中学生でもわかる Multimodal Embeddings
こんにちは、クラウドエースの佐久間です。2023 年 11 月 15‐16 日にかけて東京ビッグサイトで行われた 「Google Cloud Next Tokyo '23」 の基調講演にて、Vertex AI についての紹介がありました。Vertex AI では、アプリケーション構築に使用できる 100 種類以上の機械学習モデルが用意されています。その中の 1 つとして、「Multimodal Embeddings」 というモデルが講演の中で取り上げられました。
基調講演において Multimodal Embeddings は、レコメンドや検索、分類などに役立つモデルであると紹介されました。一方で、その専門性のためか、それ自体がどういった仕組みでレコメンドや検索を行うのか、といった詳細な解説まではなされませんでした。
そこでこの記事では、「Multimodal Embeddings について、モデルのニュアンスだけでもわかるようになる」 というモチベーションのもと、Multimodal Embeddings についてわかりやすく解説します。タイトルにもあるように、「中学生でもわかる」 というところを目指しているので、専門用語はできるだけ使用せずに (噛み砕いて) 解説したいと思います。そのため、正確性や厳密性には欠ける部分があるかとは思いますが、ご容赦ください。
Multimodal Embeddings とは
いきなり Multimodal Embeddings と言われてもかなり難しいと思うので、この言葉を 1 つずつ分解してみます。まず 「multimodal (マルチモーダル)」 とは何でしょうか。これは 「多くの方法」 や 「多くの形」 を意味します。例えば私たちは、周囲の情報を得るのに目や耳を使えます。この、目で見て(視覚)、耳で聞いて(聴覚)情報を得るのは 「マルチモーダルな方法」 と言えます。
次に 「embedding (エンベディング)」 とは何でしょうか。これは、抽象的な情報を数字のリスト (これをベクトルと呼びます) に変換する方法の 1 つです。例えば、「りんご」 をベクトルで表すとします。ベクトルに変換する際のチェック項目として、「人間、果物、乗り物」 があったとすると、りんごは果物なので、「0, 1, 0」 のように表せます。もちろんこれは例ですので数字も適当ですし、実際の変換はより複雑です。
これらのことから Multimodal Embeddings とは、様々な種類の情報 (テキストや画像、音声など) を数字のリスト (ベクトル) に変換する方法のことを指します。この方法によりコンピューターは、テキストだけでなく画像や音声といった情報も理解できるようになります。
類似画像検索における Embeddings
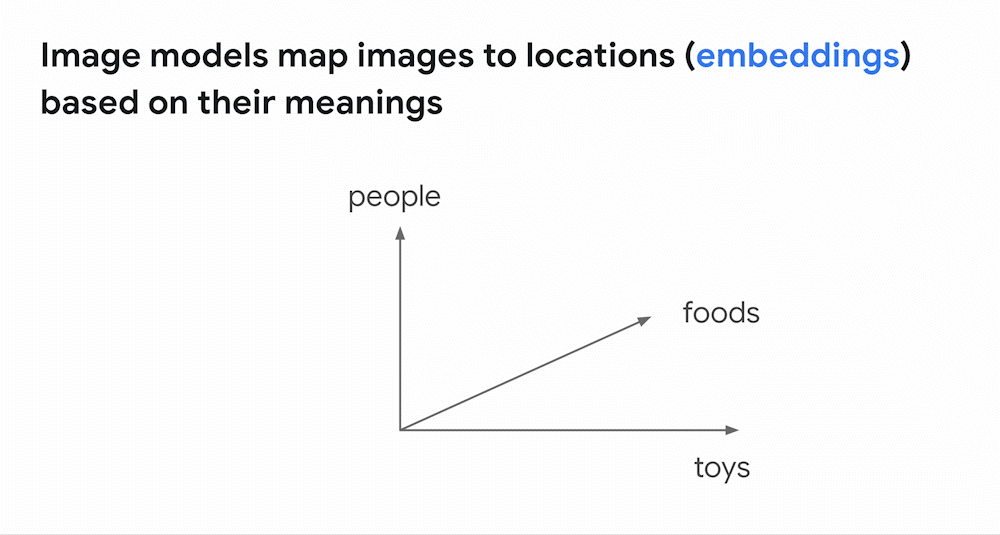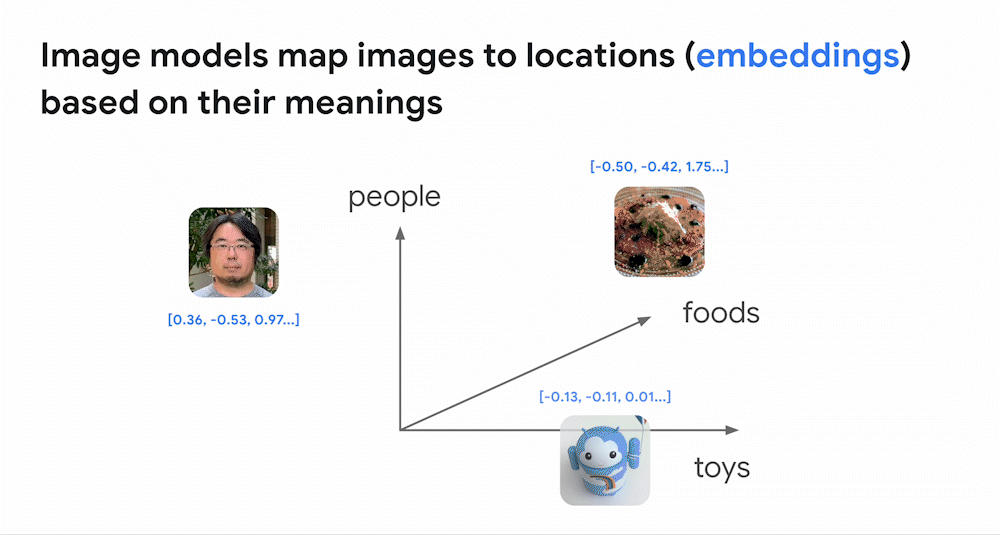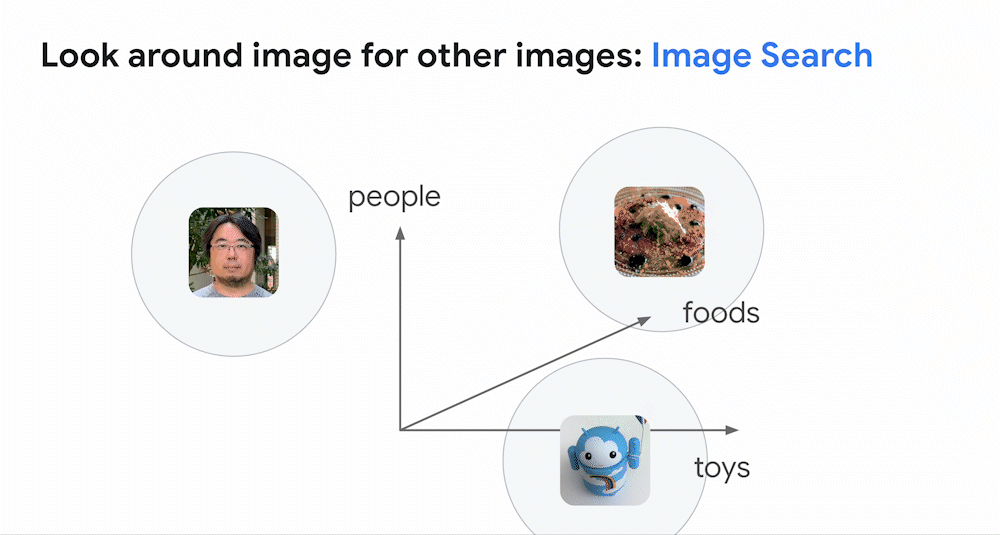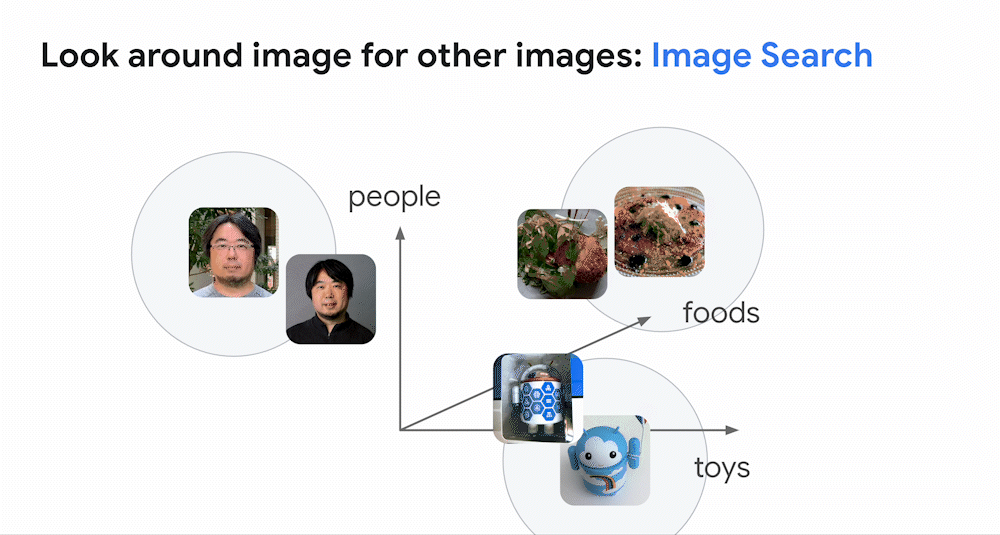
類似画像検索における Embedding の例 (Google Cloud Blog より引用)
上の動画は、類似画像検索における Embedding の例です。上の例では、「people」、「foods」、「toys」 の観点で Embedding を行い、ある画像がどのカテゴリに近いか、というのを調べています。まず、3 つの画像に対して Embedding を行っており、画像情報をベクトル (青の数字リスト) に変換しています。ここでベクトルをある座標のようなものだと考えてみましょう。先程の変換により、「この画像は『people』の矢印に近い」、「あの画像は『foods』の矢印に近い」 というように、コンピューターにもベクトルの表す位置で画像の区別ができるようになります。コンピューターが、数ある画像のうち 「特定の画像と近い位置 (動画ではグレーの円付近) 」 にある画像を提案することで、類似画像の検索が可能となります。
この例では説明を簡単にするために、「people」、「foods」、「toys」 の 3 つの観点のみで Embedding を行っていました。しかし、実際の Vertex AI Multimodal Embeddings では、1408 の要素をもつベクトルを考えます。これは先程のような簡易的な図では到底表わせません。コンピューターを用いて、実際にその結果を視覚化したのが下の図になります。

ベクトル化された 6 億の商品画像を視覚化したデモ (Google Cloud Blog より引用)
これはフリマアプリ 「メルカリ」 の 6 億にも及ぶ商品画像に対し、Vertex AI Multimodal Embeddings によるベクトル化を行ったデモです。かなりの数があるのでわかりにくいですが、各点がベクトル化された商品画像の位置を表しています。デモの冒頭では、点が密集しているところと散在しているところがあるのがわかります。よく見ると、密集している場所にはカテゴリ名が振られています。デモでは最終的に 「Ceramic vintage shakers」 というカテゴリの部分を拡大していますが、その周辺にはたしかに 「ceramic」 や 「vintage」 (「shaker」 かどうかは怪しい) っぽい画像が集まっているのがわかります。
テキストを用いた画像検索における Embeddings
先程の例では画像に対して Embedding を行っただけであり、まだ 「Multimodal」 とは言えません。そこで次に、テキストを用いた画像検索における Embedding の例を見ていきます。
以下 2 つの画像では、Multimodal Embeddings を用いて、テキストで指定した商品画像を表示しています。上の画像では 「Google カラーのコップ」、下の画像では 「『It's my birthday』と描かれた T シャツ」 を検索しています。これらの画像はキーワードでヒットしているわけではない、というのがポイントです。先程の例であったような画像情報のベクトル化だけでなく、テキストもベクトル化してあげることで、入力されたテキストの意味に近い画像を提案できています。Multimodal Embeddings を用いることで、「テキスト」 と 「画像」 という全く別の情報をコンピューターが理解し、それらをつなぎ合わせていることがわかるかと思います。
![]()

Google Cloud Blog より引用
Multimodal Embeddings の用途
いくつかの例でも挙げたように、Multimodal Embeddings は特に 「検索」 という観点で大きな力を発揮しています。頭で考えていることを言語化 (テキスト化) して検索することで、ラベリングを行っていなくても画像や動画などを見つけられるようになるわけです。
また Google が挙げている用途の 1 つとして、構造化データの検索アプリに組み込む、というのも提案されています。例えば商品検索アプリへの導入です。Multimodal Embeddings により商品の画像情報をベクトル化し、商品データの表に組み込めます。この方法を使うと、検索結果は、商品の色やサイズといった 「キーワード検索」 と、商品画像に基づく 「意味的な検索」 の組み合わせになります。これにより、より多角的で精度の高い検索ができるようになります。
まとめ
この記事では、Multimodal Embeddings の基本的な概念と、その応用例について解説しました。この記事が、専門性の高い Multimodal Embeddings に対する理解のきっかけとなれば幸いです。冒頭でも述べたように、この記事はわかりやすさを重視しているので、正確さや厳密さには目を瞑っています。より詳しく知りたい場合は、ご自身でより専門的な文献をあたってみてください。
Discussion