はじめに
株式会社CoeFontで、エンジニアリングマネージャーをしているsugasugaです。
本ブログでは、下記の流れで、「推論結果を迅速に提供する技術」と「推論の信頼性向上を実現する技術」についてご紹介します。
- MLOpsの定義
- 弊社におけるMLOps
- 推論結果を迅速に提供する技術
- 推論の信頼性向上を実現する技術
MLOpsの定義
MLOps(Machine Learning Operations) とは、機械学習モデルの開発、運用、継続的改善までのプロセスを効率化・自動化する手法です。実際の運用現場では、モデル自体のコードはシステム全体のごく一部に過ぎず、多くはインフラや連携を担うプログラミングコードなど、複雑に絡み合う周辺システムで構成されています。
以下の図は、機械学習システムにおけるコードの構成比率を示しており、機械学習アルゴリズムや学習プロセスに関する部分が小さな黒い箱で表現され、残りは周辺システムが占める部分が多い様子を視覚的に表現しています。
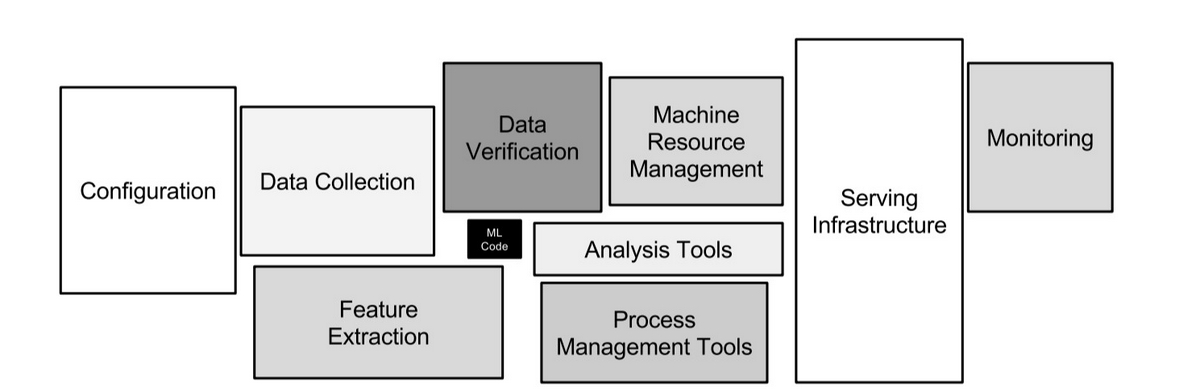
Hidden Technical Debt in Machine Learning Systemsのfigure1より引用
弊社におけるMLOps
CoeFont Cloud
音声合成技術を基盤とするクラウドプラットフォームを提供し、ユーザーが高品質な音声サービスを手軽に利用できる環境を実現しています。
CoeFont 通訳
AI技術を活用した通訳ソリューションを展開し、言語の壁を越えたコミュニケーションをサポートするサービスを提供しています。
両サービスを提供するチームの裏側で、MLOpsチームが機械学習サービスを提供しています。
弊社においては、特にServing Infrastructure は、機械学習モデルを本番環境で安定的かつ効率的に提供するための中核部分として重要な役割を果たし、ソフトウェアエンジニアリング面で多くの課題に取り組んでいます。
今回は、推論結果を迅速に提供する技術と、推論の信頼性向上を実現する技術についてご紹介します。
推論結果を迅速に提供する技術
推論結果を迅速に提供する技術を解説します。迅速なレスポンスは、ユーザー体験の向上に直結します。
FastAPIの非同期処理エンドポイントを活用する
Web APIを実装する際、リクエストに対するレスポンス速度は非常に重要です。
非同期処理を活用することで、外部サービスへのアクセス、ファイル操作、データベースとの通信など、I/O待ちが発生する処理を効率的に実行でき、全体のパフォーマンスを向上させることが可能です。
まずは、非同期処理ではなく、FastAPIの同期処理エンドポイントから解説します。
同期処理エンドポイント
同期処理エンドポイントの例は下記になります。
この例では、リクエストがあるたびに hello 関数が呼び出され、その結果がレスポンスとして順次返されます。
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def hello():
return {"Hello": "World"}
下記の図は、FastAPIサーバーが複数のHTTPリクエストを受け取った場合の、ワーカースレッドによる同期処理の流れを示しています。この図解では
- リクエスト1をワーカースレッド1で行い、レスポンスが返されます。
- リクエスト2をワーカースレッド2で行い、レスポンスが返されます。
同期処理の場合、リクエストを受けたスレッドは処理が完了するまでブロックされます。たとえば、外部サービスとの通信やデータベースクエリといったI/Oバウンドの処理が発生すると、そのスレッドは応答が返るまで待機状態になり、他の処理は行われません。
FastAPIは、GunicornなどのWebサーバーと組み合わせて利用することが推奨されており、公式ドキュメント参照ではワーカー数を「CPUコア数 × 2 + 1」に設定することが推奨されています
これにより、複数のFastAPIが立ちあげ、並列でのリクエスト処理が可能になります。また、各ワーカーで設定されるスレッド数(Python3.12だとmin(32, (os.process_cpu_count() or 1) + 4)。参照)がパフォーマンスに影響を与えます。
しかし、プロセスやスレッド間のコンテキストスイッチには高いオーバーヘッドが伴うため、数を増やすことがパフォーマンスが向上するとは限らず、大量のリクエストを処理する際には限界が生じる可能性があります。
非同期処理エンドポイント
そこで使うのが、非同期処理です。同期処理エンドポイントの例は下記になります。
この例では、hello 関数は非同期関数として定義され、await asyncio.sleep(1) により1秒間待機しています。
from fastapi import FastAPI
import asyncio
app = FastAPI()
@app.get("/async")
async def hello():
await asyncio.sleep(1)
return {"message": "This is an async response"}
FastAPI上では、イベントループが各非同期タスクの進捗を管理します。例えば、I/O待ち中に他のタスクを実行することで、全体のパフォーマンスが向上する可能性があります。また、タスク間の切り替えはコンテキストスイッチよりもはるかに低負荷です。
非同期処理エンドポイントの注意点
しかし、注意する点もあります。パフォーマンスの大幅な悪化を防ぐために、非同期エンドポイントの中で、同期処理を行ってはいけません。
下記の図は、FastAPIが複数のHTTPリクエスト(短いI/Oと長いI/O)を受け、同期処理がイベントループ上でブロックするため、タスクの開始が遅れている状態を示しています。
非同期に対応していないライブラリ (ie. boto3)などは、別のライブラリ(ie. aiboto3)に切り替えたり、無理やりイベントループから、外部スレッドプールのスレッドに処理を退避させて実行するなど、徹底的に非同期にする必要があります。外部スレッドプールのスレッドに処理を退避させる例は下記です。
import asyncio
import concurrent.futures
import time
def sync_inference(input_data):
# ここでは2秒間のスリープで重い処理をシミュレーション
time.sleep(2)
return f"同期推論結果: {input_data}"
async def run_sync_inference_in_threadpool(input_data):
loop = asyncio.get_running_loop()
# ThreadPoolExecutor を利用して、同期処理を非同期的に実行
with concurrent.futures.ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(executor, sync_inference, input_data)
return result
async def main_sync():
result = await run_sync_inference_in_threadpool("サンプルデータ")
print(result)
非同期処理は、実装の複雑さやレビュー負荷の増大という側面や、実装ミスによるパフォーマンス悪化という側面もあるため、性能向上のメリットとこれらのコストとのバランスを考慮して、適切な手法を選択することが重要です。
FastAPIにおける同期処理と非同期処理の特徴やパフォーマンスの違いをより深く理解するために、以下の資料がおすすめです。
-
Pycon 2024 FastAPIでのasync defとdefの使い分け
「FastAPIでのasync/defとdefの違い:非同期を使うならいつ使わないのか」では、同期処理と非同期処理の基本概念やそれぞれの実装上のメリット・デメリットが丁寧に解説されています。 -
FastAPIでasync defとdefをちゃんと使い分ける
こちらの記事では、非同期処理内での同期処理がブロッキングを引き起こすのか、また同期処理をスレッドプールにオフロードすることでパフォーマンスが向上するかどうかの検証結果が示されています。実際の検証結果に基づいた実践的な知見が得られるため、パフォーマンス改善のヒントになります。
これらの資料を参照することで、FastAPIの同期処理と非同期処理の適材適所な使い分けや、パフォーマンス向上のための具体的な手法について、より深い理解を得ることができるでしょう。
Server Sent Eventで通信する
Server Sent Eventとは
従来のHTTP通信は、リクエストごとに一度だけレスポンスを返す仕組みです。すべての機械学習による推論処理が完了してから、応答が返されます。
対して、Server Sent Event(以下SSE)はサーバーからクライアントへの一方向のストリーミングに特化しており、実装がシンプルでリソース効率が高く、モデル推論結果などの逐次的なデータ送信に最適です。例えばChatGPTなどで使われています。下記は、SSEを利用して、サーバーから文字列がリアルタイムに送信される様子を示しています

モデルの推論結果をストリーミングで返す場合、SSE を活用すると、部分的な結果を早期に表示でき、ユーザーエクスペリエンスが向上します。以下は、サーバーからクライアントへ文字列データをリアルタイムに送信する例です。
詳細な仕様については、MDNの公式ドキュメントなども参考にされると良いでしょう.
Server Sent Eventのエラーハンドリング
SSE では、接続が正常に確立されるとサーバーは HTTP ステータスコード200(OK)を返し、クライアントへ継続的なイベント送信が可能な状態となります。
一方、データの送信中にエラーが発生した場合は、HTTPステータスコード以外の方法でエラー情報を伝える必要があります。弊社では、例えば以下のような形式でエラー情報を送信し、クライアント側で適切にハンドリングできるようにしています。
{"event": "error", "data": "invalid-request-error"}
全体のコード例は次のようになります。
from fastapi import FastAPI
from sse_starlette.sse import EventSourceResponse
import asyncio
app = FastAPI()
def fakeLLM_generator():
messages = [
"これはServer Sent Eventのテスト文章です。",
"この文章は、LLMの出力を模倣するために作られた長文であり、",
"様々な情報が盛り込まれています。",
"ランダムなタイミングで切り取られることにより、",
"部分的な情報の伝達が行われます。",
"まるで実際の会話のように、途中で途切れることもありますが、",
"全体としては一貫した内容を持っています。",
"これにより、ユーザーは逐次的なデータの受信を体験することができます。",
"さらに、このテストはシステムのストリーミング機能を確認するためのものです。",
"出力が途中で切れても、後続のメッセージで続きが送られます。"
]
for msg in messages:
yield msg
async def event_generator():
try:
llm_iterator = fakeLLM_generator()
yield {"event": "start", "data": "開始します"}
for message in llm_iterator:
yield {"data": message}
await asyncio.sleep(1)
yield {"event": "complete", "data": "送信完了"}
# 何かしらのクライアントエラー
except CustomClientError as e:
yield {"event": "error", "data": "invalid-request-error"}
# それ以外のエラー
except Exception as e:
yield {"event": "error", "data": "unknown-error"}
@app.get("/sse")
async def sse_endpoint():
return EventSourceResponse(event_generator())
中間層なしでのリクエストの処理
システムアーキテクチャとして、よく見られる形態は「クライアント ⇔ バックエンド ⇔ 推論エンドポイント」という構成です。
これは、従来のバックエンド ( ie. 登録・認証・決済)と複雑な推論システムとの役割を明確に分離することで、システム全体の管理性や拡張性を向上させるアプローチとなっています。
弊社では、クライアントが直接Resourceサーバー(推論サーバー)からレスポンスを受け取る方式へ変更している箇所があります。初回の認証はAuthorizationサーバー(通常のバックエンド)で実施され、その後の各リクエストでは、ResourceサーバーがJWS署名の検証を行い、リソースを返却します。この仕組みにより、不要な仲介層を排除し、通信経路を短縮することで、応答速度および全体パフォーマンスが大幅に向上します。
なお、ユーザー認証にはJWS認証を採用し、高速な検証を実現しています。以下のシーケンス図は、新しいフローを示しています。
このアーキテクチャでは、各リクエストがデータベースにアクセスする頻度が減少するため、システム全体の応答速度が向上します。
推論の信頼性向上を実現する技術
システムの信頼性を向上させるためのモニタリング、エラーハンドリング、インフラ管理などの取り組みについて説明します。たとえ高速な推論結果を提供できるシステムであっても、信頼性が担保されなければユーザーの信頼を得ることは難しいため、信頼性向上は高速応答施策と連動して、全体のサービス品質を支える重要な要素となります。
各種モニタリングツールを活用する
アプリケーションモニタリング・インフラ監視・外形監視
Sentryはアプリケーションモニタリング(APM)ツールとして、発生したエラーをリアルタイムにキャッチし、詳細なコンテキスト(スタックトレース、ユーザー情報、環境情報など)を提供します。料金もかなり抑えめに利用できます
- エラー発生時のスタックトレースの表示
- エラー時のリクエストペイロードの表示
- 影響を受けたユーザー数の表示
- 問題が疑われるリリースの表示
- 一定の閾値を超えるエラーに対する通知
- 特定エンドポイントのエラー率・パフォーマンスの表示
- リクエストのプロファイリングの表示
音声合成AIの場合、本番環境でのユーザーからのさまざまな文字入力がなされ、予期せぬエラーを吐いているケースがあります。ペイロードを詳細に確認できる機能は、問題発生から発見・解決までの時間短縮に大いに役立っています。

また、弊社ではDatadogも用いています。
料金は相対的に高いですが、インフラ、アプリケーション、ログ、メトリクス、トレースなどを一元管理でき、さまざまな機能を提供しています。
監視という観点だと、Datadog Synthetic Monitoringを用いたAWSネットワーク外からの監視により、システム全体が正常に動作しているかを継続的にチェックしています。
SLOの設計とSLIの確認
-
SLI
SLIは、サービスのパフォーマンスや品質を数値で表現する指標です。具体的には、システムの稼働率、レスポンスタイム、エラーレートなどが該当します。 -
SLO
SLOは、サービス提供側がユーザーに対して約束する具体的な性能目標です。たとえば、「99.9%の稼働率」や「平均レスポンス時間500ミリ秒以内」など、明確な数値目標が設定されます。
サービスレベルの目標(SLO)を策定し、その達成状況を示す指標(SLI)を継続的にモニタリングしています。GPUを使った計算コストが高い処理や動作が不安定な外部API(LLM)の影響により、予期せぬ変動が生じる可能性があるため、常に数値を確認しています。
チームで、外形監視による稼働率やレイテンシのSLOと、実ユーザー向けの稼働率・レイテンシのSLOを設定し、毎週確認を行っています。エラーバジェットを考慮しながら、各タスクとして改善に取り組んだ結果、チーム発足以降、SLIは大幅に改善しました。
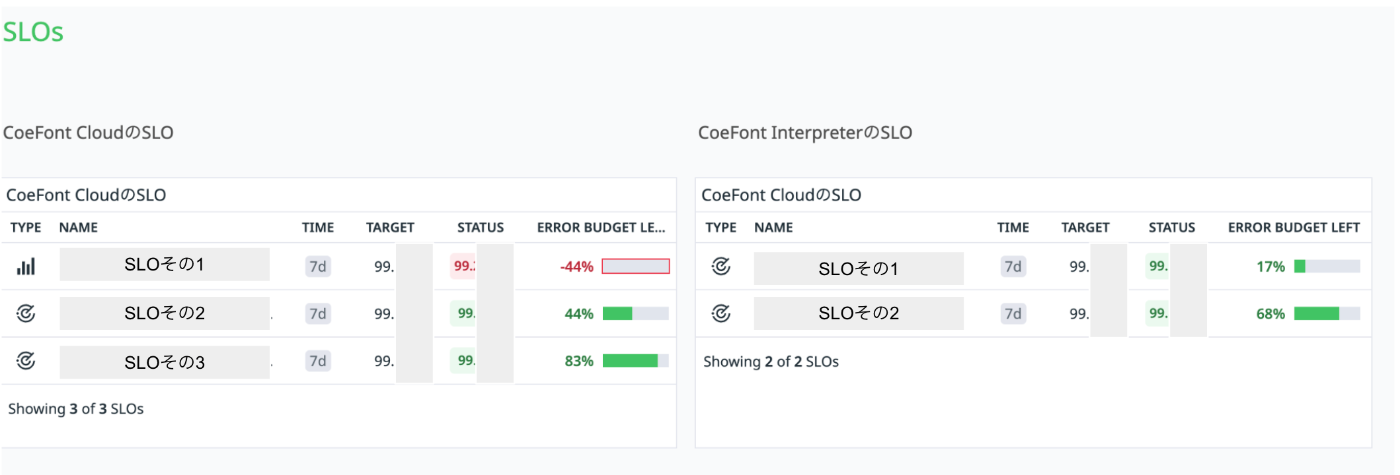
また、PO/PdMとの共通指標としてシステムの状態を数値化することで、トラブル発生時の対応や改善策の議論がスムーズに進むようになっています。
コンテンツのモニタリング
また、機械学習システムでは、単にシステム自体の稼働状況をモニタリングするだけでなく、出力されるコンテンツの品質チェックも不可欠です。
たとえば、
- 音声生成の推論結果のロギング・モニタリング
- LLMの監視(例:langfuseの利用)
などが求められます。弊社でも絶賛取組中の領域になっています。
インフラの設計
スケーリング戦略の工夫
現行のText2Speechの仕様では、リクエスト数だけでなく、リクエストごとの文字数もサーバー負荷にほぼ線形で影響を与えます。同じRPMでも、文字数の違いにより実際の負荷が100倍に達する可能性があるため、単純なリクエスト数のみでの負荷状況は把握できません。
そこで、各リクエストの文字数情報もCloud Watch Metricsに流し込み、迅速かつ柔軟なスケーリングを行い、システム全体のパフォーマンスを改善しようとしています。
セキュリティ
クライアントが直接リクエストを送信する設計は、不正アクセスのリスクを増加させる可能性があります。
そのため、AWS WAFを活用したDDoS攻撃や脆弱性を狙った攻撃への防御、ライブラリの脆弱性管理、そしてIDS(侵入検知システム)など、包括的なセキュリティ対策が不可欠となります。
最後に
本記事でご紹介した各技術と取り組みは、我々のサービスが迅速かつ安定して提供されるための基盤となっています。MLOpsチームは、非同期処理の最適化やリアルタイム通信、そして継続的なモニタリングを通じて、システム全体のパフォーマンスと信頼性の向上に努めています。これからも最新技術の積極的な採用と運用改善により、さらなる品質向上を追求していきます。

Discussion