🐳
Rescale の Docker で NVIDIA NGC を使う: LAMMPS を例に
この記事について
Rescale の計算ノードにインストールされた Docker を使用して, NVIDIA NGC からコンテナを持ってきて実行する方法を示します。実行する題材として, LAMMPS | NVIDIA NGC の Overview の内容を実行します
事前準備: Docker の有効化
Rescale のジョブ設定時のソフトウェア一覧に Docker がありますが、デフォルトではグレーアウトされています
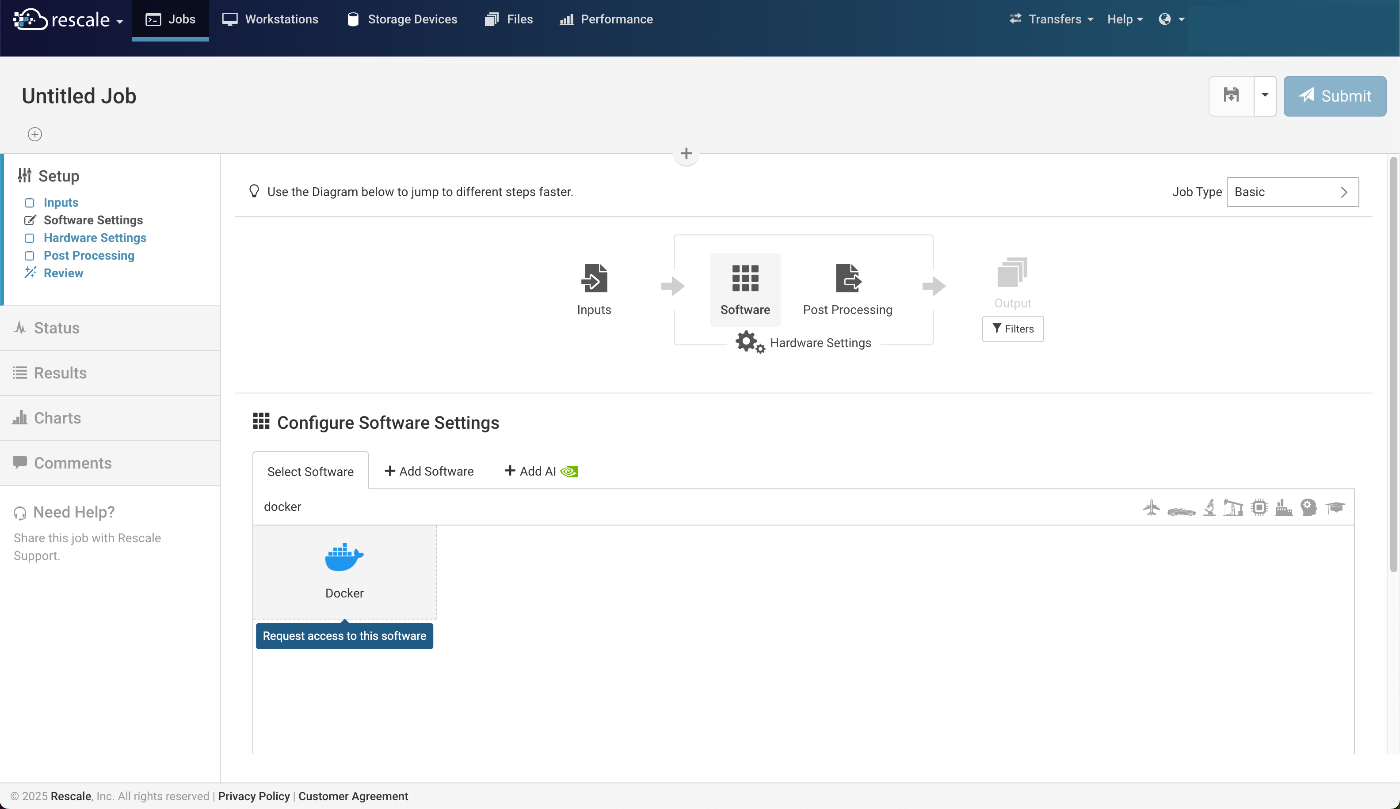
グレーアウトされている Docker のアイコンをクリックして, Software Request を送ります
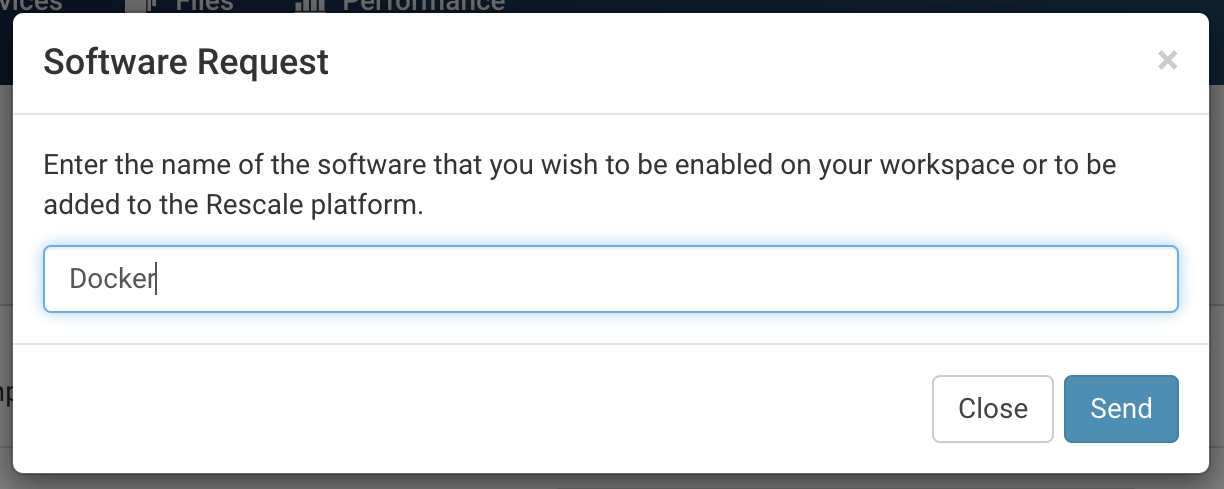
Rescale の人(営業、技術)に相談したり, Rescale Support にサポートリクエストを出すと、よりスムーズかもしれません
ジョブ設定
以下の設定でジョブを実行します。解析の入力ファイルは wget コマンドを使ってジョブ中で取得するので、入力ファイル(Inputs)は なし となっています. LAMMPS のバージョンは、この記事を書いている時点で NGC 上の LAMMPS の最新版である 15Jun2023 を使用します
- Inputs: なし
- Software Settings
- Docker latest (Rescale linux8 GPU)
- Command
TAG=patch_15Jun2023
wget https://www.lammps.org/inputs/in.lj.txt
wget https://gitlab.com/NVHPC/ngc-examples/-/raw/master/lammps/single-node/run_lammps.sh
chmod +x run_lammps.sh
docker run --rm --gpus all --ipc=host -v $PWD:/host_pwd -w /host_pwd nvcr.io/hpc/lammps:$TAG ./run_lammps.sh
- Hardware Settings
- Mallorn 12 cores (NVIDIA A100, 1 GPU)
- Walltime: 1 hour
実行結果
log.lammps が出力されます。特にエラーメッセージはなく、また process_output.log が Exited with code 0 で終了していることから、正常終了しているように見受けられます。以下に出力された log.lammps を貼ります
LAMMPS (15 Jun 2023)
KOKKOS mode is enabled (src/KOKKOS/kokkos.cpp:107)
will use up to 1 GPU(s) per node
using 1 OpenMP thread(s) per MPI task
package kokkos
package kokkos cuda/aware on neigh full comm device binsize 2.8
# 3d Lennard-Jones melt
variable x index 1
variable y index 1
variable z index 1
variable xx equal 20*$x
variable xx equal 20*8
variable yy equal 20*$y
variable yy equal 20*4
variable zz equal 20*$z
variable zz equal 20*8
units lj
atom_style atomic
lattice fcc 0.8442
Lattice spacing in x,y,z = 1.6795962 1.6795962 1.6795962
region box block 0 ${xx} 0 ${yy} 0 ${zz}
region box block 0 160 0 ${yy} 0 ${zz}
region box block 0 160 0 80 0 ${zz}
region box block 0 160 0 80 0 160
create_box 1 box
Created orthogonal box = (0 0 0) to (268.73539 134.3677 268.73539)
1 by 1 by 1 MPI processor grid
create_atoms 1 box
Created 8192000 atoms
using lattice units in orthogonal box = (0 0 0) to (268.73539 134.3677 268.73539)
create_atoms CPU = 0.522 seconds
mass 1 1.0
velocity all create 1.44 87287 loop geom
pair_style lj/cut 2.5
pair_coeff 1 1 1.0 1.0 2.5
neighbor 0.3 bin
neigh_modify delay 0 every 20 check no
fix 1 all nve
run 100
Generated 0 of 0 mixed pair_coeff terms from geometric mixing rule
Neighbor list info ...
update: every = 20 steps, delay = 0 steps, check = no
max neighbors/atom: 2000, page size: 100000
master list distance cutoff = 2.8
ghost atom cutoff = 2.8
binsize = 2.8, bins = 96 48 96
1 neighbor lists, perpetual/occasional/extra = 1 0 0
(1) pair lj/cut/kk, perpetual
attributes: full, newton off, kokkos_device
pair build: full/bin/kk/device
stencil: full/bin/3d
bin: kk/device
Per MPI rank memory allocation (min/avg/max) = 1118 | 1118 | 1118 Mbytes
Step Temp E_pair E_mol TotEng Press
0 1.44 -6.7733681 0 -4.6133683 -5.0196694
100 0.75927734 -5.761232 0 -4.6223161 0.19102612
Loop time of 1.17259 on 1 procs for 100 steps with 8192000 atoms
Performance: 36841.392 tau/day, 85.281 timesteps/s, 698.622 Matom-step/s
99.6% CPU use with 1 MPI tasks x 1 OpenMP threads
MPI task timing breakdown:
Section | min time | avg time | max time |%varavg| %total
---------------------------------------------------------------
Pair | 0.089304 | 0.089304 | 0.089304 | 0.0 | 7.62
Neigh | 0.17758 | 0.17758 | 0.17758 | 0.0 | 15.14
Comm | 0.046727 | 0.046727 | 0.046727 | 0.0 | 3.98
Output | 0.00029145 | 0.00029145 | 0.00029145 | 0.0 | 0.02
Modify | 0.81515 | 0.81515 | 0.81515 | 0.0 | 69.52
Other | | 0.04354 | | | 3.71
Nlocal: 8.192e+06 ave 8.192e+06 max 8.192e+06 min
Histogram: 1 0 0 0 0 0 0 0 0 0
Nghost: 727553 ave 727553 max 727553 min
Histogram: 1 0 0 0 0 0 0 0 0 0
Neighs: 0 ave 0 max 0 min
Histogram: 1 0 0 0 0 0 0 0 0 0
FullNghs: 6.15293e+08 ave 6.15293e+08 max 6.15293e+08 min
Histogram: 1 0 0 0 0 0 0 0 0 0
Total # of neighbors = 6.1529347e+08
Ave neighs/atom = 75.109066
Neighbor list builds = 5
Dangerous builds not checked
Total wall time: 0:00:05
Discussion