Eventarc を使用して Dataflow ジョブを管理する
はじめに
こんにちは、クラウドエース データMLディビジョン所属の直江です。
データMLディビジョンとはクラウドエースのITエンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門としております。
データMLディビジョンでは活動の一環として、毎週Google Cloudの新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回紹介するリリースは、Eventarcを使用したDataflowジョブを管理についてです。
Dataflowの概要
まず、Dataflowについて簡単に説明しましょう。
Dataflowは、データ処理ワークフローを構築、実行、監視するためのマネージドサービスです。
Dataflowを使用すると、リアルタイムまたはバッチ処理のデータパイプラインを簡単に構築できます。
また、スケーラビリティや信頼性に優れており、大規模なデータ処理にも対応しています。
Dataflowは、統合されたストリームデータ処理とバッチデータ処理を大規模に提供する Google Cloud サービスです。Dataflowを使用して、1 つ以上のソースからデータを読み取り、変換し、宛先に書き込むデータパイプラインを作成します。
Dataflowの一般的なユースケースは次のとおりです。
- データの移動: データの取り込みやサブシステム間でのデータの複製
- BigQueryなどのデータ ウェアハウスにデータを取り込むETL(抽出、変換、読み込み)ワークフロー
- ストリーミングデータへのMLのリアルタイム適用
- センサーデータまたはログデータの大規模な処理
Dataflowは、バッチ分析とストリーム分析の両方に同じプログラミングモデル(Apach Beam)を使用します。
今回のリリースについて
今回、Eventarcを使用してDataflowジョブを管理できるようになりました。
具体的には、Dataflowジョブの状態変化をEventarcのトリガーに設定できるようになりました。
Dataflowジョブが実行されると、JOB_STATE_QUEUED、JOB_STATE_RUNNING、JOB_STATE_DONEなどのさまざま状態に遷移しますが、それぞれの状態遷移時にEventarcがトリガーされます。
したがって、特定の状態遷移時にのみトリガーする場合は、IF文などでロジックを実装する必要があることに注意してください。
Eventarc のトリガーに設定できるプロダクトは以下の通りです( 2023年12月18日時点)。
- Cloud Functions (2nd gen)
- Cloud Run
- Google Kubernetes Engine (GKE)
- Workflows
※参考:イベントプロバイダと宛先
今回のリリースのユースケースは以下などが想定されます。
- 重要なジョブが失敗した場合は、オンコール エンジニアにアラートを送信
- バッチ ジョブが完了したときにユーザーに通知するか、別のDataflowジョブを開始
- Cloud Storageバケットなど、ジョブで使用されるリソースをクリーンアップ
Eventarc の概要
EventarcはGoogle Cloudで利用できるイベント管理機能です。
Eventarc を使うと、基盤となるインフラストラクチャを実装またはメンテナンスすることなく、イベントドリブンなアーキテクチャを構築することができます。
Eventarcは、分離されたマイクロサービス間の状態変更(イベント)を管理する標準化されたソリューションを提供します。
トリガーされると、Eventarcは配信、セキュリティ、認可、オブザーバビリティ、エラー処理を行いながら、これらのイベントをさまざまな宛先に転送します。
Eventarcを利用することで以下のようなメリットがあります。
- サーバーレス:Eventarcは完全に管理されたサーバーレスイベントルーティングサービスであるため、インフラストラクチャの管理やスケーリングについて心配する必要がありません。
- リアルタイム処理:Eventarcはイベントベースのアーキテクチャをサポートしており、リアルタイムでのイベント処理が可能です。独立してデプロイやスケールすることができます。
- 統合:EventarcはGoogle Cloudの他のサービスとの統合が容易であり、特にCloud FunctionsやCloud Runとの連携がよく使われます。
Eventarc を使うと、ジョブの依存関係の制御が、容易になります。
Eventarcトリガーを使用してELTパイプラインを実行してみた
検証の全体像
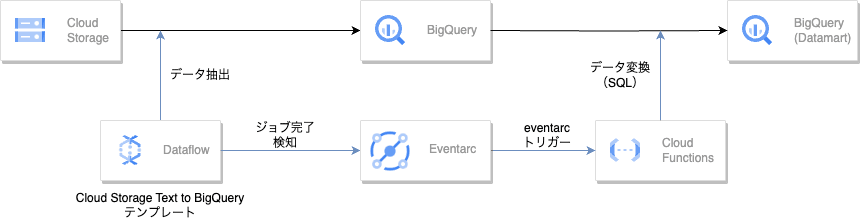
今回、Eventarcトリガーを使用してELTパイプラインを実装してみました。
手順としては以下の通りです。
- Cloud Storage に置かれた CSV を Dataflow を使って、BigQuery へテーブルデータとして取得
- Dataflow取り込みが完了したら、完了をEventarcで検知
- Eventarc をトリガーとして、Cloud Functions が Dataflow で取り込んだBigQueryのテーブルに対してSQLを発行することで、データマートを作成
一連のフローはこのようになります。
今回使用するデータ
Cloud Storageに保存したデータ(CSV)がこちらです。
| Member_ID | Book | Price | Date |
|---|---|---|---|
| 3 | 絵本 | 1500 | 2023-10-04 |
| 1 | AI教科書 | 1000 | 2023-10-03 |
| 2 | 国語辞典 | 3000 | 2023-10-17 |
| 3 | 英和辞典 | 2500 | 2023-10-01 |
| 1 | 数学教科書 | 1500 | 2023-10-30 |
こちらのCSVは書籍の購入履歴です。
具体的には、 購入者のIDと書籍タイトル、価格、購入日を記録しています。
また、BigQuery 上には、書籍購入者のマスタデータがあらかじめ、下表の通りテーブルとして登録されています。
具体的には、購入者のIDと名前、国籍をテーブルに格納しています。
| ID | Name | Country |
|---|---|---|
| 1 | Tom | USA |
| 2 | Suzuki | Japan |
| 3 | John | USA |
今回の検証のゴールは、これらのデータを使って、購入者の国ごとの購入合計金額をデータマートとして保存することです。
Dataflowの実装
Dataflowは、Google 提供のテンプレートを利用して実装しました。
具体的にはCloud Storage Text to BigQuery テンプレート を利用しました。
このテンプレートは、Cloud Storage に保存されているテキストファイルを読み取り、ユーザーが指定する JavaScript ユーザー定義関数(UDF)を使用してそれらのファイルを変換し、結果を BigQuery テーブルに追加するバッチパイプラインです。
したがって、JavaScript が必要なため、公式ドキュメントを参考に、以下のJavaScript を作成しました。
function transformJson(line) {
let values = line.split(',');
let obj = new Object;
obj.Member_ID = values[0];
obj.Book = values[1];
obj.Price = values[2];
obj.Date = values[3];
const jsonString = JSON.stringify(obj); //JSON
return jsonString;
}
このJavaScriptは、カンマで区切られた文字列をJSON形式に変換します。
具体的には、文字列を分割し、その各部分を新しいオブジェクトのプロパティとして設定します。
最後に、そのオブジェクトをJSON形式の文字列に変換して返します。
また、このテンプレートを使用するには、Cloud Storage に以下を配置しておく必要があります。
- BigQuery に保存するデータ
- 今回だと購入履歴データ(CSV)
- BigQuery に保存するデータのスキーマ(JSON)
- UDF を実行するための JavaScript
これらを準備した上で公式ドキュメント記載の下記コマンドで Dataflow ジョブが実行可能です。
コマンドの詳細は公式ドキュメントをご参照ください。
gcloud dataflow jobs run <$JOB_NAME> \
---gcs-location gs://dataflow-templates/latest/GCS_Text_to_BigQuery \
--region asia-northeast1 \
--parameters \
javascriptTextTransformFunctionName=<$JAVASCRIPT_FUNCTION>,\
JSONPath=<$PATH_TO_BIGQUERY_SCHEMA_JSON>,\
javascriptTextTransformGcsPath=<$PATH_TO_JAVASCRIPT_UDF_FILE>,\
inputFilePattern=<$PATH_TO_TEXT_DATA>,\
outputTable=<$BIGQUERY_TABLE>,\
bigQueryLoadingTemporaryDirectory=<$PATH_TO_TEMP_DIR_ON_GCS>
Cloud Functionsの実装
今回は、Eventarc をトリガーとして、Cloud Functions を起動します。
Cloud Functionsのトリガーの設定方法は次の通りです。
Cloud Functions の作成画面で「トリガーを追加」→「その他のトリガー」を選択します。

「イベントプロバイダ」に「dataflow」と入力します。

「イベント」で「google.cloud. dataflow.job.v1beta3.statusChanged」を選択します。

今回の検証では、「サービスアカウント」から「Compute Engine default service account」を選択します。
使用するサービスアカウント には、eventarc.eventReceiver ロールが付与されている必要があることに注意してください。

Cloud Functionsのコードを記載します。
Cloud Functionsのディレクトリにはmain.pyとrequirements.txtを格納しています。

以下は、Cloud Functionsで使用するPythonスクリプトです(main.py)。
このPythonスクリプトは、Google CloudのBigQueryを使用して特定のクエリを実行し、その結果をテーブルに書き込んでいます。
このスクリプトは特にDataflowジョブが完了したときに1回だけ実行したいため、Dataflowジョブステータスが”JOB_STATE_DONE”になった時のみ実行されるように設計されています。
import functions_framework
from google.cloud import bigquery
table_id = <TABLE ID>
DATAFLOW_JOB_STATUS = "JOB_STATE_DONE"
def query_bigquery():
client = bigquery.Client()
job_config = bigquery.QueryJobConfig(destination=table_id)
job_config.write_disposition = bigquery.WriteDisposition.WRITE_TRUNCATE
query = """
SELECT member.Country, SUM(purchase_history.Price) AS Total_Sales
FROM `path.to.table` AS member
LEFT JOIN `PROJECT_ID.eventarc_dataflow_trigger.purchase_history` AS purchase_history
ON member.ID = purchase_history.Member_ID
GROUP BY member.Country
"""
print("Start BQ Load.")
query_job = client.query(query, job_config=job_config)
query_job.result() # Waits for job to complete.
print("Query results loaded to the table {}".format(table_id))
@functions_framework.cloud_event
def main(cloud_event):
print(
f'dataflow job status: {cloud_event.data["payload"]["currentState"]}')
if cloud_event.data["payload"]["currentState"] == DATAFLOW_JOB_STATUS:
query_bigquery()
print("BQ Job Finished")
以下のmain.pyに記載されたクエリを解説します。
query = """
SELECT member.Country, SUM(purchase_history.Price) AS Total_Sales
FROM `path.to.table` AS member
LEFT JOIN `PROJECT_ID.eventarc_dataflow_trigger.purchase_history` AS purchase_history
ON member.ID = purchase_history.Member_ID
GROUP BY member.Country
"""
このSQLクエリは、各国ごとにメンバーの購入合計(総売上)を計算します。
具体的には、メンバーテーブルと購入履歴テーブルをメンバーIDで結合し、国ごとに購入価格を合計しています。
以下はrequirements.txtの中身です。
事前にインストールするライブラリを記載しています。
functions-framework==3.*
google-cloud-bigquery
実行結果
ここまでで、実装が完了したので、実際にDataflow を実行してみましょう。
Dataflowを実行すると、このようなグラフが見れます。

Dataflow の実行が完了したので、最終的に作成される BIgQuery 上のデータマートを見てみましょう。
想定どおり、国別に購入金額の合計が下表のようなテーブルとして作成されています。
つまり、Dataflow 完了をトリガーとして、Cloud Functions が起動したことがわかります。
| Country | Total_Sales |
|---|---|
| USA | 6500 |
| China | 3000 |
実際にCloud Functions のログを確認すると、Dataflow ジョブの状態が、JOB_STATE_DONEとなった後に、BigQuery にテーブルが作成されたことがわかります。

まとめ
今回は Eventarc を使用した Dataflow ジョブの管理について紹介しました。
この機能によって、Dataflow を使ったパイプラインの実装が、より簡単になりましたね。
皆さんもぜひご活用ください。
Discussion