Anomaly detection is the process of identifying unusual or unexpected patterns in a dataset. Conceptually, it can be considered as two-class (Binary) classification, in which data can be divided into “normal” and “anomaly”.
In the case of image data, one of the usual use cases is identifying defective products. Given an image of the product, the goal is to identify whether the product is defective (anomaly) or not.
(Semi-)Supervised anomaly detection methods are based on training a model with both good (defect-free) and bad (defective) data.
On the other hand, unsupervised anomaly detection methods only use good (defect-free) data for training. As the result, model leans the patterns that are considered good (or defect-free), and anything outside that is considered anomaly (defect).
Usually, unsupervised methods need 100+ good images for training. However, it is highly desirable to use as few data as possible for training to reduce the cost of collecting good data. When the number of training data is reduced to handful number of images. They are called few-shot methods. In the extreme case, NO data is used for training, and those methods are called zero-shot.
Following, we briefly introduce a zero-shot anomaly detection method that was presented in the paper entitled “Zero-shot versus Many-shot: Unsupervised Texture Anomaly Detection” and presented in WACV 2003.
access the article from here:
Following is the summary and highlights of the method proposed in the paper. Please refer to the paper for more detailed information.
One of the main questions is that in which cases and how zero-shot anomaly detection is feasible? Considering that anomaly detection methods try to find the regions of the image that their pattern is different from normal pattern, the problem can be reformulated as detecting regions of the image that break the homogeneity of the input image.
There are two basic assumptions about the product and the defect. The first and the main assumption is that the product has a repetitive pattern, for example, products such as carpet, textile, or tile. And the second assumption is that the defective area does not cover the whole image. In other words, there are “enough” normal pattern visible in the image.
The authors classify the patterns that their method can target into three categories:
Category-1: Anisotropic textures having a repetitive structure with perfect regularity. They are similar to grid in MVTec AD and are often found on the surfaces of manmade objects made of hard materials.
Category-2: Anisotropic textures having a repetitive structure with some irregularity. They are similar to carpet and wood in MVTec AD and are usually found on textiles and surfaces of natural objects.
Category-3: Isotropic textures without obvious repetitive patterns. They are similar to tile and leather of MVTec AD; they do not have a clear repetitive structure. Their local structure is identical at any position and orientation.
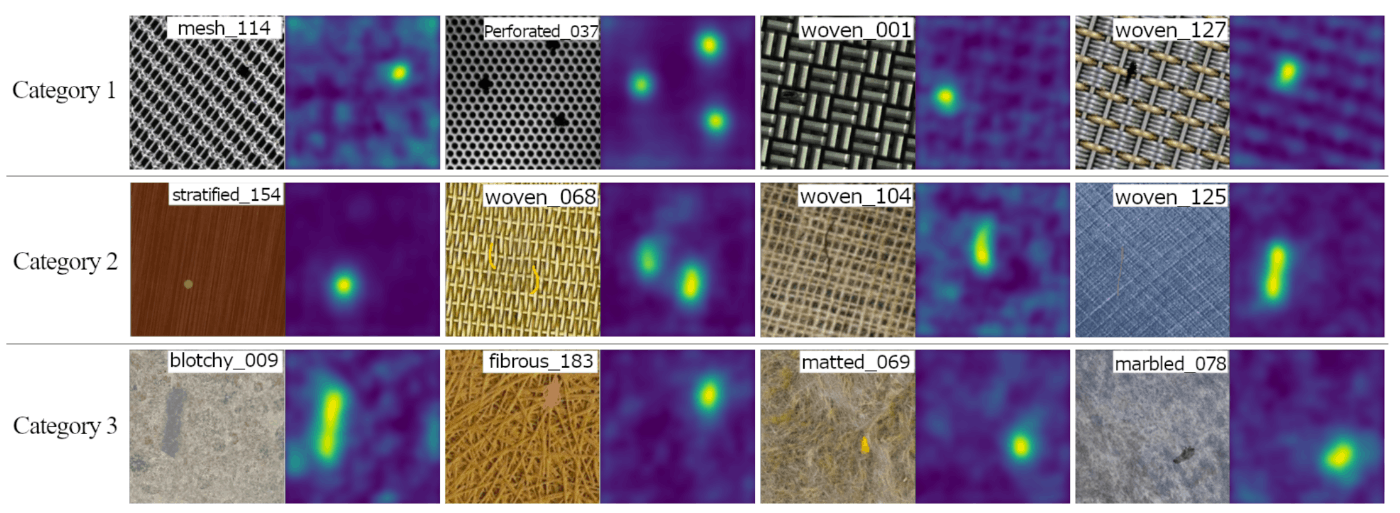
The method achieves very high accuracy on the product classes that fall under one of the above 3 categories:


Discussion