CLIで動く開発AIエージェントの仕組みと特徴
CLIから動作し、GitHubのIssueをもとにコードを解析・編集し、Pull Request(PR)を自動作成する「Issue Agent」を開発しました。
この記事では、Issue Agentの仕組みや特徴について紹介します。
Issue Agent
今回実装した開発AIエージェントはこちらです。
Issue Agentは、GitHubのIssueを読み取り、その内容に基づいてコードベースを自律的に解析し、
必要なファイルの作成や編集を行います。最終的には、自動でPRを作成する開発エージェントです。
例えば、こんなようなissueがあったとします。
# TODO
.gitignore ファイルを現在のリポジトリ構成に合わせて見直す。
たとえば、.gitignoreの設定が無秩序に増えてしまったために整理が必要だけれど、つい後回しにしていたIssueがあったとします。
これをIssue Agentに渡すことで、.gitignoreの内容や使っているフレームワークや利用技術を見て、 新しく.gitignoreを更新するPRを作ってくれます。
AIエージェント
ここでは AIエージェントを以下のように定義しておきます。
AIエージェントとは、環境の情報をもとに自律的に判断し、特定の目的を達成するために動作するAI技術を活用したソフトウェア。
AIエージェントはさまざまな分野で活躍できますが、今回開発したものはソフトウェア開発に特化したエージェントです。
GitHub Copilot のように、エディタに統合されてコーディングをサポートするものもありますが、
Issue Agentはエディタとは別の環境で動作します。CLIからコマンドとして起動し、GitHub Issueによる指示から目的達成に向かって、コードを読んだり編集したりGitHubへPRを出すAIエージェントです。
開発した背景
ソフトウェア開発・運用において、幅広いタスクをこなすAIエージェントよりも、
特定の領域に特化し、実運用で確実に使えるAIエージェントを作りたいと考えました。
もともとの目的は「単にAIエージェントを作る」ことではなく、LLMを活用することで、従来自動化が難しかった業務を効率化できると感じたことにありました。
エディタに統合されるAIツールとは異なり、指示を出す開発者がコードを書いている裏方でタスクの自動化を実現したかったため、エディタ外で動作するエージェントの開発を目指しました。
コードを書く時間の短縮ではなく、ソフトウェアの開発や運用業務自体をGitHub Issueを通して任せられる仕組みを目指しています。
重視した点
実現させるにあたって、次の点を重視しています。
- エージェントの能力を制限すること
AIエージェントが自律的にコードを編集したりコマンドを実行したりする際、
その権限の範囲を適切に設定することは重要な関心ごとです。
例えば、エージェントがOS環境を持ちシェルコマンドを実行できるとしましょう。
エージェントが自律的に動く際、環境変数に保存した機密情報を誤って外部へ送信する危険性があります。
そのため、エージェントの能力を制限・管理する設計が必要です。
エージェントに無制限な権限を与えるのではなく、あらかじめ定義した操作のみを実行することで、
セキュリティを高めています。
具体的には以降の特徴で紹介します。
- 実運用における環境に適合できるエージェントであること
OSSのAIエージェントはたくさんありますが、個人で手元のPCで動かして利用する分には問題ないかもしれません。
一方で、実際の業務で利用する場合は、設定や環境の統一、セキュリティなど運用上の考慮が不可欠です。
AIエージェントを動かすための環境構築やデプロイを必要とせず、CLIからのコマンド実行だけで即座に動作するAIエージェントを目指しました。
またプロンプトの入出力データの保存や外部への送信が最低限になるように設計しています。サービスとしての提供ではなく、CLIとしてOSSだからこそできることだと考えています。
さらに、GitHub Actionsでの利用においても運用を考慮していて、OIDCを利用し、AWS Bedrockを利用できるようにすることで、APIキーの管理を不要にしています。
開発者の手元のPCでも動かすことができ、GitHub Actionsでの利用も想定したエージェントです。
特徴
できることを限定し制限する
エージェントにファイルを開いたり、編集したり、あるいは開発環境を構築してもらうにはシェルを実行できるような環境がいいかもしれません。
任意のコマンドを実行するようなエージェントもあるでしょう。
環境に適応しやすい反面、LLMの指示によって外部情報を送信する危険なシェルコマンドを実行してしまうリスクがあります。
Issue Agentでは、任意のシェルを実行する形式ではなくて、環境で実行される操作はすべて事前に関数名と引数を定義したものを使うようにします。
事前に定義した関数をLLMのtool(Function Calling)を介して実行し、環境を操作します。
任意のシェルを実行できるほうが、開発者が普段行う環境構築やコンパイル作業をエージェントに任せやすくなるため、柔軟性があります。
一方でできることが制限されると、エージェントを利用している人にとっては何ができるかを明確に管理できるため、リスク管理やセキュリティ面でも強化されます。
また、Issue Agentはサービスとして提供するわけではないので、コードなどが入力されたプロンプトはLLMのプロバイダーに送信されるだけで外部に保存しません。
LLMを使ったサービスやツールにおいては、データがどこに保存され、どう扱われるのかは重要な関心ごとではないでしょうか。
Issue Agentで選んだこと
自由にさまざまなことができることは捨て、できることを制限してエージェントは何ができるのがコントロールすることを重視。
シンプルなタスクの自動化
開発AIエージェントは、エディタに統合されるものや自ら開発環境を構築して開発を進めるものなどいくつかの形態で登場しています。
指示の仕方次第では、人間のエンジニアに匹敵する成果を生み出す可能性もあるかもしれませんが、期待する成果物を得るためには、
明確な指示と適切なコンテキストの提供が必須です。
とはいえ、指示を出す側としては、膨大な情報を整理し詳細な指示を作成するのは大きな負担となります。
できれば、シンプルな指示だけでエージェントに任せたいのが本音でしょう。
Issue Agentは、新機能の追加や大規模な変更、長期的な議論を要するタスクではなく、開発者が「後でやろう」と後回しにしがちな作業や、
ひとたびお手本となるPRができれば横展開が可能なタスクに特化しています。
例えば、変更可能なlintツールや自動化ツールが存在しない状況で、どうしても人間がPRを出す必要があるタスクなどがその対象です。
さらに、業務で利用するエージェントには、細かなコミュニケーションを省き、できるだけ迅速にタスクを完了してもらうことが求められます。
最初の指示だけでなく、インタラクティブなやりとりを重ねれば、期待に近い成果物を得られる可能性もありますが、その分人間の介在時間が増えてしまいます。
Issue Agentの場合、最初にGitHub Issueだけを渡せば、あとはリポジトリの内容を自律的に把握し、最終的なPRを作成するまで進めます。
作成されたPRが期待する成果物になっていなかったら、無駄なPRが出来上がってしまうこともあります。
そのため、開発者が最初の指示段階で大まかな成果物のイメージを持てるタスクが、依頼する際に適しているということになります。
Issue Agentで選んだこと
幅広いタスクをこなすのではなく、特定のシンプルなタスクを迅速かつ確実に実行できるエージェントであること。
インタラクティブなやりとりに頼らず、最初の明確な指示だけで十分な成果物を得るというアプローチを採用している点。
Issue Agentの全体像と詳細
ここからはIssue Agentの全体像と、具体的な機能について紹介します。
全体像
Issue Agentの全体的な構成を以下に示します。それぞれの要素について、順を追って説明します。
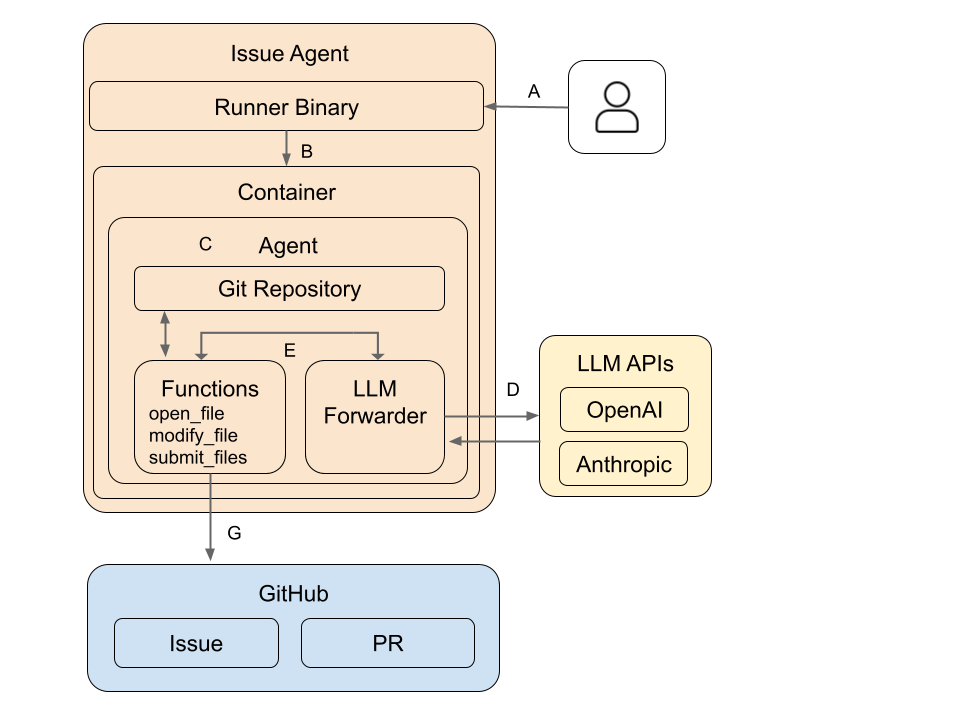
詳細
A - エージェントの起動
issue-agent create-pr clover0/issue-agent/issues/1 --base_branch main --model claude-3-5-sonnet-latest
このコマンドでCLIからエージェントを起動します。引数には clover0/issue-agent/issues/1 のように対象のissueを指定します。
上記の例では clover0/issue-agent リポジトリのissue番号1が対象になります。
Issue Agentは、指定されたissueが紐づくリポジトリに対してのみPRを作成します。
他のリポジトリに対して誤ってPRを出すことがないような設計にしています。
Runner Binaryは、エージェント本体が梱包されているコンテナを起動するバイナリです。
起動するホストマシンから設定ファイルや環境変数をコンテナに渡す準備を行います。
その後コンテナを構築してコンテナ内のバイナリが実行されます。
B - コンテナの構築
Dockerを利用しています。当初は Docker を利用するか悩みましたが、多くの環境で広くインストールされているため、
ユーザーの環境構築の手間を減らす目的で採用しました。
Dockerを利用しコンテナを構築しているのは、エージェントの環境はホストマシンとは分離したいためです。
仮想マシンのほうが分離レベルは高いものの、軽量で素早く起動できることを優先し、コンテナを採用しました。
C - Agentの起動
コンテナの構築後、コンテナ内に配置されたバイナリが実行され、エージェント本体が起動します。
この段階ではまだ自律的な処理には移らず、まずリポジトリをコンテナ内にクローンし、GitHub から issue を取得します。
その後、LLMに送信するプロンプトを構築し、ここから自律的な処理へと移行します。
D, E - LLMとのやりとり
ここがAIエージェントとして自律的であるところです。
D - プロンプトの送信
構築したプロンプトをLLMに送信し、レスポンスを受け取ります。
E - 関数の実行と実行結果の送信
LLMからのレスポンスには、図のFunctionsに記載しているような関数を利用したいという要求が発生します。
その要求に応じて、利用する関数名と引数を取り出し、実装している関数を呼び出します。
いわゆる Tool use(Function Calling) を使っているだけです。Tool use (Function Calling) とは、LLMが外部の関数を呼び出して動作する仕組みのことです。
今回のIssue Agentの例でいえば、LLMが直接GitHubのリポジトリ内のファイルを編集するということはできません。
リポジトリのファイルを操作できるのはLLMに指示を出している環境側なので、LLMからtoolを介してファイルを編集できる環境側に指示を出してもらうという形になります。
したがってDとEでは、以下の1 ~ 3を繰り返すループ構造になっています。
- E: エージェントの環境側でファイルの参照や編集をする
- D: 環境での操作結果をLLMに送信する
- D: LLMがファイルの参照や編集をするためにtoolを引数とともに実行を要求してくる
Issue Agentで実装しているのは以下のようなtoolです。
-
list_files: ファイルの一覧を取得する。ls -lコマンドのような動作。 -
open_file: ファイルの内容を取得する。cat {file}コマンドのような動作。 -
put_file: ファイルの内容を変更する。echo {content} > {file}のような動作。 -
search_files: 指定したキーワードでファイルを検索するgrep -rl "{keyword}"のような動作。 -
submit_files: 変更内容をgit commitしてPRを作成する。 - ...
これらのtoolはIssue Agentの設定で利用できるか否かを指定できるようになっています。
tool利用の流れ
具体的にこれらのtoolをどのようにLLMに使ってもらうかというのを少し紹介します。
まず、エージェントは与えられたissueを解釈して、リポジトリのどの箇所を変更すればいいかを計画します。
issue自体に 「path/to/ あたりを変更してほしい」といったようなヒントがあれば、
LLMからは list_files("path/to") と要求してきます。
エージェントはlist_files の実行結果をLLMに返します。list_filesの結果はls -lコマンドを実行したときと同じような出力です。
するとLLMは、list_filesの結果にあったfile_a(例)を開きたいと要求してきます。
open_file("path/to/file_a")といった要求で、具体的なファイル名を指定して要求してくるので、要求されたファイルを開き、中身をLLMに返します。
今度は、LLMはissueの内容を達成するためにfile_aの内容を変更する必要があれば、変更内容とともに modify_file("path/to/file_a", "新しいファイルの内容...") と要求してきます。
といった感じでしばらく list_files、open_file、modify_file といった関数を繰り返し使ってLLMとやりとりを続けます。
G - PRの作成
LLMがissueの内容を達成できたと判断したら、最後に submit_files 関数を使って、ここまでの変更をcommitしてGitHub にPRを作成します。
これでissueからPRを作成するまでの一連の流れが完了します。
利用技術
言語、フレームワーク
PythonでLangChainやLangGraphを使ってエージェントを実装している例は多いですが、
今回は以下の理由からフレームワークを使わずに、Goでスクラッチ実装しています。
- CLIで起動したかったため、配布しやすいシングルバイナリ化できるGoを選択
- 多くのサードパーティに依存したスピードの出る開発よりも、標準パッケージを中心とした信頼できる依存関係による安定性を重視
- エージェントの実装経験がなかったため、学習を兼ねてスクラッチで実装
LLM API
モデルごとの成果物も比較もしてみたかったので、いくつかのモデルに対応するようにしました。
ちなみにIssue AgentではClaudeを推奨しています。開発やコーディングにおいて指示の解釈が正確でタスクの実行精度が高い印象です(執筆時点の今のところ)。
- Anthropic
- Claude 3.5 Sonnet
- OpenAI
- GPT-4o
- GPT-4o-mini
- AWS Bedrock
- claude-3-5-sonnet
AWSを利用できるならBedrock(Claude 3.5 sonnet)がおすすめです。
API keyではなくAWSのSSOで利用できますし、CIからはOIDCを使ってモデルを利用できます。キーの管理が気になる場合はBedrockがおすすめです。
まとめ
CLI上で動作する開発向けのAIエージェントで、GitHubのIssueを起点にコードベースを自律的に解析・編集し、必要な変更を加えた上で自動でPull Requestを作成します。
指定されたIssueの内容に基づいて動作するため、開発者は簡単な指示だけでタスクの自動化を実現できます。
単なるエディタ支援ツールではなく、運用面で確実に活用できる、特定のタスクに特化し、
従来、人手で行っていた後回しにされがちな定型作業(例:.gitignoreの整理など)などを自動化し、開発や運用の現場におけるタスクを担えるエージェントを目指しました。
いくつかのモデルに対応していますが、LLMの進化に伴って対応するモデルも拡張する予定です。
また、機能追加や改善も継続して行っていく予定です。気になる方がもしいらっしゃったらウォッチしていただけると嬉しいです。
さくっと使い始めたい方は以下の記事で紹介していますのでご覧ください。
Discussion