AWS環境でSREがREDメソッドを実践するための仕組み
こんにちは。
株式会社ココナラで技術戦略室を担当しているKと申します。
今日は、AWS環境でココナラのSREが実践しているREDメソッドについてお話ししたいと思います。
そもそもREDメソッドってなに?
よくREDメソッドと同時に語られる別の方法論として、USEメソッドがあります。
それぞれ以下のように目的が異なっています。
USEメソッド
USEメソッドは、CPUやメモリなどの各リソースのモニタリングを目的としています。

USEメソッドは以下の3つの指標で構成されています。
これらの頭文字を取って、USEと呼ばれています。
- Utilization: 使用率
- Saturation: 飽和率
- Errors: エラー数
REDメソッド
一方、REDメソッドは最終的なアプリケーションの挙動をモニタリングするのが目的です。

REDメソッドは以下の3つの指標で構成されています。
これらの頭文字を取って、REDと呼ばれています。
- Requests: リクエスト数
- Errors: エラー数
- Duration: 実行にかかった時間 (レイテンシー)
このようにUSEメソッドとREDメソッドは目的が異なっており、両方必要なものです。
REDメソッドを実践したい
SREとしては、サイトの信頼性を維持、向上させるために何としてでもこれらのメソッドを実践したいものです。
しかしながら、当時はUSEメソッドの方はある程度実践できていた一方で、REDメソッドの方はあまり実践できていませんでした。
それは、AWSのCloudWatchなどのマネージドサービスだけでREDメソッドを実践するのは難しかったためです。
AWSでREDメソッドを実践する難しさ
以下のような難しさがありました。
-
URL単位でモニタリングできない
- CloudWatchで確認できるのは、ALBまたはターゲットグループ単位のメトリクスまでです。URL単位では確認できません。
- URL単位に確認したい場合、NginxのアクセスログをCloudWatch LogsやBigQueryで検索する必要がありました。
-
検知できないエラーがあった
- サイト全体に影響を与えるようなエラーであれば、CloudWatchだけで十分検知できます。
- 一方で、特定のURLだけで少量発生したエラーやログも出力されていないようなエラーは検知できないことがありました。
これらを乗り越えてREDメソッドを実践するため、モニタリングの仕組みを作りました。
作ったもの
大きく2つのものを作りました。
- Grafanaのダッシュボード
- Prometheusで各URLのREDを収集する仕組み
Grafanaのダッシュボード
まずは、ダッシュボードです。
Grafanaのダッシュボードでドメイン単位、URL単位にREDを可視化しています。
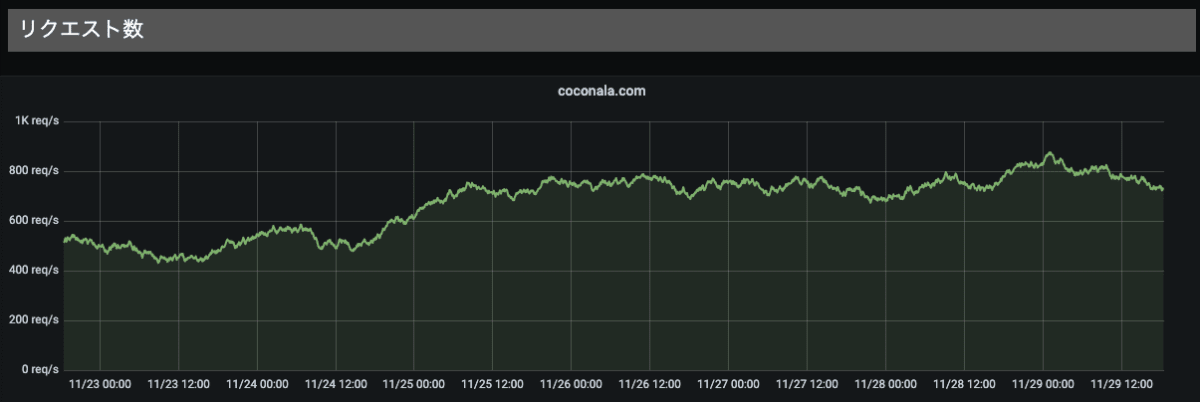
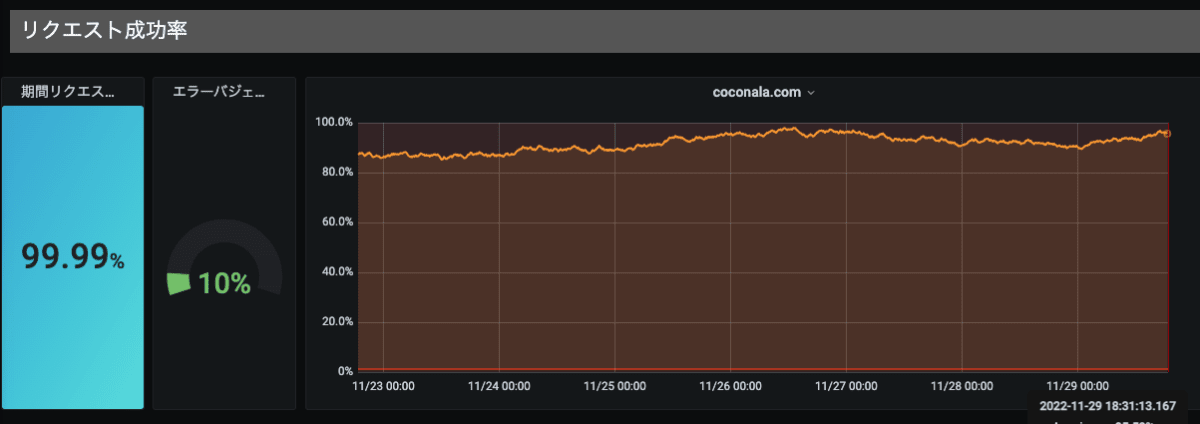
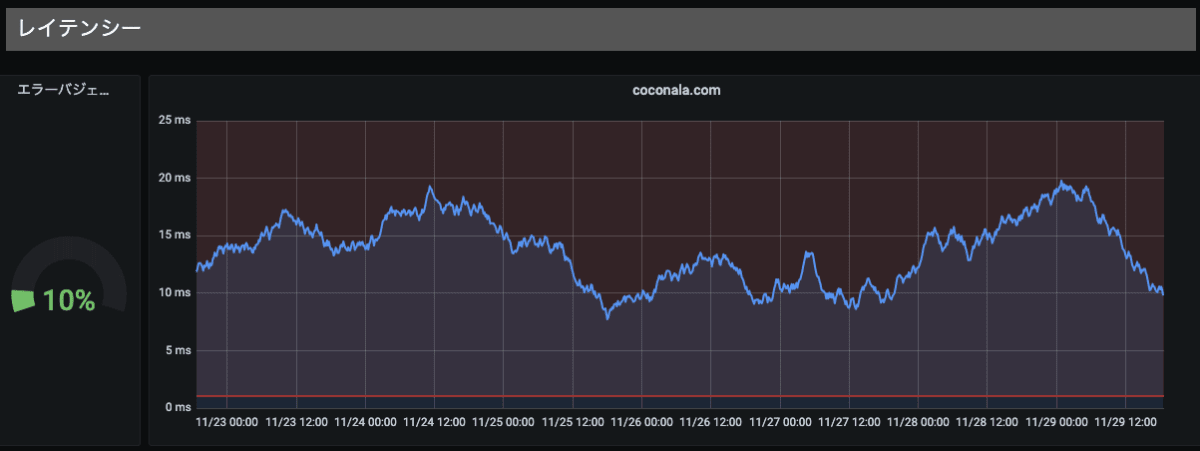
ドメイン単位のRED
ドメイン単位にサマリしたデータです。
-
R: リクエスト数
-
E: エラー数
-
D: レイテンシー
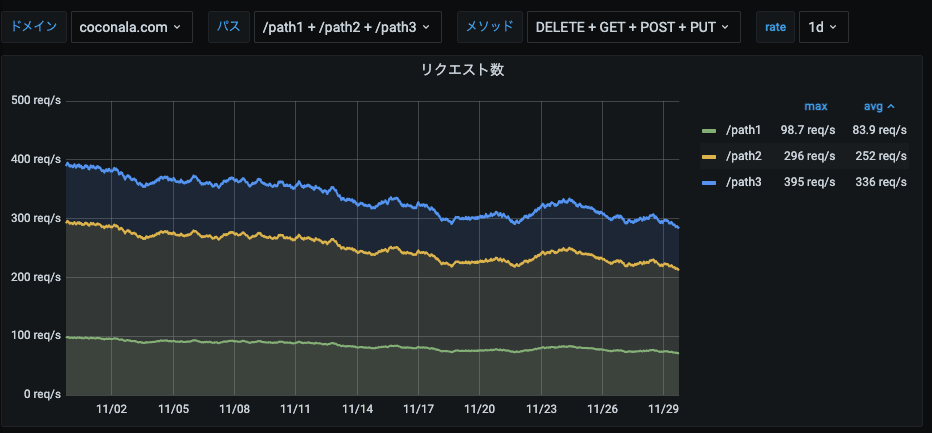
URL単位のRED
各URLのデータです。
画面上部のGrafanaの変数でURL単位に絞り込みできるようになっています。
-
R: リクエスト数
-
E: エラー数
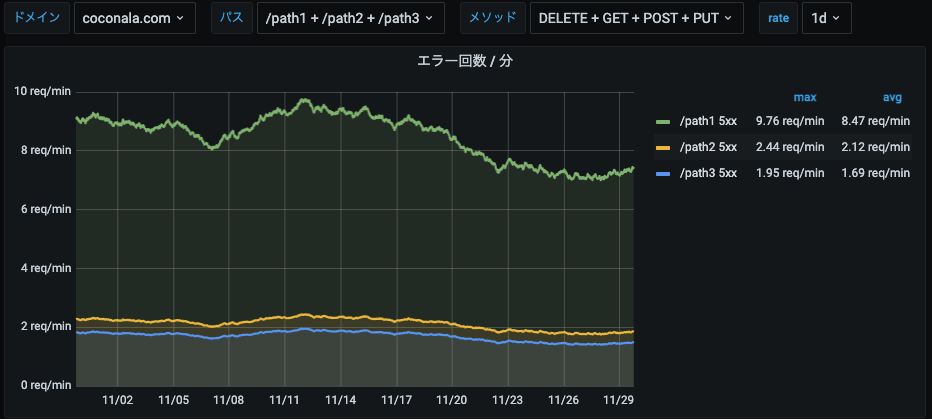
-
D: レイテンシー
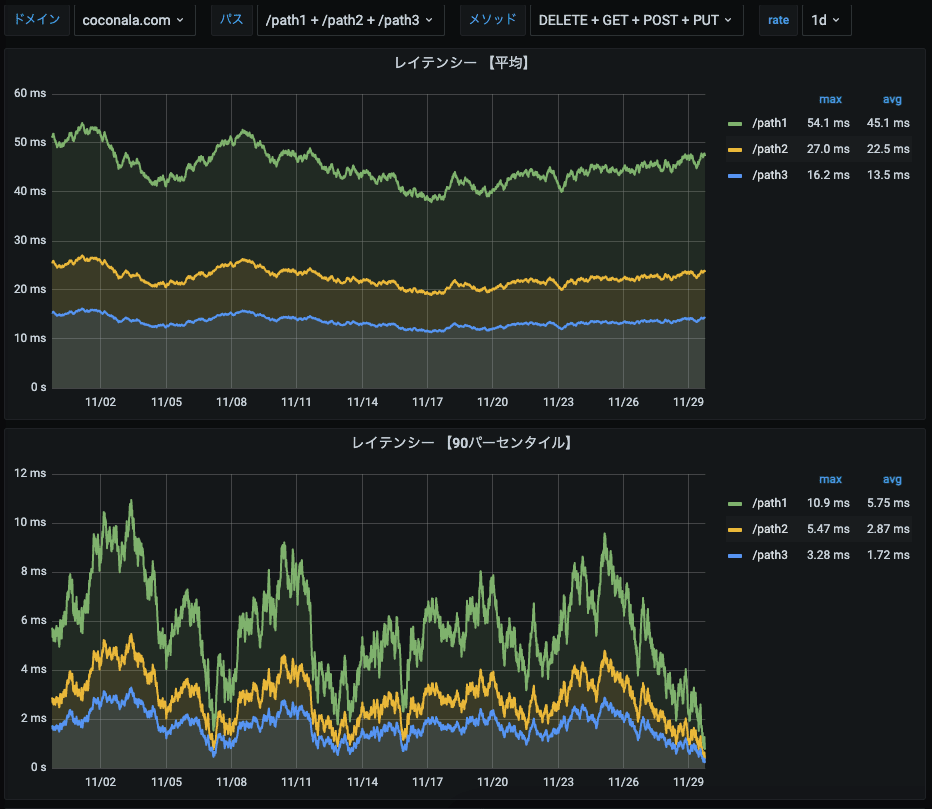
※グラフのデータはいずれもGrafanaのRandom Walkで生成したダミーデータです。
Prometheusで各URLのREDを収集する仕組み
これらのダッシュボードのデータソースはPrometheusです。
各URLのREDを次の仕組みでPrometheusに流し込んでいます。
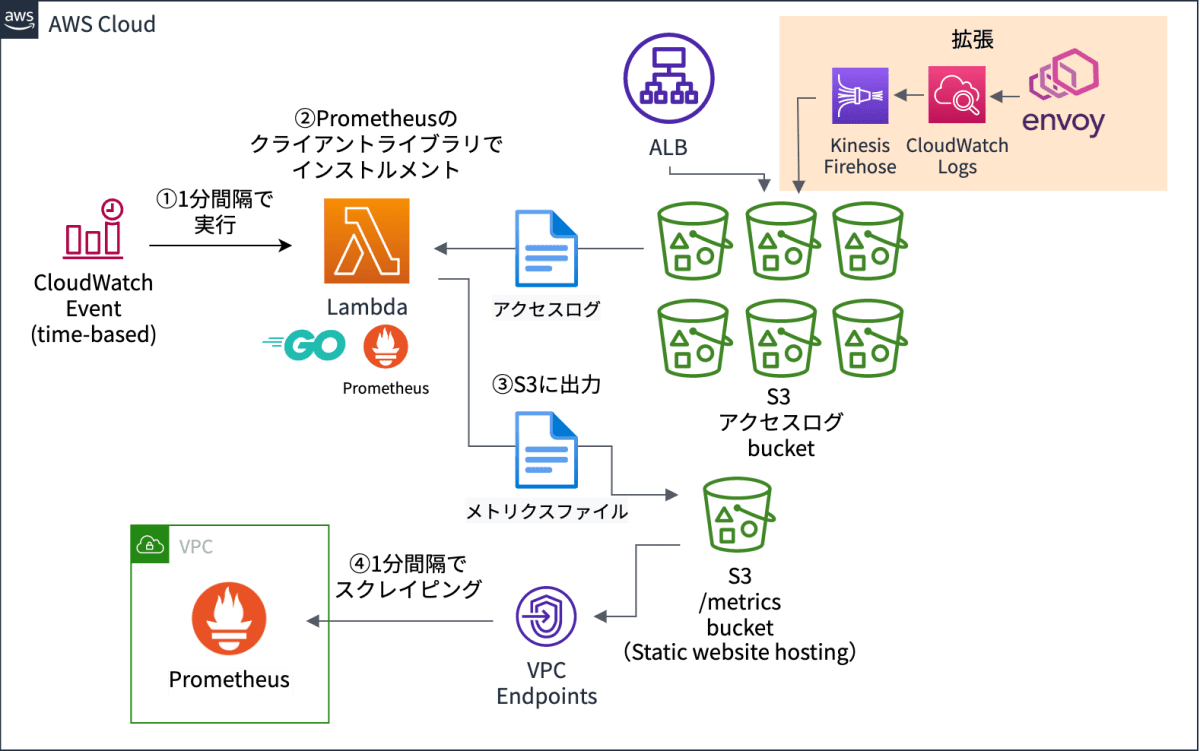
全体図
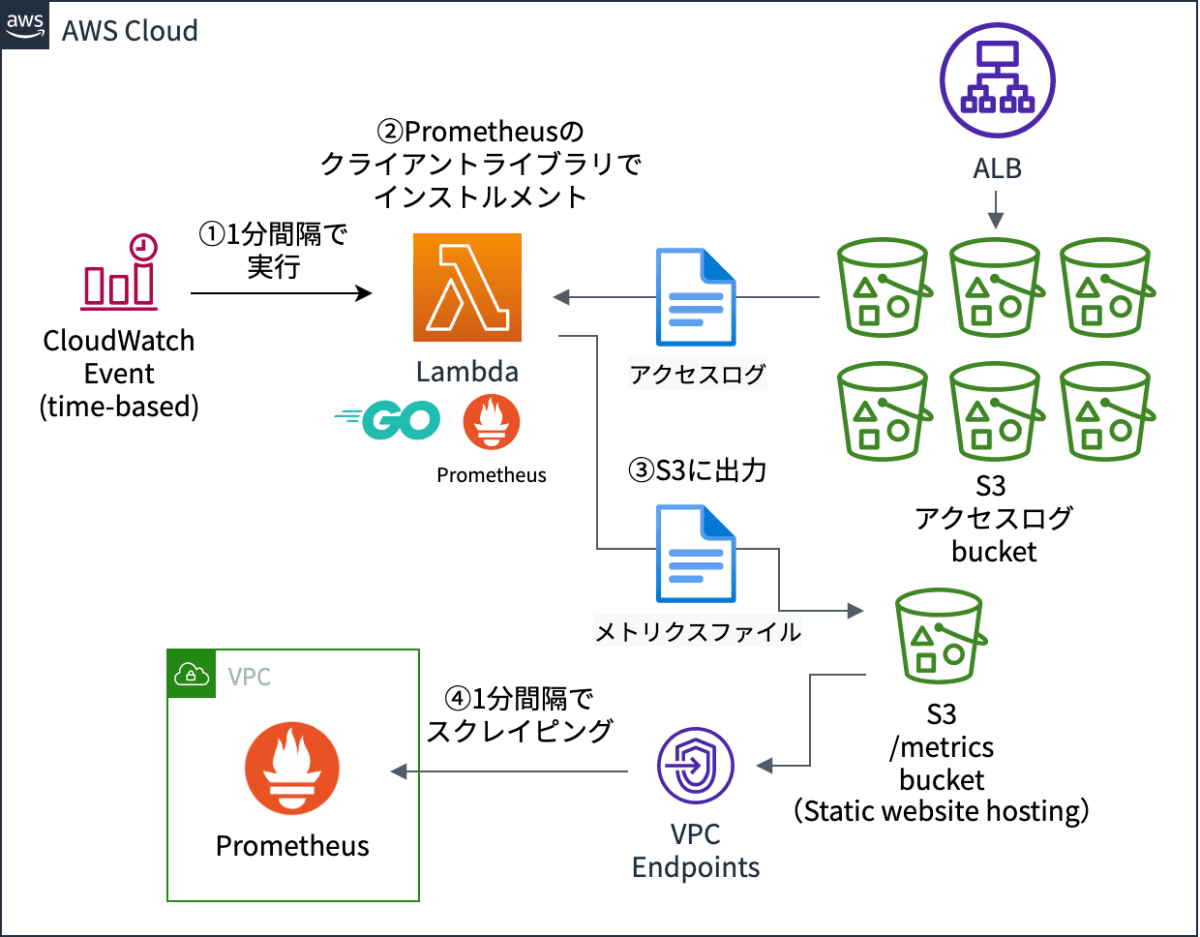
ALBのアクセスログを以下の流れで、Prometheusに取り込んでいます。
- CloudWatch Eventsが1分間隔でLambdaを実行します。
- LambdaがS3のALBアクセスログをPrometheusのメトリクスに変換します。
- 変換したPrometheusのメトリクスを別のS3に保存します。
- Prometheusが1分間隔で、S3に対してHTTPアクセスでスクレイピングします。
考慮事項
この仕組みを作るにあたって、以下の事項を考慮する必要がありました。
1. どこで計測するか?
アクセスログはALBだけではなく、Nginxでも出力されています。
データソースとして、どちらを使用するか検討しました。
それぞれ一長一短ですが、計測可能性を重視してALBのアクセスログを使うことにしました。
| 対象 | 計測可能性 | リアルタイム性 |
|---|---|---|
| ALB | ✅ ユーザーに一番近い位置で動作しているため、計測データが実際のユーザー体験に近いものになります。 | ❌ S3に出力されるまで5分程度のタイムラグがあります。 |
| Nginx | ❌ 計測できないケースがあります。例えば、以下の障害が発生すると計測できません。 - Nginxが動いているサーバーの障害 - ネットワーク障害 |
✅ タイムラグがほぼありません。 |
2. どうやって計測するか?
Prometheusでは、ラベルにURLのような種類の多い値を使うことはあまり推奨されていません。
ラベルのカーディナリティが高いと動作が遅くなってしまうためです。
そのため、 Promethuesで本当に実現できるのか? という懸念がありました。
対応
以下の2つの対応を行った結果、Prometheusで問題なく実現することができました。
-
URLを正規化する
-
/数字またはIDのようなURLを個別に計測すると、URLの数が膨大になってしまいます。 - そこで、これらのURLを
/*のように正規化した上で計測するようにしました。
-
-
レコーディングルールで事前集計する
- Prometheusでは、スクレイピング時にレコーディングルールを適用することで、データを事前集計できます。
- この機能を使用することで、ドメイン単位の集計クエリなどを高速化できました。
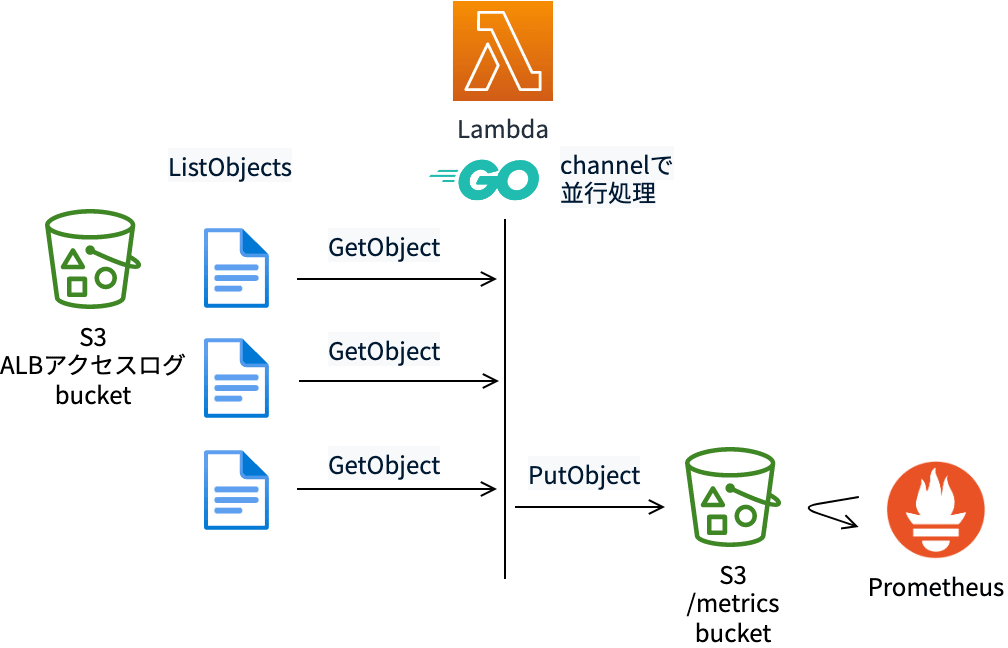
3. 大量のログをどう処理するか?
アクセスログは大量に出力されます。
大量のログを一定時間以内に高速に処理する必要があります。
対応
Go言語を採用し、以下のように並行処理することで短時間で処理することができました。
4. gRPCに対応できるように拡張する
現在、ココナラではgRPCを使っています。
この仕組みを作った当初は、gRPCのAPIがそれほど多くないこともあり、計測対象外にしていました。
しかし、その後次第にgRPCのAPIが増えてきたため、gRPCも計測できるようにこの仕組みを拡張しました。
gRPC対応版の全体像
右上が拡張した箇所です。
EnvoyのアクセスログをKinesis FirehoseでS3に転送しています。
まとめ
本記事では、AWS環境でココナラのSREが実践しているREDメソッドの仕組みをご紹介しました。
この仕組みを作ってから、URL単位のモニタリングがやりやすくなり、サイトの信頼性向上に繋げることができました。
本記事が同じようにAWS環境でモニタリングを検討されている方の目にふれ、ご参考になれば幸いです。
さらにこの仕組みの詳細を知りたい方は、ぜひ以下フォームよりお気軽にご連絡ください!
ココナラに少しでも興味が湧いたという方も大歓迎です。
入力時間は1、2分です。
ココナラのエンジニアについてもっと知りたい!という方はこちらをご確認ください。
Discussion