🧑✈️
Cohere Command R+をAzureで完全従量課金で利用できるので試してみた。
Annoucing Cohere Command R+, now available on Azure
Cohere's Command-R+ Specialized Mode for RAG and Tools
Cohere Command R+ とは
検索拡張生成(RAG)や高度なタスクを自動化するためのツールの使用など、高度な機能を備えた1,040億のパラメータのモデルです。
日本語にも対応していますが、現状、RAGとmulti-step tool use (Agent)はEnglishのみとなっています。
Note, however, that RAG and multi-step tool use (agents) are currently only available in English.
試してみた。
Azure AI Stdioを作成
learnの通りに作成すればいけます。
ただし、Azure AI は作成時のみリージョン指定できますが、変更不可なので注意
Model Catalog
Pay-as-you-goからデプロイします。

Command R+のエンドポイントはpublicのみ、EntraID認証はつかえず、API Keyのみのようです。
Pricing

Playgroundから
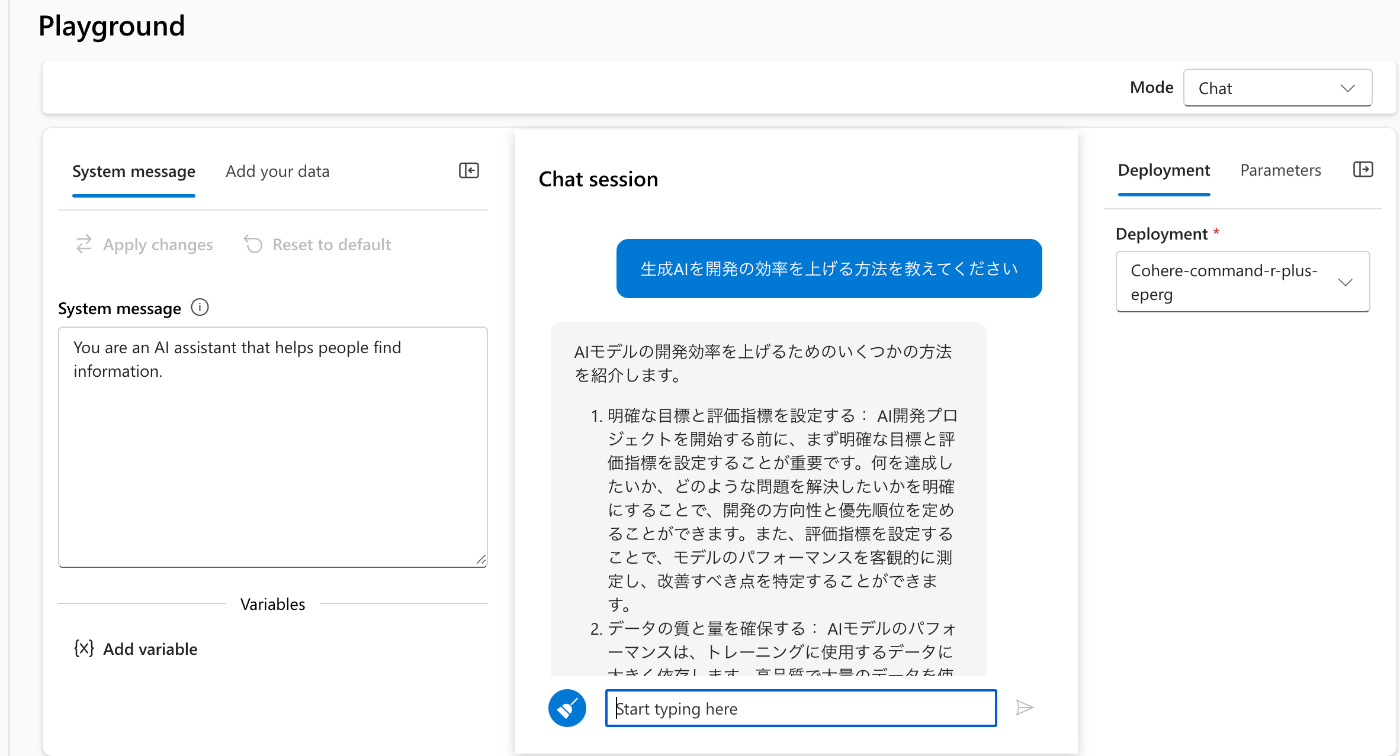
AzureOpenAIのPlaygroundにあったView Codeなどはつかえない。
pythonから
pip install cohere
cohere.Clientのパラメータとして、base_urlにModelをデプロイしたときに払い出されるEndpoint Targetを設定要
Streaming responseの実装例になります。
import cohere
co = cohere.Client(
base_url="https://<endpoint>.<region>.inference.ai.azure.com/v1", api_key="<key>"
)
for event in co.chat_stream(
message="生成AIを開発の効率を上げる方法を教えてください"
):
if event.event_type == "text-generation":
print(event.text, end='')
elif event.event_type == "stream-end":
print(event.finish_reason)
AIモデルの開発効率を上げるためのいくつかの方法があります。以下にいくつかの提案を示します。
1. 明確な目標と評価指標の設定:AIモデルの開発を始める前に、まず明確な目標を設定し、成功を測定するための評価指標を決定することが重要です。これにより、開発プロセスの全体的な方向性が明確になり、モデルのパフォーマンスを客観的に評価して改善することができます。
2. データの質と量:AIモデルのパフォーマンスは、トレーニングに使用するデータに大きく依存します。高品質で関連性の高い大量のデータを収集および準備することが重要です。これには、データのクリーニング、前処理、ラベリングが含まれる場合があります。データの多様性と代表性も考慮する必要があります。
3. 実験と反復:AIモデルの開発は反復的なプロセスであることが多いです。さまざまなアルゴリズム、アーキテクチャ、ハイパーパラメーターを実験し、比較することで、最も優れたパフォーマンスを発揮する組み合わせを見つけることができます。反復的なアプローチを採用し、モデルのパフォーマンスを定期的に評価および改善することで、時間の経過とともに改良することができます。
4. 転移学習と事前トレーニング:転移学習は、大規模なデータセットで事前トレーニングされたモデルを使用して、より小さなデータセットでカスタムタスクにモデルを適応させる技術です。これにより、トレーニングに必要なデータと時間の量を削減できます。 BERT や GPT などの事前トレーニングされた言語モデルは、特定のタスクに素早く適応させることができ、優れた結果が得られます。
5. 計算リソースの活用:AIモデルのトレーニングには、強力なコンピューティング リソースが必要になる場合があります。クラウドコンピューティングプラットフォームを利用することで、GPU や TPU などのスケーラブルで高性能なハードウェアにアクセスできます。これにより、トレーニング時間を短縮し、より複雑なモデルを実験することが可能になります。
6. 自動化とツール:開発プロセスを自動化できるツールやフレームワークを利用することで、効率が大幅に向上する場合があります。たとえば、TensorFlow や PyTorch などの深層学習フレームワークは、モデルのプロトタイピングと実験を高速化するために使用できるさまざまなツールとライブラリを提供します。また、継続的統合および継続的デプロイ (CI/CD) プラクティスを実装することで、コード変更を自動的にテストおよびデプロイできます。
7. チームワークとコラボレーション:AI 開発は複数の専門分野にまたがるため、さまざまなスキルを持つチームメンバー間の効果的なコラボレーションが不可欠です。データサイエンティスト、エンジニア、ソフトウェア開発者、ドメインエキスパートが協力することで、問題をより効率的に解決し、革新的なソリューションを開発することができます。
8. 最新技術の継続的な学習:AI は急速に進化する分野であるため、最新のアルゴリズム、技術、ベストプラクティスについて常に最新の情報を得ることが重要です。研究論文、オンラインコース、カンファレンス、コミュニティフォーラムに参加することで、新しいアイデアや手法を学び、開発プロセスに適用することができます。
9. モデル圧縮と最適化:AI モデルのサイズと計算要件を削減するモデル圧縮技術を検討してください。これには、ネットワークの剪定、量子化、知識蒸留などの技術が含まれます。これにより、モデルの効率が向上し、デプロイと実行が容易になります。
10. 継続的な監視と改善:AI モデルを本番環境にデプロイした後も、パフォーマンスを監視し、継続的に改善することが重要です。モデルが新しいデータに適応し続けるように再トレーニングし、新しい傾向や変化を捉えることができます。また、ユーザーからのフィードバックを収集し、モデルの出力の品質を向上させるために使用することもできます。
これらの戦略を組み合わせて、開発プロセスを反復的かつ反省的にアプローチすることで、AI モデルの開発効率を大幅に向上させることができます。COMPLETE
Single-Step Tool Use ( Function Calling )
下記のサンプルを試したが、500 Internal Errorになった。
Traceback (most recent call last):
File "/Users/hiruta/.pyenv/versions/3.9.18/lib/python3.9/site-packages/cohere/base_client.py", line 673, in chat
_response_json = _response.json()
File "/Users/hiruta/.pyenv/versions/3.9.18/lib/python3.9/site-packages/httpx/_models.py", line 761, in json
return jsonlib.loads(self.content, **kwargs)
File "/Users/hiruta/.pyenv/versions/3.9.18/lib/python3.9/json/__init__.py", line 346, in loads
return _default_decoder.decode(s)
File "/Users/hiruta/.pyenv/versions/3.9.18/lib/python3.9/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/Users/hiruta/.pyenv/versions/3.9.18/lib/python3.9/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/hiruta/test4.py", line 46, in <module>
response = co.chat(
File "/Users/hiruta/.pyenv/versions/3.9.18/lib/python3.9/site-packages/cohere/client.py", line 33, in wrapped
return method(*args, **kwargs)
File "/Users/hiruta/.pyenv/versions/3.9.18/lib/python3.9/site-packages/cohere/base_client.py", line 675, in chat
raise ApiError(status_code=_response.status_code, body=_response.text)
cohere.core.api_error.ApiError: status_code: 500, body: Internal Server Error
Discussion