depth-wise Convを用いた条件付き位置エンコーディング(Conditional Positional Encoding; CPE)について
Xを見てたら以下ツイートを見かけた。
入力が画像に対してVision Transformer(ViT)は明示的に位置エンコーディングを行うが、CNNはConv操作で画像の外側のpaddingの情報から暗黙的に位置情報を伝えている。
CNNの絶対位置エンコーディングに関して、"How Much Position Information Do Convolutional Neural Networks Encode?"[Islam+ 2020]で検証された。日本語資料は宮澤さんのこのスライドがおすすめ。
このトピックではFastViT[Vasu+ 2023]などでも用いられているdepth-wise Convを用いた条件付き位置エンコーディング(Conditional Positional Encoding; CPE)を簡単に解説する。
Conditional Positional Encodingとは?
CPEは"Conditional Positional Encodings for Vision Transformers"[Chu+ 2021]で提案された通常の位置エンコーディングとは異なり、動的かつ入力トークンの局所近傍に依存する位置エンコーディングである。これにより高解像度画像などトークン長が大きく増加する場合でも汎化性が高い。
このPosition Encoding Generator(PEG)はシンプルに記述することができて、シンプルにdepth-wise Convを加えるだけである。以下論文中の実装でgithubはこちら:
import torch
import torch.nn as nn
class VisionTransformer:
def __init__(self, layers=12, dim=192, nhead=3, img_size=224, patch_size=16):
self.pos_block = PEG(dim)
self.blocks = nn.ModuleList([TransformerEncoderLayer(dim, nhead, dim * 4) for _ in range(layers)])
self.patch_embed = PatchEmbed(img_size, patch_size, dim * 4)
def forward_features(self, x):
B, C, H, W = x.shape
x, patch_size = self.patch_embed(x)
_H, _W = H // patch_size, W // patch_size
x = torch.cat((self.cls_tokens, x), dim=1)
for i, blk in enumerate(self.blocks):
x = blk(x)
if i == 0:
x = self.pos_block(x, _H, _W)
return x[:, 0]
class PEG(nn.Module):
def __init__(self, dim=256, k=3):
super().__init__()
self.pos = nn.Conv2d(dim, dim, k, 1, k // 2, groups=dim) # Only for demo use, more complicated functions are effective too.
def forward(self, x, H, W):
B, N, C = x.shape
cls_token, feat_tokens = x[:, 0], x[:, 1:]
feat_tokens = feat_tokens.transpose(1, 2).view(B, C, H, W)
x = self.pos(feat_tokens) + feat_tokens
x = x.flatten(2).transpose(1, 2)
x = torch.cat((cls_token.unsqueeze(1), x), dim=1)
return x
また、CLSトークンを除いてGlobal Average Pooling(GAP)で画像特徴ベクトルを抽出するNNにすると並進不変な構造であり、画像分類精度も向上した。
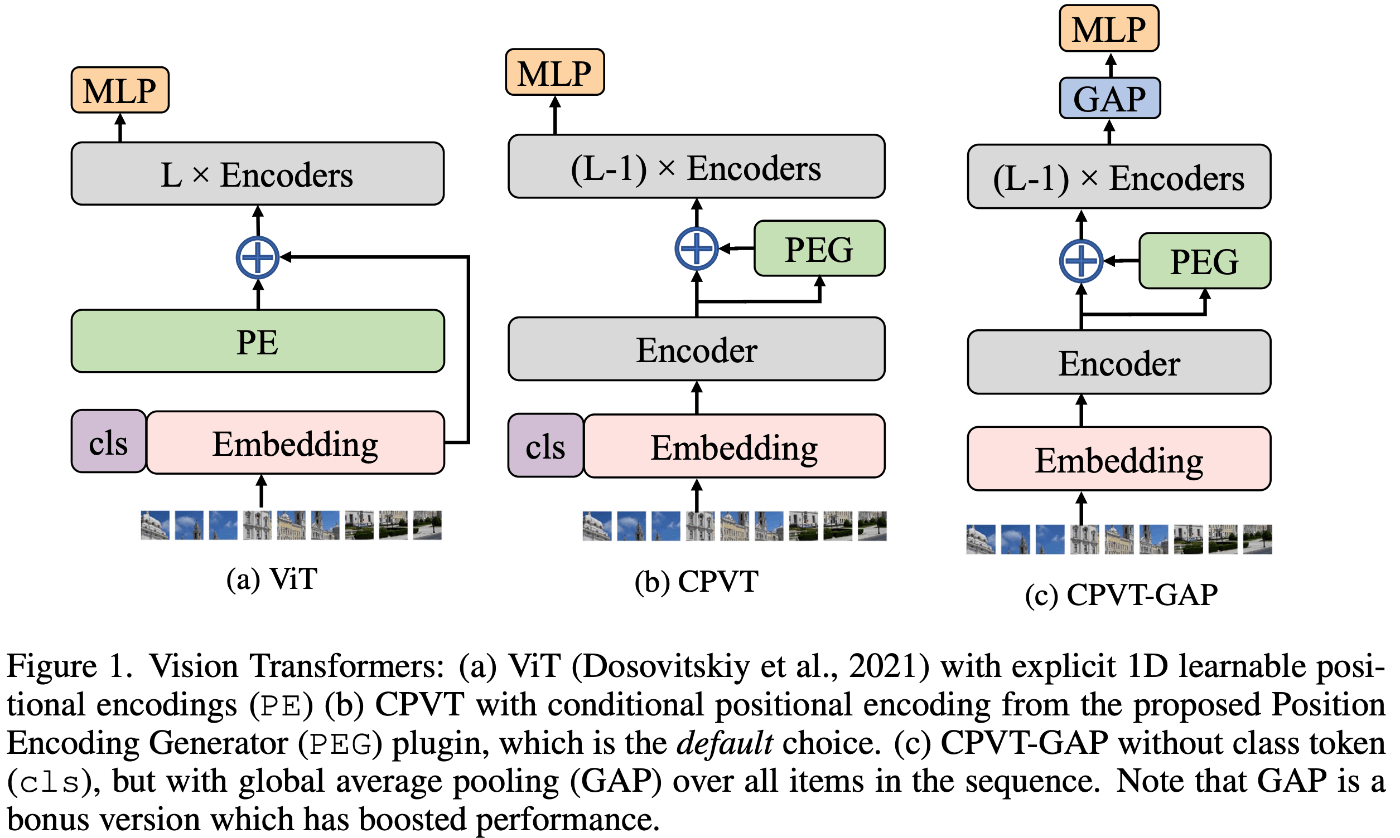
[Chu+ 2021]より引用
ViTベースの物体検出やセグメンテーションタスクを行うPVTv2[Wang+ 2022]は、Fead-Forward Network(FFN)にdepth-wise Convを追加したConvolutional Feed-Forward Networkを追加し、位置エンコーディングを除くことを可能にした。
FastViT[Vasu+ 2023]は、ViTと名前があるが構造の大部分はMobileNet系の派生モデルでConvが多くを占める。具体的に、Stage1からStage3はMobileNet[Howard+ 2017]、MobileNetV2[Sandler+ 2018]で提案されたDepthwise Separable Convolutionをもとに構築されている。学習時と推論時はネットワーク構造が変化するが、これはMobileOne[Vasu+ 2023]のre-parameterizationによるもの(この話もかなり面白い)。
Stage4はTransformerのself-attentionやdepth-wise ConvによるRepMixerが採用される。この際の位置エンコーディングとしてCPEや、PVTv2のConvolutional Feed-Forward Netowkに近いConvFFN構造が用いられる。
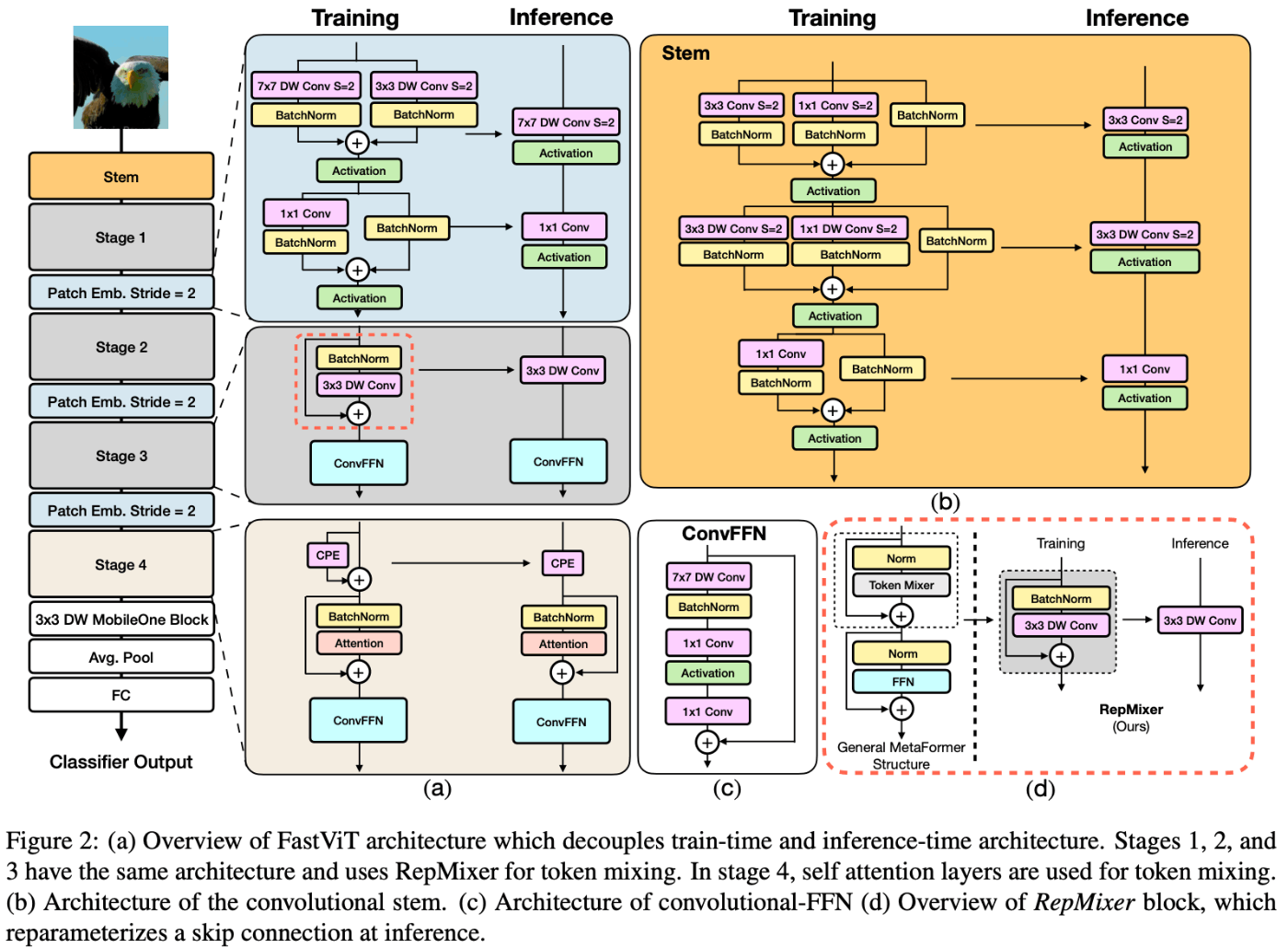
[Vasu+ 2023]より引用
なお、ここまでの話の一部はyu4uさんの近年のHierarchical Vision Transformerにも載っているためそちらも参照。
まとめ
CNN自体も位置情報が符号化されているが、depth-wise Convを用いることで条件付き位置エンコーディング(CPE)が可能である。CPEは物体検出やセグメンテーションなどの(絶対)位置情報が必要なタスクでも十分な性能を示し、入力画像サイズが変化してもロバストに位置情報を付与することができる。ただ絶対位置情報が必要なタスクで議論した結果を見ていないため調べたい。
参考
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
- Islam, M. A., Jia, S., & Bruce, N. D. (2020). How much position information do convolutional neural networks encode?. arXiv preprint arXiv:2001.08248.
- Vasu, P. K. A., Gabriel, J., Zhu, J., Tuzel, O., & Ranjan, A. (2023). FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization. arXiv preprint arXiv:2303.14189.
- Chu, X., Tian, Z., Zhang, B., Wang, X., Wei, X., Xia, H., & Shen, C. (2021). Conditional positional encodings for vision transformers. arXiv preprint arXiv:2102.10882.
- Wang, W., Xie, E., Li, X., Fan, D. P., Song, K., Liang, D., ... & Shao, L. (2022). Pvt v2: Improved baselines with pyramid vision transformer. Computational Visual Media, 8(3), 415-424.
- Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., ... & Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
- Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., & Chen, L. C. (2018). Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4510-4520).
- Vasu, P. K. A., Gabriel, J., Zhu, J., Tuzel, O., & Ranjan, A. (2023). MobileOne: An Improved One Millisecond Mobile Backbone. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7907-7917).
- Kazuyuki Miyazawa. How Much Position Information Do Convolutional Neural Networks Encode? https://www.slideshare.net/KazuyukiMiyazawa/how-much-position-information-do-convolutional-neural-networks-encode
- Yusuke Uchida. 近年のHierarchical Vision Transformer https://www.slideshare.net/ren4yu/hierarchical-vision-transformer