🐡
pythonで2匹の愛猫を判別するAIアプリを作成してみた
はじめに
私は現在2匹の愛猫達と暮らしています。
今回はその2匹の愛猫達の画像を使用し、画像から、どちらがどの猫であるか識別できるようにしました。
解決したい社会課題
ペットの健康管理は、現代において多くの飼い主が直面する重要な課題です。
複数のペットを飼っている場合、それぞれの健康状態や行動を適切に把握し、管理することが困難になることがあります。
ペットは個体ごとの性格や行動に違いがあります。健康状態の微妙な変化を見逃すことがないように、
複数のペットを簡単に識別し、それぞれの行動や健康状態を正確に記録することで、飼い主がペットの健康をより適切に管理できる様にしたいと思い、
今回は、自身の愛猫達の画像データを使用し、2匹の判別機能を作成しました。
分析するデータ
愛猫達2匹の写真をそれぞれ1000枚ずつ使用しました。
実行環境
パソコン:Windows 10
開発環境:Google Coraboratory
言語:Python
ライブラリ:Keras、Matplotlib
分析の流れ
1.データのラベル付け
2.データの前処理
3.モデルの構築
4.モデルのトレーニング
5.モデルの評価
6.モデルの利用
実行したコード
#1.データのラベル付け
# dataset/
# ├── cat1/
# │ ├── 0001.jpg
# │ ├── 0002.jpg
# │ └── ...
# └── cat2/
# ├── 0001.jpg
# ├── 0002.jpg
# └── ...
# 2.データの前処理
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# データジェネレータの設定
datagen = ImageDataGenerator(rescale=1.0/255, validation_split=0.2)
train_generator = datagen.flow_from_directory(
'datasetの場所',
target_size=(416, 416),
batch_size=32,
class_mode='binary',
subset='training'
)
validation_generator = datagen.flow_from_directory(
'datasetの場所',
target_size=(416, 416),
batch_size=32,
class_mode='binary',
subset='validation'
)
# 3. モデルの構築
# シンプルなCNN(Convolutional Neural Network)モデルを構築
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(416, 416, 3)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 4. モデルのトレーニング
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // train_generator.batch_size,
validation_data=validation_generator,
validation_steps=validation_generator.samples // validation_generator.batch_size,
epochs=10
)
import matplotlib.pyplot as plt
# トレーニングの履歴から損失と精度をプロット
def plot_training_history(history):
fig, axs = plt.subplots(2, 1, figsize=(10, 10))
# 損失のプロット
axs[0].plot(history.history['loss'], label='Training Loss')
axs[0].plot(history.history['val_loss'], label='Validation Loss')
axs[0].set_title('Training and Validation Loss')
axs[0].set_xlabel('Epochs')
axs[0].set_ylabel('Loss')
axs[0].legend()
# 精度のプロット
axs[1].plot(history.history['accuracy'], label='Training Accuracy')
axs[1].plot(history.history['val_accuracy'], label='Validation Accuracy')
axs[1].set_title('Training and Validation Accuracy')
axs[1].set_xlabel('Epochs')
axs[1].set_ylabel('Accuracy')
axs[1].legend()
plt.show()
# トレーニング履歴をプロット
plot_training_history(history)
# 特定のディレクトリに保存
import os
output_dir = '/保存先'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model.save(os.path.join(output_dir, '名前.h5'))
可視化したデータ
Epoch=10 の結果
Epoch 1/10
50/50 [==============================] - 648s 13s/step - loss: 0.4377 - accuracy: 0.8100 - val_loss: 0.3199 - val_accuracy: 0.9115
Epoch 2/10
50/50 [==============================] - 695s 14s/step - loss: 0.2257 - accuracy: 0.9119 - val_loss: 0.2344 - val_accuracy: 0.9167
Epoch 3/10
50/50 [==============================] - 683s 14s/step - loss: 0.1523 - accuracy: 0.9369 - val_loss: 0.1884 - val_accuracy: 0.9375
Epoch 4/10
50/50 [==============================] - 683s 14s/step - loss: 0.1074 - accuracy: 0.9575 - val_loss: 0.3353 - val_accuracy: 0.8568
Epoch 5/10
50/50 [==============================] - 682s 14s/step - loss: 0.0874 - accuracy: 0.9675 - val_loss: 0.3765 - val_accuracy: 0.8672
Epoch 6/10
50/50 [==============================] - 680s 14s/step - loss: 0.0479 - accuracy: 0.9856 - val_loss: 0.3621 - val_accuracy: 0.9141
Epoch 7/10
50/50 [==============================] - 686s 14s/step - loss: 0.0315 - accuracy: 0.9906 - val_loss: 0.3686 - val_accuracy: 0.8932
Epoch 8/10
50/50 [==============================] - 684s 14s/step - loss: 0.0360 - accuracy: 0.9900 - val_loss: 0.7757 - val_accuracy: 0.8333
Epoch 9/10
50/50 [==============================] - 683s 14s/step - loss: 0.0432 - accuracy: 0.9837 - val_loss: 0.6903 - val_accuracy: 0.8125
Epoch 10/10
50/50 [==============================] - 686s 14s/step - loss: 0.0122 - accuracy: 0.9950 - val_loss: 0.7686 - val_accuracy: 0.8880
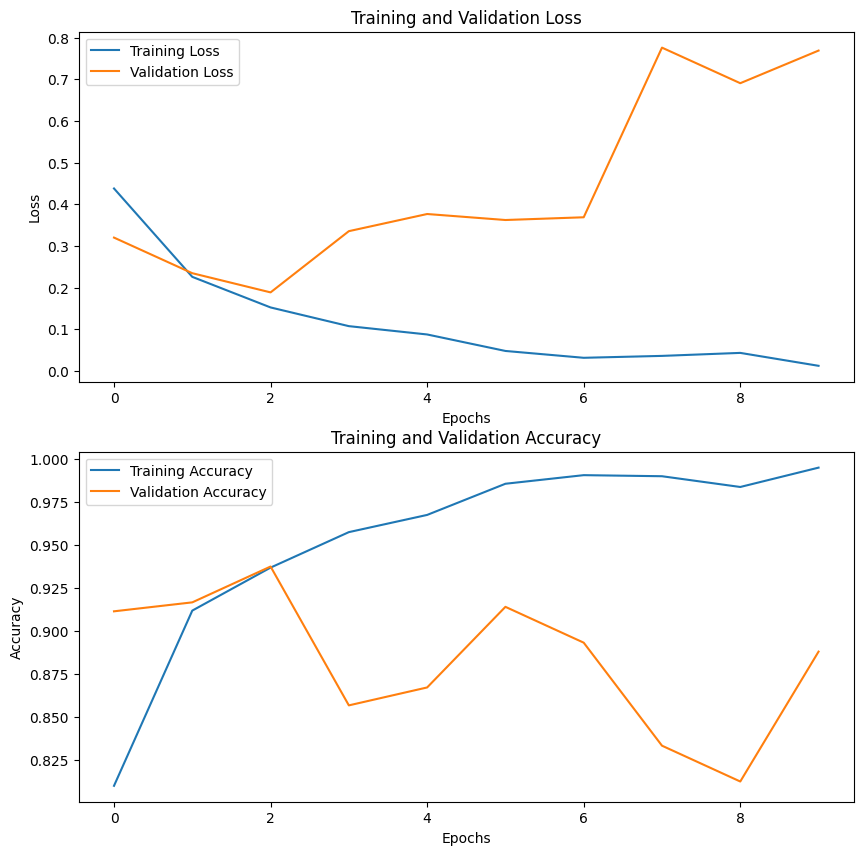
分析したデータから得られた情報
10回の結果から
Epoch=3 でトレーニング
Epoch 1/3
50/50 [==============================] - 659s 13s/step - loss: 0.8705 - accuracy: 0.6488 - val_loss: 0.3900 - val_accuracy: 0.8203
Epoch 2/3
50/50 [==============================] - 684s 14s/step - loss: 0.2907 - accuracy: 0.8825 - val_loss: 0.2672 - val_accuracy: 0.9062
Epoch 3/3
50/50 [==============================] - 645s 13s/step - loss: 0.2273 - accuracy: 0.9150 - val_loss: 0.2144 - val_accuracy: 0.9427
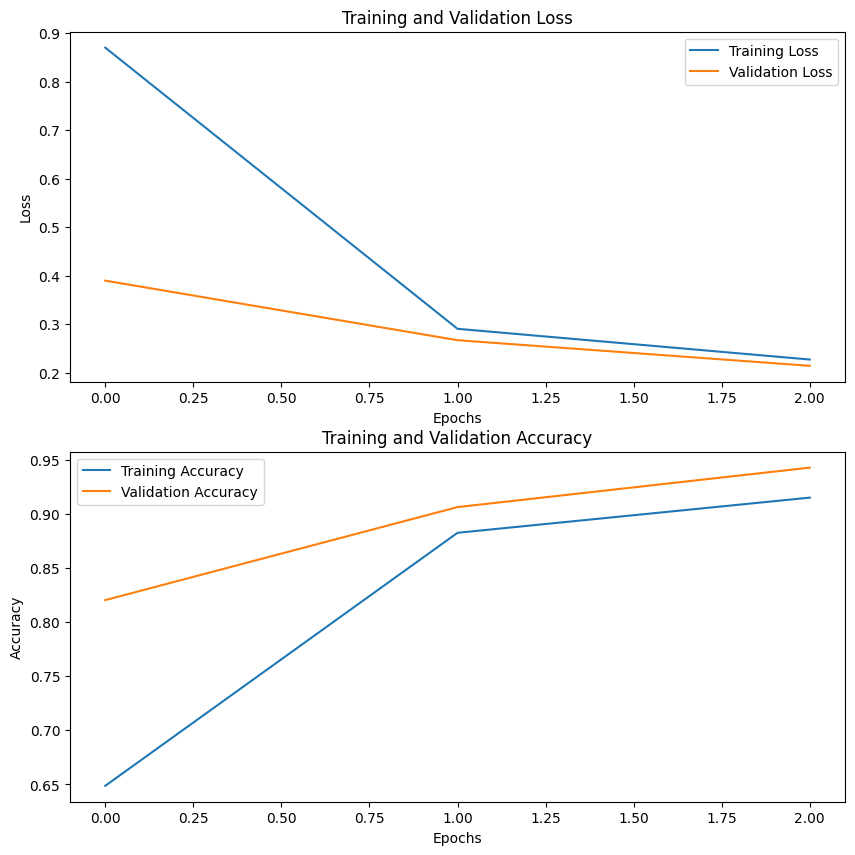
# 5. モデルの評価
# トレーニング後、モデルの性能を評価。
loss, accuracy = model.evaluate(validation_generator)
print(f'Validation Loss: {loss}')
print(f'Validation Accuracy: {accuracy}')
13/13 [==============================] - 46s 3s/step - loss: 0.2139 - accuracy: 0.9425
Validation Loss: 0.21391597390174866
Validation Accuracy: 0.9424999952316284
# 6. モデルの利用
drive.mount('/content/drive')
# 新しい画像に対して予測を行います。(確認)
from tensorflow.keras.models import load_model
# モデルの読み込み
# 特定のディレクトリから読み込む
loaded_model = load_model('/モデルの場所')
import numpy as np
from tensorflow.keras.preprocessing import image
def predict_image(img_path):
img = image.load_img(img_path, target_size=(416, 416))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
prediction = model.predict(img_array)
if prediction[0] > 0.5:
# cat2
print('This is cat2')
else:
# cat1
print('This is cat1')
predict_image('/写真')
判別アプリコード
import streamlit as st
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.image import img_to_array, load_img
import numpy as np
# モデルのロード
model = load_model('cat_classifier_modell_n_s_e3.h5')
# 画像サイズの定義
IMG_SIZE = (416, 416)
def classify_image(uploaded_file, model):
# 画像の前処理
img = load_img(uploaded_file, target_size=IMG_SIZE)
img = img_to_array(img)
img = np.expand_dims(img, axis=0) # バッチ次元の追加
img /= 255.0 # 正規化
predictions = model.predict(img)
return predictions
# Streamlit アプリ
st.title("Cat Classification App")
uploaded_file = st.file_uploader("Choose an image...", type="jpg")
if uploaded_file is not None:
st.image(uploaded_file, caption='Uploaded Image.', use_column_width=True)
st.write("")
st.write("Classifying...")
predictions = classify_image(uploaded_file, model)
# st.write(f"Predictions shape: {predictions.shape}")
# st.write(f"Predictions content: {predictions}")
# `predictions`の形状が1出力である場合
if predictions.shape[1] == 1:
cat2_prob = predictions[0][0]
cat1_prob = 1.0 - cat2_prob
st.write(f"Cat 1: {cat1_prob * 100:.2f}%")
st.write(f"Cat 2: {cat2_prob * 100:.2f}%")
else:
st.write("Unexpected prediction shape:", predictions.shape)
アプリ内で画像を判定させた結果(cat1 or cat2)
cat1の写真をアップした結果

cat2の写真をアップした結果

課題
今回は画像を判別する機能を実装しただけなので、
別途作成済みの愛猫達の健康管理アプリ(日付の選択、体重の記録やグラフ、病気の症状、通院記録の有無等を記録できるもの)と組み合わせ、
写真の管理や、日記その他機能等を追加し、より健康管理記録に特化したアプリを作製したいです。
まとめ
手持ちのデータから画像分類モデルを作製し、結果を排出するアプリを作成しました。
Discussion