EC2からECS on Fargateへ移行するまでの道のりとポイント
こんにちは。
株式会社ココナラのシステムプラットフォーム部でインフラ・SREチームのチームマネージャーをしているよしたくと申します。
EC2で稼働していた経理会計システムをECS on Fargateへ移行したので、移行実施までの道のりと考慮ポイントをまとめていきます。
背景
インフラ運用としては、EC2サーバ管理の運用コストは削減したいという思いがあります。
一方でプロダクト(アプリケーション)開発側でもシステムの改善、アップデートを進めています。その中で経理会計システムのRubyアップデートの計画がなされていました。
経理会計システムは全体からみると比較的小さな構成をしており、影響度合いもそれほど大きくはなかったため、Fargate推進を進めるための第一歩を踏み出すためにはちょうどよい機会だということで、Rubyアップデートとあわせてアーキテクチャ刷新に踏み切りました。
基盤アーキテクチャ
経理会計システムとは、内部の別システムからの呼び出しに対応したAPIサーバと、データを作成するために定期的に動くバッチの大きく2つのことを指します。
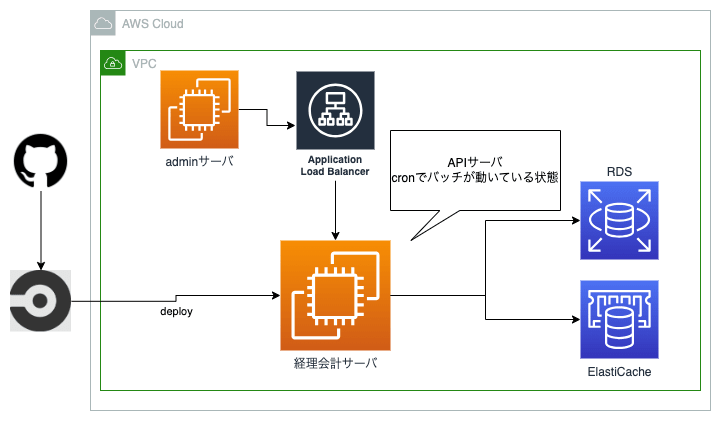
EC2(旧)
APIサーバとバッチの稼働が1つのEC2インスタンス内で動くような形式でした。いわゆる単一障害点になってしまっていました。
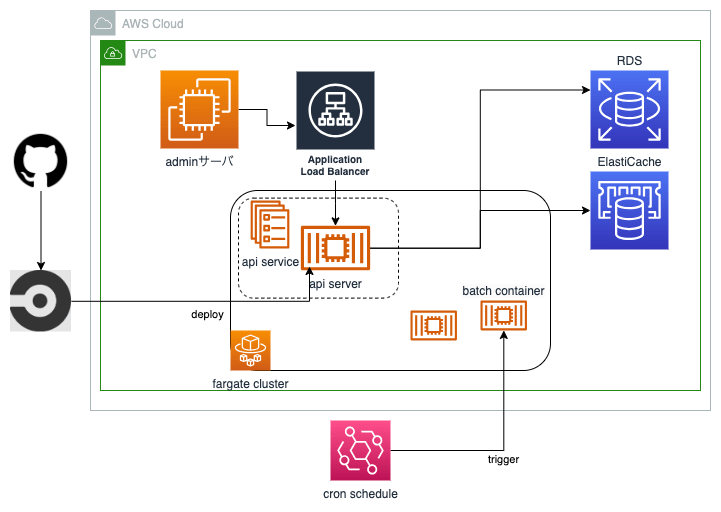
ECS on Fargate(現)
実際に切り替えるまで
インフラ設計
おもにAPI部分とバッチ部分をどのようなアーキテクチャにするかを設計します。(結果は前述図)
また、EC2の際のスペックをそのままFargateに持っていこうとすると、コストが増加してしまいます。
そこで、使用するリソース量を用途に応じてアジャストしました。詳しくは後述の考慮ポイントを参照してください。
CI/CD変更
もともとCircleCIを用いてEC2へデプロイしていたため、引き続きCircleCIにてECSへデプロイラインを組むこととしました。
多くの記事ではOrbのaws-ecs/deploy-service-updateを用いてデプロイする方式をとっていますが、これですとタスク定義の変更が反映されません。後述しますが、タスク定義はアプリケーション開発側で担保してほしいため、タスク定義の変更もデプロイ時に反映されるように少し工夫しました。
# タスク定義はリポジトリで管理しているjsonから都度更新するようにすることで、変更も反映する
- aws-ecs/update-task-definition-from-json:
task-definition-json: docker/<< parameters.environment >>/task_definition.api.json
- aws-ecs/update-service:
cluster: <<parameter.prefix>>-<< parameters.environment >>
family: <<parameter.prefix>>-<< parameters.environment >>
service-name: <<parameter.prefix>>-<< parameters.environment >>
skip-task-definition-registration: true
verify-revision-is-deployed: true
poll-interval: 5
開発環境の整備
Terraformはこちらの記事のポリシーに則り、開発/本番とで共通moduleを作成しつつ開発環境の構築を行います。
これにより本番環境構築は、差分となるところさえ記載してapplyすればすぐに作業することができますね。
また、アプリケーション開発チームから、開発サーバに接続してコマンド実行したいというユースケースがありました。
こちらを実行するためにサービス上でECSExecを有効化する必要があります。必要なときに有効化しようとすると、タスクを再デプロイするという手間が発生するため、あらかじめ開発側は有効な状態でサービスを作成することとしました。
接続するコマンドは都度打つのも面倒なのでスクリプトを作成し、それを展開することで解決しています。
#!/usr/bin/env bash
CONTAINER=hoge
AWS_PROFILE=hoge
CLUSTER=hoge
SERVICE=hoge
TASKARN=`aws ecs list-tasks --cluster ${CLUSTER} --service-name ${SERVICE} --profile ${AWS_PROFILE} | jq -r '.taskArns[0]'`
TASKID=`aws ecs describe-tasks --cluster ${CLUSTER} --tasks ${TASKARN} --profile ${AWS_PROFILE} | jq -r '.tasks[0].containers[0].runtimeId' | awk -F '-' '{print $1}'`
# ここが接続
aws ecs execute-command \
--cluster ${CLUSTER} \
--task ${TASKID} \
--container ${CONTAINER} \
--interactive \
--profile ${AWS_PROFILE} \
--command "/bin/sh"
擬似Blue/Green環境運用
開発環境での動作確認はじゅうぶんに実施したのちの本番適用となりますが、とはいえ本番で発覚する問題も可能性として存在するのでBlue/Greenライクな運用を1ヶ月を行いました。
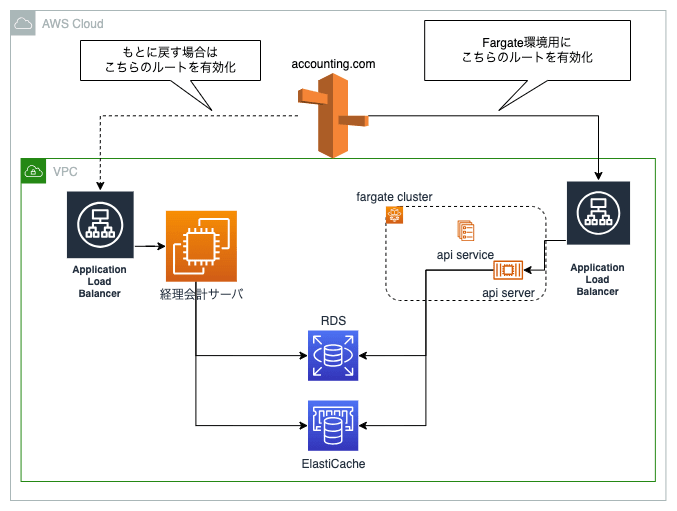
API部分はRoute53レコードでいつでもBlue/Greenを切り替え可能なような状態です。
バッチは対象のEventBridgeを停止し、EC2側のcron定義のコメントアウトを外すことでバッチごとに復帰が可能になるようにしています。
旧環境破棄
1ヶ月程度新環境側で稼働させて問題ないことを確認したのち、EC2環境を破棄しました。EC2は念のためAMIのバックアップを取得しています。
EC2環境はほとんどコード管理外だったため、確認しながら手動で削除を実行しています。
考慮ポイント
スペックの選択
EC2とECS on Fargateにおいてスペック選択方法が異なります。Fargateのほうがより柔軟にスペックが定義可能です。
- EC2:インスタンスタイプから選択
- Fargate:一定の組み合わせから選択
EC2で稼働していたときは、もっともリソースを使用するバッチのCPU/メモリ使用量をベースとして、そのバッチ実行に影響がないようにインスタンスタイプを選択していました。そのため定常状態ではリソース過剰である状態がほとんどでした。また、Fargateのほうが定常的なコストは高くつきます。
以上のような理由から、用途に応じてスペックをアジャストします。具体的には以下の3種類で分類し、このことからタスク定義は3つにわかれています。
- APIサーバ
- CPU/メモリパワーを要するバッチ
- CPU/メモリパワーを要さないバッチ
責任分界
EC2運用時代は、サーバにインストールするツール、マシンスペック、環境変数など一括してインフラ側が管理していました。
しかし、本来はアプリケーション開発側が定義&管理してしかるべきものです。
ECS on Fargateにおいて、それはタスク定義となることから、タスク定義はアプリケーション・サービス定義はインフラで管理するように責務を分離しました。
監視
APIサーバの監視は一般的なもの(エラーログと死活監視)を投入しています。
一方でバッチは少し特殊で、周期的に実行されていることを担保することを考慮する必要がありました。エラーについてもしっかり拾いたいので、以下のような監視設定を組み込んでいます。
- エラー検知
- アプリケーションログの「Error: hogehoge」という文字列の監視(API/バッチ共通)
- Target GroupのHealthyサーバ数 < 1 となったとき
- ECSタスクの終了ステータス != 0
- 周期的に実行されていることの担保
- バッチ終了時にログに「{バッチ名} End.」を出力し、これをメトリクスフィルターで拾って一定時間内に1回以上出現しなければアラート
考慮不足ポイント
EventBridgeはターゲットのトリガーを行うところまでが責務であり、その先でどうなっているのかについては関心を持ちません。
設計当初こちらの仕様について理解できておらず、リリース後しばらくしてから以下のような問題に直面しました。
直面した問題
EventBridge側では問題なくECSタスクがトリガーされたログがあるにもかかわらず、実際には当該ECSタスクが存在しないということがありました。前後30分のレンジで確認しても、特定の時刻帯でのみ発生しており、こちらの設定の問題であることは考えにくいものでした。
深掘りすると、タスク起動段階で「Capacity is unavailable at this time.」というエラーが発生していました。これはFargate基盤側でタスク起動のための十分なコンピュートリソースを確保できない際に発生するものです。
前述のログ監視をしていたため発生後30分程度で検知できましたが、仮に監視設定が漏れていたとすると本事象は検知することができず、データに不整合があることに気づくのはかなりあとになっていたことかと思います。このことから監視設定の重要性を身にしみて実感できました。
対策
EventBridgeから直接ECSタスクを起動するのではなく、StepFunctionsを呼び出す形にすることでタスク起動または起動後に問題が発生した際に即時検知が可能です。
それはStepFunctionsではエラー処理/再試行処理機能があるためです。今回のようなごく一時的な時間帯で発生しうる問題に対しては、再試行処理が有効であり、これによって手動作業によるリカバリが不要となります。
StepFunctionsを経由したバッチ処理の起動については、また別の機会に記載しようと思います。
おわりに
EC2サーバで運用していたときの以下の負債を解消することができ、運用コストの削減につなげることができました。
- APIとバッチを分離できた
- APIサーバは冗長化できた
- Ansible / Terraform の2つのツールでインフラ管理していたところがTerraformのみで完結するようになった
- アプリリソースやDockerfileの作成など開発チームとインフラチームとで責務をより適切化できた
システムによって考慮すべき点は異なってきますが、Fargate移行の参考となれば幸いです。
ココナラでは、一緒に事業のグロースを推進していただける様々な領域のエンジニアを募集しています。
インフラだけでなく、フロントエンド開発・バックエンド開発などでも積極的にエンジニア採用を行っています。
少しでも興味を持たれた方がいましたら、エンジニア採用ページをご覧ください。
Discussion