GTCでの発表時に現地で販売されたJetson Nanoをお土産にもらったことのあるコネクトーム・デザインの伊藤です。
前回書いたNIMの記事の冒頭でちらっと触れましたが、NIMより前に公開されていたNVIDIAの新しいサービス「Jetson AI Lab」を紹介したいと思います。
1. "Generative AI at the Edge"
謳い文句の通り、エッジデバイスで生成AIを動かすためのライブラリが揃っています。
トップページを下に少しスクロールし、"Check out our tutorials"を見てみると、テキスト生成、画像生成、ViTなどが並んでいます。これらを"簡単に"動かすことができるとのこと。どれくらい簡単なのか、実際に試してみます。
2. Jetsonシリーズについて
Jetsonについても少しだけ紹介しておきます。
Jetsonシリーズは組み込みやエッジ環境でAIを動かすための小さなコンピュータです。
TX1、TX2、AGX、Xavier、Nano、NX、Orinなど多く機種が発売されてきました。
"GPU搭載Raspberry Pi"のような感じのNanoから、自動運転やロボット制御にも使えるようなハイパワーなAGXまで、幅広くラインナップされ、NVIDIAらしく新機種へのアップデートも割と頻繁に行われています。
詳しくはこちらをご覧ください。
Jetsonによる組み込みシステム
OSは、Ubuntu Linuxをベースにデバイスドライバや基本ライブラリがプリセットされた、"Jetpack"が用意されており、microSDに書き込むだけで簡単にセットアップできるようになっています。(機種によってセットアップ手順は異なります。)

個人所有のJetson 2台。左:Jetson Nano/右:Jetson Orin Nano
(赤/黄色の部分は、3Dプリンターで作ったボトムケース)
Raspberry Pi4よりは大きいですが、手のひらに乗るくらいのサイズです。
※Orin Nanoの画像出力端子はDisplayPortのみ。ここはHDMIを選択して欲しかった。
今回は、この"Orin Nano"を使って進めていきます。
RYOYO NVIDIA JETSON ORIN NANO 開発者キット 商品ページ
なお、生産終了している"Jetson Nano"はJetpack4.6.1までしか対応していないため、今回のサンプルは動かせません。
3. 生成AIを動かせるJetsonの環境
それでは、「Explore Tutorials」のリンクボタンから、チュートリアルを見てみましょう。
Tutorial - Introduction
一番上に出てくる、
Text (LLM)
text-generation-webui
を見てみます。
"What you need"として、動作に必要な環境が書かれています。

必要なJetsonデバイスは以下のどれか。
- Jetson AGX Orin (64GB)
- Jetson AGX Orin (32GB)
- Jetson Orin NX (16GB)
- Jetson Orin Nano (8GB)
最低でも、Orin Nanoが必要。ただし、メモリが8GBなので、7B modelのLLMしか動かせません。
※Jetsonは、CPUとGPUでメモリを共用します。
Jetpackは、5か6。
今回は新しくセットアップしたので、Jetpack6を入れました。
また、通常はmicroSDカードにJetpackを入れますが、高速化とストレージ容量増強のため、背面のM.2スロットに1TBのNVMe SSDを追加してJetpackをインストールしました。

4. LLMをセットアップしてみる
手順に従って進めます。
- Set up a container for text-generation-webui
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
このまま進めるとモデルを読み込もうとするとさすがにメモリ不足になるため、Ubuntuのデスクトップを止めておきます。
sudo systemctl set-default multi-user.target
# sudo systemctl set-default graphical.target →GUIに戻すとき
sudo reboot
再起動したらいよいよコンテナを立ち上げます。
- How to start
jetson-containers run $(autotag text-generation-webui)
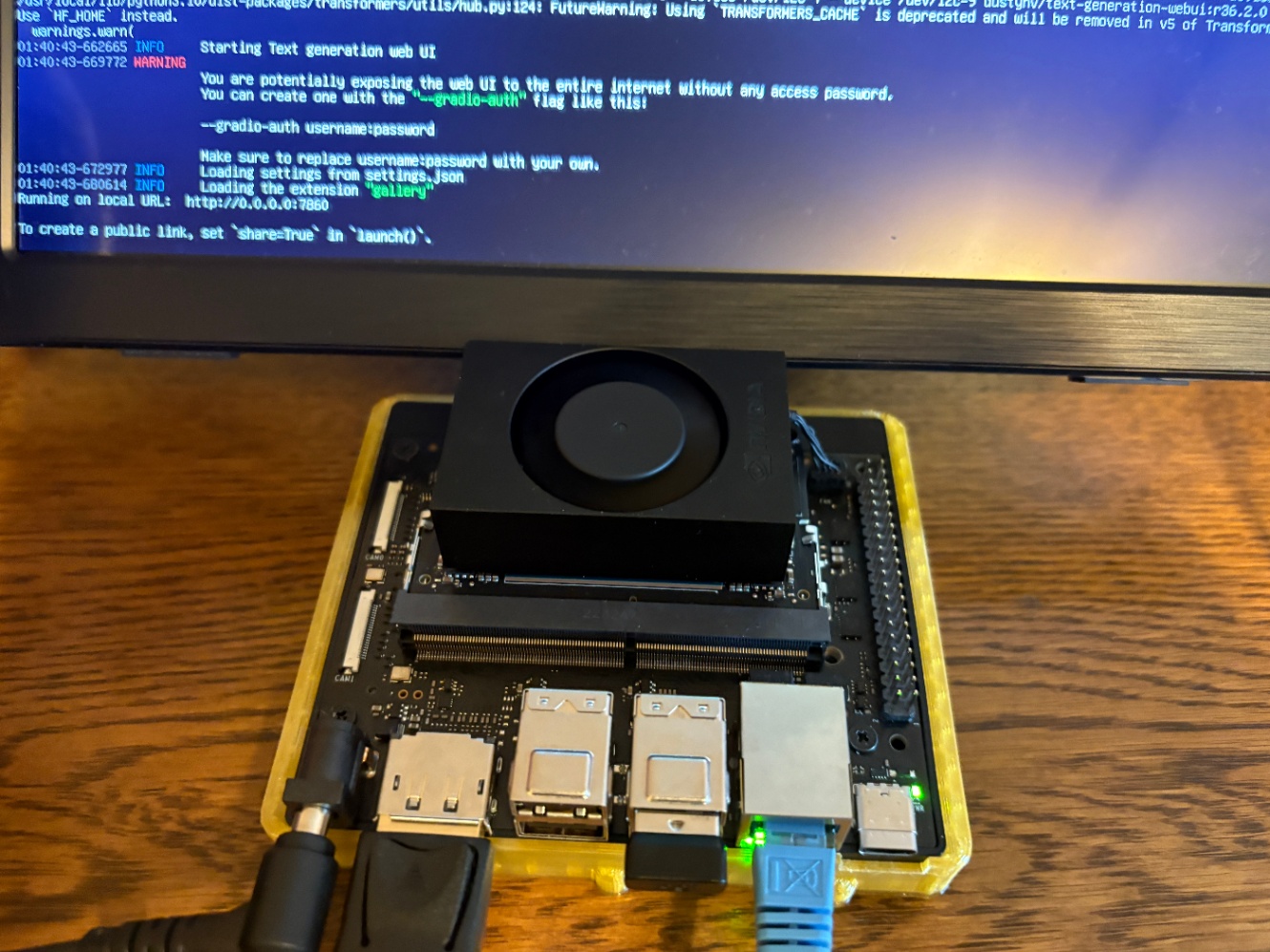
動きました。
同じLAN上のPCからブラウザでアクセスすると、プロンプト入力画面が出てきます。
http://<IP_ADDRESS>:7860
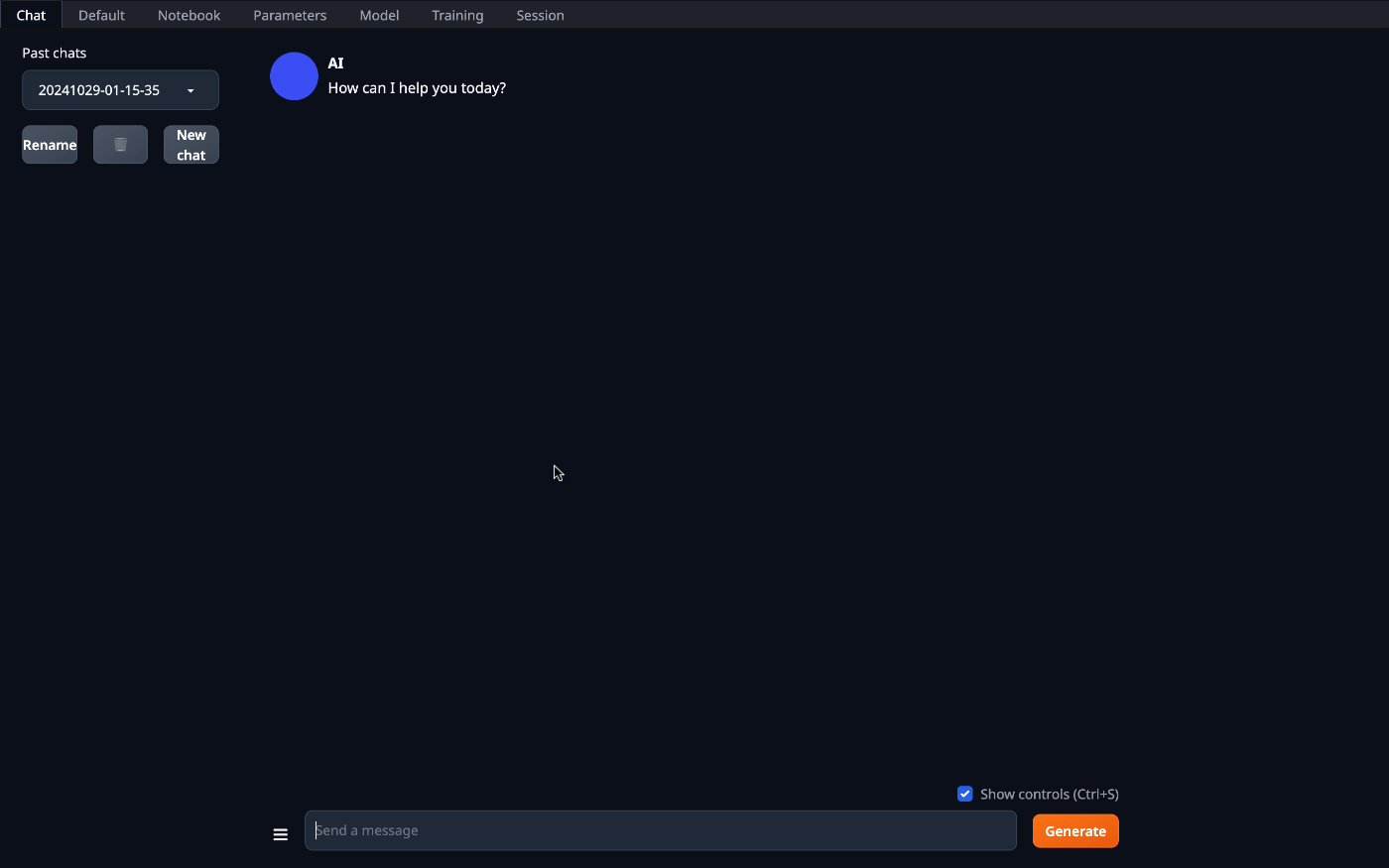
ここではまだモデルが読み込まれていないのでもう少し操作が必要です。
ここからはブラウザ上で操作できるようになります。
モデルをダウンロードして読み込みます。
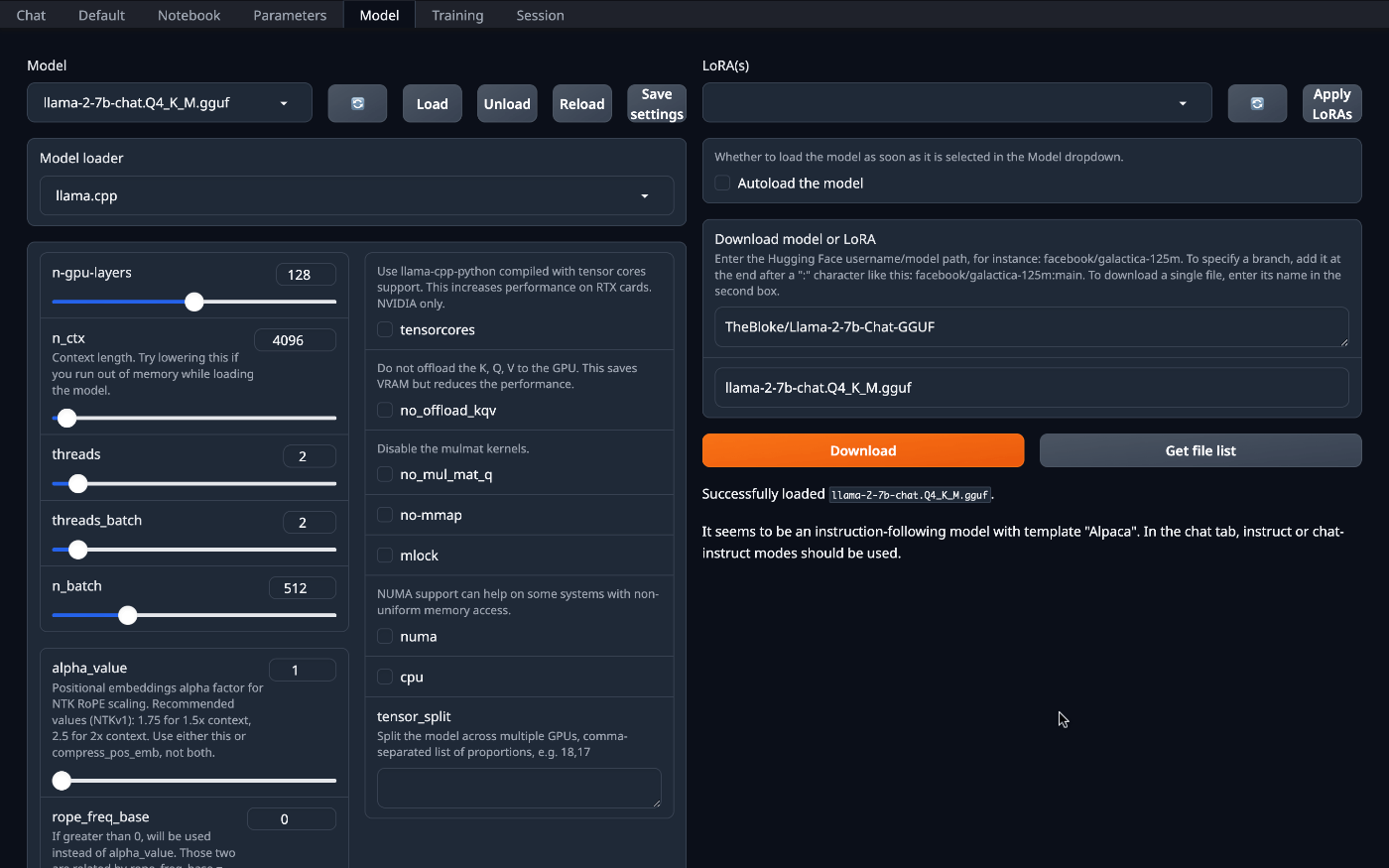
チュートリアルに合わせて、
- TheBloke/Llama-2-7b-Chat-GGUF
- llama-2-7b-chat.Q4_K_M.gguf
を指定して"Download"。
ダウンロードできたら、左上の"Model"選択のプルダウンメニュー横のボタンを押してリストを更新し、リストから"llama-2-7b-chat.Q4_K_M.gguf"を選択。
"Model loader"は、"llama.cpp"を選択。
"n-gpu-layers"の値を、"128"に設定。
"Load"ボタンを押して、モデルを読み込み。
これで準備完了です。
5. AIに質問してみる
では、AIに質問してみましょう。
Q:LLMをエッジデバイス上で動作させることによるメリットを教えて。
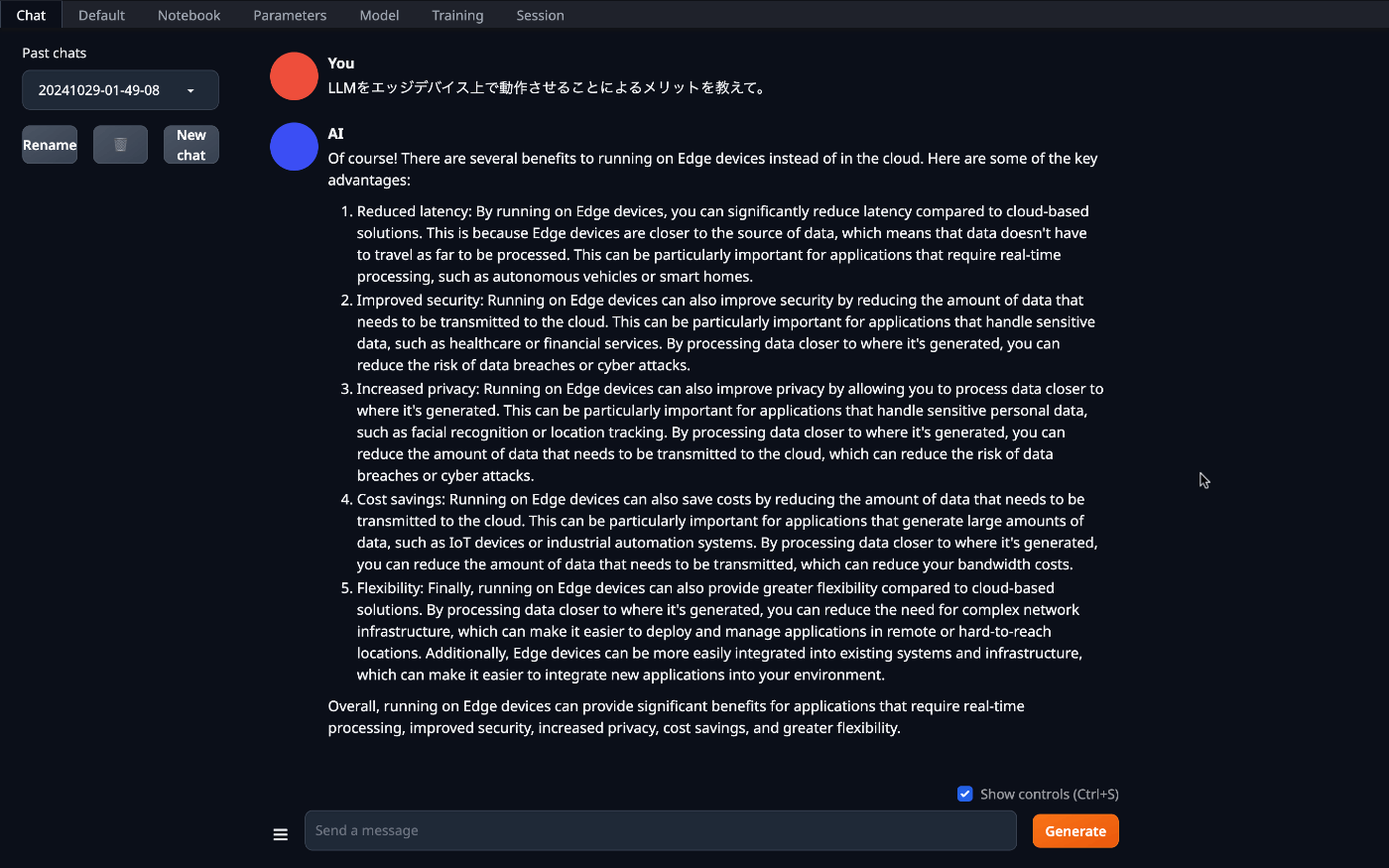
約98秒、500トークン。
きちんとした回答が英語で返ってきました。
日本語で回答してくれるようにお願いしてみましょう。
Q:LLMをエッジデバイス上で動作させることによるメリットを教えて。日本語で回答してください。
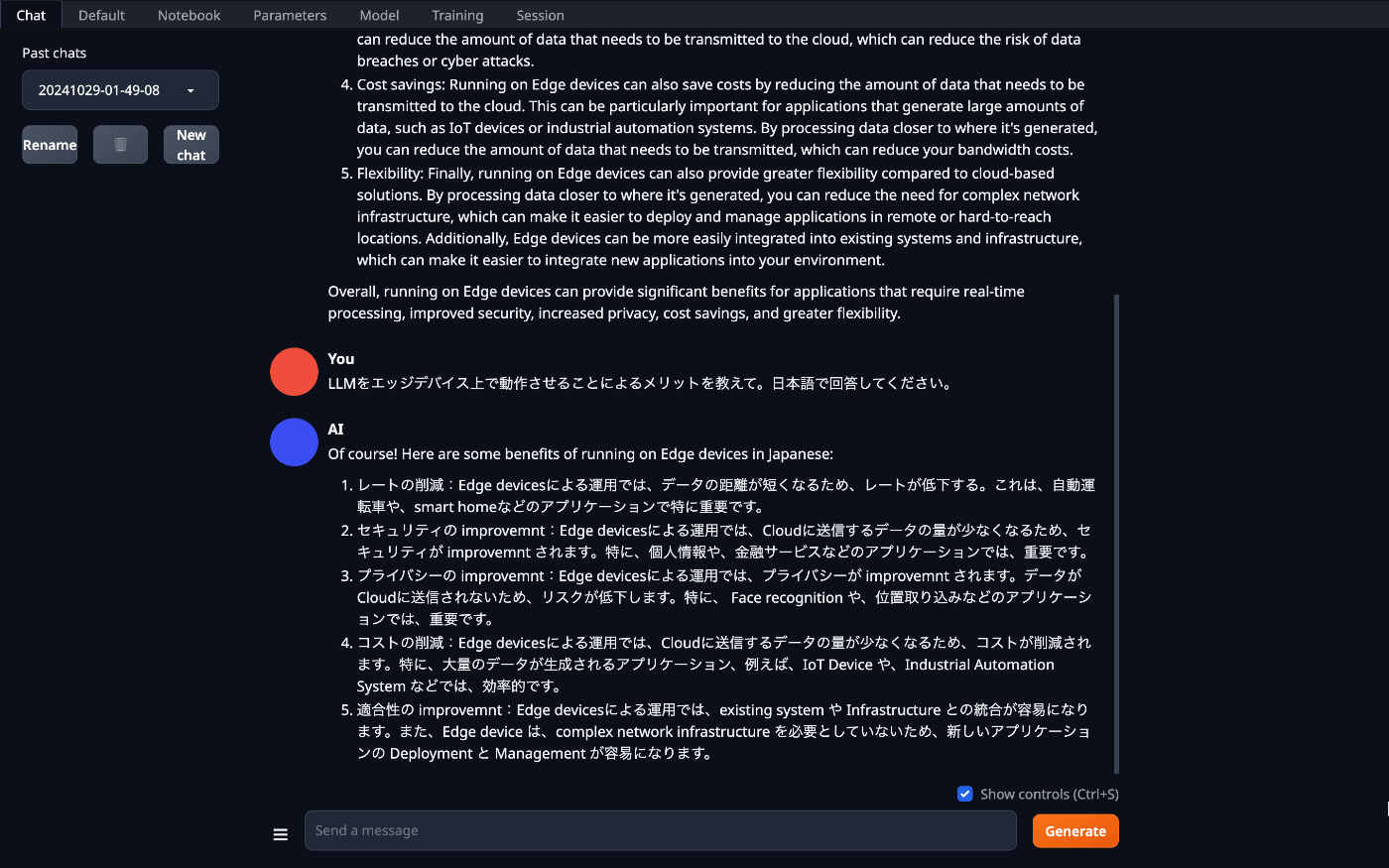
約108秒、540トークン。
ちゃんと日本語で答えてくれましたが、ところどころ英単語がそのままになっていました。
もう一つ、日本語チャットモデルも試してみました。
このモデルはchatntq-ja-7b-v1.0をベースにした7Bパラメータの日本語チャットモデルです。高性能の英語モデルであるStarling-LM-7B-betaの重みからMistral-7B-v0.1の重みを差し引くことで得たchat vectorを適用しています。
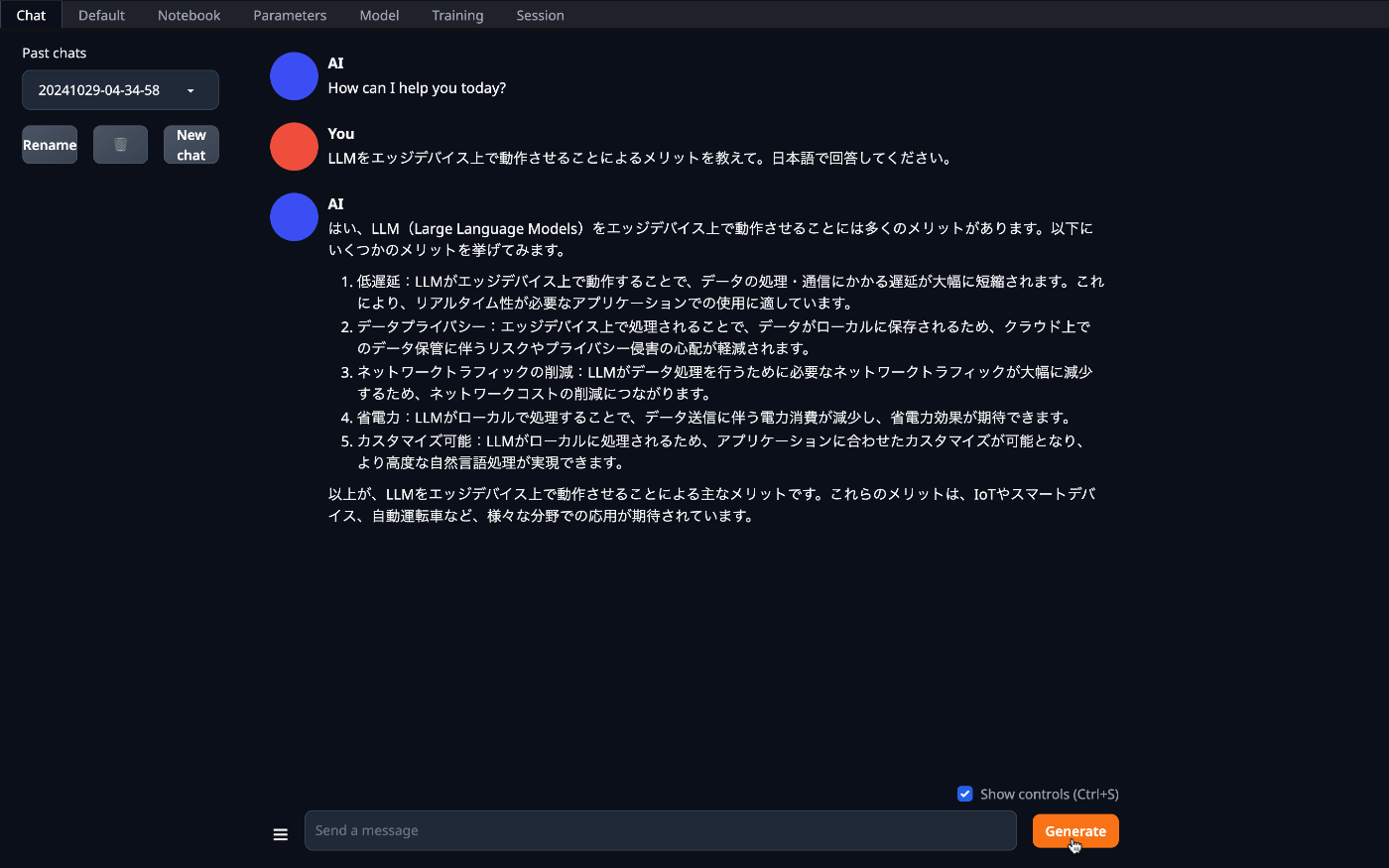
約178秒、570トークン。
倍くらいの時間がかかりましたが、回答としてはなかりこなれた日本語になっています。
こんな小さなシングルボードコンピュータ上で、7BモデルのLLMが動作しました。
若干、応答に時間がかかりますが、どれだけやりとりしても上限値に引っかかることはないですし、もちろん課金も発生しません。
工場内などエッジデバイス単体で運用できるチャットボット活用の可能性も見えてきそうです。
6. 続いて、「Stable Diffusion」での画像生成
では次に、画像生成を試してみましょう。
Image Generation
Stable Diffusion
こちらも同じ環境で動作するので、早速セットアップ。
jetson-containersのインストールはすでに終わっているので、"How to start"の通り、Jetsonで次のコマンドを入力するだけです。
jetson-containers run $(autotag stable-diffusion-webui)
先ほどと同様に別PCからブラウザでアクセス。
http://<IP_ADDRESS>:7860
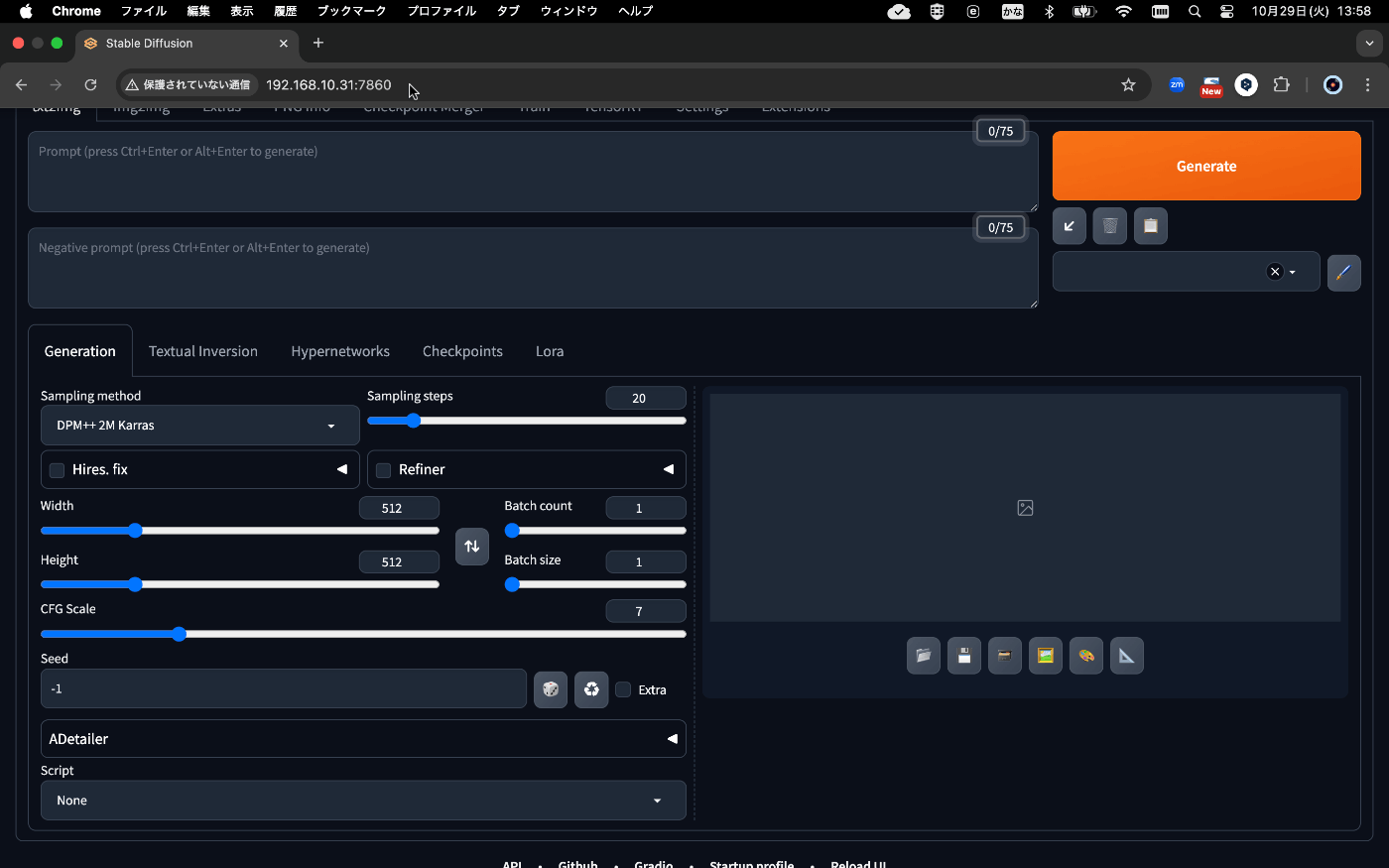
見慣れた、"AUTOMATIC1111's stable-diffusion-webui" が動いています。
自分のGPU搭載PCに、Stable Diffusion webuiの環境を構築したことのある方は、こんなに楽に動かせることに驚かれるのではないかと思います。
リアル系の画像生成が得意なBRA V7のCheckpointを入れ、簡単なプロンプトを入れてみます。
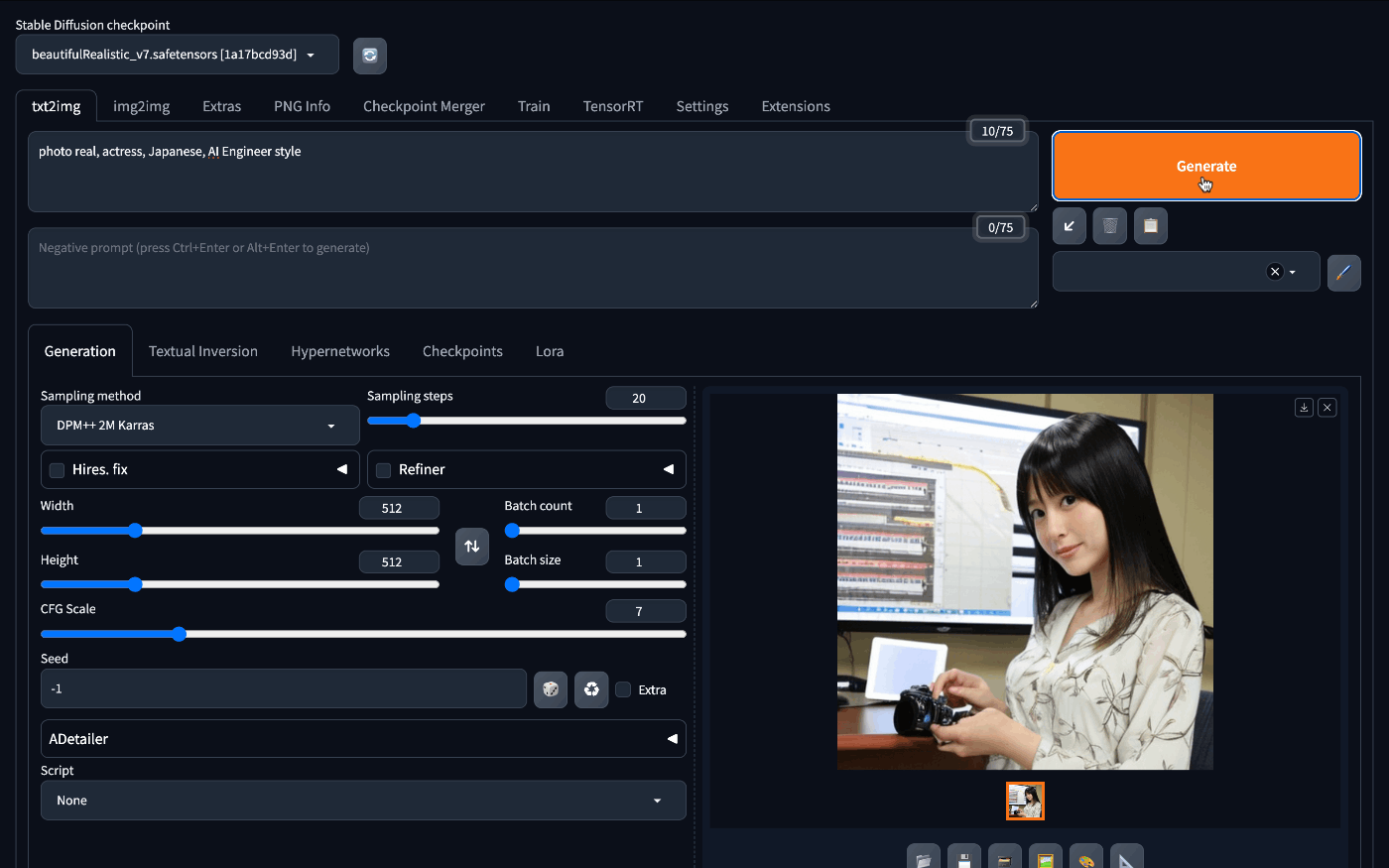
一枚の画像を生成するのに20秒程度。
十分使えるレベルではないかと思います。もちろん、作成枚数の制限もなく作り放題です。
7. 最後に
Orin Nanoではメモリ8GBの制約のため、並んでいる全てのチュートリアルを動かすことはできませんが、NanoVLMやNanoOWLなども動かせるので、同様の手順で簡単に試すことができます。
(カメラが必要な場合は、USB接続のwebカメラも使えます。)
手のひらサイズのコンピュータだけでオフラインでLLMや画像生成AIを持ち運べるという点は、「え、これだけで動いてるの?」というインパクトも大きいですが、今後のエッジAIの発展に大きな期待が持てるかと思います。

Discussion
初めまして。個人でローカルLLMに興味がある者です。興味深い記事をありがとうございました!
◆質問:このページの性能結果は、最近発表された「Jetson Orin Nano Super 開発者キット用のソフトウェア更新前のJetson Orin Nanoの結果」と理解していますが、合っていますか?下記記事では70%向上との話をしていたので、もし個人的に新規購入した際は、ここのページ結果のx1.7倍の速度になるのかな?と想像しました。
◆記事抜粋:本日より提供開始したJetson Orin Nano Super向けのソフトウェアアップデートは、従来のJetson Orin NXやJetson Orin Nanoシリーズにも適用でき、ソフトウェア更新により生成AI性能を最大70%向上させることができるという。
コメントありがとうございます。
ご指摘の通り、"初期型のJetson Orin Nano" で試したものになります。
新型の"Super"は生成AIの性能が70%向上と謳われているので、体感できるくらいの速度向上はあるだろうと想像しております。価格が半額程度になった点も導入しやすくなりますよね。
ただ、実際に業務レベルで使うにはパワー不足は否めないと思いますので、AGX Orinなどの検討が必要になるだろうと考えています。
返信ありがとうございます!
一番のネックは「メモリ8GBの制約」ですよね。様々なモデルがあっても、この制約からは逃れられないので。ですが、使用するシチュエーションを絞り込めば、使える場面がある!と興味を持ってみています。
Superもハードウェアは同じで、初期型もJetpackを入れ替えれば性能向上されるようです。実際に応答時間計測して比較してみようと思います。
おお!比較レビューを期待しています☺️