こんにちは、commmuneでデータサイエンティストをしているひぐです。
人間が苦手なマルチタスクをLLMに任せたら、効果的に処理してくれるのではないか?というモチベーションのもと、Pythonの非同期処理を使って並列かつストリーミングでChatGPTの回答を出力するアプリを作りました🤖
例えば下記は、ある課題を入力すると、深さ・広さ・構造・時間軸という異なる観点で解像度を上げてくれるアプリケーションです。
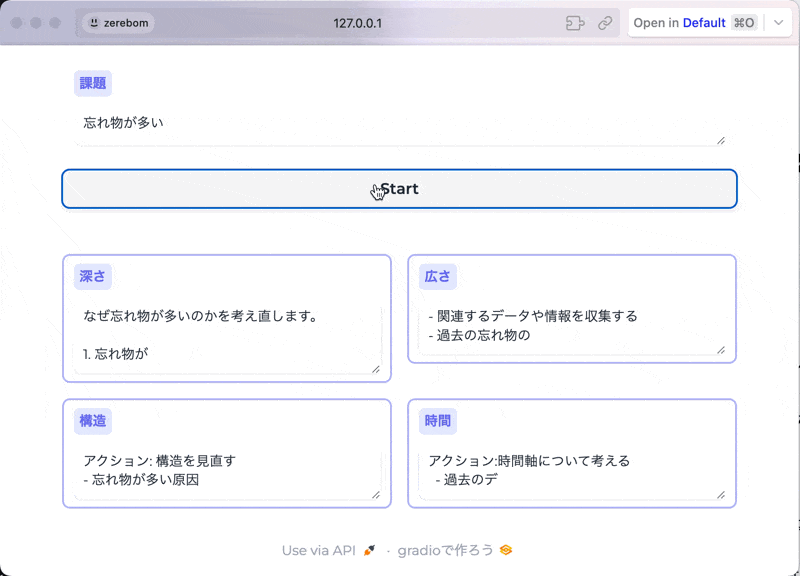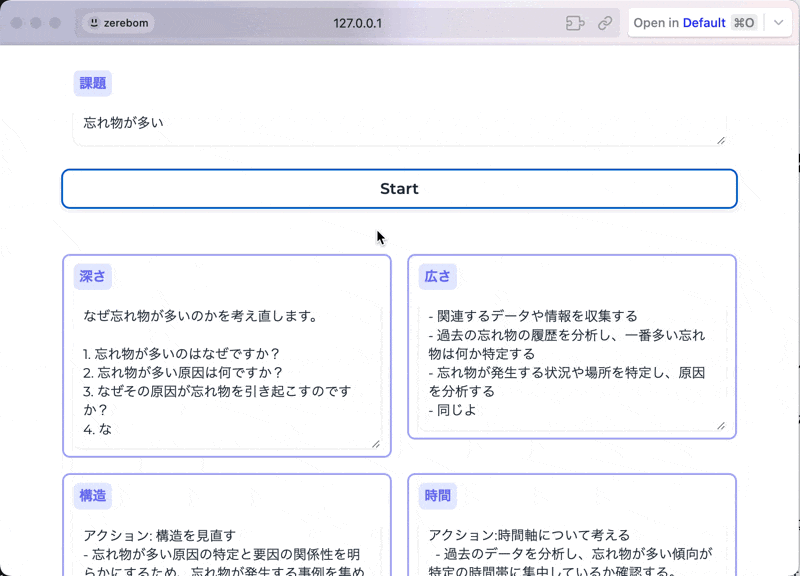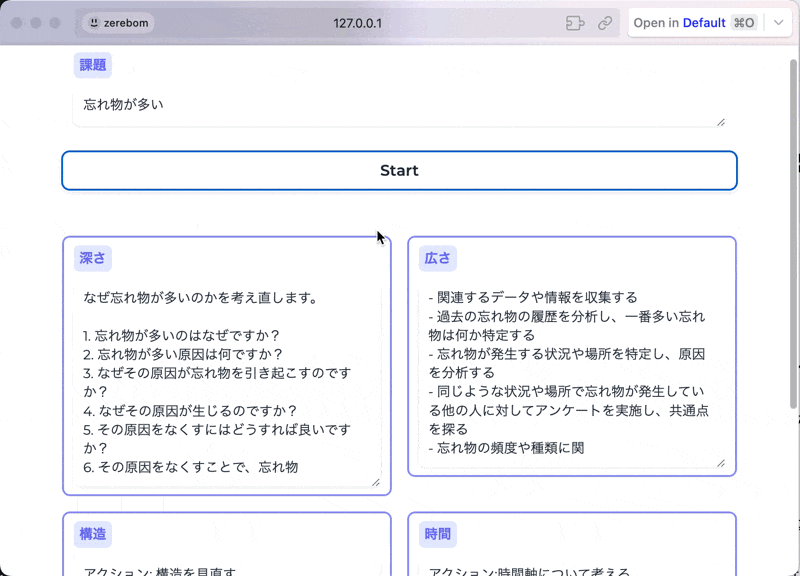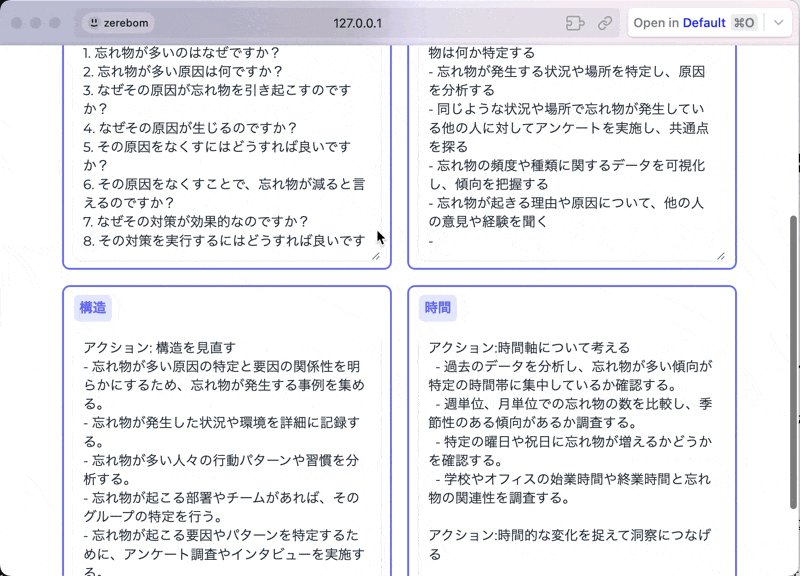
アプリに関する登壇資料↓
このアプリ作成にあたってPythonの非同期処理を勉強したところ、最初は多くの専門用語(コルーチン、イベントループ...)や独自の記法により、全体像をつかむのに苦戦しました。一方で、学んでみると予想以上にシンプルな記法で実装できること、そして応用範囲が広くて便利だと理解しました。
この記事では、そんな少し取っつきにくけど便利なPythonの非同期処理にフォーカスを当てて、基礎知識から、OpenAI APIを非同期でコールする実用例までを紹介します。
もし記事に誤りを見つけたり、疑問点があれば、ぜひコメントでご指摘いただけるとありがたいです。
非同期処理とは何か?
非同期処理とは、データベースからのデータ取得やAPIとの通信など、待ちが発生する処理を待っている間に、他の処理を進めることができる技術です。
非同期処理はスレッドやコアを複数動かすわけではないので、演算能力を直接上げるわけではないです。しかし、I/O操作など待ちが多い処理を用いる際は効果的で、アプリケーションのレイテンシやスループットを改善することができます。
Pythonではmultithredsやmultiprocessingなど他の方法で処理を並列に行えるライブラリがあります。これらの違いは下記の記事が詳しいです。
スレッド数 プロセス数 CPUコア数 区分 async 1 1 1 非同期処理 threading N 1 1 並行処理 multiprocessing 1(1コアあたり) N N 並列処理
どんなときに使えばいいのか?
非同期処理は、演算処理(CPUバウンド)よりも、外部との通信がボトルネック(I/Oバウンド)となる場合に最適です。今回のようなOpenAIのAPIに同時多発的にアクセスしたいケースなど、外部リソースとの通信で待ちが発生するシーンで効果を最大限に発揮できます。
ここでthreadingやmultiprocessingなどの並行・並列処理では、複数のコア・スレッドを活用できるので、常にこれらを使えばいいのでは?、と感じるかともいるかと思います。
しかし、これらの技術を使うと非同期処理に比べて、デバッグ・記法・エラーハンドリングが複雑になることがあります。特に、一つのリソースに対する同時書き込みや読み取りを行う場合、競合が発生しやすくなります。
ただし、非同期処理を行うには、呼び出し先の関数やライブラリが非同期に対応している必要があります。幸い、Pythonの世界では既に多くのライブラリが非同期処理をサポートしており、Webアプリケーションのバックエンド開発やデータ処理タスクなど、多岐にわたる用途で非同期処理の恩恵を享受できます。
Pythonにおける基本的な文法
ここからは具体的にPythonの文法に踏み込んで紹介します。
下記コードは、ある時間待機した後に標準出力するsay_afterメソッドを複数非同期に呼び出している例です。
import asyncio
from time import time
async def say_after(delay: int, what: str) -> None:
await asyncio.sleep(delay)
print(f"Waiting for {delay} seconds and {what}")
async def main() -> None:
st = time()
print("start")
await asyncio.gather(say_after(1, "hello"), say_after(2, "world"))
print("done:", time() - st)
asyncio.run(main())
出力は二つのsay_afterが直列でなく、非同期に実行されているため、待機時間は3秒ではなく2秒になっています。
start
Waiting for 1 seconds and hello
Waiting for 2 seconds and world
done: 2.001857042312622
このコードの主要な要素を簡単に説明します。より深く理解したい方は、Python公式ドキュメントをご覧ください。
async def(非同期関数, コルーチン)
async defを使用して定義した関数は、非同期関数と呼ばれます。これらの関数はコルーチンとも呼ばれ、処理を一時停止して後で再開できる特別な関数です。これにより、他のタスクを同時に進めることが可能になります。
await 式
await式を使うと、非同期関数内で処理の実行を一時停止し、他の処理が行われる間に待つことができます。主に、時間がかかる処理(例: API呼び出し)を待つ際に使用します。await式はコルーチンの中でしか定義できません。
asyncio.gather()
asyncio.gatherは、複数の非同期関数を同時に実行し、全てが完了するまで待つために使用します。これを使うと、複数のタスクを並行して処理でき、全体の処理時間を短縮できます。
asyncio.run()
asyncio.run関数は、非同期プログラムのエントリーポイントです。この関数を使って非同期関数を実行し、完了するまでプログラムが待機します。
イベントループ・タスク
非同期関数を実行するには、それらを管理するイベントループが必要です。イベントループは、どのタスクをいつ実行するかを決定し、タスク間での切り替えを行います。非同期関数から作られた実行単位をタスクと呼びます。
つまり、イベントループに処理を登録するために、コルーチンから生成されたオブジェクトは、タスクと呼ぶのです。(用語が多くてややこしいね...)
処理のフロー
このコードの処理のフロー・依存関係は下記の通りになります。asyncio.gatherで複数のコルーチンをまとめた後、asyncio.run()で実行し、すべての処理が終わるまで待ちます。
OpenAIへの非同期コールとストリーミングでの出力
最後に冒頭のアプリを作れるように、asyncを使ったコーディングの実用的な例を紹介します。
利用したUIライブラリ: gradio
アプリケーションのUIは機械学習に特化したアプリ作成用のライブラリである、gradioを使っています。
gradioは下記のような簡単な記法でデモアプリを作成することができます。
def greet(name: str) -> str:
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, # ← 関数(処理)をラップする思想
inputs="text", # ← 関数の入力
outputs="text") # ← 関数の出力
基本的な文法は下記の記事が詳しいです。
アプリの要件
アプリに必要な要件を定義します。冒頭のアプリのような、ユーザーが一つの問いに対して複数の角度からの解答を受け取れるような体験を実現したいです。
これには、OpenAIのAPIに直列ではなく、非同期にコールする必要があります。また、ユーザを長く待たせたくないので、出力が返ってきたら順次それをUI上にレンダリングする、ストリーミング処理を採用します。
gradioでこれを実現するには、複数の出力コンポーネントを定義し、そのコンポーネント数と同数の要素を持つtupleを出力するジェネレーターを渡す必要があります。
しかし、gradioは単一のUI上のアクション(ex. ボタンのクリック)で発火させるメソッドは単一しか受け取れません。従って、非同期にコールしてレスポンスを出力するメソッドは一つにまとめる必要があります。
これらの要件をまとめると下記の通りです。
- ユーザーの単一の入力プロンプトに対して、複数の分岐するサブプロンプトを用意し、それぞれOpenAIのAPIにはコールする
- APIへのコールはそれぞれ非同期かつストリーミング処理で出力する
- 上記のレスポンスを単一のメソッドの返り値にまとめる
- gradioには返り値が
Generator[Tuple[str]]となるメソッドを渡す
実装と解説
アプリケーション全部で100行程度のコードからなります。
コード
OpenAIへの非同期ストリーミングコール
OpenAIへの非同期コールはAsyncOpenAI()でクライアントを定義することで実現できます。
ストリーミング処理は、client.chat.completions.create(stream=True)と指定するだけでよいです。徐々にレスポンスが返ってくるので、generatorでこれまでの出力をconcatしながら出力します。
またAPIのコールは待ちが発生する処理なので、コルーチンの中でawait式で定義します。
また、OpenAIのレスポンスはAsyncGeneratorになるので、async forでfor文を定義する必要があります。
client = AsyncOpenAI()
async def fetch_gpt_response(
prompt: str, model: str = "gpt-3.5-turbo"
) -> AsyncIterator[str]:
"""
GPTからのレスポンスを非同期で取得し、内容を連結して返す。
ex) こん→こんにちは→こんにちは、元気ですか?
"""
stream = await client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt},
],
stream=True,
)
all_content = ""
async for chunk in stream:
chunk_content = chunk.choices[0].delta.content
if chunk_content is not None:
all_content += chunk_content
yield all_content
複数の非同期ジェネレーターの出力を統合する
gradioでは、一度に一つのメソッドしか実行できないため、複数の非同期ジェネレーターから得られるデータを一つにまとめる必要があります。この処理を行うためにmerge_async_iterators()メソッドを使用します。
このメソッドは、複数の非同期ジェネレーターから次々と値を取り出し、それらを一つのタプルとして返します。もし、ジェネレーター間で出力の長さが異なる場合、短いものは最後に出力した値を継続して出力します。これにより、gradioのUI上での出力が途切れることなく、すべてのジェネレーターからのデータを継続的に表示できます。
具体的にはiterable.__aiter__()でオブジェクトを初期化して、__anext__()で次の値を取得可能にしています。例えば出力1の系列の長さが1,出力2は2であるときは下記のようになります。
(output_1_1,output_2_1) → (output_1_1,output_2_2)
async def merge_async_iterators(*iterables: AsyncIterator) -> AsyncIterator[tuple[str]]:
"""
複数のAyncIteratorを受け取り、それぞれの最新の値をタプルにまとめて返す。
いずれかのAsyncIteratorが終了した場合は、その値を最後の値として返す。
すべてのAsyncIteratorが終了した場合は、処理を終了する。
"""
iterators = [iterable.__aiter__() for iterable in iterables]
last_values = [None] * len(iterators)
done_flags = [False] * len(iterators)
while not all(done_flags):
results = []
for idx, it in enumerate(iterators):
if done_flags[idx]:
results.append(last_values[idx])
continue
try:
next_item = await it.__anext__()
last_values[idx] = next_item
results.append(next_item)
except StopAsyncIteration:
done_flags[idx] = True
results.append(last_values[idx])
yield tuple(results)
gradioへのつなぎ込み
最終的に、ユーザーからの入力を受け取り、それを複数のサブプロンプトに分割して、OpenAIのAPIに非同期で問い合わせるメイン関数を定義します。この関数は、上記で説明したmerge_async_iterators()メソッドを使用して、複数の非同期ジェネレーターからの出力を一つに統合し、それらをgradioのUIに表示します。
このような手順を踏むことで、OpenAIへの非同期ストリーミングコールを実現できています。
async def main(user_prompt: str) -> AsyncIterator[str]:
detail_prompts = [
"深く考え直す。なぜ?を9回繰り返し問う。",
"広く考え直す。異なるアプローチや視点を検討する。",
"構造を見直す。原因や要因の関係性を把握する。",
"時間軸について考える。時間的な変化を捉えて洞察につなげる。",
]
gpt_responses = [
fetch_gpt_response(build_whole_prompt(user_prompt, detail_prompt))
for detail_prompt in detail_prompts
]
async for merged_responses in merge_async_iterators(*gpt_responses):
yield merged_responses
with gr.Blocks(theme=gr.themes.Soft()) as demo:
greet_btn = gr.Textbox(
label="課題", placeholder="解像度を上げたい課題を入力してください。"
)
btn = gr.Button("Start")
with gr.Row():
with gr.Column():
t1 = gr.Textbox(label="深さ")
with gr.Column():
t2 = gr.Textbox(label="広さ")
with gr.Row():
with gr.Column():
t3 = gr.Textbox(label="構造")
with gr.Column():
t4 = gr.Textbox(label="時間")
outputs = [t1, t2, t3, t4]
btn.click(
fn=main,
inputs=greet_btn,
outputs=outputs,
)
補足:gradioでなく、APIとして実現する場合
gradioでなく、APIとしてこの処理を実現する場合、FastAPIのstremingresponseというメソッドを使えば実現可能かと思います。
まとめ
この記事では、Pythonにおける非同期処理の基本から始めて、具体的にOpenAI APIを非同期に呼び出す実装方法について紹介しました。
レイテンシがあるOpenAI APIを有用に使うためには非同期かつストリーミングで処理したいケースも多いと思います。少しでも参考になったら嬉しいです!では〜
参考資料

Discussion
純粋な疑問なのですが、streamlit で同様の実装をする方法はありますでしょうか。