Vertex AI Pipelines のTabular Workflow for Forecasting
こんにちは、クラウドエース データML ディビジョン所属の江藤です。
クラウドエースのITエンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータML ディビジョンです。
データML ディビジョンでは活動の一環として、
毎週Google Cloudの新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回、ご紹介するリリースは2023年8月28日付でpreviewで利用可能となった、Vertex AIのTabular Workflowについてです。
リリース内容
Tabular Workflow for Forecastingはプレビューで利用できるようになりました。
Tabular Workflow とは
Tabular Workflow(表形式ワークフロー)は、表形式データを対象としたエンドツーエンドの機械学習を実現するための統合されたスケーラブルなビルド済みパイプラインのことです。
このワークフローは、機械学習のタスクを簡素化し、自動化するためのツールやプロセスのセットを提供します。
データの前処理からモデルのトレーニング、評価、デプロイメントにいたるまで、機械学習プロジェクト全体をカバーします。これにより、ユーザーは一貫性のあるプロセスで機械学習モデルを構築できます。
このワークフローは、Google Cloud PlatformのVertex AI Pipelinesの一部として提供されます。Vertex AI Pipelinesは、機械学習パイプラインを簡単に作成、管理、デプロイできるプラットフォームで、Tabular Workflowはその一部として提供され、マネージド環境で実行できます。
Tabular Workflow for Forecastingとは
Tabular Workflow for Forecasting(予測のための表形式ワークフロー)は、予測タスクを実行するためのステップのシーケンスです。このワークフローは、AutoML APIと同様に予測モデルを構築しますが、ユーザーが各ステップを制御し、カスタマイズできる点が異なります。以下は、制御できるパイプラインのステップです。
- データ分割
- 特徴量エンジニアリング
- アーキテクチャ検索
- モデルのトレーニング
- モデルのアンサンブル
これらのステップを調整することで、ユーザーは予測モデルのパフォーマンスを向上させ、特定の予測課題に適したモデルを構築するための柔軟性を持つことができます。
Tabular Workflow for Forecastingは、大規模なデータセットを扱うことができ、予測精度も高いため、さまざまな予測タスクに利用できます。
Tabular Workflow for Forecastingのメリット
Tabular Workflow for Forecastingには以下のメリットがあります。
- 最大1TB、200カラムのデータセットをサポートします。
- アーキテクチャの種類の探索範囲を制限またはスキップすることで、安定性を向上させ、トレーニング時間を短縮させることができます。
- トレーニングとアーキテクチャ検索に使用するハードウェアを手動で選択することで、トレーニング速度を向上させることができます。
- 一部のモデルトレーニング方法では、アンサンブルサイズを変更することで、モデルサイズを小さくし、レイテンシーを向上させることができます。
- 各コンポーネントの詳細は、pipelines graph interfaceで確認できます。このインターフェイスでは、変換されたデータテーブルや評価されたモデルアーキテクチャなど、さまざまな情報を確認できます。
- 各コンポーネントは、細かい設定や状態を視覚的に確認できるようになりました。これにより、予測タスクのカスタマイズやトラブルシューティングがしやすくなります。
Vertex AI Pipelinesの予測
Tabular Workflow for Forecastingは、Vertex AI Pipelinesのマネージドインスタンスです。
Vertex AI Pipelinesは、Kubeflowパイプラインを実行するサーバーレスサービスです。パイプラインを使用して、機械学習とデータ準備タスクを自動化および監視できます。パイプラインの各ステップは、パイプラインのワークフローの一部を実行します。たとえば、パイプラインには、データを分割、データ型を変換、モデルをトレーニングするステップを含めることができます。ステップはパイプラインコンポーネントのインスタンスであるため、ステップには入力、出力、およびコンテナーイメージがあります。ステップ入力は、パイプラインの入力から設定するか、このパイプライン内の他のステップの出性に依存させることができます。これらの依存関係は、パイプラインのワークフローを有向非巡回グラフとして定義します。
Tabular Workflow for Forecasting のパイプラインコンポーネント
Tabular Workflow for Forecasting は、予測タスクに必要なデータ準備、モデルのトレーニング、予測結果の評価を自動化するためのパイプラインです。
以下の図は、Tabular Workflow for Forecasting のモデリング・パイプラインの概要を示しています。
緑色のボックスはユーザーが設定できるコンポーネントを表し、黄色いボックスはデータや入出力を表し、オレンジ色のボックスは条件分岐を表しています。
各コンポーネントの詳細は、コンポーネントを参照してください。
コンポーネントの入出力詳細は、コンポーネント入出力を参照してください。
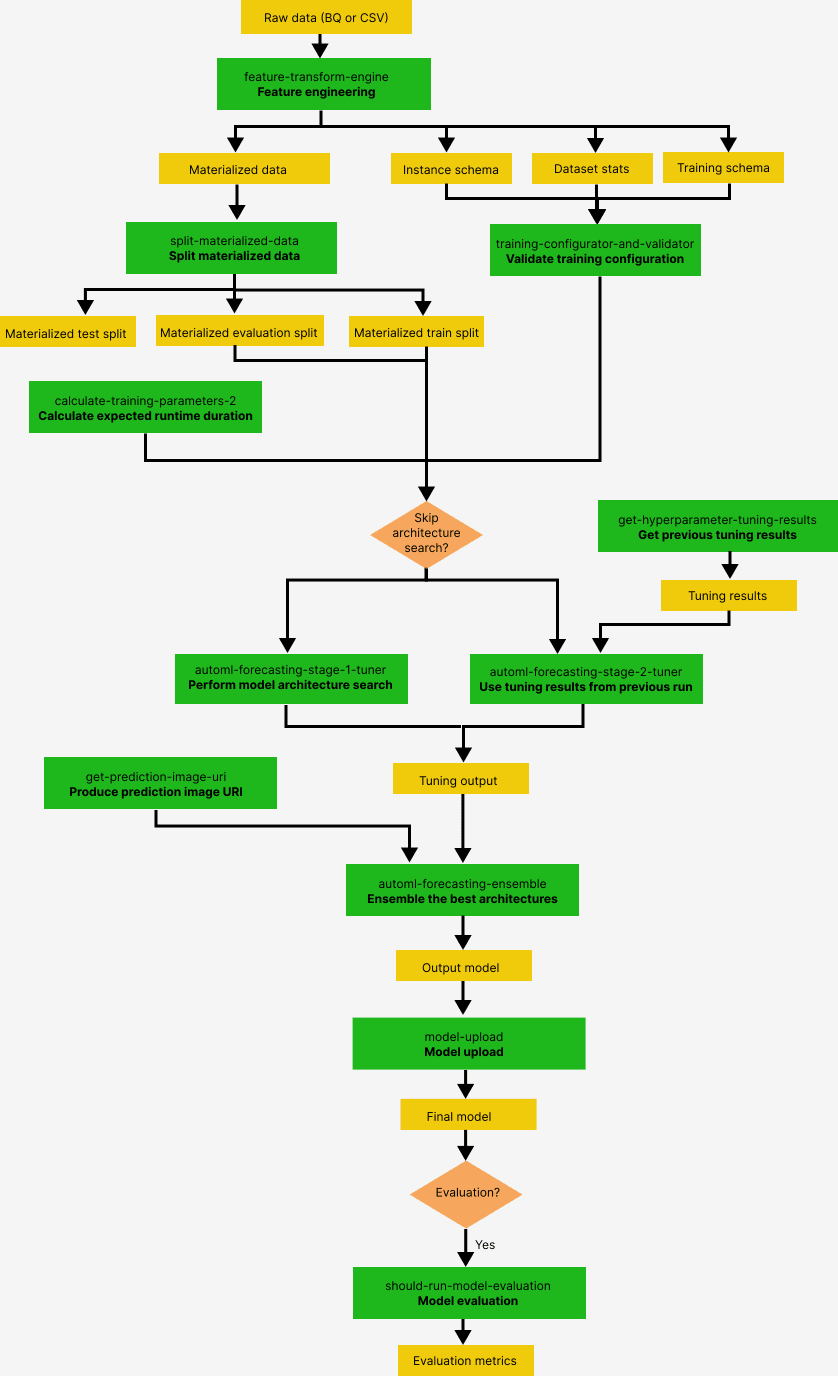
画像はgoogle公式ホームページより参照
コンポーネント
Tabular Workflow for Forecasting には、以下のコンポーネントがあります。
| コンポーネント | 役割 |
|---|---|
| feature-transform-engine | データの前処理(特徴量エンジニアリング)を行います。欠損値の補完、データの標準化、新しい特徴量の作成などを行うことができます。 |
| training-configurator-and-validator | トレーニングの設定を検証し、トレーニングに必要なメタデータを生成します。トレーニングのアルゴリズムやパラメータを指定します。 |
| split-materialized-data | マテリアライズされたデータをトレーニングセット、評価セット、テストセットに分割します。トレーニングセットはモデルのトレーニングに使用され、評価セットはモデルの性能を評価するために使用されます。テストセットはモデルのパフォーマンスを評価するために使用されます。 |
| calculate-training-parameters-2 | トレーニングに必要な時間を計算します。 |
| get-hyperparameter-tuning-results(オプション) | 以前のパイプライン実行で得たハイパーパラメータチューニング結果を読み込みます。これにより、アーキテクチャ検索をスキップして、より高速にパイプラインを実行できます。 |
| automl-forecasting-stage-1-tuner(または automl-forecasting-stage-2-tuner) | モデルアーキテクチャを探索し、ハイパーパラメータをチューニングします。これにより、予測精度を向上させることができます。 |
| get-prediction-image-uri-2 | モデルタイプに基づいて、予測に使用するイメージ URI を生成します。 |
| automl-forecasting-ensemble-2 | 最良のアーキテクチャをアンサンブルして最終モデルを作成します。これにより、予測精度をさらに向上させることができます。 |
| model-upload-2 | モデルをアップロードします。 |
| should-run-model-evaluation(オプション) | テストセットを使用して評価指標を計算します。これにより、モデルのパフォーマンスを評価できます。 |
コンポーネント入出力
| コンポーネント | 入力 | 出力 | 入出力説明 |
|---|---|---|---|
| feature-transform-engine | Raw data (BigQuery or CSV dataset) | instance_schema, dataset_stats, training_schema, materialized_data | - instance_schema: 予測データのデータ型を記述した OpenAPI 仕様のインスタンススキーマ。 - dataset_stats: 生のデータセットを記述する統計情報。 - training_schema: トレーニングデータのデータ型を記述した OpenAPI 仕様のトレーニングデータスキーマ。 - materialized_data: データ準備済みのデータ。 |
| training-configurator-and-validator | instance_schema, dataset_stats, training_schema | training_config | - training_config: トレーニングの設定。 |
| split-materialized-data | materialized_data | materialized_train_split, materialized_eval_split, materialized_test_split | - materialized_train_split: トレーニングセット。 - materialized_eval_split: 評価セット。 - materialized_test_split: テストセット。 |
| calculate-training-parameters-2 | materialized_train_split | training_parameters | - training_parameters: トレーニングに必要なパラメータ。 |
| get-hyperparameter-tuning-results | - | tuning_result_output | - tuning_result_output: ハイパーパラメータチューニングの結果。 |
| automl-forecasting-stage-1-tuner(または automl-forecasting-stage-2-tuner) | materialized_train_split, materialized_eval_split, artifact (オプション) | tuning_result_output | - tuning_result_output: ハイパーパラメータチューニングの結果。 |
| get-prediction-image-uri-2 | tuning_result_output | prediction_image_uri | - prediction_image_uri: 予測に使用するイメージ URI。 |
| automl-forecasting-ensemble-2 | tuning_result_output | unmanaged_container_model | - unmanaged_container_model: 出力モデル。 |
| model-upload-2 | unmanaged_container_model | model | - model: 出力モデル。 |
| should-run-model-evaluation(オプション) | - | model_evaluation_results (オプション) | - model_evaluation_results: モデルの評価結果。 |
オプション機能
- get-hyperparameter-tuning-results: 以前のパイプライン実行で得たハイパーパラメータチューニング結果を読み込む。
- should-run-model-evaluation: テストセットを使用して評価指標を計算する。
Tabular Workflow for Forecastingで学習してみる
上記では、Tabular Workflow for Forecastingの概要とメリットについて説明しました。
この章ではより理解を深めるために実際にTabular Workflow for Forecastingを使用して学習してみます。
前提として以下のAPIを有効化しておきます。
- Vertex AI
- ユーザー管理のノートブック
- Dataflow
- Compute Engine
- Cloud Storage
以下を開き、ノートブックを作成します。
Open in Vertex AI Workbench user-managed notebooks
上記ノートブック内の以下項目を設定します。
- PROJECT_ID
- region
- bucket_name
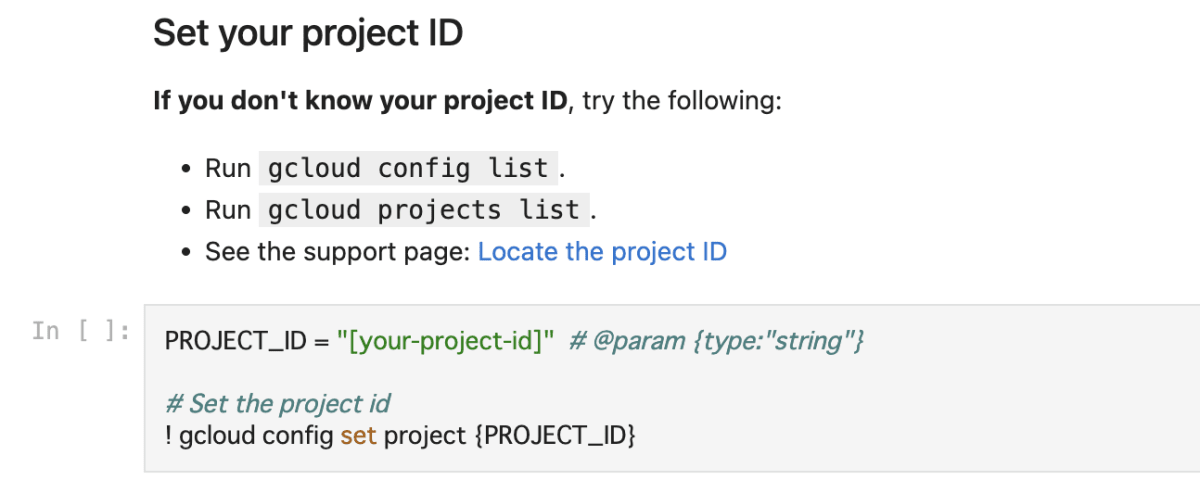


ノートブックをトレーニングの前まで実行します。
モデルのトレーニング方法を以下から選択し実行します。
- Time series Dense Encoder (TiDE)
- With model architecture search
- Without model architecture search
- Temporal Fusion Transformer (TFT)
- AutoML (L2L)
- Seq2Seq+
各モデルの説明は以下を確認してください。
ハイパーパラメータ調整結果のURIを取得する
Tabular Workflow for Forecastingの実行を完了している場合は、前の実行のハイパーパラメータチューニング結果を使用して、トレーニング時間とリソースを節約できます。
前のハイパーパラメータチューニング結果を見つけるには、Google Cloud Consoleを使用するか、APIを使用してプログラム的に読み込むことができます。
以下はコンソールでの操作方法になります。
- 該当パイプラインを選択する。
- コンポーネントexit-handler-1をクリックします。
- コンポーネントstage_1_tuning_result_artifact_uri_emptyをクリックします。
- コンポーネント automl-forecasting-stage-1-tuner を見つける。
- 関連するアーティファクト tuning_result_output をクリックします。
- Node Infoタブを選択する。
- モデル学習ステップで使用するURIをコピーします。

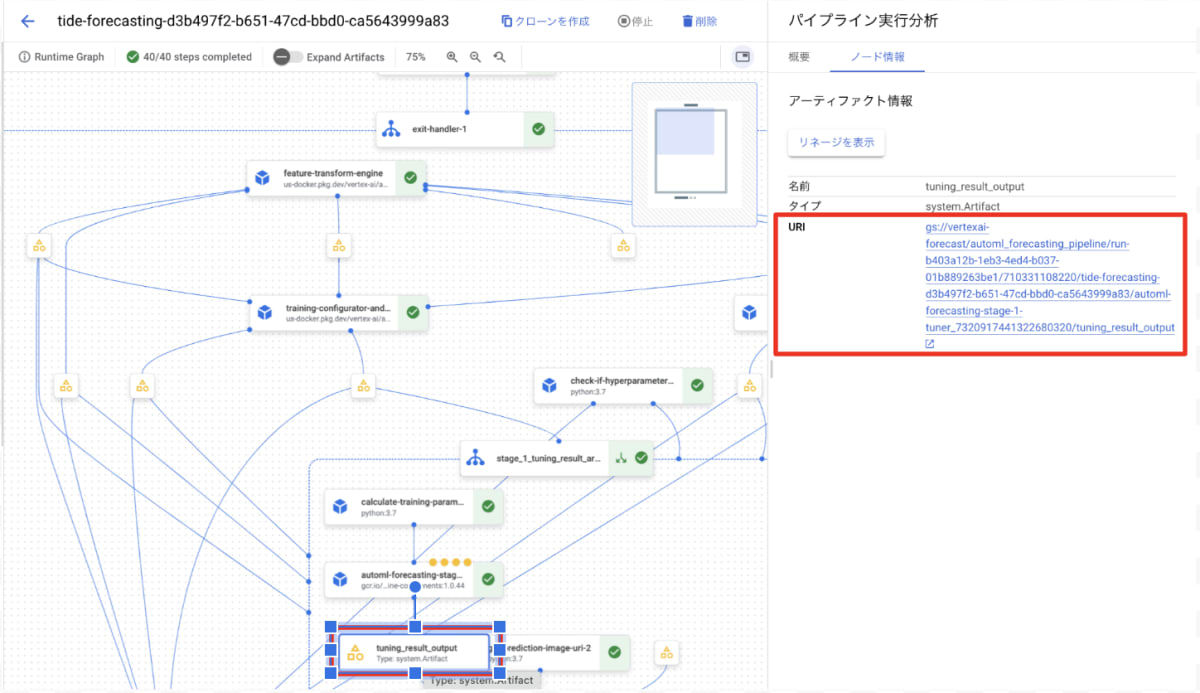
モデル学習
以下のサンプルコードは、実際に私がモデル学習パイプラインに使用したパラメータを示しています。
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
それぞれのモデルで以下のようにパイプラインとパラメータ値を定義します。
- Time series Dense Encoder (TiDE)
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)
- Temporal Fusion Transformer (TFT)
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)
- AutoML (L2L)
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)
- Seq2Seq+
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
Vertex AI Forecastingパラメータ名と説明
以下はパイプラインパラメータ引数に渡すことができるパラメータの一覧です。
| パラメータ名 | 型 | 説明 |
|---|---|---|
| optimization_objective | String | 最適化目標 |
| time_column | String | 時間列 |
| time_series_identifier_columns | List[str] | 時系列識別列 |
| weight_column | String | (オプション) 重み列 |
| time_series_attribute_columns | List[str] | (オプション) 時系列属性である列の名前 |
| available_at_forecast_columns | List[str] | (オプション) 予測時に値がわかっている共変量列の名前 |
| unavailable_at_forecast_columns | List[str] | (オプション) 予測時に値がわかっていない共変量列の名前 |
| forecast_horizon | Integer | (オプション) 予測期間 |
| context_window | Integer | (オプション) コンテキストウィンドウ |
| window_max_count | Integer | (オプション) 最大ウィンドウ数 |
| window_stride_length | Integer | (オプション) ストライド長 |
| window_predefined_column | String | (オプション) ウィンドウ識別列 |
| holiday_regions | List[str] | (オプション) ホリデー地域 |
| predefined_split_key | String | (オプション) データスプリットキー |
| training_fraction | Float | (オプション) トレーニングデータの割合 |
| validation_fraction | Float | (オプション) バリデーションデータの割合 |
| test_fraction | Float | (オプション) テストデータの割合 |
| data_source_csv_filenames | String | データソースのCSVファイル名 |
| data_source_bigquery_table_path | String | データソースのBigQueryテーブルパス |
| dataflow_service_account | String | (オプション) Dataflowサービスアカウント |
| run_evaluation | Boolean | (オプション) 評価を実行するかどうか |
| evaluated_examples_bigquery_path | String | (オプション) 評価結果のBigQueryテーブルパス |
Workflowカスタマイズオプション
パイプライン定義中に渡される引数値を定義することで、Tabular Workflow for Forecasting をカスタマイズできます。
- Configure hardware
- トレーニングに使用するマシンの種類と台数を設定できます。
- このオプションは、大規模なデータセットがあり、それに応じてマシンのハードウェアを最適化したい場合に適しています。
- Skip architecture search
- アーキテクチャ検索なしでパイプラインを実行し、代わりに以前のパイプライン実行からハイパーパラメータのセットを提供することができます。
ハードウェア設定
| パラメータ名 | 型 | 説明 |
|---|---|---|
| stage_1_tuner_worker_pool_specs_override | Dict[String, Any] | (オプション) マシンタイプとトレーニング用マシン数のカスタム設定。このパラメータは、パイプラインのautoml-forecasting-stage-1-tunerコンポーネントを構成します。 |
| stage_1_tuning_result_artifact_uri | String | (オプション) 以前のパイプライン実行によるハイパーパラメータのチューニング結果のURIを設定します。 |
Tabular Workflowsの料金
Tabular Workflowsを使用してモデルをトレーニングする場合、インフラストラクチャと依存サービスのコストに基づいて課金されます。
このモデルを使用して予測を行う場合、インフラストラクチャのコストに基づいて課金されます。
インフラストラクチャのコストは、以下の要因に依存します。
- 使用するマシンの数
- 使用するマシンのタイプ
- マシンの使用時間
- モデルのトレーニングまたはバッチ予測の場合、これはオペレーションの合計処理時間です。
- オンライン予測を行っている場合、これはモデルがエンドポイントにデプロイされている時間です。
また、Tabular Workflowsは、プロジェクト内の以下複数の依存サービスを実行します。
- Dataflow
- BigQuery
- Cloud Storage
- Vertex AI Pipelines
- Vertex AI Training
私が全てのコンポーネントでマシンタイプn1-standard-16で5回訓練1回予測を実行した結果、総額$70程度でした。
まとめ
今回の記事では、Vertex AIのTabular Workflow for Forecastingを紹介しました。
より柔軟で簡単な機械学習をサポートするのでプレビュー版ではございますが是非ご利用ください。
その他VertexAI関連記事
Vertex AI Pipelines で scheduler API がプレビューになりました
Vertex AIのTimeseries Insights APIとは
Vertex AIのGenerative AIサポートの概要
Vertex AI Model Gardenを活用した効果的なモデル開発プロセスの紹介
Discussion