この記事について
この記事は、UnJSの主要なライブラリを調査していくシリーズ記事の1つになります。
シリーズ記事の概要や今後公開される予定の記事の確認はこちらの記事を参照してください。今回はradix3というライブラリについて紹介します。
radix3の特徴
radix3(unjs/radix3)は軽量で高速なルーターで、基数木(英: Radix tree)というデータ構造に基づいて実装されています。シリーズ記事の前回の記事で紹介したH3ライブラリのルーター部分で使われています。Charlie Duong氏により開発されたRadix Routerというライブラリを基にして実装されています。
radix3の主要な特徴として、次のものがあります:
- 基数木というデータ構造に基づいて実装された軽量で高速なルーター
- パスをキーにしてデータを格納したり、取り出したりすることができるRouterを提供
-
Routerに格納したデータを全探索して取り出すためのMatcherを提供 (※ なぜMatcherが提供されているのかは後述します)
radix3の説明をする前に、木構造と基数木について説明します。
木構造
基数木は木構造の一種であるため、最初に木構造について説明します。木構造(英: Tree)は図1のように個々のデータが親子関係を持った0個以上の子データを持ち、木が階層毎に分岐していくようなデータ構造になります。木構造を構成する個々の要素をノード、ノード間の関係をエッジと呼びます。
木構造の最上位の階層の親を持たないノードを根ノード、末端にある子ノードを持たないノードを葉ノード、そして子ノードを持つノードを内部ノードと呼びます。親ノードと子ノードの距離を1とした場合、根ノードから葉ノードまでの最大距離を木の高さと呼びます。このことから、図1の木構造の木の高さは3になります。
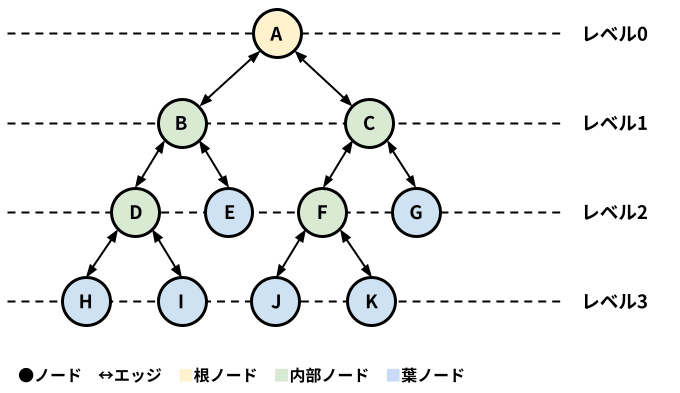
図1: 木構造のデータ構造と用語
木構造の種類
木構造には様々な種類があり、代表的なものは次のものがあります:
- 二分木 (英: Binary tree): 各ノードが2つの子ノードしか持たないデータ構造になります
- 多分木 (英: Multi-branch tree): 二分木は2つの子ノードしか持ちませんが、多分木は3つ以上の子ノードを持つデータ構造になります
- トライ木 (英: Trie tree): 各ノードがデータとして1つの文字列を格納するデータ構造になります。
この記事で紹介する基数木は、トライ木の一種に分類されます。
基数木
基数木はトライ木の一種で、各ノードに文字列を格納するデータ構造になります。トライ木との違いとして、各ノードに格納する文字列を1文字以上の任意の長さにすることができます。ウェブアプリケーションは、ディレクトリ構造によって階層化されたパスを持つことが一般的です。複数文字列を1つのノードとして扱うことが可能な基数木は、最も効率的にパスを格納し、探索することができるデータ構造になります。
基数木がradix3にどのように応用されているのか、Twitter APIのいくつかのエンドポイントのパスを用いて説明します。
Twitter APIの中から次のエンドポイントを使用して、radix3にデータを格納してみます。
/tweets/tweets/:id/tweets/counts/all/tweets/counts/recent/users/:id/bookmarks/users/:id/likes/users/:id/tweets
エンドポイントのパスがどのように格納されるかを説明するのが目的なので、HTTPメソッドは考慮していませんが、これらのパスをradix3に格納すると、図2のようになります。
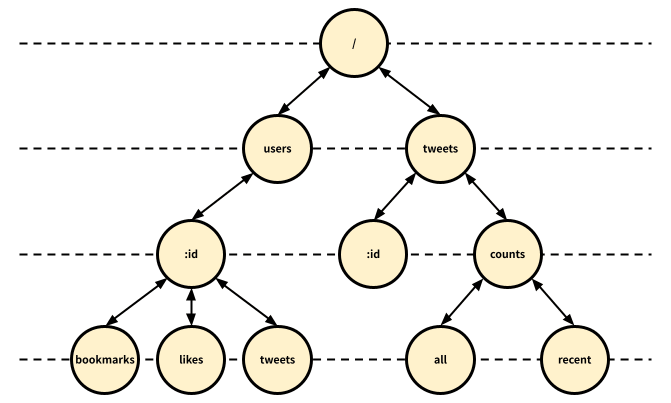
図2: Twitter APIをradix3に格納した時のデータ構造
パスを/で分割して、パスセグメント毎にノードが割り当てられています。ディレクトリによって階層化される一般的なウェブアプリケーションにおいて、各ノードが1つの文字列しか格納できないトライ木より、パスセグメント毎に1つのノードとして扱うことができる基数木の方が効率的にデータを格納できていることが図2からも分かります。
次からRouterとMatcherの使い方について説明します。
Router
Routerはパスをディレクトリ階層毎に分割し、パスセグメントをキーとしてデータを格納します。次のようにcreateRouter関数を使って初期化します。
import { createRouter } from "radix3";
const router = createRouter();
createRouter関数はオプションを渡して初期化することもできます。
const router = createRouter({
strictTrailingSlash: true,
routes: {
"/foo": {},
},
});
strictTrailingSlashにtrueを渡すと、パスの末尾のスラッシュの有無は厳密に判定されます。(デフォルトはfalseになり、末尾のスラッシュは取り除かれた上で挿入されます)
routesに渡すオブジェクトは、パスと格納するデータのセットを初期化の段階で指定することができます。
初期化したrouterインスタンスは、insert、lookup、removeの3つのメソッドを提供しています。
データを格納するには、insertメソッドの第1引数にパス、第2引数に格納するデータを渡して呼び出します。格納するデータは任意のオブジェクトを渡すことができますが、paramsプロパティは予約されていて使うことができません。
router.insert("/hello", { payload: "Hello world!" });
格納したデータを探索するには、lookupメソッドにパスを渡して呼び出します。該当するパスが存在すると、格納しているデータが返却されます。
router.lookup("/hello");
// => { payload: "Hello world!" }
格納したデータを削除するには、removeメソッドにパスを渡して呼び出します。削除に成功するとtrueが返却され、以降はlookupメソッドで削除済みのパスを探索してもnullが返却されます。
router.remove("/test");
// => false (存在しないパスを削除すると、falseが返ってきます)
router.remove("/hello");
// => true (削除に成功すると、trueが返ってきます)
router.lookup("/hello");
// => null
Placeholder (:)
Placeholderは、パスの一部をパラメータとして受け取るための記述方法で、次のサンプルコードのようにパスセグメントの文字列の先頭にコロン(:)を使って記述します。Placeholderによって指定したパスセグメントは、任意の文字列に該当します。
lookupメソッドを呼び出して該当するパスが存在すると、格納しているデータのparamsプロパティに結果を詰めて返却します。結果として返却されるオブジェクトは、パスセグメントのコロンを取り除いた残りの文字列がキーになり、探索に使われて実際に該当したパスセグメントの文字列が値になります。
router.insert("/hello/:word", { payload: "named route" });
router.lookup("/hello/world");
// => { payload: "named route", params: { word: "world" } }
router.lookup("/hello/everyone");
// => { payload: "named route", params: { word: "everyone" } }
router.insert("/test/:foo/:bar", { payload: "named route" });
router.lookup("/test/foo/bar");
// => { payload: "named route", params: { foo: "foo", bar: "bar" } }
また、ドキュメントには小さくしか書かれていませんが、アスタリスクを1つ(*)使う方法も存在しています。この方法を使う場合は、paramsのキーはパスの階層順にインクリメントされ、次のサンプルコードのようなデータとして返却されます。
router.insert("/test/*/*", { payload: "named route" });
router.lookup("/test/foo/bar");
// => { payload: "named route", params: { _0: "foo", _1: "bar" } }
Wildcard (**)
Wildcardは、パスセグメントにアスタリスクを2つ(**)繋げて記述することで、以降のパスを全てマッチさせて、パラメータとして受け取ることができます。以降のパスを全てマッチさせることからパスの一番最後のパスセグメントとして指定します。paramsのキーは_になり、次のサンプルコードのようなデータが返却されます。
router.insert("/test/**", { payload: "wildcard route" });
router.lookup("/test/foo");
// => { payload: "wildcard route", params: { _: 'foo' } }
router.lookup("/test/foo/bar");
// => { payload: "wildcard route", params: { _: 'foo/bar' } }
Shadowed route
Shadowed routeは、radix3でRouterが提供されているのになぜMatcherも提供されているのか疑問に思って調査していく際に、H3のソースコード内で発見した仕様になります[1]。日本語に翻訳すると隠されたルートと言ったところでしょうか。
H3のルーターは、次のサンプルコードのようにHTTPメソッドが異なる同じパスに対して、それぞれにイベントハンドラを登録することができます。全てのHTTPメソッドのリクエストを受け取るuseメソッドに渡したパスは、Wildcardを使って記述しているため、/hello/worldのパスに該当します。Shadowed routeは、このような条件で問題になります。
import { createRouter, eventHandler } from "h3";
const router = createRouter()
.post("/hello/world", eventHandler(() => "[POST] /hello/world"))
.delete("/hello/world", eventHandler(() => "[DELETE] /hello/world"))
.use("/hello/**", eventHandler(() => "[ALL] /hello/**"));
H3サーバーを起動して、次のようなリクエストを送ります:
$ curl -X POST http://localhost:3000/hello/world
[POST] /hello/world
$ curl http://localhost:3000/hello/world
[ALL] /hello/**
GETリクエストに対しては、サンプルコード1のrouter.useで登録したイベントハンドラが処理され、レスポンスを返却しています。
H3のRouterは、内部的にradix3のRouterを使っています。サンプルコード1のようなルーティングの実装をすると、次のサンプルコード2のようにhandlersプロパティにHTTPメソッドをキーとしてイベントハンドラが格納されます。
import { createRouter } from "radix3";
const router = createRouter()
.insert("/hello/world", {
handlers: {
post: handler, // このhandlerは、`[POST] /hello/world`を返すイベントハンドラ
delete: handler, // このhandlerは、`[DELETE] /hello/world`を返すイベントハンドラ
},
})
.insert("/hello/**", {
handlers: {
all: handler, // このhandlerは、`[ALL] /hello/**"`を返すイベントハンドラ
},
});
H3サーバーは、/hello/worldに対してGETリクエストを受け取ると、radix3のrouterインスタンスのlookupメソッドに/hello/worldを渡して呼び出します[2]。そして、lookupメソッドの返り値の中からGETリクエストのイベントハンドラを取り出そうとします[3]。
この2つの処理を簡略して説明的に書くと次のようになります:
const matched = router.lookup('/hello/world');
// => { handlers: { post: [Function], delete: [Function] } }
const handler = matched.handlers['get'];
// => undefined
1行目のlookupメソッドによって返却される返り値は、router.insert("/hello/world")で登録した値になります。探索処理がどのように行われているのかradix3のソースコードを読むと、insertメソッドでデータを格納する時にPlaceholderやWildcardが使われていないパスを指定しない場合、routerインスタンスのデータ構造に対してデータを格納しますが、staticRoutesMapというMapオブジェクトにもデータを追加します[4]。
パスにPlaceholderやWildcardがない場合、データ構造を探索するよりもMapオブジェクトから取り出したほうが処理速度として早いため、このような処理が行われています。lookupメソッドの処理の一番最初にstaticRoutesMapにパスが存在するかを確認していることがソースコードから分かります[5]。
このことから、router.insert("/hello/world")から返却される返り値の中には、GETリクエストを処理するイベントハンドラはありません。H3サーバーとしては、該当するパスは存在するが処理をするためのイベントハンドラが存在しないのはイレギュラーなことで、これを解決する手段として、radix3はrouterインスタンスに格納された全てのパスを探索するMatcherを提供しています。H3はフォールバック処理として、このMatcherを使っています。
Matcher
Matcherは、radix3が提供しているRouterをHTTPサーバーのルーティングとして使用する場合、先程説明したShadowed routeの問題が発生するため、別途提供されている機能になります。Matcherは、Routerに登録された全てのパスを探索し、マッチするものを全て返すmatchAllというメソッドを提供しています。
Shadowed routeのサンプルコードのrouterインスタンスをtoRouteMatcher関数に渡して初期化します。次のようにmatchAllメソッドに探索するパスを渡すことで結果を得ることができます。
import { toRouteMatcher } from "radix3";
const matcher = toRouteMatcher(router);
const matches = matcher.matchAll("/hello/world");
console.log(matches);
// [
// { path: '/hello/world', handlers: { post: [Function], delete: [Function] } },
// { path: '/hello/**', handlers: { all: [Function] } }
// ]
調査しながら思ったこと
ブラウザ側のルーティングはどうなっているか?
radix3自体は、UnJSの哲学に基づき、NuxtやVue.jsとの依存はありません。しかし、NuxtはHTTPサーバーのライブラリとしてH3を使っていて、その内部でradix3のルーターを使っています。そして、ブラウザ側で動くルーターライブラリにVue Routerを使っています。
Vue Routerのソースコードを簡単に読んでみると、あらかじめ想定していたとおり、radix3は使われていません。サーバーサイドのルーティングで求められる要件として、1台のサーバー辺りのスループットが重要になるため、高速に動作することが重要になりますが、ブラウザサイドでは、処理はユーザーの個々のブラウザ上で行われるため、radix3を使わなくても十分な速度で動作すると思います。
しかし、まだ調査が不十分なので推測で書きますが、Vue RouterとH3(radix3)のルーティングの記法で異なる仕様や挙動がある場合、サーバーサイドとブラウザサイドの違いを吸収するためにNuxtがどのような処理をしているのか気になりました。
ライブラリの責務
radix3を調査してみて、H3とradix3がそれぞれどのように責務を分けるとより良いのかなと思いました。radix3は元々、Radix Routerという元になったライブラリがあり、それに倣ってradix3がルーター機能を提供しています。そしてradix3が提供するルーター機能にH3のルーティングに必要な機能を拡張しているため、(今回の事情がなかったとしても必要な機能かもしれませんが、H3のRouterの機能を満たすためにMatcherが存在しているように見えています。
今回調査してみて、木構造以外にもスタック・キューやヒープ等の様々なデータ構造が存在することが分かりました。radix3で提供しているルーター機能をH3に移して、radix3はデータ構造全般を扱うライブラリにすると、責務としてスッキリし、尚且つUnJSの哲学との親和性もさらにあがるのかなと思いました。(その場合、radix3という名前を変える必要が出てきますが...)
参考

Discussion
参考情報: h3のルーターが新しいライブラリに変わります