バックエンドモニタリング改善の取り組み
こんにちは。
プロダクト開発部のバックエンド開発グループでエンジニアをしているゆうまです。
今回はバックエンド開発グループ内のモニタリングの改善事例についてご紹介します。
いままでのモニタリング
今までバックエンド開発グループでは、日別の担当者がGrafanaで作成したドメイン別のエラー率、URL別エラー発生状況、スロークエリを監視していました。しかし、定常的なモニタリングがこれのみでは、新規発生エラーやDB周り以外のパフォーマンス劣化を検知できず、対応が遅れるという課題がありました。
url別エラー発生状況

ドメイン別のエラー率

モニタリングの重要性の周知
自分たちで開発した機能をリリースした、で終わりではありません。 リリース後の障害検知が、ユーザーからの問い合わせや他部署からの指摘によって初めて気づくというのは、まさに後手となります。ユーザーに不快な思いをさせてしまうだけでなく、企業にとっても大きな損失となる可能性があります。
モニタリングを怠ることによって、重大な障害の検知が遅れたり、問題が深刻化するまで放置されたりする可能性があります。 こうした事態を招かないためにも、モニタリング習慣のないメンバーにその必要性を理解してもらうことが重要でした。しかし、単に周知するだけでは、メンバーの状況によっては実行に移せない可能性もありました。また、重要性は理解していても、具体的なモニタリング方法がわからないメンバーも存在しました。そこで、モニタリングの重要性と具体的な方法を共有する必要がありました。
モニタリングの仕組み化
部署全体でモニタリングを仕組み化し、すべてのメンバーが同じようにモニタリングできるようにしなければ、重要性を周知したとしても、メンバーが入れ替わったりした場合にモニタリングがおろそかになったり、従来の状態に戻りかねません。
仕組み化にあたって、まず何をモニタリングするかを決めました。バックエンド領域では、エラー監視、パフォーマンス監視、インフラメトリクスの監視が必要と判断しました。
具体的には、以下のようにツールを導入しました。
- エラー監視: 以前から導入していたSentryを使用、X-Rayの導入
- パフォーマンス監視: NginxのログからGrafanaにダッシュボードを作成
モニタリングを仕組み化するのは良いものの、いきなりすべての監視を展開すると学習コストが多くなるため、少しずつ導入を始めました。
Sentryの導入
まず、Sentryの導入から始めました。Sentryは以前から導入していましたが、使い方を理解していないメンバーもいたため、バックエンド開発グループとして知見を共有しました。具体的には、朝会でSentryの使い方を共有し、その後に朝会の中でモニタリングを行いました。約2ヶ月間朝会でモニタリングを行い、メンバーの知見が広まったタイミングで、朝会のモニタリングから担当者のモニタリングに切り替えました。ただし、担当者だけがモニタリングすれば良いというわけではなく、モニタリングの意識はエンジニアとして全員持つべきなので、担当ではないからといって見ないという意識は良くないことを伝えました。また、本番環境だけではなく、dev環境でもsentryの通知をしており、リリース前にエラーが出ていないかなど確認してSentryに触れる機会を増やしています。
パフォーマンス監視の強化
以前からもスロークエリのログは確認していましたが、同じクエリが重複して表示されており可読性も低く確認するのが大変でした。そこでCloudWatch Logs Insightsを用いてGrafanaで重複を取り除きダッシュボードを作成しました。スロークエリはmax値とavg値でそれぞれ作成しました。
また、CloudWatch Logs Insightsのpattern構文を使うことでスロークエリの傾向をまとめることができました。
スロークエリだけだとDBのみでアプリケーションや通信の問題も気付けないのでAPIごとのパフォーマンスもダッシュボード化しました。CloudWatch Logs Insightsを用い、Nginxのログを可視化しました。
スロークエリ(avg)

スロークエリ(pattern)

パフォーマンスモニタリング

X-Rayの導入
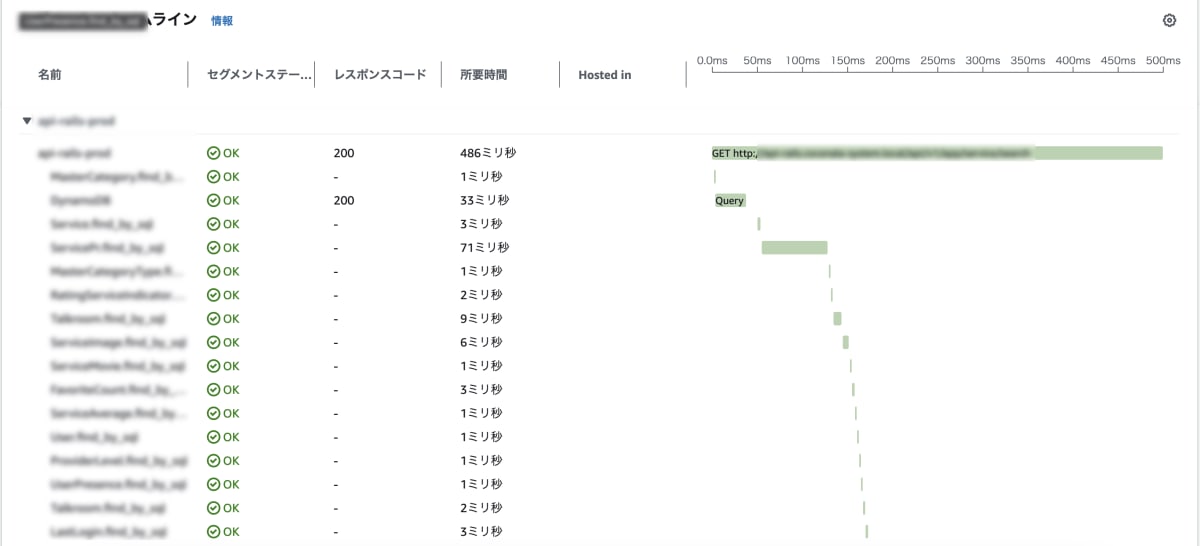
X-Rayの導入もモニタリング強化の一貫として行いました。X-Rayを入れることでどこのエンドポイントのどこの箇所がボトルネックになっているのかがわかるようになりました。また、どこの箇所でエラーが発生したのかも確認がしやすくなりました。X-Rayは分散アプリケーションの分析のためのツールなのでサービス連携のどこの箇所で失敗したのかもすぐに把握できるようになりました。
X-Rayパフォーマンス調査
今後の監視
インフラメトリクス監視
インフラメトリクスの監視については、バックエンド開発グループ内での知識共有がまだ十分ではありませんが、今後積極的に取り組んでいきたいと考えています。ココナラでは、インフラメトリクスの監視ツールとしてDatadogを主に使用しています。Datadogには様々なメトリクスが収集・可視化されていますが、バックエンド開発グループでは、特に使用頻度が高いサーバーとDBの監視に注力していくことが重要だと考えています。
リリース後にこれらのメトリクスを監視することで、DBへの負荷状況やメモリ使用量などを把握し、潜在的な問題を早期に発見・解決することができます。また、Datadogの機能を活用することで、より詳細な分析や異常検知を行うことも可能です。こうした取り組みを通じて、Datadogを最大限に活用し、より安定したサービス提供を継続していきたいと考えております。
まとめ
開発業務に忙殺される時期もありますが、モニタリングをおろそかにしてしまい、障害の発見が遅れるようなことがあっては本末転倒です。
サービスを安定してユーザーに提供するために様々なメトリクスをモニタリングすることで、素早く対応を行えるように今後もサービスを運用して行きたいと思います。
さいごに
私たちココナラでは、一緒にサービスを盛り上げていく仲間を募集しています。
私が所属するバックエンド開発グループ以外にも、部署ごとに環境の改善などに取り組んでいます。もし興味をお持ちいただけましたら、カジュアル面談にお越しください。
また、募集求人については以下のリンクからご確認いただけます。
Discussion