🦔
【PostgreSQL】相関サブクエリと非相関サブクエリ
準備:テーブルとデータ作成
社員テーブルと部署テーブルを作成し、データを挿入します。
employees(社員)
| id | name | salary | department_id |
|---|---|---|---|
| 1 | 田中 | 500万 | 1 |
| 2 | 鈴木 | 400万 | 1 |
| 3 | 佐藤 | 450万 | 2 |
| 4 | 高橋 | 600万 | 2 |
departments(部署)
| id | name |
|---|---|
| 1 | 営業部 |
| 2 | 開発部 |
-- 部署情報テーブルの作成
drop table if exists departments;
create table departments (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL
);
-- 社員情報テーブルの作成
drop table if exists employees;
create table employees (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
salary INTEGER NOT NULL,
department_id INTEGER REFERENCES departments(id)
);
-- 部署データの挿入
INSERT INTO departments (id, name) VALUES
(1, '営業部'),
(2, '開発部');
-- 社員データの挿入
INSERT INTO employees (id, name, salary, department_id) VALUES
(1, '田中', 5000000, 1),
(2, '鈴木', 4000000, 1),
(3, '佐藤', 4500000, 2),
(4, '高橋', 6000000, 2);
相関サブクエリ
- サブクエリでメインクエリのデータを参照している状態
- メインのクエリが1行ずつ処理するときに、サブクエリも毎回実行される
- データごとにサブクエリが実行されるので、遅くなることがある
使用例
各社員の給与が、同じ部署の平均給与より高いかを調べる

↑ e1.department_idはメインクエリのデータにあたるので相関サブクエリになる
<出力例>
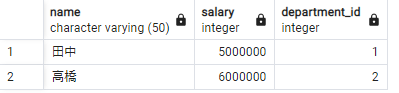
処理の流れ
1.メインクエリが employees テーブルのデータを1行ずつ取得するので、最初の行が取得される
| id | name | salary | department_id |
|---|---|---|---|
| 1 | 田中 | 5000000 | 1 |
2.サブクエリを実行

<出力例>

3.田中さんのsalary(500万)が、サブクエリの結果(450万)より大きいかをチェック。
WHERE 500万 > 450万
条件を満たすので田中さんを結果に含める
4.次は鈴木さんについて同じことをおこなう
| id | name | salary | department_id |
|---|---|---|---|
| 2 | 鈴木 | 400万 | 1 |
5.佐藤さん、高橋さんについても1行ずつ調べて行く
6.結果

非相関サブクエリ
- サブクエリがメインクエリのデータを参照しない
- 単独で実行される
- サブクエリが一度だけ実行され、その結果がメインクエリに渡される
- 相関サブクエリのようにデータごとにサブクエリが繰り返し実行されないので、一般的に処理が速い
使用例
営業部の中で一番給与が高い人を探す

1.サブクエリで営業部(department_id = 1)の最高給与を取得(500万)。
SELECT MAX(salary)
FROM employees
WHERE department_id = 1

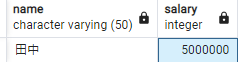
2.その給与(500万)をもつ社員を検索し、田中さんが抽出される。

Udemyで講座を公開中!
X(旧Twitter)
Zenn 本
Youtube
Discussion