Laravel マイグレーションでの文字列の「長さ」とは
若干ぼんやりしたタイトルですが、こちらのマイグレーションコードを見て、stringメソッドで定義した「長さ」というのは一体何のことだろうか、との疑問から始まった一連の調査のまとめです。
public function up()
{
Schema::create('items', function (Blueprint $table) {
$table->id();
$table->string('name', 40);
$table->string('description');
// ...
$table->timestamps();
});
}
lengthとは
まずはlaravelのソースコードを見ると、stringメソッドは次のように定義されています。
/**
* Create a new string column on the table.
*
* @param string $column
* @param int|null $length
* @return \Illuminate\Database\Schema\ColumnDefinition
*/
public function string($column, $length = null)
{
$length = $length ?: Builder::$defaultStringLength;
return $this->addColumn('string', $column, compact('length'));
}
// ...
/**
* The default string length for migrations.
*
* @var int
*/
public static $defaultStringLength = 255;
はい、lengthについて特に説明がありませんが、デフォルトの文字列長さが255となります。
255って何?少しCSに馴染みのある方はすぐにわかるかもしれませんが、255 = 2^8-1 で、8bitで保存できる最大の数字となります。8bit = 1byteですから、1バイトで保存できる数字の上限で、256になると、もう一つのバイトを使うことになります。これは、Amazonパントリーで、ちょうど段ボールひとつ100%詰めたけど、ドリンク1本のせいで二つ目のダンボールが必要になった、というもったない感がありますね。
ならば、「長さ」の単位って何でしょうか。まずは次の例を見てみると:
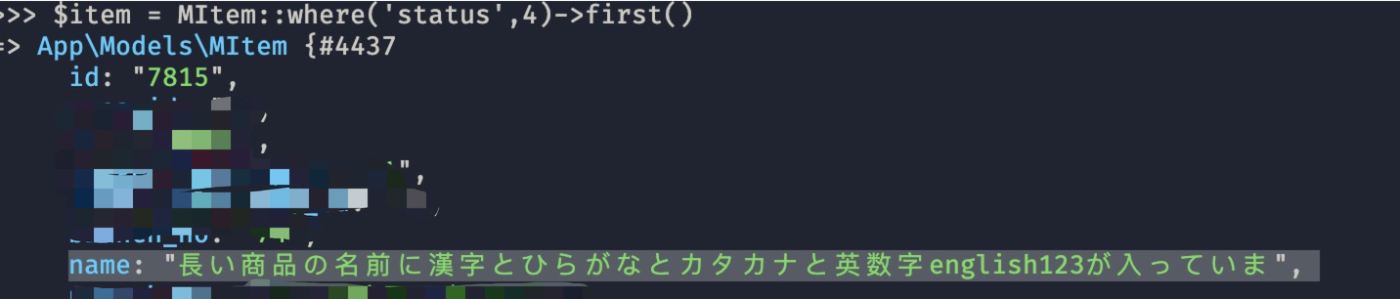

strlen関数は文字列のバイト数をカウントしています。ここはutf-8のエンコーディングを使っているので、英数字を含めて半角1文字で1バイト、全角1文字で3バイトとなります。それに対して、mb_strlen関数は文字列の文字数をカウントしています。なので、英数字を含めて半角1文字も全角1文字も1文字となります。
上記の例で、stringメソッドで定義された「長さ」が40ですが、それは40バイトというより、40文字となっていますね。数えてみるとわかりますが、英数字のenglish123がちょうど10文字で、半角英数字などはutf-8で1バイトを使っています。残りの30文字は全て全角文字で3バイトを占めていますので、90バイトを使っています。
つまり、マイグレーションのstringメソッドで定義した「長さ」というのは、文字数のことを指しています。
果たしてそうでしょうか。
バイト数と文字数
前節でも少し触れましたが、データーベースに、キャラクター(char)の保存に必要とするバイト数が、charset・エンコーディングによって違います。例えばutf-8の場合は基本的に1バイトから4バイトが必要となりますが、漢字など全角日本語は3バイト使います。日本語で使われているSJISでは、ASCII、半角カタカナなどの半角文字が1バイト、漢字や全角仮名などが2バイトとなります。utf-16の場合、全角文字は2バイトでSJISと同じですが、半角カナでも2バイト使ってしまいます。
Laravelのコマンドで、上記のマイグレーションコードで実行されるSQLをチェックしてみると:
php artisan migrate --pretend
// SQL Server
create table "items" (
"id" bigint identity primary key not null,
"name" nvarchar(40) not null,
"description" nvarchar(255) not null,
"created_at" datetime null,
"updated_at" datetime null
)
SQLでは、nvarchar(40)とnvarchar(255)の定義となります。ただ、公式の説明によると、nvarchar(n), nchar(n)のnは文字数ではありません。
A common misconception is to think that NCHAR(n) and NVARCHAR(n), the n defines the number of characters. But in NCHAR(n) and NVARCHAR(n) the n defines the string length in byte-pairs (0-4,000). n never defines numbers of characters that can be stored. This is similar to the definition of CHAR(n) and VARCHAR(n).
ではなぜ、前節の例では、「文字数」に見えるのでしょうか。これはキャラクターセット・エンコーディングに騙されているだけです。SQL Serverで日本語の文字を保存する際に、utf-8ではなく、utf-16を使っています。ここのnの単位はバイトペア=2バイトとなります。つまり、utf-16で保存されている日本語のデータは、1文字2バイト=1バイトペアとなっていて、ちょうどnと同じになった、偶然に過ぎません。物理容量の上限は依然として存在し、nはその上限のバイトペア数を定義しています。
しかし、前節のnameが40バイトペア、つまり80バイトなのに、なぜ100バイトのデータが保存できたのだろうか。これはただの誤解で、Laravelではデフォルトのエンコーディングがutf-8なので、tinkerでテストしていると、日本語の1文字が3バイト使います。その環境で取得すると、定義の40バイトペアを超えてしまうバイト数になっただけです。
DBによる違い
nがバイト数かそれとも文字数か、DBによって違います。
SQL Serverでは、1バイトを超える文字を使うときに、VARCHARではなく、NVARCHARがすすめられています。先ほども触れましたが、NVARCHAR(n)の形で指定できる最大サイズが4000バイトペアとなります(VARCHARの最大は8000バイト)。nは文字数ではありません。仮に2バイトペアを使う文字があれば、4000文字に到達する前にバイト数の上限を超える可能性があります。
MySQLの場合、VARCHARのnは文字数を指しています(4.0以前はバイト数らしい)。文字数は0-65,535まで指定できますが、これは、英数字など1バイト=1文字の場合は文字数かバイト数か関係ないですかもしれません。ただ、バイト数が文字数より大きい場合は、65535バイトが上限となります。PostgreSQLも同じく、nが文字数を指していますが、マックスサイズが65535バイトまでとなります。
Oracleには少し違いがありますが、設定によって上限がばらつきます。Oracleでは、varchar2を使い、varchar2(40 BYTE)か、varchar2(40 CHAR)の指定が可能となり、上限の単位をバイト数または文字数にするかをはっきりと決められます(ここにも参照)。ただ、最終的に上限は4000バイト(スタンダードの場合)となっていて、もしutf-8で日本語全角文字を保存すると、1333文字を超えると上限を超えることになりますので、仮に4000 CHARを指定しても保存はできません。また、Oracleにも、NVARCHAR2がありますが、キャラクターセットがutf-16かutf-8しか選べませんので、例えばSJISで保存したい場合は、VARCHAR2を使うことになると思います。
まとめ
これでようやく結論ができた気がします。
- VARCHARのnで定義されたのは、文字数かバイト数か、SQLのDialectによって違います。
- DBに保存されている時に使用されるcharset/encodingは文字のバイト数を決められます。
- Laravelのマイグレーションのstringメソッドでは、「長さ」との定義は基本的に「文字数」との認識で良いが、SQL Serverのような、文字数ではない可能性もあります。
- Laravelのデフォルトエンコーディングがutf-8のため、日本語の場合、バイト数と文字数、定義の文字数・バイト数と合わない可能性がありますが、騙されないように注意が必要です。
補足
最近業務では、指定のバイト数で文字列をカットして欲しい、との要望がありました。その対応のためでもあって上記の調査をしていました。自分もしくは相手が使っているDB、該当フィールドの定義、使用されているキャラクターセットを事前にわかることが必要ですね。
Laravelのコード例:
function truncateItemColumn(array $items, string $column, int $length)
{
return array_map(function ($item) use ($column, $length) {
$converted = mb_convert_encoding($item[$column], 'SJIS', 'utf-8');
$cut = mb_strcut($converted, 0, $length);
$item[$column] = mb_convert_encoding($cut, 'utf-8', 'SJIS');
return $item;
}, $items);
}
ではでは。
Discussion