Google Cloud Pub/Sub のデッドレタートピックを探求する
はじめに
こんにちは。クラウドエース株式会社 第一開発部の前山です。
アプリケーション開発を中心に取り組みつつ、Google Cloud 公式認定トレーナーとしても活動しています。
大規模なシステムにおいて、メッセージングは重要な役割を果たしています。特に Google Cloud Pub/Sub は、その信頼性と柔軟性から多くのシステムで採用されています。しかし、実運用では必ずメッセージ処理の失敗という課題に直面します。
本記事では、この課題に対する重要な解決策として、Pub/Sub のデッドレタートピックについて深く掘り下げていきます。デッドレタートピックの基本的な概念から実装方法、さらには代表的な活用パターンまで、詳しく探求していきます。
私自身、あるプロジェクトで Pub/Sub を利用したメッセージング処理を担当した際、メッセージの再試行とエラー処理に関する課題に直面しました。その経験から得た知見と、デッドレタートピックの重要性について共有できればと思います。
本記事を通じて、より信頼性の高いメッセージング基盤の構築に向けたヒントを得ていただければ幸いです。
対象読者
- メッセージングシステムを運用している/検討している開発者
- Google Cloud でシステム運用している/検討している方
- 障害に強いシステム設計に興味がある方
Pub/Sub について
デッドレタートピックの説明に入る前に、Pub/Sub について確認しておきましょう。
Google Cloud の Pub/Sub は、非同期メッセージングを実現するフルマネージドサービスです。
システムコンポーネント間で信頼性の高いメッセージ配信を実現し、疎結合なアーキテクチャの構築を可能にします。
メッセージングサービスを利用することで、システム間の通信がより柔軟になります。
例えば、ECサイトで注文が入った際に、在庫管理システムや配送システム、請求システムなど複数のシステムに通知する必要がある場合、直接的な通信では各システムの状態や実装を考慮する必要があります。

図: 直接通信と Pub/Sub を利用した通信の比較
しかし、Pub/Sub を利用すれば、メッセージをトピックに発行するだけで、必要なシステムがそれぞれのタイミングでメッセージを取得して処理できます。これにより、システム間の依存関係を最小限に抑え、より柔軟なシステム構築が可能になります。
主要な概念
Pub/Subの主要な概念について説明します。

図: Pub/Sub の基本アーキテクチャ
上図のように、Pub/Sub は「Publisher」「Topic」「Subscription」「Subscriber」の4つの主要コンポーネントで構成されています。
Message(メッセージ)
Publisher から送信されるデータの単位です。Pub/Sub システムを流れる実際のデータを表します。
Publisher(パブリッシャー)
メッセージを発行するアプリケーションやサービスです。Publisher は、処理すべきデータやイベントをメッセージとしてTopicに発行します。
Topic(トピック)
メッセージを格納する論理的なチャネルです。Publisher は、この Topic にメッセージを発行します。
一つの Topic に対して、複数の Publisher からメッセージを発行することができます。
Subscription(サブスクリプション)
Topic に発行されたメッセージを受信するための設定です。Subscriber は、この Subscription を通じてメッセージを受信します。
一つの Topic に対して複数の Subscription を作成でき、それぞれが独立してメッセージを受信できます。
Subscriber(サブスクライバー)
Subscription を通じてメッセージを受信し、処理を行うアプリケーションやサービスです。
Pub/Subの一般的なユースケース
Pub/Sub は様々なユースケースで利用されていますが、特に以下のようなシナリオで効果を発揮します。
イベント駆動アーキテクチャ
- マイクロサービス間の非同期通信
- イベントソーシング
- リアルタイムのデータ処理パイプライン
システム統合
- レガシーシステムとモダンなシステムの連携
- クロスリージョンデータ同期
- 異なるサービス間のデータ連携
負荷分散とスケーリング
- バックエンド処理の分散化
- バッチ処理のスケールアウト
- システム間の負荷の平準化
デッドレタートピックについて
ここまで Pub/Sub の基本的な概念とユースケースについてみてきましたが、実際のシステム運用では、メッセージ処理の失敗は避けられない現実があります。
そこで、本題であるデッドレタートピックについて詳しく見ていきましょう。
デッドレタートピックとは
デッドレタートピックは、Pub/Sub において正常に処理できなかったメッセージを保存するための特別な Topic です。メッセージングシステムにおける「安全網」として機能し、処理に失敗したメッセージ(デッドレター)を確実にキャプチャして保持します。

図: デッドレタートピックを含むメッセージングフロー
通常のメッセージ処理フローでは、Subscriber がメッセージを受信し処理を行いますが、ネットワークエラーやアプリケーションの不具合など、様々な要因で処理が失敗することがあります。
デッドレタートピックは、このような失敗したメッセージを通常のフローから切り離し、専用の経路で管理することを可能にします。
デッドレタートピックによって解決できる問題
メッセージの滞留に起因する問題
Pub/Sub を利用したシステムにおいて、特に注意が必要なのがメッセージ処理の失敗による滞留問題です。この問題は、システムの安定性とコストに大きな影響を与える可能性があります。
具体的な例として、Subscriber が障害によってメッセージを正常に処理できない状況を考えてみましょう。

図: デッドレタートピックがない場合のメッセージ滞留
デッドレタートピックが設定されていない場合、Subscription は同じメッセージを繰り返し Subscriber に送信し続けます。この結果、以下のような深刻な問題が発生する可能性があります。
- メッセージの有効期限切れによるデータ損失
- 不要な再送信によるリソース消費とコストの増大
- 処理遅延の蓄積による下流システムへの影響
etc...
デッドレタートピックを使用することで、一定回数の配信失敗後にメッセージを通常のフローから切り離し、別経路での処理が可能になります。これにより、処理失敗の繰り返しによる通常フローへの過剰な負荷を防ぐことができます。
さらに、デッドレタートピックに集められたメッセージは、以下の宛先に転送することができます。
- Cloud Storage
- BigQuery
- カスタムアプリケーション
このように、メッセージを通常フローから切り離すだけでなく、システムの安定性を維持しながら柔軟な異常系処理を実現できます。
デッドレタートピックの実装と動作確認
ここからは、デッドレタートピックの具体的な実装方法と動作確認を行っていきます。以下の4つのシナリオを通じて、デッドレタートピックの基本的な使い方から応用的な活用方法まで見ていきましょう。
- デッドレタートピックの構築と基本的な動作確認
- Cloud Storage への転送設定
- BigQuery への転送設定
- アプリケーションとの連携
デッドレタートピックの構築と基本的な動作確認
まずは基本的なデッドレタートピックの構築と動作確認を行います。
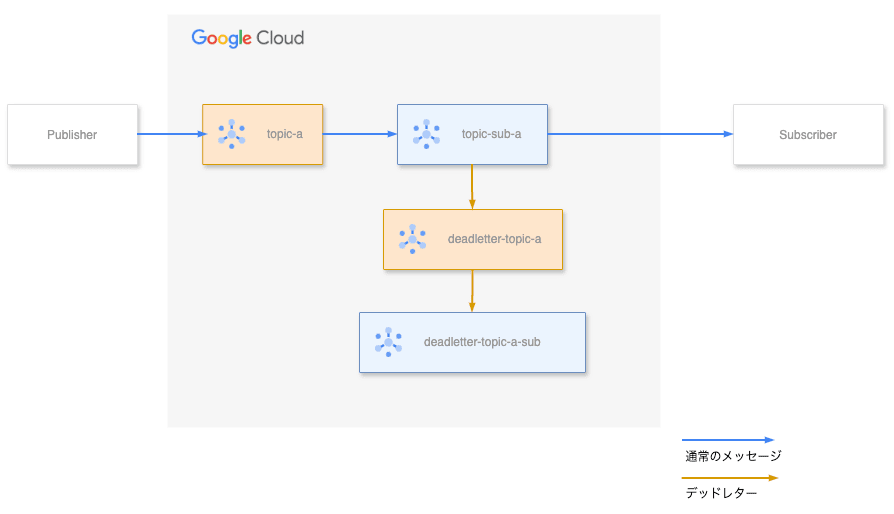
図: デッドレタートピックの構築の完成イメージ
1. デッドレタートピックの構築
今回は上記の構成で実装を進めます。topic-aというトピックとtopic-sub-aというサブスクリプションが既に存在する環境から始めます。
まず、デッドレターを受け取るための専用トピックdeadletter-topic-aを作成します。

次に、topic-sub-aに対してデッドレタートピックの設定を行います。

デッドレタートピックを利用するために必要な権限を設定します。警告アイコンが表示された場合は、指示に従って必要な権限を付与します。

2. 動作確認
デッドレタートピックが正しく機能することを確認するため、意図的に処理を失敗させるアプリケーションをローカルで実行します。
(参考)今回使用しているアプリのコードはこちらになります。
import os
import logging
import signal
import sys
from google.cloud import pubsub_v1
from collections import Counter
from dotenv import load_dotenv
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class MessageCounter:
def __init__(self):
self.counter = Counter()
def callback(self, message):
try:
data = message.data.decode('utf-8')
attributes = message.attributes
message_id = message.message_id
self.counter[message_id] += 1
logger.info(f"メッセージID'{message_id}'の現在のカウント: {self.counter[message_id]}")
logger.info(f"総受信メッセージ数: {sum(self.counter.values())}")
message.nack()
except Exception as e:
logger.error(f"メッセージ処理エラー: {e}")
message.nack()
def run_counter():
load_dotenv()
# 環境変数の取得と検証
project_id = os.getenv("PROJECT_ID")
subscription_id = os.getenv("SUBSCRIPTION_ID")
topic_id = os.getenv("TOPIC_ID")
if not all([project_id, subscription_id, topic_id]):
raise ValueError("必要な環境変数が設定されていません")
subscriber = pubsub_v1.SubscriberClient()
# サブスクリプションの作成
subscription_path = subscriber.subscription_path(project_id, subscription_id)
# メッセージ受信の開始
counter = MessageCounter()
streaming_pull_future = subscriber.subscribe(
subscription_path,
callback=counter.callback
)
logger.info(f"メッセージ受信待機中: {subscription_path}")
try:
streaming_pull_future.result()
except Exception as e:
streaming_pull_future.cancel()
logger.error(f"エラーが発生しました: {e}")
def signal_handler(signum, frame):
logger.info("終了シグナルを受信しました。プログラムを終了します。")
sys.exit(0)
def main():
signal.signal(signal.SIGINT, signal_handler)
signal.signal(signal.SIGTERM, signal_handler)
try:
run_counter()
except KeyboardInterrupt:
logger.info("プログラムを終了します")
except Exception as e:
logger.error(f"予期せぬエラーが発生しました: {e}")
return 1
return 0
if __name__ == "__main__":
exit(main())
テストメッセージの送信
gcloud pubsub topics publish topic-a \
--message='{
"user": {
"name": "John Doe",
"age": 30
}
}' \
--attribute="content-type=application/json"
3. 結果の確認
アプリケーションのログから、メッセージが5回再試行されたことが確認できます
2025-04-08 08:24:46,689 - INFO - メッセージID'14557226085101693'の現在のカウント: 1
2025-04-08 08:24:46,690 - INFO - 総受信メッセージ数: 1
2025-04-08 08:25:01,287 - INFO - メッセージID'14557226085101693'の現在のカウント: 2
2025-04-08 08:25:01,287 - INFO - 総受信メッセージ数: 2
2025-04-08 08:25:19,154 - INFO - メッセージID'14557226085101693'の現在のカウント: 3
2025-04-08 08:25:19,155 - INFO - 総受信メッセージ数: 3
2025-04-08 08:25:35,260 - INFO - メッセージID'14557226085101693'の現在のカウント: 4
2025-04-08 08:25:35,260 - INFO - 総受信メッセージ数: 4
2025-04-08 08:26:00,203 - INFO - メッセージID'14557226085101693'の現在のカウント: 5
2025-04-08 08:26:00,203 - INFO - 総受信メッセージ数: 5
4. デッドレターの確認
デッドレタートピックにメッセージが転送されていることを確認します。上手くいってますね。

デッドレターには以下の属性が付与されます。障害調査などに役立つ情報になりますのでぜひ押さえておいてください。
-
CloudPubSubDeadLetterSourceDeliveryCount: 通常フロー用のサブスクリプションに対しての配信試行回数 -
CloudPubSubDeadLetterSourceSubscription: 通常フロー用のサブスクリプションの名前。 -
CloudPubSubDeadLetterSourceSubscriptionProject: 通常フロー用のサブスクリプションを配置しているプロジェクトの名前。 -
CloudPubSubDeadLetterSourceTopicPublishTime: メッセージが最初にパブリッシュされたときのタイムスタンプ
Cloud Storage への転送設定
次は、デッドレタートピックに集まったメッセージを Cloud Storage に転送する方法を確認します。この機能を利用することで、デッドレターを長期保存することができます。

図: デッドレタートピックから Cloud Storage への転送フロー
1. 転送設定の準備
デッドレターを保存するための Cloud Storage バケットを作成します。
そして、Cloud Storage 転送用のサブスクリプションdeadletter-topic-a-sub-to-gcsを作成します。

図: Cloud Storage 転送用のサブスクリプション設定画面
2. 動作確認
通常フローで意図的にデッドレターを発生させ、Cloud Storage への転送を確認します。以下の通り、Cloud Storage へオブジェクトが書き込まれたのが確認できました。

図: Cloud Storage に保存されたデッドレター
保存されたメッセージの内容はこちらです。
{
"user": {
"name": "John Doe",
"age": 30
}
}
3. Cloud Storage への転送機能に関する考察
確認した限り、Cloud Storage への転送機能には以下の特徴があります。
- メッセージの本文が保存されます
- 属性情報は保存されません
- Cloud Storage に保存する際にデータの加工はできません
これを踏まえると、Cloud Storage の転送機能は、デッドレターのメッセージを低コストで単純に長期保存したいという用途に向いています。
BigQuery への転送設定
今度は、デッドレターの詳細な分析や監視を実現するための、BigQuery への転送の方法を確認します。BigQuery を利用することで、デッドレターの傾向分析を効率的に実現できます。

図: デッドレタートピックから BigQuery への転送フロー
1. BigQuery の環境準備
デッドレター保存用のデータセットdeadletter_datasetと、保存用テーブルdeadletter-tableを作成します。
BigQuery のテーブルにデッドレターの情報を保存するためには、テーブルにスキーマを設定する必要があります。
今回は、公式の情報を参考に、以下のスキーマを設定します。
[
{
"name": "subscription_name",
"type": "STRING",
"mode": "NULLABLE",
},
{
"name": "message_id",
"type": "STRING",
"mode": "NULLABLE",
},
{
"name": "publish_time",
"type": "TIMESTAMP",
"mode": "NULLABLE",
},
{
"name": "attributes",
"type": "JSON",
"mode": "NULLABLE",
},
{
"name": "data",
"type": "JSON",
"mode": "NULLABLE",
}
]

図: 作成された BigQuery のテーブル
2. 転送設定
BigQuery 転送用のサブスクリプションを作成し、以下の設定を行います。
- デッドレタートピックと BigQuery テーブルの紐付け
- メッセージ属性のJSON形式での保存設定
- メッセージ本文のJSON形式での保存設定

今回は、デッドレターの属性とメッセージを単純に保存するのが目的なので「スキーマを使用しない」「メタデータを書き込む」という構成を選択しています。

3. 動作確認
デッドレターを発生させ、BigQuery への転送を確認します。テーブルにデッドレターの情報が保存されていることが確認できました。

図: BigQuery に保存されたデッドレター
4. BigQuery 転送機能に関する考察
BigQuery への転送機能には以下の特徴があります。
- メッセージ本文と属性情報の両方が保存されます
- スキーマの設定により、構造化されたデータとしてデータが保存できます
このような特徴から、BigQuery への転送はエラーの発生状況の詳細情報の把握や原因分析という用途に向いています。
システム改善に向けた知見を得るための有効な機能といえるでしょう。
カスタムアプリケーションとの連携
最後に、デッドレターのカスタムアプリケーションへの転送を確認します。ここでは Cloud Run Functions を利用して、デッドレターの処理の実施します。

図: デッドレタートピックからアプリケーションへの転送フロー
1. Cloud Run Functions の構築とアプリケーションの処理実装
まず、デッドレターを処理する Cloud Run Functions を作成します。今回は動作確認のため、受信したデッドレターの内容をログ出力する簡単な実装とします。
ソースコードはこちら
const functions = require('@google-cloud/functions-framework');
functions.http('helloHttp', (req, res) => {
try {
// リクエストボディからPubSubメッセージを取得
const message = req.body.message;
// デッドレター情報の取得
const rawData = message.data ? Buffer.from(message.data, 'base64').toString() : '';
const data = rawData ? JSON.parse(rawData) : null;
const messageId = message.messageId || 'ID不明';
const publishTime = message.publishTime || '時刻不明';
const attributes = message.attributes || {};
// 整形されたログ出力
console.log(JSON.stringify({
デッドレターメッセージを受信: {
messageId,
publishTime,
data,
attributes
}
}, null, 2));
// 処理成功を返す
res.status(200).send('OK');
} catch (error) {
// エラー処理
console.error('デッドレター処理中にエラーが発生:', error);
res.status(500).send('Internal Server Error');
}
});
2. Push型サブスクリプションの設定
デッドレタートピックから Cloud Run Functions へメッセージを転送するための Push 型サブスクリプションを作成します。

図: Push 型サブスクリプションの設定画面
3. 動作確認
デッドレターを発生させ、Cloud Run Functions で処理が行われていることを確認します。
アプリケーションの処理通りにログにデッドレターに関する情報が出力されていることが確認できました。

図: Cloud Run Functions でのデッドレターの処理のログ
4. カスタムアプリケーションへの転送の特徴と活用方法
カスタムアプリケーションへの転送には以下の特徴があります。
- リアルタイムな処理が可能
- カスタマイズ可能な処理の実装
- メッセージと属性の両方にアクセス可能
このような特徴から、カスタムアプリケーションへの転送はデッドレター発生時に任意の処理を実行したいという用途に向いています。
例えば、メールやSlackへの通知、データを任意の形式に加工し活用するなどが考えられます。かなり汎用性が高い機能だといえるでしょう。
まとめ
本記事では、Google Cloud Pub/Sub のデッドレタートピックについて、基本的な概念から実装方法、そして代表的な活用パターンまで見てみました。
デッドレタートピックの主な特徴と利点をまとめると、以下のようになるでしょう。
-
メッセージの滞留防止
- 処理失敗したメッセージを適切に分離
- システムの安定性維持
- コスト増大の防止
-
柔軟な転送オプション
- Cloud Storage: 低コストでの長期保存
- BigQuery: 詳細な分析と監視
- カスタムアプリケーション: リアルタイムな処理と通知
-
豊富な付加情報
- 配信試行回数
- 元のサブスクリプション情報
- タイムスタンプ
- エラー情報
これらの機能を適切に組み合わせることで、より信頼性の高いメッセージング基盤を構築することができます。Pub/Sub を使う際にはぜひデッドレタートピックを活用いただければと思います。
本記事が、皆様のシステム設計やトラブルシューティングの一助となれば幸いです。
Discussion