【Gemini-1.5-Pro】マルチモーダルLLMを使って動画検索してみた
こんにちは、クラウドエース SRE ディビジョン所属の茜です。
今回は、マルチモーダル LLM として注目されている Gemini-1.5-Pro を使用して、自然言語での動画検索が可能な簡易的なアプリケーションを作成します。
マルチモーダル LLM とは
マルチモーダル LLM (Large Language Model) は、テキストだけでなく、画像、音声、動画などの複数のモダリティのデータを理解し、処理することができる大規模言語モデルです。
従来の LLM がテキストのみを扱うのに対し、マルチモーダル LLM は異なる種類のデータを統合し、より幅広いタスクに対応することができます。
マルチモーダル LLM は、以下のような特徴を持っています。
-
テキスト、画像、音声、動画の双方向のやり取りが可能
以下のようなタスクが実行可能です。- 写真の情報をテキストで出力する
- テキストの内容を基に画像を生成する
- 音声ファイルから文字起こしを行う
- 動画の内容をテキストで要約する
-
出力精度の向上
様々な種類のデータを処理できるため、インプットできる情報量が増えます。
これにより、ユーザーの質問により的確に答えることができます。
Gemini-1.5-Pro とは

Gemini-1.5-Pro は、Google が開発した次世代マルチモーダル生成 AI 「Gemini 1.5」シリーズの 1 つです。従来の LLM を超える 100 万トークンもの入力が可能な点が特徴です。
性能テストにおいて、大規模言語モデルファミリー「Gemini」の中で最も能力の高いモデルと言われていた「Gemini Ultra」に対して、多くの主要なベンチマークで上回っています。
ユースケース
自然言語での動画検索は、以下のようなユースケースが考えられます。
-
メディア企業における動画アーカイブの管理
ニュース番組やドキュメンタリーのアーカイブから、特定のトピックや人物に関する動画を素早く見つけることができます。膨大な動画アーカイブを効率的に管理し、必要な情報へのアクセスを容易にすることで、制作業務の生産性向上が期待できます。 -
教育機関における講義動画アーカイブの管理
講義動画のアーカイブから、特定のトピックやキーワードに関する動画を素早く見つけることができます。膨大な講義動画アーカイブを効率的に管理し、学生が必要な情報へ容易にアクセスできるようにすることで、学習効率の向上と知識の定着が期待できます。
また、教員が新しい講義や教材を作成する際、過去の講義動画から必要な情報を効率的に収集することができます。動画アーカイブを有効活用することで、教材の質の向上と準備時間の短縮が期待できます。
動作フローの概要
アプリケーションのフローは以下です。
- 動画データの要約を Gemini-1.5-Pro でテキスト化
- タイトル、要約、URL をカラムに持つ BigQuery テーブルを作成
- Vertex AI Search のデータストアにテーブルをインポート
- ユーザーの質問に対して Vertex AI Search で検索を行い結果を返す

アプリケーション作成
動画データのテキスト化
Gemini-1.5-Pro を使用し、動画データの要約をテキスト化します。
今回は動画データとして、YouTube にある動物に関するニュースを 5 つ使用します。
今回使用したプロンプトは以下です。
{動画データ}
動画データから、以下の点に留意して要約を作成してください。要約以外の文字列は出力しないでください。
1,要約は2~3文程度で簡潔に表現する。
2,動画に登場する固有名詞や関連する一般的な単語を適切に含める。
3,文章は平易な表現を用い、読みやすく、意味が明確であるようにする。
4,要約全体は100文字程度の長さに収まるようにする。
5,動画内で実際に起こっている事象のみを説明し、推測や評価を含めない。
6,事象の説明は、具体的な行動や状況を表す表現を用いる。
プロンプトに関して
動画データのテキスト化を行う際、類似性検索にヒットしやすいようなテキストを生成するプロンプトを使用する必要があります。
以下は、プロンプトと出力の一例です。
{動画データ}
添付した動画データから、以下の点に留意して要約を作成してください。要約以外の文字列は出力しないでください。
1、動画の主要なトピックや話題をカバーし、内容を的確に表現する。
2、キーワードや固有名詞を適切に含める。
3、文章は簡潔で、読みやすく、意味が明確であるようにする。
4、要約は100文字程度の長さにする。
広島県尾道市の市立美術館で、警備員と猫の攻防が話題になっている。昨年3月に公開された「猫展」で、美術館に入ろうとした黒猫を警備員が阻止した様子がツイッターに投稿され大きな話題となった。
その後も警備員と猫の攻防は続き、新たな猫として茶トラ猫が登場。茶トラ猫も美術館に入ろうとするも、警備員は優しく制止し、頭などを撫でている。美術館を訪れる人々に癒しを与えているようだ。
ニュースのような動画に対して検索を行う場合、特定の名称や状況に関する検索が行われることが想定されます。
例) 「警備員と猫」「猫の侵入を阻止」
「美術館を訪れる人々に癒しを与えているようだ。」のような出力は、検索クエリとの関連性が低く、ニュース動画の内容を的確に表現していないと言えます。
検索時のノイズとなるため、このような出力をさせないプロンプトを考える必要があります。
今回使用したプロンプトでは、以下のように修正し出力を調整しています。
- 主観的な推測を避けるよう指示を追加
- 動画内で実際に起こっている事象のみを説明するよう指示を追加
- 文数を具体的に指定し、簡潔に表現させる
出力結果から、以下 CSV ファイルを作成します。
"小田急線の車内に可愛らしい珍客が 意外な結末も・・・", "小田急線東海大学前駅で飼い猫が電車に乗り込み、車内を歩き回ったり、乗客に近づいたりしました。 その後、飼い主を知る人が見つかり、猫は無事に飼い主の元に戻りました。", "https://www.youtube.com/watch?v=87yQ8lMeHwc&list=PLKeSkVQhqoOquUOnpthPiOaMAcFZm2uJi&index=1"
"歴史的“迷”勝負!?・・・小さな“訪問者”vs警備員", "広島県尾道市立美術館で、猫が美術館に入ろうとするのを警備員が阻止する様子がTwitterで話題になっています。美術館のスタッフが猫と警備員の攻防を撮影し、ほぼ毎日投稿しているとのことです。", "https://www.youtube.com/watch?v=PYBBK1oUygk&list=PLKeSkVQhqoOquUOnpthPiOaMAcFZm2uJi&index=2"
"気持ち良すぎて…温泉でカピバラ寝落ち 飼育員もビックリ 貴重映像", "群馬県草津熱帯圏の温泉につかるカピバラ「マルくん」の映像。マルくんは気持ちよさそうに温泉につかっているうちに寝てしまい、口と鼻が水面下に沈んでしまった。約20秒後、マルくんは再び起き上がった。", "https://www.youtube.com/watch?v=MZiKvYuH0-E&list=PLKeSkVQhqoOquUOnpthPiOaMAcFZm2uJi&index=5"
"なぜか居付いた手乗りスズメ 姉妹になついて相思相愛", "ある女の子の家に、スズメのチュン太郎が飛んできた。チュン太郎は女の子の肩や腕に載ったり、ときには言葉を理解しているかのような行動を見せる。", "https://www.youtube.com/watch?v=oIxOw0wo_3E&list=PLKeSkVQhqoOquUOnpthPiOaMAcFZm2uJi&index=6"
"大群ザリガニ襲来で住民騒然 岡山市で異常発生", "岡山市の住宅街を流れる用水路に、アメリカザリガニが大量発生しました。用水路から1km下流には田んぼが広がっており、水抜き作業が行われていました。", "https://www.youtube.com/watch?v=eOk_vxppfIU&list=PLKeSkVQhqoOquUOnpthPiOaMAcFZm2uJi&index=11"
BigQuery テーブル、Vertex AI Search アプリ作成
CSV ファイルから、「name」「summary」「url」をカラムに持つテーブルを作成します。

Vertex AI Search のデータストアに、作成したテーブルをインポートします。
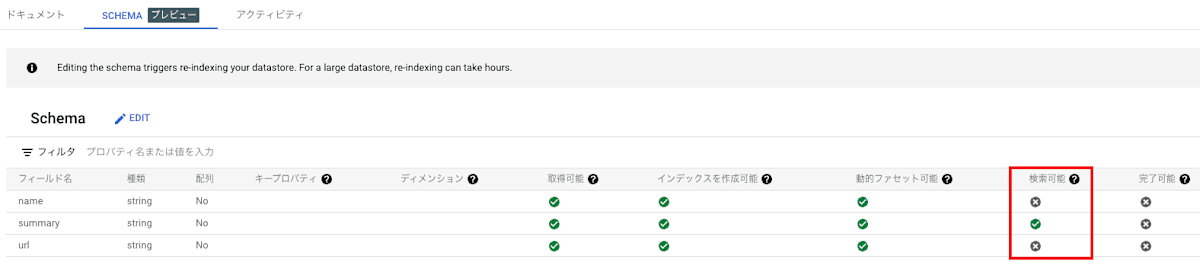
今回は、動画の要約のみを検索対象とします。
スキーマ設定から「summary」のみ「検索可能」のチェックを入れます。
作成したデータストアを使用し、Vertex AI Search アプリを作成します。
作成方法は、こちらの記事や公式ドキュメントをご確認ください。
プレビューで出力を確認します。

Vertex AI Search を用いた検索
今回のアプリケーションでは、Web フレームワークとして streamlit を使用します。
また、LangChain の VertexAISearchRetriever クラスを使用し、Vertex AI Search での検索結果を取得します。
必要なパッケージをインストールします。
pip install streamlit
pip install google-cloud-discoveryengine
pip install langchain-google-community
今回使用したバージョンは以下の通りです。
| パッケージ名 | バージョン |
|---|---|
| streamlit | 1.35.0 |
| google-cloud-discoveryengine | 0.11.13 |
| langchain-google-community | 1.0.5 |
Vertex AI Search での検索結果を取得する部分は、以下のように記述します。
今回は、取得する最大ドキュメント数は 3 つに設定しています。
また、データストアに格納されているデータのタイプは、構造化データを指定しています。
PROJECT_ID = "<YOUR PROJECT ID>"
LOCATION_ID = "<YOUR DATA STORE LOCATION>"
DATA_STORE_ID = "<YOUR DATA STORE ID>"
retriever = VertexAISearchRetriever(
project_id=PROJECT_ID,
location_id=LOCATION_ID,
data_store_id=DATA_STORE_ID,
max_documents=3,
engine_data_type=1,
)
result = retriever.invoke(question)
全体のソースコードは以下です。
streamlit の記述に関する説明は割愛します。
from langchain_google_community import VertexAISearchRetriever
import json
import streamlit as st
PROJECT_ID = "<YOUR PROJECT ID>"
LOCATION_ID = "<YOUR DATA STORE LOCATION>"
DATA_STORE_ID = "<YOUR DATA STORE ID>"
st.title("動画検索アプリ")
question = st.text_input("検索クエリを入力してください")
if question:
retriever = VertexAISearchRetriever(
project_id=PROJECT_ID,
location_id=LOCATION_ID,
data_store_id=DATA_STORE_ID,
max_documents=3,
engine_data_type=1,
)
result = retriever.invoke(question)
st.markdown("")
st.write("#### 検索結果")
cols = st.columns(3) # 横に3つのカラムを作成
for i, doc in enumerate(result):
content = json.loads(doc.page_content)
with cols[i % 3]: # 3つのカラムを順番に利用
st.write(f"{i+1}. **{content['name']}**")
st.video(data=content["url"])
動作確認
構成図には Cloud Run が記載されていますが、これは実際にアプリケーションをデプロイする場合の推奨構成を示しています。本記事では、開発と基本的な機能確認に焦点を当てているため、Cloud Run へのデプロイは行っていません。
以下を実行し、ローカル環境での動作確認を行います。
streamlit run main.py
「警備員が猫の侵入を防ぐ」と検索したところ、該当する動画がトップでヒットしました。
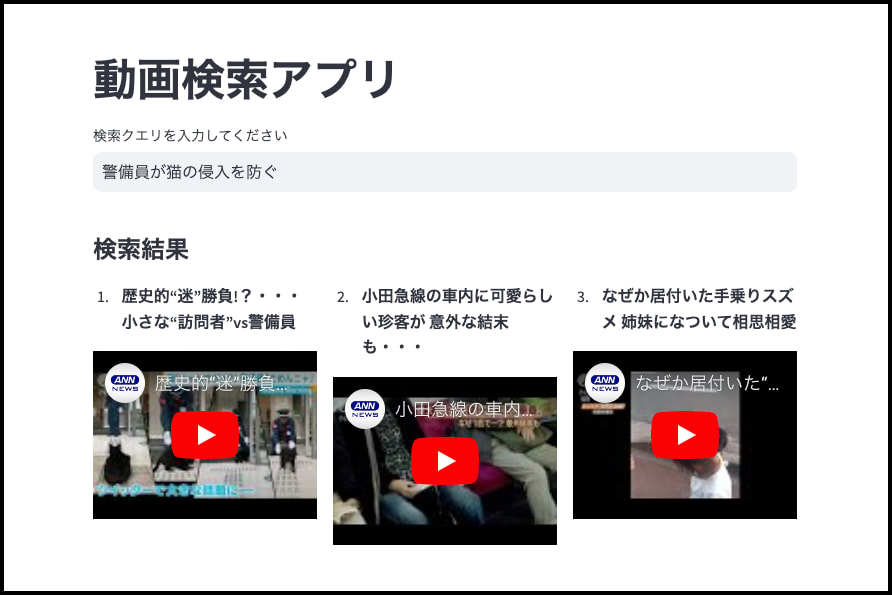
また、「大量発生」と検索した場合も該当する動画がトップでヒットしました。

まとめ
今回は、動画の内容を基に検索を行うアプリケーションを作成しました。
Gemini-1.5-Pro を使用し、動画の内容をテキスト化することで、より詳細で文脈を考慮した動画検索が可能になります。この際、想定される検索クエリに適したプロンプトを設計することが、精度の高い検索結果を得るために非常に重要です。
今回使用したプロンプトはあくまで一例であり、実際の運用に当たっては、検索対象とする動画の特性や、ユーザーの検索ニーズを踏まえた上で、プロンプトの改善を継続的に行っていく必要があります。例えば、動画の種類によっては、要約だけでなくトピックや重要なキーワードを抽出するようなプロンプトの方が効果的な場合もあるでしょう。
マルチモーダル LLM の登場により、様々なデータを統合的に処理することが可能になりました。
これを生かして、どのようなアプローチができるか今後も調査していこうと思います。
Discussion