サービス終了する AutoML Tables の代わりに Vertex AI を使う
はじめに
こんにちは。クラウドエース データソリューション部の池上有希乃です。
クラウドエース データソリューション部 について
クラウドエースのITエンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています🤝 もし、ご興味があれば エントリー をお待ちしております!
私は個人的に Google Cloud が AutoML のサービスを提供する前から AutoML という取り組みに興味を持っていて、過去には PyLadies Tokyo という女性の Python コミュニティで LT をしたことがあります (参考: Python で機械学習を自動化 auto sklearn)。
Google Cloud には、AutoML Tables、AutoML Vision や AutoML Natural Languageなどの、AutoMLのサービスがありました。ところが、2024年3月31日をもって Google Cloud のサービスとしての AutoML Tables が終了となります。しかし、機能としては引き続き同等のものが Vertex AI の中で使うことができます。Web上には「AutoML Tables の使い方記事」や「Vertex AI の使い方」に関するドキュメントや記事はあるものの「AutoML Tables で出来たことと同じことを Vertex AI で実施するにはどうすればよいか」という記事は見当たりませんでした。今回、このような記事として残すことで、少しでも「AutoML Tables が終了してしまうことで、やりたいことの実現方法に辿り着けない」人を減らしたいと思い、筆を執りました。そのため、この記事では、AutoML のなかでも AutoML Tables に焦点を当てていきます。
なお、既に作られた AutoML モデルを Vertex AI への移行は Vertex AI に移行のページにて紹介されています。この記事は、新たに AutoML Tables と同等のことを Vertex AI でモデル作成・運用を紹介することに焦点を当てています。
AutoML Tables はこんな便利なサービスだった
まずは、AutoML Tables がどんなサービスだったか説明します。
AutoML Tables のサービス概要
AutoML Tables は表形式データを教師データとして、モデルのトレーニングと評価、予測ができるものです。
AutoML Tables のメリット
- モデル作成にプログラミングが不要
- 機械学習モデルの理論に詳しくなくても性能のよいモデルが構築できる
- 内部で複数のモデルタイプを自動的に評価・検証し、一番よいモデルを選んでくれる
- 作成したモデルはエクスポートでき、クラウド以外でも利用できる
AutoML Tables のデメリット
- 予測と分類しかできない
- 内部で実装済のモデルしか使えない
- 教師データとして使える列数に上限がある
- Cloud Storage のオブジェクト (≒ファイル) 形式は CSV しか対応していない
注意点
AutoML Tablesはモデル作成の知識は不要ですが、データ整備やモデル評価の知識は必要となります。たとえば、「教師データに与えるべきでない列」を与えていないかの判断は自分たちで行う必要があります。また、作ったモデルが良いか悪いか、あるいは実用に耐えられるか否かの判断は自分たちで行う必要があります。
これは、AutoML Tables に限らず Vertex AI に対しても当てはまることです。
同等のことを Vertex AI で実現するには
ここからは AutoML Tables と同様のことを Vertex AI で実現する手順を紹介します。Vertex AI の話なのか AutoML Tables の話なのかわからなくなった場合は、Vertex AI の話であると思っていただければと思います。
まず、一般的な機械学習の利活用の流れは以下の通りです。
- 機械学習でやりたいことの整理をする
- データセットを用意する
- モデルのトレーニングをする
- モデルの評価をする
- モデルを使って予測する
以下のセクションでは、この流れで説明します。また、それぞれのセクションで AutoML と Vertex AI での差がある部分は述べていきます。
やりたいことの整理をする
まず機械学習モデルを作る前に、機械学習によって実現したい目的が Vertex AI のサービスにより生成されるモデルで達成できるかを吟味する必要があります。Vertex AI の表形式データ (テーブルデータ) で作れることができるモデルの種類は、「分類/回帰」と「予測」です (2024年1月時点)。
たとえば、メールがスパムメールかそうでないメールかを識別するようなことを「分類」といいます。また、物の値段のような数値を求めるものは「回帰」といいます。「予測」は、将来の一定期間ごとの売上高の予測のような時系列データに対する予測モデルのことを指します。
教師データとなる表形式データを登録する
Vertex AI データセットに登録
目的と Vertex AI のサービスがフィットした場合、次はデータセットを登録する必要があります。Cloud Console から [Vertex AI] セクション -> [データセット] ページを選び ➕作成 ボタンを押すとデータセットを登録できます。このとき AutoML Tables と同等のことを行う場合、データタイプを表形式として選択することが必要です。
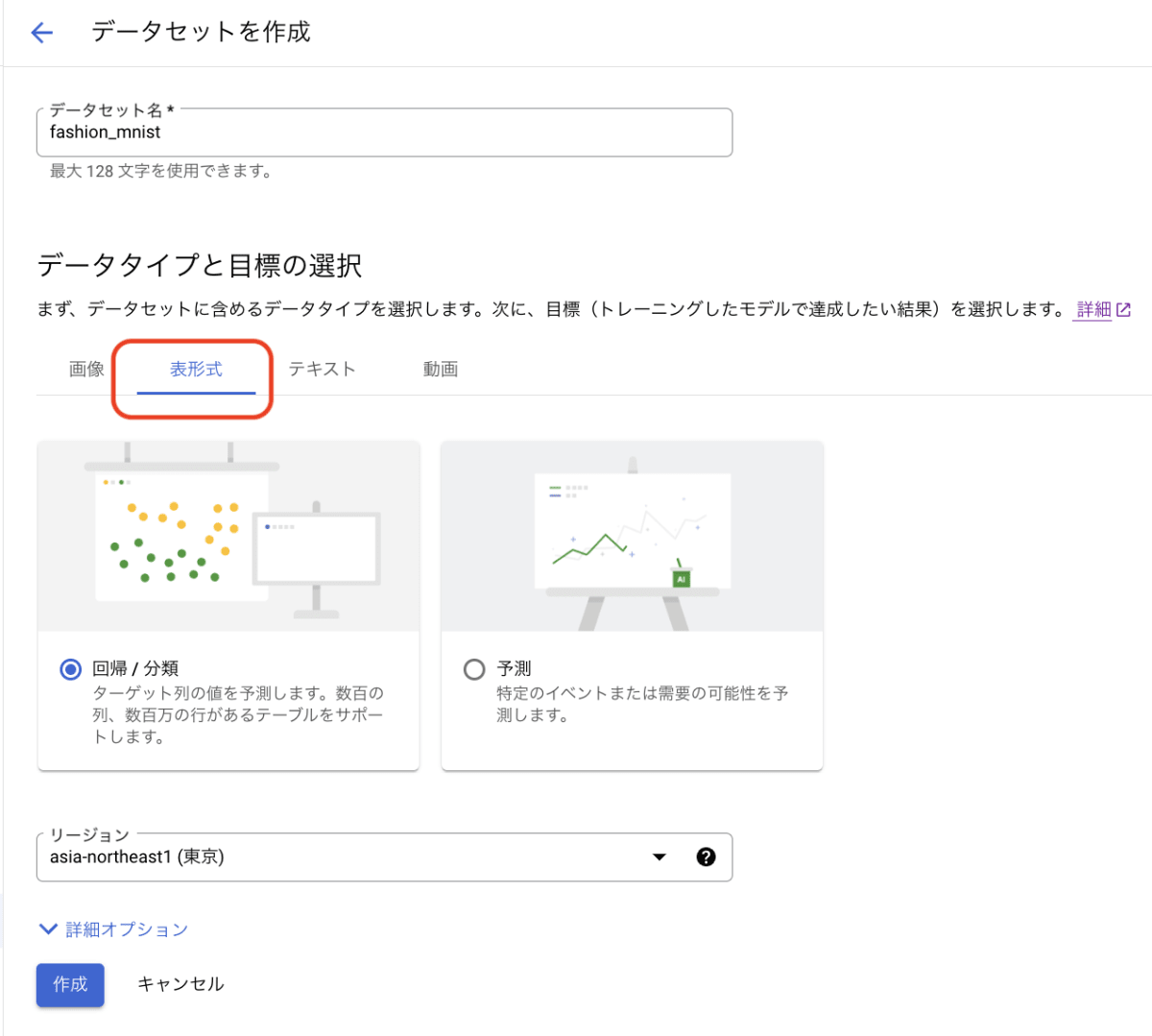
次にデータソースを選択します。以下の三択から選べます。
- パソコンから CSV ファイルをアップロード
- Cloud Storage から CSV ファイルを選択
- テーブルまたはビューを BigQuery から選択
CSV ファイルの時に注意する点として、一行目にヘッダーがない CSV は扱えないという点です。ヘッダーがないとエラーになってしまうので、カラム名のヘッダーが一行目にあるか確認しましょう。
データ量
データに関してはタスクの種類に応じて十分な教師データ (トレーニングデータ) を準備する必要があります。一般的に、教師データの数が多ければ多いほど精度が上がることが知られています。ここで問題となるのが、どの程度の量のデータを集めたらよいかということです。AutoML 初心者向けガイドによると、推奨される教師データの最低数量は次のとおりとなっています。
- 分類問題: 50 行 × 特徴数
- 予測問題:
- 5,000 行 × 特徴数
- 時系列 ID 列に一意の値 10 個 × 特徴数
- 回帰問題: 200行 × 特徴数
注意事項として、これはあくまでも最低数量なので、実用上はこれ以上のデータを集める必要があります。
逆に最大限度のサイズについては、データ構造の要件を参照してください。重要だと思うところだけまとめると以下の通りです。
- データセットは 100 GB 以下
- データセットの列数は 2~1,000
- データセットの行数は 1,000~100,000,000 行
- ターゲット列の指定の必要あり。null 値は不可。カテゴリや数値にする必要あり。カテゴリの場合、2~500 個の固有の値が必要。
このあたりは AutoML Tables と差はありません。
データのクリーンアップ・クリーニング
AutoML Tables と同様に Vertex AI も欠損値を処理できますが、一般的にはデータの欠損値が多いほど精度が下がる傾向にあります。そのため欠損値の多い行は削除すると良いかもしれません。
また、テーブル内の文字列に対して全角英数字を半角英数字にする、半角カナを全角カナにするなどの表記を統一することも有効です。
モデルのトレーニングを実施する
さて、ここまでの手順を終えたらいよいよモデルのトレーニングです。まず、Cloud Console から [Vertex AI] -> [トレーニング] を選びます。
リージョンの選択
[トレーニング] のページを開いたら、データセットと同じリージョンを選びます。データセットと違うリージョンが選択されていると、そのデータセットは表示されませんのでご注意ください。
新しいモデルのトレーニング
次に 新しいモデルのトレーニング を選択し、データセットと目的 (分類、回帰など) を選び、Model training method で Auto ML を選択します。そして、Target column に教師ラベル (目的変数、正解ラベル) のカラムを選びます。トレーニングオプション の詳細オプションにて最適化の目標を選べますが、多クラス分類のときはログ損失以外を選ぶとトレーニング時にエラーになるので注意しましょう。
なお、デフォルトではデータセットからトレーニングセット、検証セット、テストセットへの分割は自動で行ってくれます。自分で指定することも出来ます。時系列データの場合は、時系列を保持したまま分割することも出来ます。
AutoML Tables ではトレーニング方法が AutoML のみでしたが、Vertex AI ではカスタムトレーニング (TensorFlow、scikit-learn、XGBoost をクラウドで実行) という選択肢もある点も Vertex AI ならではです。つまり、AutoML は Vertex AI のトレーニングにおける選択肢のひとつ、という位置付けになっています。
コンピューティングと料金
最後に コンピューティングと料金 で、モデルのトレーニングに費やすノード時間の最大値を入力します。トレーニングに費やす時間が長いほど精度が高いモデルが出来る傾向にありますが、そうは言ってもどこかで頭打ちになります。なので、無闇に時間をかければ良いというものではありません。Auto ML の料金のページの1ノード時間あたりの料金を参考に、「モデル作成にどれだけのお金をかけてもいいか」を基準に最大ノード時間を選ぶべきでしょう。ちなみに料金は、AutoML Tables と変わりません。
また、 早期停止を有効にする の項目を有効にすることもトレーニング料金の節約になります。先ほど「どこかで頭打ちになります」と書きましたが、この項目を有効にすると精度が頭打ちになったと判断した時点でトレーニングが終了します。これは early stopping とも呼ばれます。この場合、余ったトレーニング予算は返金されます。この項目が無効にしてある場合は、予算を使い切るまでトレーニングが継続されるのでご注意ください。
出来上がったモデルを確認する
ここは AutoML Tables と Vertex AI で違いはないのですが、AutoML Tables を知らない人のために説明します。
モデルのトレーニングが完了したら各種指標 (AUC ROC, 精度, 再現率, F1スコアなど) を確認し、期待通りかどうか評価しましょう。
ここでは Fashion MNIST の CSV をトレーニングした結果を紹介します。
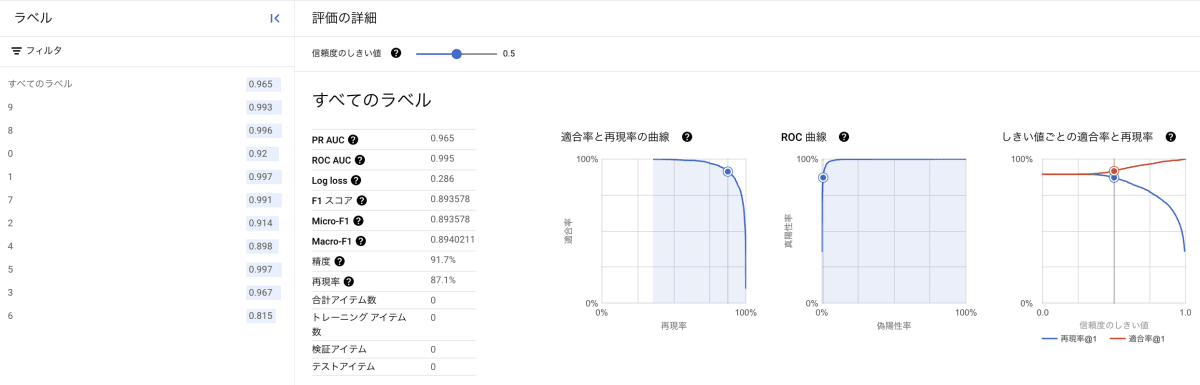
すべてのラベル全体での PR AUC (適合率と再現率の曲線内の面積) が0.965なので全体的によく識別できるモデルといえるでしょう。
しかし、ラベル6のシャツの PR AUC が0.815と低いのが気になります。その原因を混同行列 (confusion matrix) で探っていきましょう。

ラベル6のシャツは、ラベル0のTシャツ/トップスと間違えやすいようです。確かにグレースケールの低解像度画像だと識別が難しそうですね。と、このように混同行列を見ることでモデルの予測が外れた時の傾向をすぐに把握することが出来ます。
他にも、特徴量の重要度 (feature importance) を見ることも出来ます。
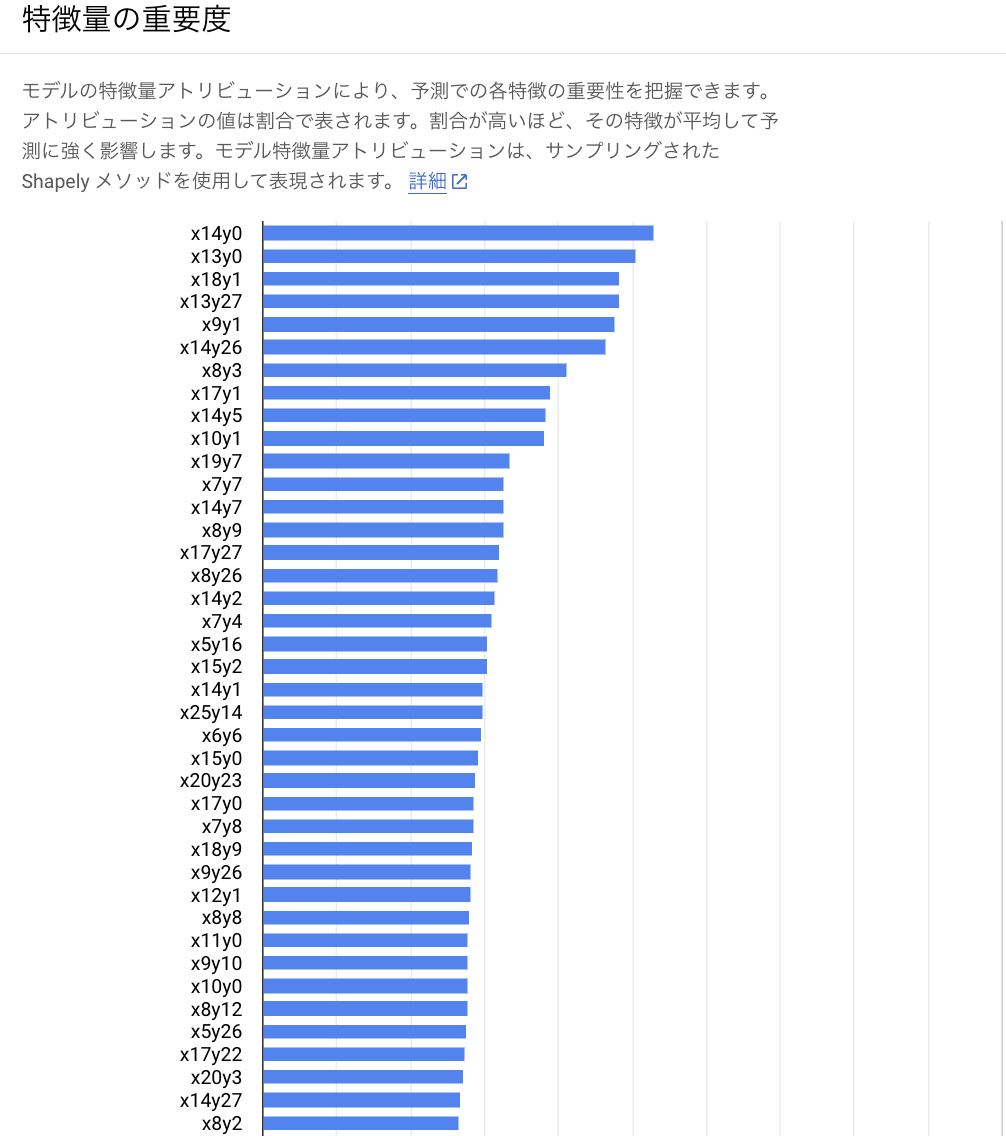
Fashion MNIST は画像を CSV にしたものなので直感的にわかりにくいですが、x14y0 の位置のピクセルの特徴量が分類に最も寄与していることがわかります。
AutoML が決めたモデルの構造を知りたい場合は、[バージョンの詳細] タブから モデルのハイパーパラメータ 行の モデル をクリックします。
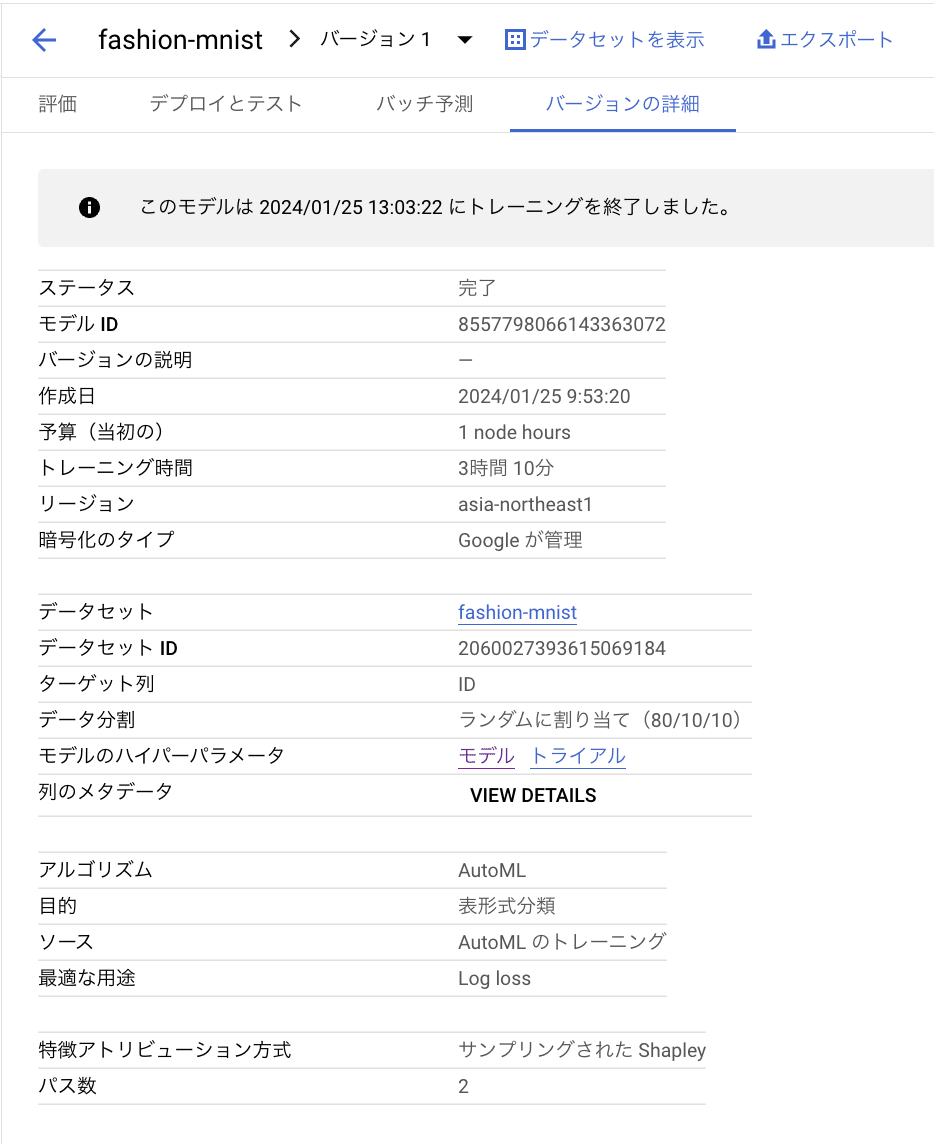
すると、Cloud Logging の画面に遷移して、エントリを展開していくことで詳細を確認することが出来ます。

この場合は、ニューラルネットワークで隠れ層3層、隠れ層のサイズ256ユニットであることがわかります。
予測を実施する
予測については、バッチ予測は AutoML Tables と Vertex AI で大きな差はありませんが、オンライン予測はエンドポイントを指定するという点で差があります。モデルを複数のエンドポイントで使うことが出来るし、1つのエンドポイントにさまざまなモデルを紐づけることも出来ます。
バッチ予測の場合
バッチ予測は、一度に大量のデータの予測結果を出力することが出来ます。ただし、対象のデータ数が少ない場合は処理時間のオーバーヘッドが割に合わないことにご注意ください。
なお、バッチ予測は入出力に BigQuery 上のテーブルと Cloud Storage 上のオブジェクトを利用することが出来ます。これら入出力にはそれぞれ別のサービスを使うこと (たとえば、入力に Cloud Storage 上のオブジェクトを指定し、出力に BigQuery 上のテーブルを指定すること) も可能です。
それと、入力データに特徴量カラムと一致しない余分な行があっても、出力先が Cloud Storage の場合は余分な行は別のオブジェクトに除外されます。出力先は BigQuery だと errors_ID というカラムにエラー内容が記載されています。必要な行が欠けている場合は出力先がBigQueryだと「errors」と prefix のついたテーブルが作成されます。
出力に BigQuery を利用する場合の注意点
BigQuery を出力先に指定する場合、テーブル名まで指定したパスを入れると Table name is not allowed in Bigquery output uri. というエラーになります。これは、プロジェクト名のみを指定した場合はデータセットとテーブルが作られて、プロジェクト名とデータセットを指定した場合はテーブルが作られるという挙動になっていることに起因するようです。このことは GitHub に Issue があがっています。
入力に Cloud Storage 上のオブジェクトを利用する場合の注意点
Vertex AI の表形式データの予測で Cloud Storage 上のオブジェクトに対応しているフォーマットは CSV、JSONL、TFRecord です (2024年1月現在)。AutoML Tables では CSV 形式のみでしたが、対応するフォーマットが増えました。
なお、CSV には、最初の行に特徴量の列の名前が含まれている必要があります。
Cloud Console上からの予測
まず、Cloud Console から [Vertex AI] -> [バッチ予測] を選びます。次に、➕作成 ボタンを押して設定することでバッチ予測の実行が可能です。
なお、このモデルの特徴のアトリビューションを有効にする にチェックを入れると、予測結果でどの項目が効いたかの重みが表示されます。ただし、そのための追加費用もかかるので必要に応じてチェックを入れましょう。
ちなみにプレビューにて公開されている モデルのモニタリング という項目にて現在サポートされているのは、トレーニング サービング スキューのみです (2024年1月現在)。
APIを介した予測
APIによってバッチ予測リクエストを行うことも可能です。詳しくはモデルにバッチ予測リクエストを行うの項目を参考にしてください。
オンライン予測の場合
バッチ予測は一度に大量のデータの予測を行う一方で、オンライン予測はモデルをデプロイすることでオーバーヘッドを気にせずにすぐに予測結果を返すこと出来ます。その代わり、API 呼び出しごとに1つの予測リクエストしか受け付けません。少量の件数に対して素早く予測結果を得たい時にオンライン予測が適しています。
また、AutoML Tables と違って Vertex AI では予測のエンドポイントに複数のモデルをデプロイ出来たり、同じモデルを複数のエンドポイントにデプロイ出来たりします。
ただし、モデルをデプロイし続けているだけで継続的に課金されることにご注意ください。予測処理を実行しているか、スタンバイ状態かに関係なく、使用されているノードに対して料金が発生します。不要になったらデプロイを解除しエンドポイントを削除しましょう。
その他にも、マシンタイプや最小/最大ノード数の設定にも気をつけましょう。マシンタイプがリッチなほど大きいモデルでもすぐに予測結果を返したり、大量のリクエストを捌くことが出来ますが、その分料金が嵩みます。また、どのくらいの頻度でリクエストを送るかを考えてノード数を設定しないと同じく料金が嵩んだり、予測に時間がかかったりします。用途に応じて適切な設定を選びましょう。
Cloud Console上からの予測エンドポイントへのモデルのデプロイ
まず、Cloud Console の [Vertex AI] セクションで、[オンライン予測] ページに移動します。[➕作成] ボタンを押します。
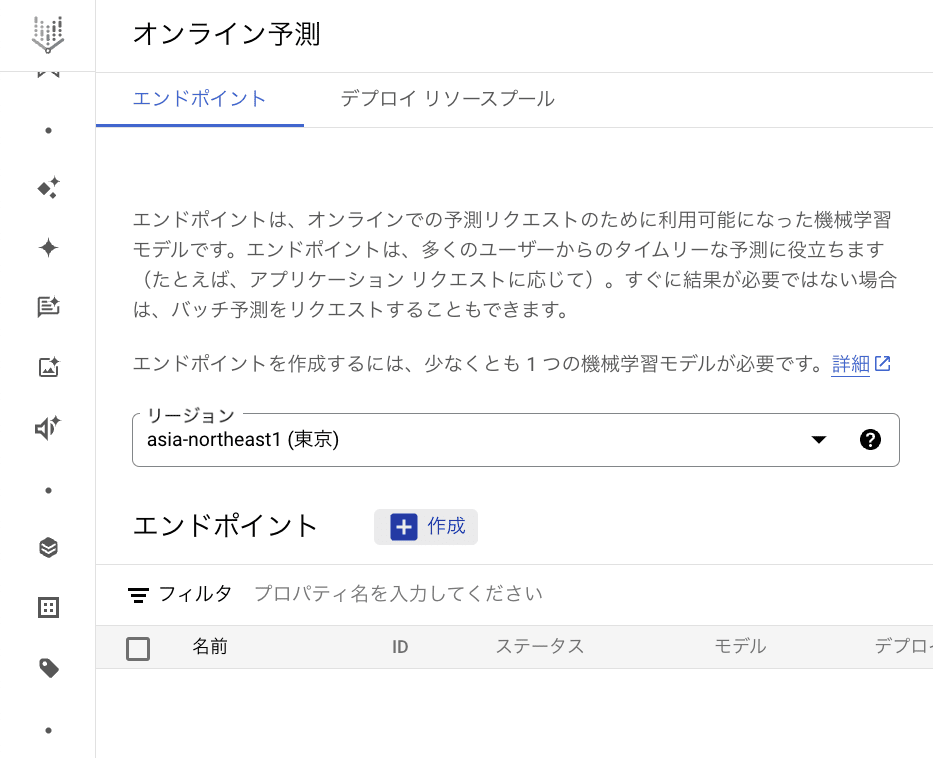
すると、[新しいエンドポイント] の画面が出ます。ここでエンドポイント名を入力し、アクセスを 標準 (REST API) か プライベート (VPC ネットワークとプライベートサービス アクセスを使用したプライベート接続) かを選択します。
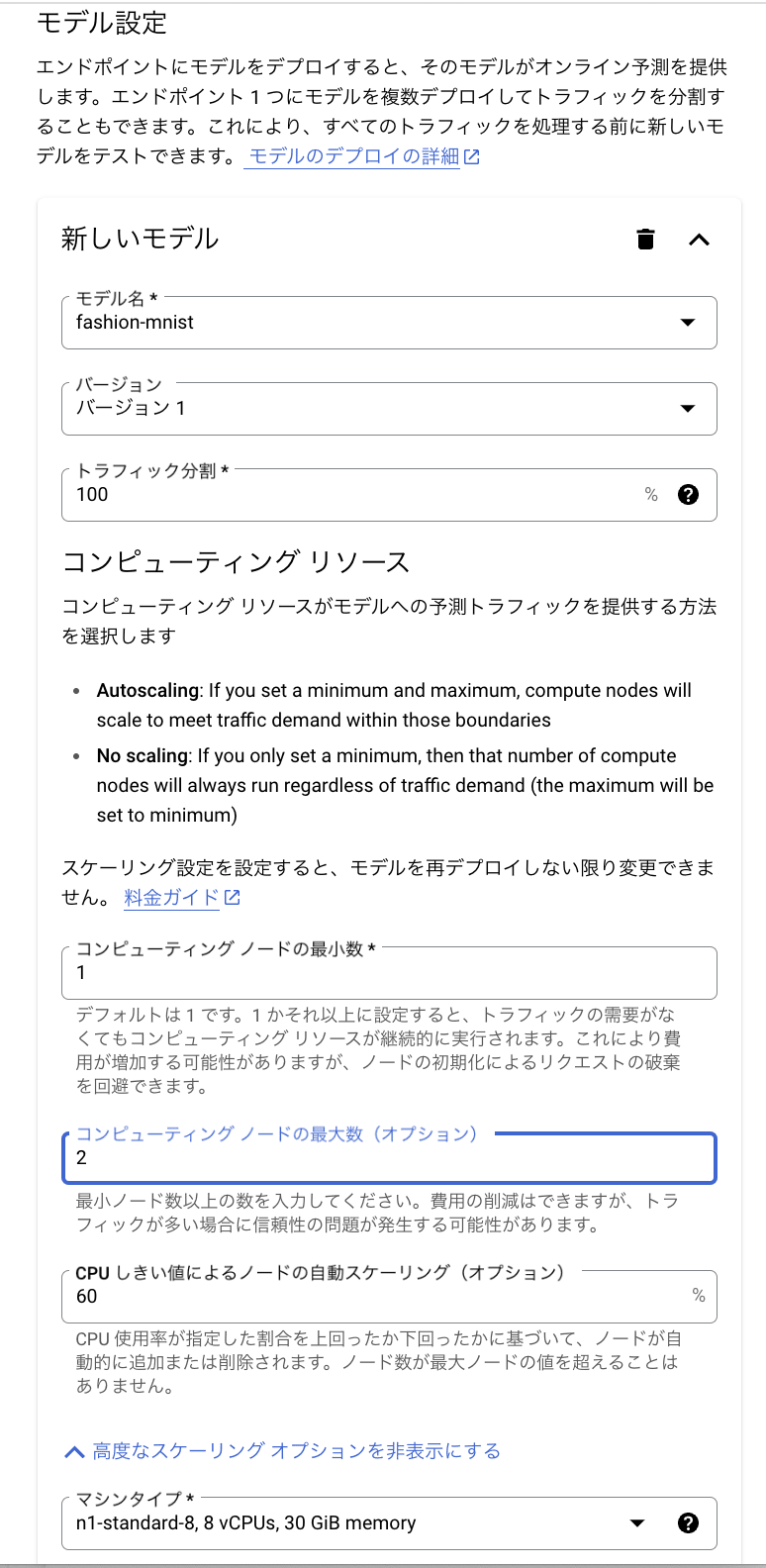
その後、[モデル設定] のページでは、デプロイするモデルとそのバージョン、計算ノードの最小数、最大数、オートスケーリングのルール、マシンタイプを設定できます。マシンリソースのサイズが大きいほど、予測パフォーマンスが向上しますが、コストも増加します。
[モデルのモニタリング] ページで、モニタリングを ON にするとトレーニング サービング スキューや予測ドリフトを追跡することが出来ますが、追加で料金がかかります。ON にする場合は、トレーニングデータの場所を入力し、ターゲット列の名前を入力します。OFF の場合は、モニタリングの設定は不要です。
そして、[作成] をクリックして、エンドポイントにモデルをデプロイ出来ます。
APIを介した予測
オンライン予測は、基本的にAPIを介した予測を行うことが基本となります。詳しいやり方は、デプロイされたモデルを使用してオンライン予測を取得するの項目を参考にしてください。
モデルのエクスポート
モデルのエクスポート周りは、モデルサーバーのパスが変わったくらいで AutoML Tables とあまり変わりません。ですが、この記事では記録のために手順を記載します。
作成したカスタムモデルを Cloud Storage にエクスポートする
[Vertex AI] セクションの [Model Registry] のページから、Cloud Storage にモデルをエクスポートします。
モデルをDockerコンテナ環境に移す
まず、モデルを gsutil コマンドなどで Cloud Storage からダウンロードします。モデルは以下のような形式の名前になっています。
model-<model-id>/tf-saved-model/<export-timestamp>
しかし、Docker では、名前にタイムスタンプが含まれているとディレクトリが無効になってしまうので、ディレクトリ名からタイムスタンプを削除する必要があります。
mv model-<model-id>/tf-saved-model/<export-timestamp> model-<model-id>/tf-saved-model/<new-dir-name>
モデルサーバを実行してモデルデータを読み込ませる
docker pull ${MODEL_SERVER_IMAGE}
pull するモデルサーバーのイメージのパスは、エクスポートされたモデルディレクトリの environment.json ファイルにあります。environment.json のパスは次のようになります。
model-<model-id>/tf-saved-model/<new-dir-name>/environment.json
もしも、environment.json ファイルが存在しない場合は、${MODEL_SERVER_IMAGE} に次のパスを指定します。
${REGION}-docker.pkg.dev/vertex-ai/automl-tabular/prediction-server-v1
${REGION} を us、europe、または asia に置き換え、Docker イメージの取得元となる Docker リポジトリを選択します。
以下のコマンドで作成したディレクトリ名を使用して、Docker コンテナを起動します。
docker run -v `pwd`/model-<model-id>/tf-saved-model/<new-dir-name>:/models/default -p 8080:8080 -it ${MODEL_SERVER_IMAGE}
予測を実行する
ここでは Python を使った Docker コンテナからのマルチクラス分類モデルの予測のサンプルコードを示します。CSV ファイルを読み込んで pandas の DataFrame 型として予測結果を格納するものです。
import json
import subprocess
import pandas as pd
def predict_from_csv(csv_path):
df = pd.read_csv(csv_path)
result_df = None
for _, row in df.iterrows():
row_dict = row.to_dict()
curl_data = {"instances": [row_dict]}
cmd = f"curl -H \"content-type: application/json\" -X POST --data '{json.dumps(curl_data)}' http://localhost:8080/predict"
result = subprocess.run(cmd, shell=True, capture_output=True, text=True).stdout
result_dict = json.loads(result)
r = dict()
for idx in range(len(result_dict["predictions"][0]["classes"])):
r[result_dict["predictions"][0]["classes"][idx]] = [result_dict["predictions"][0]["scores"][idx]]
if result_df is None:
result_df = pd.DataFrame(r)
else:
result_df = pd.concat(result_df, pd.DataFrame(r))
return result_df
結果を CSV ファイルとして出力したい場合は result_df.to_csv("results.csv", index=False) などと実行するとよいでしょう。
最後に
この記事では AutoML Tables と同等のことを Vertex AI で実現する手順を紹介してきました。Vertex AI は単に AutoML Tables と同じことができるだけでなく、予測のオブジェクト (≒ファイル) 形式が、CSV の他に JSONL、TFRecord に対応していたり、予測のエンドポイントに複数のモデルをデプロイ出来たりと、より便利になっています。そして、AutoML は Vertex AI Training の一つの選択肢となっており、完全に Vertex AI と統合されているといっても過言ではないでしょう。
最後にひとつ言葉を添えてこの記事を締めたいと思います。
「AutoML Tables これまでありがとう。そして改めて Vertex AI こんにちは!」
Discussion