上がると思われる。例えば、
EXPLAIN SELECT * FROM tenk1 WHERE unique1 = 42;
QUERY PLAN
-----------------------------------------------------------------------------
Index Scan using tenk1_unique1 on tenk1 (cost=0.29..8.30 rows=1 width=244)
Index Cond: (unique1 = 42)
この場合は、インデックスの作られているカラムに対して、WHEREで条件を追加することで、インデックスを利用した検索となった。そのおかげで、検索のコストも劇的に減り、データ行数も1行のみとなっている。この場合は典型的なindex scanと言われる。
レンジクエリー
条件制約は、必ずしも=を使って(equality check)1行とかに絞るわけではなく、複数行の候補になる場合も頻繁にある。いわばインデックスのあるカラムに対して、レンジクエリーを実行して、index range scanを行う。
ただ、レンジクエリーの時には実は良い状況と悪い状況が存在する[8]。
- リーフノードのデータが物理的に連続している状況: これはよりシンプルなケースで、例えば
WHERE a BETWEEN 1 AND 10といったケースだと、基本連続と考えて問題ない - リーフノードのデータに関連性(correlation)が弱い状況:これは複数の条件を絞る時、もしくは選択性が低い時(大量なデータが候補になる)に相当する。
PostgreSQLの場合、正式なindex range scanという命名のメソッドがないが、前者の場合はindex scanで対処する可能性がある(コストが一番低いなら)。
後者のケースに関しては、独自のBitmap Index Scanを採用している。
A plain Index Scan fetches one tuple-pointer at a time from the index, and immediately visits that tuple in the table. A bitmap scan fetches all the tuple-pointers from the index in one go, sorts them using an in-memory “bitmap” data structure, and then visits the table tuples in physical tuple-location order.
上記の記述[9]のように、考え方としては、データの場所(tuple-pointer)がわかった後すぐにヒープテーブルから取るわけではなく、複数の条件で全ての対象を絞り出して、ビットマップにソート・保存し、最後にこれを参照してテーブルアクセスするようになっている。
例えば、PostgreSQLを例にすると、
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100;
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=5.07..229.20 rows=101 width=244)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0)
Index Cond: (unique1 < 100)
ここでBitmap Heap ScanとBitmap Index Scanという2段階のプランになっている。BitmapIndexScanの方は、どの行にデータがあるのかの情報を集めてくれている。それを利用して、BitmapHeapScanの方は、ヒープファイルに該当行のあるページを探して、ページごとにデータを取ってくる。
ただ、レンジをあまりにも広すぎるようにすると、場合によってSeqScanの方が早いケースもある。レンジクエリーの最も懸念点となるのは、そのレンジの広さにあるとも言える。実践的に言えば、レンジクエリーよりも等価性チェックを利用するのが優先的に考えたい[10]。
インデックスのみを使うクエリー
以上の2つのスキャンは、いずれもB木探索->連結リスト探索->テーブルファイルアクセスの流れを踏んでいる。実際に、最後のテーブルファイルアクセスをせずに、インデックスのみで完結するクエリーはできる。
ここは主に2つの考え方がある
-
selectでインデックスのあるカラムのみを選択する -
includeでインデックス作成時に、よく一緒に取るインデックスではないカラム(non-key columnとも)を含めてインデックスを作る[11]
一つ目のケースは、例えばselect id from table_name where id = 1;とかの場合、IDにインデックスがあるのであれば、リーフノードの時点でセレクト対象となるIDの値はすでにわかるので、ヒープファイルまで行く必要がなくなる。また、CREATE INDEX ON table_name (id, date)というような複合キーの場合も、select id, date where id > 100 and date >= 2024-01-01とかでindex only scanが行われる。
二つ目のケースは、複合キーと多少近いが、違いと言えば、インデックスはID、dateだけに対して貼り付けながら、追加の情報をリーフノードにコピーしておくところにある(non-key column index, covering indexとも)。例えば、CREATE INDEX ON table_name (id) INCLUDE (date)とか。複合キーと比べて、インデックスの情報が少ないので、各ノードにおいて必要とするスペースも少なくなり、B木の階層・レベルが少なくなる可能性がある。ただインデックス全体のサイズが劇的に下がることはない。また、INCLUDEされているカラムはインデックス対象ではないので、テーブルアクセスは省けるが、select id, date where id > 100 and date >= 2024-01-01では複合キーより効率が下がる。
いずれにしても、設計時に複合キーかnon-keyカラムとして追加するかは、アプリケーションと業務内容と割と緊密に関連しており、データアクセスのパターンが分かれば、どのようなデータをよくセットになって、どのような条件で取るかを考えながら決めた方が良いだろう。このボトムアップ的な考え方自体はRDB、NoSQLのインデックス設計に共通すると思われる。
まとめ
それぞれのRDBMSにはデータアクセスする際のスキャンメソッドの呼び方が多少違い、独自のスキャンメソッドも存在する。ただ、概念自体は共通するため、呼び方について下記の表にまとめた。
また、気軽に各DBでプランを見るためにこちらのサイトがおすすめ。
| RDBMS | Sequential Scan | Index Scan | Index Range Scan | Index Only Scan | Other Index Scans |
|---|---|---|---|---|---|
| PostgreSQL | Sequential Scan | Index Scan | (Part of Index Scan) | Index Only Scan | Bitmap Index Scan, Bitmap Heap Scan |
| MySQL | Full Table Scan | Index Scan | Range Scan | Index Covering Scan | |
| Oracle | Full Table Scan | Index Unique Scan | Index Range Scan | (Part of Index Range Scan) | Index Full Scan, Index Fast Full Scan, Index Skip Scan |
| SQL Server | Table Scan | Non-Clustered Index Scan | Index Seek | Covering Index Scan | Clustered Index Scan |
この節のポイントとして
- クエリー実行時はコストをベースで実行プランが作成され、そのコストの最適化にはインデックスの利用が有効
- データ取得時のフィルターの条件のカラムにインデックスをつける
- レンジクエリーより
=のチェックが効率的 - インデックスのみ使えるなら、複合インデックスまたはnon-keyカラムの形でインデックスを作る
WHERE文のインデックス活用
前節でシンプルな例を上げたが、ピンポイントで条件を指定する=の場合と、レンジクエリーで条件を指定する場合がある。
そのほかにも、実はいくつか活用できるパターンが存在する。
関数ベースのインデックス
これは、カラムの値に対して関数をかけて計算された結果(computed value)に対して、インデックスを作るパターン。このパターンでも、whereの条件対象としてインデックスが力を発揮できる。
例えば、よくあるのは、英文も文字列検索する際に大文字と小文字の違いでインデックスにヒットしない可能性がある。そのようなケースでは、
-
UPPER/LOWERといった関数をかけてインデックスを作る - 同じ関数をかけて
WHEREでフィルターリングする
CREATE INDEX upper_name ON users (UPPER(username));
SELECT * FROM users WHERE username = UPPER('value');
このようなインデックスは、function-based index(FBI)とも呼ばれる。また、計算された値に対して関数をかけて直接インデックスが作れないDBもあるが、代わりに計算されたカラム(computed column)に対してインデックスを作るパターンもある。いずれにしても考え方は同じだろう。
部分的インデックス
通常インデックスは一つまたは複数のカラムの全ての行のデータに対して作られるが、部分的インデックスの場合は、一部の行にしかインデックスを作らない。
例えば、チャットメッセージの未読のものだけを取りたい場合がある。
CREATE INDEX unread_msg on messages (send_from_user) WHERE unread is true;
SELECT * FROM messages WHERE unread is true AND send_from_user = 'username';
このメリットで言うと、関心のない行を除外することで、インデックスのサイズがはるかに小さくなる。未読メッセージの量は通常一定に保持されるので、データが増えていくにつれてインデックスのサイズがほぼ変わらないメリットがある[12]。
NULL
部分的インデックスと関連する話だが、NULL値が入っているカラムに対して、NULLをインデックスの一部にするかどうかは基本状況次第。
例えば、出荷日shipped_dateとのカラムがあるとして、注文を取得する際に、未発送のものを取得するパターンが考えら得る。この時は、shipped_date is null的な条件が適切なため、NULLをインデックスに含めるべきだと思われる。
ただ、NULLをインデックスの対象に取り込む時に注意したいのは、やはり選択性の問題になる。is nullの対象行が多くなると、B木探索の恩恵が少なくなるため、連結リスト探索に落ちる恐れがある。また、NULLも含めることで、インデックス自身のサイズも増えていく。部分的インデックスが適応できるかどうか、データのアクセスパターンをよく考えた上で決めたほうが良いでしょう。
LIKE
文字列検索する時に気軽に使える。ただ、WHERE text LIKE '...'で検索するときに、少し問題がある。
-
LIKE a%-> 先頭一致、aから始まる名前のデータが対象になる。インデックス利用可能。 -
LIKE %a-> 後尾一致、aが最後のデータが対象になる。インデックス利用不可。 -
LIKE %a%-> 部分的に一致、aが現れれば対象になる。インデックス利用不可。
先頭一致でない限り、B木インデックスの利用ができない[13]。先頭一致であれば、ワイルドカードまでのテキストは全部インデックス利用対象になる。ワイルドカードの中身は、インデックス探索で取得された行数に対してのフィルター条件になる。その意味で言えば、ワイルドカードの前の部分は精確になるほど、インデックスが力を発揮できる(下記の図 の通り)。

パラメーターバイディング
パラメーターバインディングを利用するには主に2つのメリットがある。
- SQLインジェクションを防止できる
- クエリープランをキャッシュすることで、パラメーターが違う値になっても同じプランを利用することができるため、プラン作成のコストが下がる
- これについて、基本的に複雑なクエリーであるほど、都度コンパイル必要がなくなるため、パラメーターバイディングの恩恵が大きい。
ただ、懸念点と言えば、統計データから取得行数を正しく見積もることが難しいことにある。パラメーターバインディングによって、プレースホルダーを入れてクエリーを最適化エンジンに投げるが、最適化エンジンにとっては、具体値がないからどのくらいの行を取るか、統計データを利用して見積もることができない。プレースホルダーの値は、実行時にしかわからないので、クエリープランの後になるのだ。
どういうケースでパフォーマンスに悪い影響を与えるかというと、
- データの分布が非常に極端なパターン。例えば、todoを管理するテーブルに、
statusのカラムがあるとして、doneになっている項目は、時間の経つにつれてtodoのステータスのものよりはるかに多くなる。この場合にstatusに対してプレースホルダーを入れると、事実とだいぶ違うコストが見積もられるだろう。 - パーティショニング。データが大量にあって複数のテーブルやインデックスに分けられている場合、実際の値によってどのパーティションにアクセスすべきか、または複数のパーティションにアクセスすべきかなどの判断ができないため、実態から離れるコストが見積もられる。
-
LIKEクエリー。%のワイルドカードが冒頭にくるパターンが邪魔になって、インデックスの利用ができるかできないかの判断は、LIKE ?の状態ではできないからだ。結果的にインデックスを利用せずフルスキャンになってしまう。
一見これはパラドックスになっているかもしれない。クエリープランのキャッシングでパフォーマンスが上がるのでは?と思いきや、正確な統計データが利用できないからそもそも最適なプランになるのか?との疑惑に陥るだろう。DBや、我々にとってもトレードオフになるが、正確な統計データによる最適なプランから一歩譲って、上記のケースを考慮した上で、ほとんどの場合はクエリープラン作成のキャッシングとSQLインジェクションのセキュリティメリットを取るのがより大事になるだろう。
まとめ
この節のポイントとして
- カラムの値そのものだけではなく、関数をかけたcomputed valueに対してインデックスをつけると、ケースインセンティブなどの運用場面がある
- インデックス作成時に値に絞る条件をつけることで、とある値のデータが多い、といったデータの選択性の偏りによるクエリーコストの問題が解消される
-
NULLはインデックス対象にはできるが、部分的インデックスで除外すべきかはデータアクセスパターンを考慮したい -
LIKEでは先頭一致の場合のみインデックスが利用可能、かつワイルドカードまで精確であるほど効果的になる - パラメーターバインディングでセキュリティ上やクエリープランのキャッシングによるパフォーマンスのメリットがあるものの、悪影響のケースも存在する
JOINのアルゴリズムとインデックス活用
テーブルのジョインは、正規化されたデータを再び非正規化する操作となる。inner, outerなどのジョインタイプはこちらで割愛する。ジョインの特徴として、
- 一度に2つのテーブルしか同時にジョインできなく、複数のテーブルをジョインする時は段階的に進めるようになる(パイプライン方式)
- 複数のテーブルでジョインする場合、最適化エンジンがジョインするパターンの順列(permutation)を羅列し、その中から最もコストの低いものを選ぶ。ジョインするテーブルが多ければ多いほど、評価するジョイン順番のパターンが階乗的に増えるため、クエリーのレスポンスが遅くなるが、パラメーターバインディングによってプランのキャッシングが可能
- ジョインする際はデータの特徴次第で3つのアルゴリズムでジョインを行う
インデックスを正しく利用することで、時間短縮に繋がることができるが、どのカラムに対してインデックスを作れば正しいと言えるのかは、3つのジョインアルゴリズム次第になる。
nested loops
このアルゴリズムを一言で言えば、フィルター条件でベーステーブル(outer)のレコードはまず全て取得し、その結果に対してループしながら、ジョイン先テーブル(inner)のデータを一件ずつ取得することである。アルゴリズム自体は、いわゆるN+1クエリー問題と全く同じではあるが、N+1問題の本当の問題というのはこのアルゴリズムにあるわけではなく、クエリーをいっぱい生やした後の、サービスとDBの間のネットワークIO、スループット制限といったところにある。そのため、nested loops = N+1問題との誤解は避けたい。
このアルゴリズムの効率は3つの要素に影響される(参考 )
- ジョインするカラムがベース・アウターテーブルにおける選択性
- ジョイン先・インナーテーブルへの効率的なアクセス方法
- ジョイン先のテーブルから重複する行の行数
選択性は、一つのカラムに対して、違う値が多ければ多いほど選択性が高く、逆に値のパターンがあまりない場合は選択性が低い、との概念である。例えば、user_idとのカラムは、通常ユニーク制約もあるので、選択性が高いカラムになる。逆に、性別とのカラムは、テーブルの行数がどれだけ増えても、性別に関しては、指で数えるくらいの可能性しかないので、選択性が低いと考えられる。これはなぜ影響するかというと、選択性が低いと、ジョイン先のテーブルでマッチする行が多くなり、ループ中毎回取るデータ量が増えるからだ。
効率的なアクセス方法というと、まさに今回のトピックになるが、ジョインするカラムにインデックスをつけることが考えられる。
最後にジョイン先テーブルから重複する行の数は、ベーステーブルの選択性と近い考えで、仮にジョインする条件にマッチする行がジョイン先のテーブル多く存在する場合(性別でジョインすると、maleで大量に候補が見つかるだろう)、ループしている中で同じ行は何回もマッチされることになり、重複操作が生じ、リソースの無駄になってしまう。
ネストループは、下記の2つのアルゴリズムに適合性が低い場合、フォールバックのアルゴリズムになるので、設計時のポイントとして、
- 選択性の高いカラムをジョインするカラムとして選ぶ
- ジョインするカラムにインデックスをつける
が考えられるだろう。
hash join
ハッシュジョインはある意味でネストループにおける「ループして1つずつマッチする行を探し出す」操作を改善しようとしている。ハッシュテーブルを事前に用意する必要があるが、時間効率はB木探索のO(logN)からO(1)に下がる。ただ、この方法を有効にするには、ネストループとかなり違うインデックス戦略を取らなければならない。
ハッシュテーブルの用意は、ジョインが始まる前に、先にジョイン先のテーブルの全ての行を取って、ハッシュテーブルに保存することが必要。メモリを配分しないといけないので、ハッシュジョインは厳密に、インナーとアウターの区別はかたまらず、行数の少ない方をハッシュテーブルに置く。ハッシュテーブルはkey:valueの形で保存するが、ハッシュキーはジョインするカラムに相当する。
ここでネストループと大きな違いとして、ハッシュジョインを効率的にするためには、ジョインするカラム以外の件数を絞るための条件カラム
にインデックスをつけることがポイントになる。例えば、
SELECT *
FROM orders o
INNER JOIN order_details od ON o.order_id = od.order_id
WHERE o.order_date BETWEEN '2023-01-01' AND '2023-03-31';
ここでorder_dateにインデックスをつけると、orderテーブルで件数を絞れるので、行数が少ない方だと判断できる。それで、order_idをハッシュキーとして、絞られたorderをハッシュテーブルに入れる。最後に、order_detailsをスキャンして、マッチする行を見つけ出す。このケースでは、order_idにインデックスをつけてもパフォーマンス上メリットがない。
sort merge
ハッシュジョインの方は、データの少ないテーブルの行を用いてハッシュテーブルを作っている。データを用意する意味で言えば、ソートマージの方法は似ているが、片方だけではなく、ジョインする2つのテーブルいずれもデータをソートして置く必要がある。ソートするキーはジョインするカラムになる。そのため、両方のデータがソートできると、データは綺麗に対称的になり、ジョイン効率が高い。ただ、前置条件のソートはコストが高いので[14]、多くの場合はハッシュジョインまたはネストループの方が有利になる。
一方で、前もってデータがソートされている状態であれば、ソートマージを採用するメリットが大きくなる。これは、例えばユーザーテーブルとユーザープロフィールテーブルといった、1対1の関係の持つテーブル、かつ共通する主キーuser_idとかをもっていれば、この事前にソートされている状態が作れる。
EXPLAIN (costs off) SELECT *
FROM users u
JOIN user_profiles up ON up.user_id = u.user_id
ORDER BY u.user_id;
プランを見ると、
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join
Merge Cond: (up.user_id = u.user_id)
−> Index Scan using users_pkey on users u
−> Index Scan using user_profiles_pkey on user_profiles up
(4 rows)
もちろん、user_idといった主キーに限らず、ここで伝えたいのは、order byを運用する時に、ソートするカラムにインデックスをつけると、ソートというコストの高い操作が不要になるため、ソートマージのアルゴリズムが適切なデータ・クエリーであればより効率化できるところである。
まとめ
この節のポイントとして
- テーブルジョインする際に、データ次第でソートマージ、ハッシュ、ネストループとのアルゴリズムで処理する
- ネストループアルゴリズムはN+1問題と同じ考え方で、データの選択性の高いカラムをジョインキーとして選び、インデックスをつけると効果的
- ハッシュアルゴリズムは少ない方のデータでハッシュテーブルに構築するため、ジョインキーのインデックスは効果ないものの、条件絞るためのカラムにインデックスをつけると効果的
- ソートマージアルゴリズムはデータをソートする必要があるため、ソートするカラムにインデックスをつけ、前もってソートされている状態を作れば効果的
なお、どのアルゴリズムにするのかは、基本オプティマイザーが関心を持つ領域ではあるが、開発者として知っておきたいのは
- 以上のアルゴリズムに優劣はなく、適応するケースがそれぞれある
- 明示的にまたはヒントなどを駆使してDBにどれかのジョインアルゴリズムを選択させることはできない
- 各自のアルゴリズムに対して効率を上げる方法を理解した上でインデックスを作るのが嬉しい
ソートとパイプライン方式
パイプライン方式について前節で軽く出ていたが、その考えは名前通りで、できたデータからどんどん次の処理へ繋いでいく考え方となる。これは、データのソートとグループ化の時もインデックスを用いた最適化との意味でかなり大事なポイントになる。パイプライン方式のデータ処理は、Markus氏が曰く、インデックスの第三の力(third power)でもある。
ORDER BY
ソートマージアルゴリズムで言及していたが、(インデックスがない状態の)ソート(order by)の問題は主に2つ考えられる
- ソートする時間(これは仕方がない部分)と空間の複雑度
- パイプライン方式の処理ができない
これらの問題は、大きなデータセットをソートしようとすると顕著になり、メモリに入れきれずディスクアクセスが必要になってしまう。こう言う時に、インデックスをソートするカラムにつけることで、前もってソートされた状態が作れるため、ソートが不要になるだけではなく、パイプライン方式でデータ取得することが可能になる。
この第三の力をうまく利用するために、ソートするカラムにインデックスをつけるだけではなく、クエリーの絞り条件(whereの部分)にも同じカラムで絞る必要がある。
CREATE INDEX idx_order_date ON orders(order_date);
SELECT * FROM orders WHERE order_date >= '2023-01-01' ORDER BY order_date;
複合キーの場合
また、複数のカラムからインデックスを作成する時に、インデックス構成を考えて左からのカラムでソートする必要がある。
例えば、
create index order_date_product_id_idx on orders (order_date, product_id)
-- index利用 OK
select order_date, product_id from orders where order_date > '2020-02-02' order by order_date;
-- index利用 NG
select order_date, product_id from orders where order_date > '2020-02-02' order by product_id;
時に、カラムAに対して降順、カラムBに対して昇順とかミックスのクエリーが考えられる。このケースは「前もってソートされた状態」に当てはまるかどうかは気につける必要がある。
select order_date, product_id from orders where order_date > '2020-02-02' order by order_date asc, product_id desc;
例えば上記のケースだと、インデックスも少し変更する必要がある。
create index order_date_product_id_idx on orders (order_date ASC, product_id DESC)
このような調整をするのは、あくまでも降順と昇順がミックスしたデータアクセスパターンを考慮した上でソートされた状態を作り出すためである。asc/desc指定を追加しても、where文でインデックスの利用には特に影響しないし、降順と昇順が一致する場合は追加する必要がない(リーフノードでは双方向連結リストのため)[15]。
LIMITを使う時
これはよく2つのパターンがある。
-
Top-Nクエリーと呼ばれるものでもある。例えば、一番直近の注文を20件表示するとか、最新のフィード内容を10件取得するとか、様々な場面で出回るだろう。 -
OFFSETと併用してページネーションを作るパターン。例えば、全部注文をリストする際に件数が多すぎてページで分割するなど。
ORDER BYとインデックスの組み合わせがなぜ優先的に考えたいかというと、インデックスがない=前もってソートされていない=パイプライン方式に処理できない、とのことなので、仮に100000件のデータからtop-10を探そうとすると、一回全てのデータを取得して、ソートして、そして99990件を捨てなければならない。
非常に時空間効率の悪い処理になるので、LIMIT(fetch first, topとも)を使う際には、必ずインデックスが効いているかどうか、パイプライン方式に処理されるかどうか、確認した方が良いでしょう。
それで、ページネーションに関しては、OFFSETは毎回同じクエリーを投げて、同じデータセットを取得して、その上で今までのデータを捨てないといけないこと、固定値で分けているので新しいデータが挿入・削除された時にズレが生じてしまう、といった問題が存在するので、基本おすすめはしない。
NoSQLのDBにもよく見られるが、nextPageTokenとかインデックスを利用して素早く検索できる、次のスタート時点となるキーを保存した上で、ページをめくる時のリクエストにパラメーターとして含めると、都度同じ程度の行数だけ取れるようになる。また、キーで比較しているので、仮に挿入と削除があってもズレが生じない。なので、OFFSETを考えるより、WHEREの条件でインデックスつきのカラムに対して境界を指定するのが良いだろう。
SELECT * FROM orders ORDER BY order_date DESC LIMIT 10 OFFSET 50; -- ❌
SELECT * FROM orders WHERE (order_date, product_id) < (?, ?) ORDER BY order_date DESC, product_id DESC LIMIT 10; -- ✅ order_dateとproduct_idで範囲を狭める
複数のカラムでインデックスを作る時に、WHERE (order_date, product_id) < (?, ?)のような表現がDBにとってインデックスを使っての比較になる。
GROUP BY
RDBでグループ化するときのアルゴリズムは2つに分けられる。
- ハッシュアルゴリズム これは自分たちもよく実装する考え方で、要はグループバイのカラムをキーとしてハッシュテーブルを作る。
- ソートグループアルゴリズム ジョインのソートマージアルゴリズムと同じ考え方で、データがソートされた状態をまずグループバイのカラムをソートキーとして作り、後に集計(aggregate)する(主に複数のカラムに対して
group byするケース)
いずれにしても、データをグループ化することは、ソートとかなり近い問題をもっている。すなわち、ハッシュテーブルまたはソートされたデータ(インデックスない前提で)、という中間ステートを持つ必要があり、パイプライン方式でグループ化することができない。
GROUP BYを最適化したい場合は、基本インデックスを利用してソートされた状態のデータを作るのが考えとなる。 MySQLのドキュメント にも記載されている通り、
all GROUP BY columns reference attributes from the same index, and that the index stores its keys in order
同じインデックスのカラムをグループ化の対象にして、かつインデックスの順番を守るのが前提となる。
順番を守る意味で言えばWHERE分とかと同じなのだが、group byの場合は、whereとの組み合わせも考えられる。
create index idx(c1,c2,c3) on t(c1,c2,c3,c4);
SELECT c1, c2, c3 FROM t1 WHERE c2 = 'a' GROUP BY c1, c3; -- c1, c3となっているが、whereでc2で補完できてインデックスが効くようになる
SELECT c1, c2, c3 FROM t1 WHERE c1 = 'a' GROUP BY c2, c3; -- 同じく
通常は、group by c1, c2の順番通りで書くが、上記の例もインデックス利用が可能になる。
まとめ
この節のポイントとして
- インデックスを利用してデータを事前にソートすることで、
ORDER BYとGROUP BYがより効率的になる - ソートの昇順と降順は、複合インデックスの時にデータアクセスパターンを考慮してインデックス作成時に指定する場合がある
- 事前にソートされている状態だと、
LIMIT文で行ったTop-Nクエリーは、パイプライン方式でデータが処理されるようになる - ページネーションを考慮する際に、
OFFSETではなく、データ特定可能な主キーをブックマークとして、クエリーの絞り条件にした方が良い
DMLとインデックス
DBはデータの取得だけではなく、編集と削除などの操作ももちろん必要である。これらの操作に対して、実際インデックスがパフォーマンスに良い影響をもたらすかどうかというと、ネガティブな判断になるかもしれない。これは、インデックスがテーブルのデータの一部のコピーを持っているとも考えられ、テーブルのデータへの変更は、インデックスにも適応しなければならない、というメンテナンスのコストに由来する。
データ挿入
挿入ははっきり言ってインデックスのメリットと無縁となる。というのは、WHERE文がないし、インデックスの目的となる素早い検索というニーズもないからだ。
ヒープテーブルの場合、とにかく空いているページがあればそこにデータを挿入する。ただ、インデックスが存在すれば、全てのインデックスにこの行の情報を追加しなければならない。インデックスの数が多いほど、このコストが多くなる。なお、インデックスは順番を保つ(さらにいうとB木の構造を保つ)必要があるため、ヒープテーブルにデータを挿入するより複雑度が高い。正しい場所を見つけても、スペースがないとまたノードの分割が必要になる。
なので、データ挿入の最もコストの高いところは、テーブルにその行を追加するところではなく、インデックスメンテナンスのところにある。
もちろん、挿入だけ考えるならインデックスがない状態がベストだが、ここのトレードオフというのは、無闇にインデックスを増やさないというところだと思われる。
データ削除
削除は実質、データの取得+データの削除に分解される。WHEREが使えるし、インデックスを利用してデータ取得の段階で恩恵が得られる。」
ただ、挿入と同じ問題で、インデックスの数が増えるにつれ、削除するたびにインデックスの更新も必要になてくる[16]。
データ更新
更新は実質、データの削除+データの挿入に分解されるので、上記の2つの操作のオーバーヘッドを重ねてしまうことになる。
インデックスの数には依存するが、同時にどのカラムに対しての更新にも依存する。つまり、インデックスの貼っているカラムが更新されていなかれば、そのインデックスの更新も不要になる。
そのため、インデックスの数以外に、更新のクエリーを考える時に、必要以上なカラムを巻き込んでいないか、が見るべきポイントになる。
クエリーブランを見る時
DMLの操作ももちろん、EXPLAIN, ANALYZEでプランを確認することが可能。ただ、ANALYZEの方は、クエリーを実際に実行してしまうので、DMLのクエリーに対しては、EXPLAINが無難になる。もちろん、デバッグ観点での実行や、予測コストと実際コストの予実比較には有用であろう。
まとめ
この節のポイントとして
- インデックス設計は読みだけではなく、データ書きも考慮する必要がある
- データ更新のコストは全般的に、インデックスの数と反比例するため、インデックスの数を必要以上増やさない
- 挿入はインデックス利用ができないものの、削除と更新は対象データ検索の意味で利用することができる
- データ更新は、更新カラムによってインデックスによるネガティヴ影響を避けることができるため、更新したいカラムだけを更新する
終わりにーインデックスの3つの力
Markus氏がSQL Performance Explainedの中で、インデックスには3つの力(power)があると主張している。
- first power: 対数時間複雑度の探索
B木探索->連結リスト探索->テーブルファイルアクセスとの流れの中で最も効率の良い部分がファーストパワーとして強調されている。ゆえに、インデックスをうまく利用して、テーブルファイルへのアクセスを最小限に抑えるのは、この第一の力を最大限にするためである。
- second power: クラスタ化されたデータ
Clustering data means to store consecutively accessed data closely together so that accessing it requires fewer IO operations(p.111).
インデックスを作ると、ターゲットとなるカラムを基準にデータがソートされるようになる。複数のインデックス(特に複数のカラムから作った複合インデックス)を作れば、それぞれの基準で近い値を持つデータをクラスタ化・近いところに配置することを意味する。これがあるからこそ、関連性の近いデータ(レンジクエリー、複合キーのカラムを条件にするクエリーなど)の取得が効率的になる。
- third power: パイプライン方式のデータ処理
ジョインやソート・グループ化する時に、インデックスを利用して前もってソートされている状態を作れば、パイプライン方式のデータ処理に用いることができ、無駄のない実行プランになれる。
これらの3つの力は、いずれもB木インデックスの構造が根底にあるので、データがどう保存されているかを理解しなければならない。
この記事を通して、筆者自身の直近DB関連の学びを整理して共有した。DBMSの話は、学べば学ぶ程膨大だと感じており、今回は一旦データ保存の仕方とインデックスの利用での最適化に絞って書いてみた。これをスタート地点として、SQLは書けるけどRDBはわからないと感じている方の参考になれると嬉しく思う。
-
Database Internals p.9, ↩︎
-
実際ノードにキーを保存する際に、Prefix compressionやsuffix truncationといった手法でスペース最適化はされるらしい が、UUIDのような文字列の場合はこれらの手法で最適化することが難しく、一般的にsortableなキーよりもスペースが必要となってくる。 ↩︎
-
Leetcodeで この問題 を見た時に何に使うか思いつかなかったが、Database Internalsを読んで初めて理解した。 ↩︎
-
Database Internals p.21, ↩︎
-
コストの単位はよくミリ秒とかに誤解されることがある。これは最適なプランを選択する時に比較するために利用するものなのでコストには単位がない。コストを基準にする最適化エンジン(cost-based optimizer)以外にも、ルールベース、ヒューリスティックベースなどのタイプが存在するが、主流となるのはやはりコストベースになっている。コストには、クエリーの用意コスト、インデックス利用のコスト、ヒープテーブルアクセスのIOコストなどが含まれる。
..の前の部分はクエリー用意のコスト(startup cost)となり、サブクエーリー、関数演算、ハッシュジョインのような事前にデータ用意が必要な操作などで増えてしまう。..の後の部分が全体のコストになっている。通常全体コストを見るものの、用意コストが大きくなる時も気をつけなければならない。 ↩︎ -
関係が近い概念ではあるが、定義としては異なる。selectivity/選択性 = クエリーから取得した行数 / トータルな行数。cardinality/多重度 = トータルな行数 * 選択性 = クエリーから取得した行数。この数式のように、選択性は、通常数値として0-1に表現されて、低いほど選択性が高い。多重度の訳語は多少紛らわしいのは、選択性と同一視しているのが多いからだ。多重度は行数との絶対値を表現する本来の概念よりも、値のバリエーションを指すとの解釈もみられたりするので、誤解を避けるために選択性との言葉を使う。 ↩︎
-
PostgreSQL 14 Internals , p331 ↩︎
-
こちらに参照:https://www.postgresql.org/message-id/12553.1135634231@sss.pgh.pa.us ↩︎
-
SQL Performance Explained, p.42. 原文:
Rule of thumb: index for equality first - then for ranges↩︎ -
この考え方についてNoSQL側にも近いものが存在する。例えば、DynamoDBには sparse-index とのテクニックがあり、カラムAに対して値が存在する行のみインデックス対象となる。NoSQLには固定のスキーマがないため、RDBのNULL値を除外した部分的インデックスとは同じ考え方になる。 ↩︎
-
ここはいくつかのケースに分けられる。もし
work_memに定義されているメモリ量にデータが入るのであれば、基本quicksort採用され、O(N*logN + M*logM)になる。一方で、行数が多い場合は、別途ディスクへの書き読みが発生する。また、LIMIT文がついている場合は、いわばTop-N queryになると、ヒープソートが採用され、必要な分だけ取るようになる。詳細はこちらの記事 に参照されたい。 ↩︎ -
例外として、クラスターインデックスのテーブルでは、セカンダリーインデックスを作る時に、クラスターキー・PKも暗黙的にインデックスに追加されるが、そのソート方向を指定することができない。 ↩︎
-
PostgreSQLで削除する際に、行に
deletedのフラグをつけて、定期実行のVACUUMプロセス( routine vacuuming )によって物理削除されるようになる。その意味で言えば、インデックスの数には直接に影響されない。 ↩︎
Discussion