CQRS
スケールするのは DynamoDB や CosmosDBだけど、フィルタとか JOIN とか考えると RDS がいいな。と思ったのと、今進めてるブロジェクトの読み取りの性能を上げるためにCQRSをキャッチアップして実践したので備忘を残しておきます。
参考:Azure アーキテクチャ センターは非常に勉強になる
単一データベースに依存したアーキテクチャの課題
単一の大きなデータベース(CRUD用のRDBなど)を中心に置き、それらを取り巻くように各種コンピューティングリソースを配置する。というアーキテクチャが多いと思います。
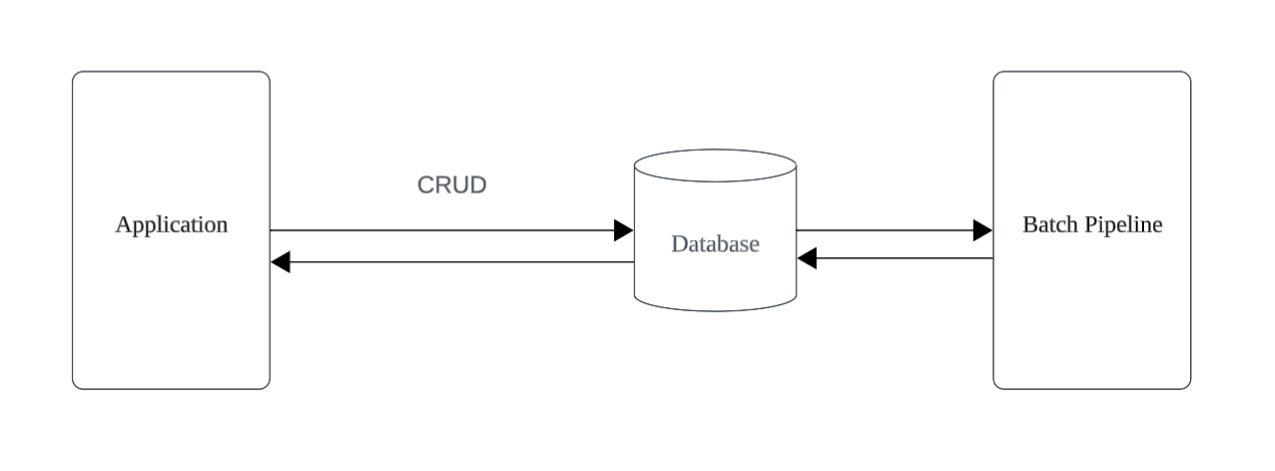
これはプロダクトによっては設計として非常にシンプルになる一方、性能要件がシビアになると、中心にあるデータベースがボトルネックとなりやすい。
データベースは書き込みと読み込みでは特性が大きく異なる
■ 書き込み(Create, Update, Delete)
Create, Update, Delete では、トランザクションが重要視される。また、アプリケーションの振る舞いに関わる複雑なドメインロジックが要求される。
■ 読み取り(Read)
Readは一覧画面や詳細画面であり、頻繁に呼び出される。また、多くの場合リクエストごとに挙動が変わるわけではないので、キャッシュが有効。検索やソートもある。
| 書き込み(CUD) | 読み取り(R) |
|---|---|
| トランザクション・整合性 | キャッシュ可能 |
| レスポンスは最小限でいい | たくさん叩かれる |
| 複雑なドメインロジック | 複雑なフィルターやクエリ |
構造的な課題
コストをかけてスペックの高いデータベースにスケールアップして対策するという方法でその場をしのぐケースもあるが、それでも一定の規模以上になると RDB の構造的な課題であるコネクション数の限界などによって、何らかの抜本的な対応が必要になることがある。
実装の複雑化
DDDで定義されている実装パターンを使っている前提で、複数集約がありそれぞれにRepositoryがあるとして、これを1つのUseCase(ApplicationService)で実装しようとすると、複数のRepositoryからそれぞれ値を取得し、戻り値のオブジェクトに詰め替えるような実装にしないといけない。
そうなると以下のような問題が発生する。
- 複数の集約から値を取得して戻り値の型に詰め替える処理が、普通に読みにくい
- 画面に返す必要のない値を取得しないといけない
- 複数集約を跨いだ条件(where)でページングができない(しづらい)
例えば以下のようなモデルから「〇月△日に注文した商品の価格を調べる」というようなUseCaseなど。

課題の整理
課題を整理すると、大きく「開発面」「性能面」の2つに分けられる。
-
開発面(設計・実装の複雑さ)
- 単一DB依存だと、DDDの複数集約を跨ぐユースケースでRepository取得と詰め替え処理が複雑化する
- 複数集約を跨いだ条件検索やページングがしづらい
-
性能面(パフォーマンス・スケーラビリティ・セキュリティ)
- 読み取りと書き込みで要求特性が大きく異なるため、単一DB設計では最適化が難しい
- 書き込み: トランザクション重視・複雑なドメインロジック
- 読み取り: 頻繁なアクセス・検索やソートが必要
- 単一RDBはスケールアップで一時的に対応できても、コネクション数など構造的な制約に直面する = 抜本的対応(分離や分散)が必須になる
- 読み取りと書き込みで要求特性が大きく異なるため、単一DB設計では最適化が難しい
CQRSによる解決
CQRS(Command Query Responsibility Segregation:コマンド・クエリ責務分離)は、その名のとおり 書き込み(Command)と読み取り(Query)の責務を分離するアーキテクチャパターン。

CQRSパターンでは以下のように考える。
- 書き込み(Command):データの状態を変更する。ドメインロジックやトランザクション制御が中心。
- 読み取り(Query):データを表示・検索・集計する。ユーザー体験やパフォーマンスを重視。(システムの観測可能な状態を変化させない=副作用がない)
つまり CQRS は、「更新のためのモデル」と「参照のためのモデル」を別々に持つことで、両者をそれぞれの要件に合わせて最適化できるようにするアプローチ。
主な利点
-
モデルの単純化
- 責務の分離により、1つのモデルに複数の要件を押し込める必要がなくなる。
- 書き込みモデル:「業務ロジック」「整合性ルール」のみに集中できる。
- 読み取りモデル:「検索条件」「表示形式」「キャッシュ戦略」などUI/UX寄りの最適化に専念できる。
- 責務の分離により、1つのモデルに複数の要件を押し込める必要がなくなる。
-
パフォーマンス
- 書き込みと読み取りでデータ構造およびデータストアを変えられるため、それぞれの要求に応じた最適化ができる。
-
スケーラビリティ
- データストアを分けることで書き込み負荷と読み取り負荷を別々にスケールできる。
-
変更容易性
- 書き込みモデルに新たにフィールドやロジックを追加しても、読み取りモデルに影響しない。
- 読み取り要件が変わった場合も、専用のビューや投影を追加するだけで済み、既存の書き込みロジックを壊さずに拡張できる。
- ドメインロジック(書き込み側)とユーザー体験(読み取り側)が疎結合になるため、仕様変更に対する影響範囲を局所化できる。
導入パターン
■ 1 つのデータ ストアでモデルを論理分離する
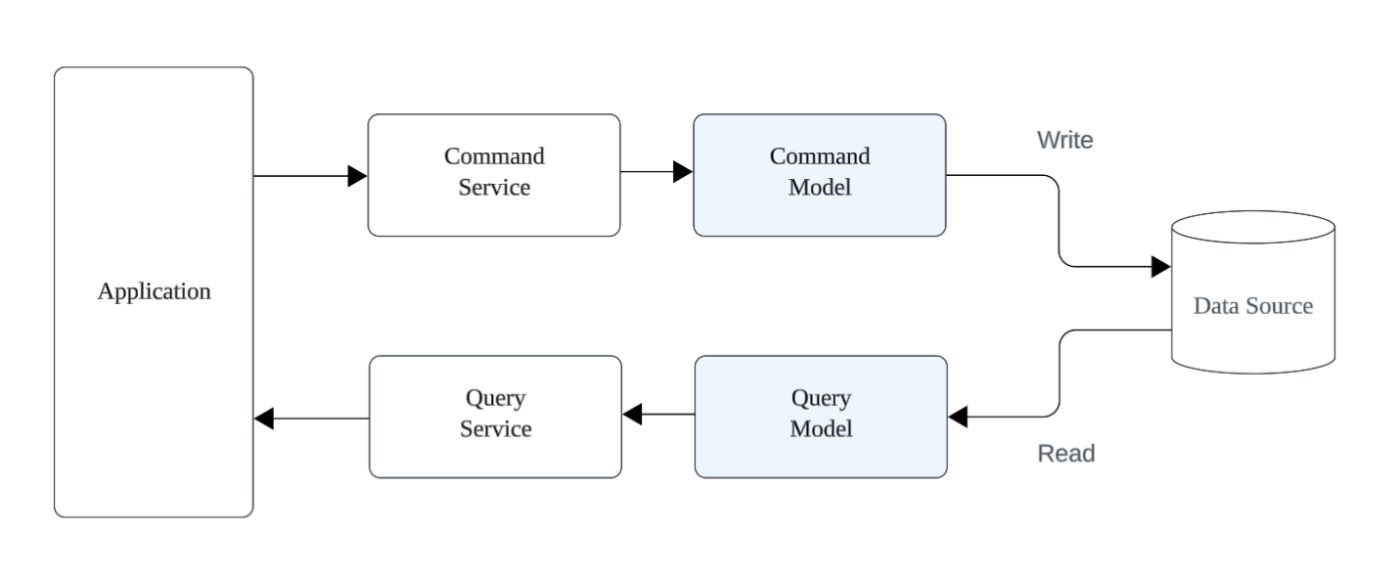
- 同じDBを使いつつ、読み取りと書き込みのモデルを分離する
- 読み取りはQueryServiceを通し、更新モデルへの依存を避ける
■ 異なるデータ ストアでモデルを分離する
- 書き込み用DBと読み取り用DBを物理的に分ける
- 書き込み時にイベントを発行し、読み取り側に同期する
- 読み取りはユースケースごとに最適化する
ユースケース
読み取りと書き込みのワークロードが不均衡なシステム(もしくはエンティティ)で有効。
- 書き込み:最小限のレイテンシとしたい
- 読み取り:それなりに複雑なクエリが必要
エンティティ単位など部分的な導入も可能。
整合性とのトレードオフ
CQRSでデータストアを分離した場合、書き込みストアの更新イベントを読み取りストアに同期する仕組みを取るため、基本的に「結果整合性」となる。
これはシステム全体のデータが瞬時に同期するわけではなく、一定時間の遅延を経て整合した状態に収束するという話。
そのため「結果整合性を受け入れられるか?」は設計上(というか要件定義上)認識合わせが必要なポイント。ただ、そのまま伝えると受け入れづらいというのもあると思うので、難しい部分・・・。
現実的には、以下のポイントは押さえておく。
-
トレードオフを明確に説明する
- CAP定理 / PACELC定理などの前提条件
- プロダクトにおける性能・スケーラビリティのメリットと、結果整合性のデメリット
-
SLA / SLO をシステム要件として明確化する
- 「書き込みから参照に反映されるまで最大◯ms or sまでなら許容する」など
-
システム全体ではなく一部のエンティティで「結果整合性」を受け入れてCQRSのメリットを享受する
- 例:在庫や残高のようなクリティカル領域は即時整合性、ログ閲覧やレポート画面は結果整合性を許容する
現実的な話
- データストアを分ける場合は基本的に 結果整合性 になる。
- システム全体に適用する必要はない。
- 1部のエンティティのみ導入してCRUDとのハイブリッドでも全然OK。
- 他パターンと組み合わせて実装することが多い
- Materialized View パターンとの組み合わせ
- イベントソーシングパターンとの組み合わせ
参考
CQRSパターン
Materialized View パターン
イベントソーシングパターン
CAP定理 / PACELC 定理(および結果整合性周りの話)