【初心者向けハンズオン】機械学習の専門知識なしで始める!Google Cloud 需要予測モデル構築入門
はじめに
こんにちは、クラウドエース株式会社 第二開発部の劉です。
Google Cloud では、機械学習の専門知識がなくても需要予測モデルを構築できる製品が提供されています。そこで今回は、BigQuery ML (BQML) の時系列予測機能と Vertex AI Forecast の2つの製品を使い、同じデータセットで予測モデルを構築する方法をハンズオン形式で紹介していきます。
BigQuery MLはSQLだけでモデル構築から運用まで完結でき、Vertex AI ForecastはGUI操作でモデル構築を開始でき、どちらも機械学習の専門知識なしで始められます。本記事では、同じデータセットを使って両製品でモデルを構築し、それぞれの特徴を体験します。
対象読者
本記事は、Google Cloudでの需要予測を始めたい初心者を対象としています。以下のような方におすすめです。
- 機械学習の専門知識はないが、需要予測を始めたい方
- SQLは書けるが、MLは初めての方
- データアナリストで、予測モデルを構築したい方
- GUI操作で機械学習を試してみたい方
本記事では、専門的な機械学習の知識は前提とせず、基本的なSQLスキルがあれば理解できる内容となっています。
本記事で学べること
- BigQuery MLでSQLだけで予測モデルを構築する方法
- Vertex AI ForecastでGUI操作だけで予測モデルを構築する方法
- 同じデータセットでモデルを構築し、それぞれの特徴を体験すること
検証の前提
-
使用データ: BigQueryの公開データセット
bigquery-public-data.austin_bikeshare.bikeshare_trips(同じデータセットを両製品で使用) - 環境: BigQuery、Vertex AI
- 評価指標: MAPE(平均絶対パーセント誤差)
第1章:Google Cloud上の需要予測製品の紹介
Google Cloud では、機械学習の専門知識がなくても需要予測モデルを構築できる製品が提供されています。本記事では、BigQuery MLの時系列予測機能とVertex AI Forecastを比較します。
主に以下の2つの製品があります。
BigQuery ML (BQML)
- SQLベース: SQLだけで機械学習モデルを構築・実行できる
- 手軽で低コスト: 数分〜数十分でモデルが作成でき、コストも低い
- 既存データ基盤との連携: BigQueryにデータがあればすぐに始められる
Vertex AI Forecast
- GUI操作で開始: GUI操作でモデル構築を開始でき、プログラミング知識は不要(運用時はMLOpsで自動化可能)
- 高精度: 深層学習モデルを活用し、高い精度が期待できる
- MLOps機能: モデルレジストリなど、本格的なMLOps機能が利用可能
第2章:BigQuery ML ハンズオン — SQLだけで予測モデルを構築する
第1章で紹介したBigQuery MLを使って、実際に予測モデルを構築するハンズオンを行います。SQLだけでモデル作成から推論までを完結できます。
利用可能なモデル
BQMLでは、主に以下の3つのモデルが利用できます。今回のハンズオンではARIMA_PLUSを使います。
-
ARIMA_PLUS: 統計モデルベース。ML.EXPLAIN_FORECASTで予測根拠(トレンド、季節性など)を明確に分解できる透明性が特長です。
-
ARIMA_PLUS_XREG: ARIMA_PLUSに外部回帰変数(xreg)を追加できるモデル。ARIMA_PLUSと同様にML.EXPLAIN_FORECASTで予測根拠を分解でき、天気やイベントなどの外部要因を考慮した予測が可能です。
-
TimesFM: Googleが開発した深層学習ベースの基盤モデル。事前学習済みの汎用モデルを転用するため、BQMLでありながら高度なAI予測を可能にします。ただし、ML.EXPLAIN_FORECASTのような分解機能はなく、透明性の観点ではARIMA_PLUS系とは異なります。
TimesFMについては、弊社メンバーが執筆した以下の記事で紹介されています。ぜひご参照ください。
2.1 データ準備
使用するデータセット
今回のハンズオンでは、BigQueryの公開データセット bigquery-public-data.austin_bikeshare.bikeshare_trips を使用します。このデータセットは、後述するVertex AI Forecastでも同じデータを用いるため、両製品での比較が可能です。
SELECT
DATE(start_time) AS date,
count(trip_id) AS num_trips,
'austin_trips' AS time_series_id -- すべての行に同一の時系列IDを付与
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_trips`
WHERE
DATE(start_time) < '2017-01-01' -- 予測対象期間の直前までをトレーニングに使用
GROUP BY
1, 3 order by 1
データ形式
BQテーブルに、以下のような形式で時系列データを格納します。
- date: タイムスタンプ(日付)
- num_trips: 予測対象(利用回数)
- time_series_id: 時系列ID(オプション)
最低限、dateとnum_tripsの2つのカラムがあれば予測モデルを構築できます。
2.2 モデル作成 (CREATE MODEL)
外部要因(祝日など)を取り込みつつ、ARIMA_PLUSモデルを作成します。
CREATE OR REPLACE MODEL
`austin_bikeshare.bikeshare_arima_model`
OPTIONS(
# 予測モデルとしてARIMA_PLUSを指定
model_type = 'ARIMA_PLUS',
# 時系列データの設定
time_series_timestamp_col = 'date', -- タイムスタンプの列名
time_series_data_col = 'num_trips', -- 予測対象の値の列名
time_series_id_col = 'time_series_id', -- 複数時系列を扱うためのID列 (今回は単一ID)
# ARIMA_PLUS の自動設定
auto_arima = TRUE, -- 最適なARIMAパラメータを自動で探索
data_frequency = 'DAILY', -- データは日次で集計
HOLIDAY_REGION = 'US' -- 祝日を考慮
) AS
SELECT * FROM `austin_bikeshare.bikeshare_trips`
2.3 予測実行と分解 (ML.EXPLAIN_FORECAST)
この関数を実行することで、予測結果がトレンド、季節性、祝日効果などに分解されます。
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `austin_bikeshare.bikeshare_arima_model`, STRUCT(90 AS horizon));

体験ポイント: 予測結果の内訳を可視化することで、「なぜこの数値が出たのか」を論理的に説明できることを確認できます。


2.4 精度の確認方法
予測精度の詳細は、第4章の精度比較で後述するVertex AI Forecastと比較して紹介します。
第3章:Vertex AI Forecast ハンズオン — GUI操作だけでも予測モデルを構築できる
第1章で紹介したVertex AI Forecastを使って、実際に予測モデルを構築するハンズオンを行います。GUI操作だけでモデルを構築でき、MLの専門知識がなくても最新の深層学習モデルを活用した高精度な予測が可能です。
利用されるモデル
Vertex AI Forecastでは、AutoML(デフォルト)が複数のモデルタイプ(時系列高密度エンコーダ(TiDE)、Temporal Fusion Transformer (TFT)、Seq2seq+など)から最適なものを自動選択します。また、手動で特定のモデル(TiDE、TFT、Seq2seq+)を選択することも可能です。
- 時系列高密度エンコーダ(TiDE): 高速なトレーニングと推論が可能で、長いコンテキストや長期予測に適しています。
- Temporal Fusion Transformer (TFT): 高精度で解釈可能性が高いアテンションベースのモデルです。
- AutoML(デフォルト): 幅広いユースケースに適しており、最適なモデルを自動選択します。
- Seq2seq+: テスト用途に適しており、トレーニング時間が短縮されます。
3.1 データ準備
第2章のBigQuery MLと同じデータセット(austin_bikeshare.bikeshare_trips)を使用します。BigQueryに格納されたデータを、Vertex AI Forecastで直接参照できます。データのコピーは不要です。
Vertex AIへのデータ登録
Vertex AI のコンソール画面で、BigQuery に格納された検証データを選択し、データセットとして登録します。
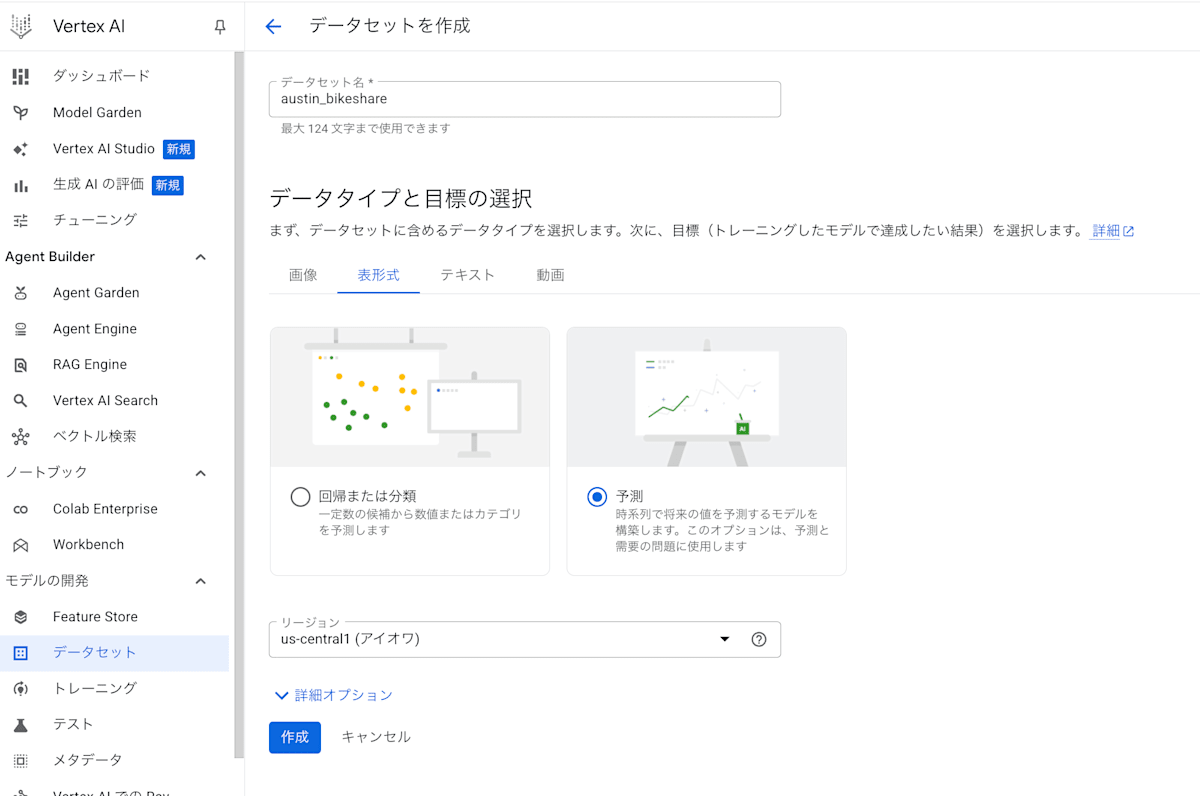
- 時系列データセットの作成
表形式の時系列予測を選択し、データセットを作成します。
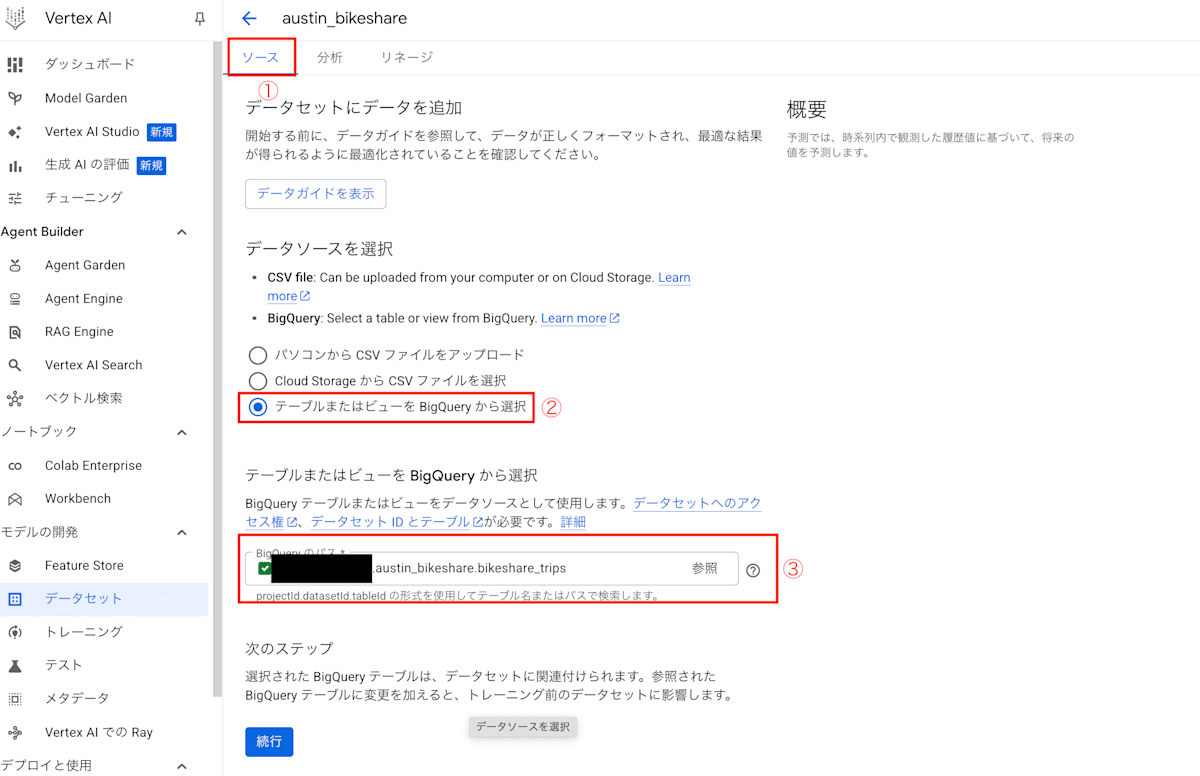
- ソースとしてBigQueryテーブルを指定
作成したデータセットをクリックし、ソースタブを選択して、BigQueryテーブルをソースとして指定します。
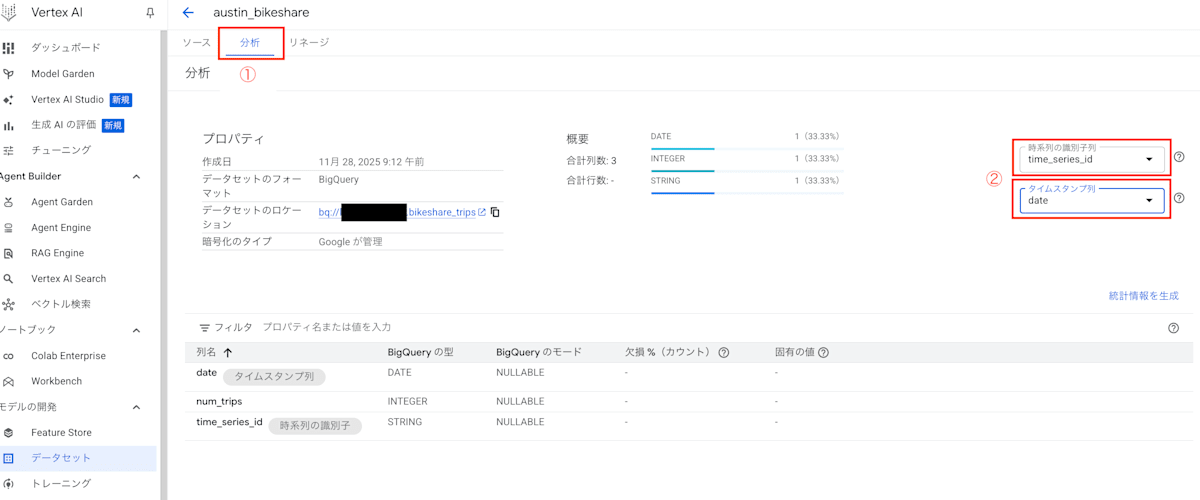
- 分析対象を指定
分析タブを開いて、時系列の識別子とタイムスタンプ列を設定します。
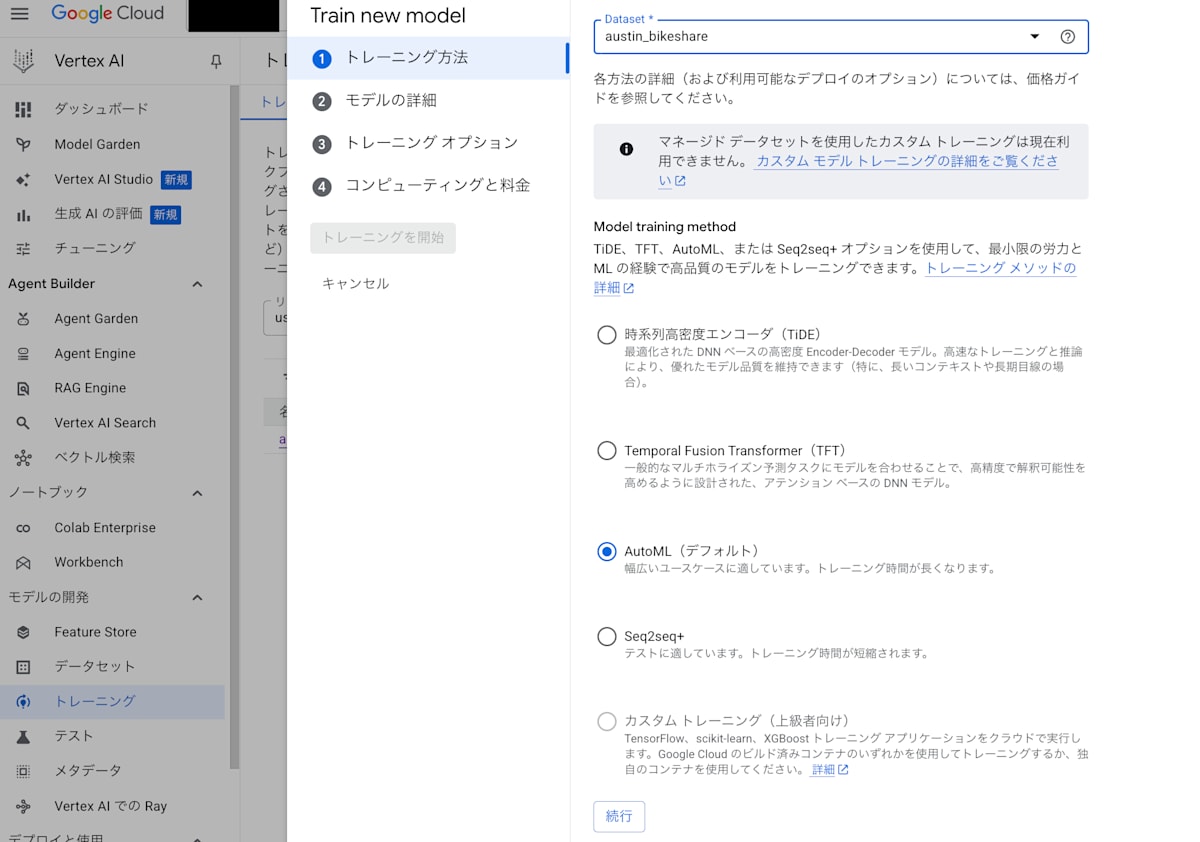
3.2 モデル作成(GUI操作)
専門知識の壁を感じさせないGUI操作によるハンズオンです。
-
トレーニング方法の設定
データセット:前章で作成したデータセットを指定します。
モデル:デフォルトのAutoMLを使います。
-
モデル詳細の設定
以下の項目を設定します。各項目の意味と、今回のハンズオンでの設定値を示します。
-
Target Column(予測対象列):
num_trips(INTEGER)- 予測したい値(自転車の利用回数)を指定します -
Series identifier column(時系列識別子列):
time_series_id(STRING)- 複数の時系列を扱う場合の識別子。 -
タイムスタンプ列:
date(DATE)- 時系列データの日付を指定します -
データ粒度(Forecasting configuration):
毎日- データが日次で集計されていることを指定します -
地域の休日(Forecasting configuration):
United States- アメリカの祝日を考慮する設定です -
Forecasting Horizon(Forecasting configuration):
90- 90日先まで予測する設定です -
コンテキスト期間(Forecasting configuration):
365- 予測に使用する過去データの期間(365日分)を指定します

3. コンピューティングと料金の設定
今回のモデルでは、最小値の1ノード時間を指定すれば十分です。料金は約3,000円程度かかります(料金体系)。

約2時間でモデルの訓練が完了します。Vertex AI Forecastのダッシュボードでは、MAPEなどの評価指標が自動的に計算され、表示されます。

体験ポイント: トレーニング中は待機となりますが、裏側で複雑な処理が自動的に行われていることを理解できます。AutoMLが最適なモデルを自動選択し、特徴量エンジニアリングも自動的に行われます。
3.3 予測実行
- バッチ推論用のソースデータ準備
入力として、「予測の根拠となる過去のデータ(コンテキスト)」と「予測したい未来の期間の行(プレースホルダー)」を組み合わせたデータが必要になります。2017-01-01以降の3ヶ月のデータを予測するため、下記のSQLで入力データを生成します。
CREATE OR REPLACE TABLE `austin_bikeshare.vertex_ai_batch_prediction_input` AS
SELECT * FROM `austin_bikeshare.bikeshare_trips`
UNION ALL
SELECT *, NULL AS num_trips, "austin_trips" AS time_series_id FROM UNNEST(GENERATE_DATE_ARRAY('2017-01-01', '2017-03-31')) AS date
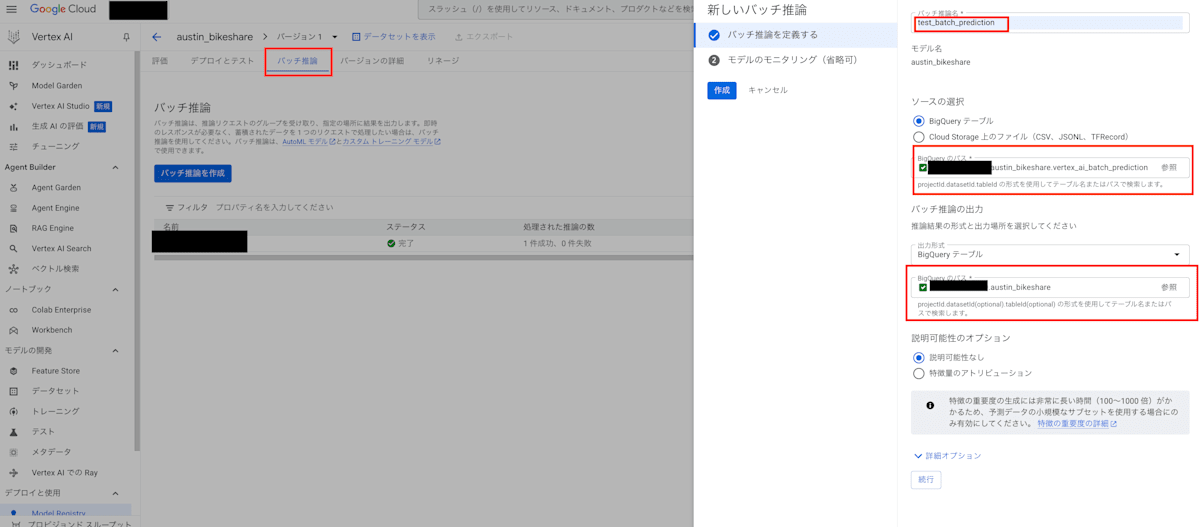
- バッチ推論設定
作成したモデルをクリックし、「バッチ推論」タブを選択して、バッチ推論を作成します。1.で作成したソースデータをソースとして選択し、バッチ推論の出力先も指定します。特徴量のアトリビューションも設定可能ですが、特徴量の重要度の生成に非常に時間がかかるため、今回は設定しませんでした。
3.4 精度の確認方法
予測結果の精度の詳細は、第4章でBigQuery MLと比較して紹介します。
第4章:ハンズオンの結果と比較 — 今回のハンズオンでの予測結果を確認する
4.1 比較の前提
今回のハンズオンでは、同じデータセットを使って両製品でモデルを構築し、それぞれの特徴を体験しました。比較を行うにあたり、以下の前提条件を設定しています。
- 同じデータセットを使用: 第2章のBigQuery MLと第3章のVertex AI Forecastで、同じデータセットを用いてモデルを構築しました。
- 同じ評価指標: MAPE(平均絶対パーセント誤差)で比較します。
- 同じ検証期間: 同じ検証期間で精度を評価します。
4.2 今回のハンズオンでの結果
予測結果
以下は、BigQuery MLとVertex AI Forecastの両方で構築したモデルの予測結果を、実際の値(実測値)と比較したグラフです。グラフでは、以下のことが確認できます。
- 実測値(黒線): 実際に観測された自転車の利用回数
- BigQuery MLの予測(青線): ARIMA_PLUSモデルによる予測結果
- Vertex AI Forecastの予測(赤線): AutoMLモデルによる予測結果
両モデルとも時系列の傾向を捉えており、実際の値に近い予測を行っていることが分かります。次のセクションでは、より定量的な精度評価(MAPE)を行います。

予測結果の精度
予測モデルの精度を評価するために、MAPE(平均絶対パーセント誤差)を使用します。MAPEは、予測値と実際の値の誤差をパーセントで表した指標で、値が小さいほど精度が高いことを示します。
同じデータセットで両ツールを比較した結果、以下のようになりました。
| ツール | モデル | MAPE |
|---|---|---|
| BigQuery ML | ARIMA_PLUS | 197.1 |
| Vertex AI Forecast | AutoML | 156.3 |
今回のハンズオンでは、Vertex AI Forecastの方が少し高い精度を示しました。
ただし、BigQuery MLでも十分に実用的な精度が得られており、コストとトレーニング時間の観点を考慮すると、BigQuery MLで求められている精度が出ている場合はBigQuery MLを選択するのが合理的です。
4.3 今回のハンズオンから分かること
今回のハンズオンを通じて、以下のことが分かりました。
- 精度だけでなく、コスト・時間・手軽さを総合的に判断することが重要: 今回のデータセットでは、BigQuery MLでも求められている精度が出ているため、コストとトレーニング時間の観点からBigQuery MLを選択するのが合理的です
- データや問題によって結果が異なる: 他のデータや問題では結果が異なる可能性があるため、実際のプロジェクトでは両方を試すことを推奨します
- まずは手軽なBigQuery MLから始める: SQLが書ければすぐに始められ、低コストで試せるため、まずはBigQuery MLから始めることを推奨します
まとめ
本記事では、機械学習の専門知識がなくても、Google Cloud の製品を使って需要予測モデルを構築できることを、ハンズオンを通じて実践的に学びました。
Google Cloudには、機械学習の専門知識がなくても需要予測モデルを構築できる製品が提供されています。本記事で紹介したBigQuery ML(時系列予測機能)とVertex AI Forecastの2つの製品は、どちらも初心者でも簡単に始められます。
BigQuery MLはSQLだけで予測モデルを構築でき、既存のBigQueryデータを活用しやすく、短時間・低コストで試せるため、まずはこちらから始めることをおすすめします。一方、Vertex AI ForecastはGUI操作で予測モデルを構築でき、高度なモデル(AutoML、TiDE、TFTなど)を選択でき、MLOps機能も充実しています。
データや問題によって最適なツールは変わりますが、まずは手軽なBigQuery MLから始めて、自分のデータで精度を検証してみることをおすすめします。本記事のハンズオンを参考に、ぜひあなたのデータでも試してみてください。
Discussion