インフラストラクチャの障害を監視できる Personalized Service Health の紹介
こんにちは。クラウドエース SRE 部の阿部です。
本日は 2024 年 1 月 24 日に一般提供された Personalized Service Health を紹介します。
Google Cloud における監視の基本
Personalized Service Health を紹介する前に、Google Cloud の監視の基本的な考え方について説明します。

一般的な監視のポイント
一般的なアプリケーションの監視は、概ね 3 種類の方法があります。
- 外形監視
- メトリクス監視
- ログ監視
- ダッシュボード監視
外形監視はアプリケーションが外部に公開しているエンドポイントと通信して想定する応答が返ってくるかを監視する方法です。Cloud Monitoring であれば、Uptime Check や Synthetic Monitoring が該当します。
メトリクス監視は、アプリケーションの CPU 使用率やメモリ使用量、インスタンス数のようなリソースの状況に関する指標を使った監視です。Cloud Monitoring の Metrics を使ったアラートポリシーが該当します。(メトリクス監視以外の呼び方もあるかも知れませんが、とりあえずこの記事ではこのように呼びます。)
ログ監視は、アプリケーションや Google Cloud のプラットフォームのログメッセージ(エラーメッセージや監査ログ等を含む)において、特定のキーワードやラベルをもったメッセージの有無で監視する方法です。Cloud Logging と Cloud Monitoring を組み合わせて設定します。
※Cloud Monitoring はこれ以外にも SLO Monitoring やカスタムメトリクス監視もありますが、ここでは細かい言及を割愛します
1 ~ 3 の監視は、基本的にはアラートポリシーを作成し、メール等でプッシュ通知するように設計・実装します。
また、ダッシュボード監視として 1 ~ 3 の概況を確認できるように実装することもあります。
一般的にはこれらを複合的に使用し、複数の要因を調査して原因を特定できるようにすることが肝心です。
監視の流れ
アプリケーション障害発生時は外形監視をはじめとして、いくつかの監視ポイントでアラートを検出して、調査を開始するという流れです。
以下の図では、アプリケーションレイヤーで障害を検出した場合のアラートの例です。例えば、外形監視で障害に気付き、メトリクスとログを並行して調査して原因を特定するといった流れになると思います。
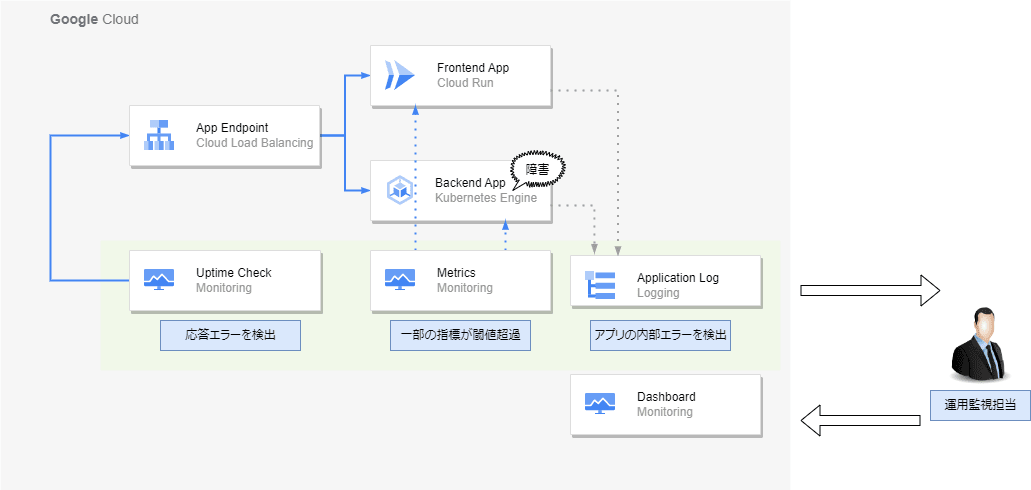
アプリケーション障害検出時
インフラストラクチャ障害の調査
一方、以下のようなユーザーが直接監視を設定出来ない箇所で障害が発生した場合、調査が困難になることがあります。
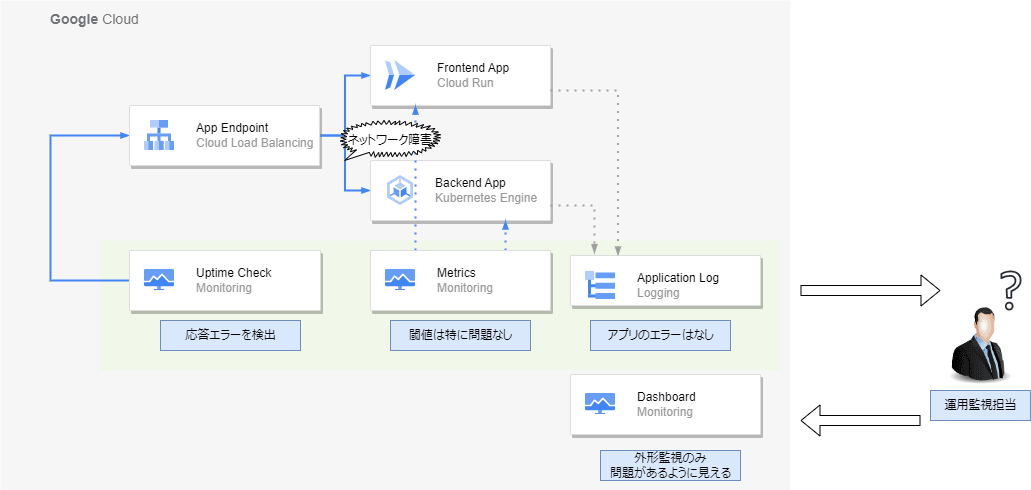
インフラストラクチャ障害時
このケースでは、外形監視では障害を検出していますが、一方でメトリクス監視やログ監視では特に目立った問題が発生していません。
インフラストラクチャの障害を疑うにも証拠が少なく、どのポイントを調査するかの目星を付けづらいことが多いです。
インフラストラクチャ障害の発生を知る方法
以前は Google Cloud のインフラストラクチャレイヤーの障害を知るには、下記のダッシュボードを確認する必要がありました。
Google Cloud Service Health ダッシュボード
ただ、このページを監視運用で使用するにはいくつかの問題がありました。
- Service Health ページは、全リージョンのあらゆるプロダクトの障害情報が掲載されており、自分が必要な情報をサッと確認しづらい
- Service Health の情報をプッシュ通知するためには、RSS フィードを購読する必要があるが、フィードは全リージョン・プロダクトが含まれているため、通知の大半は余計な情報となってしまう
- Service Health JSON 履歴ファイル(https://status.cloud.google.com/incidents.json)を定期的に参照し、自分が該当するリージョンやプロダクトの情報があれば通知するような自前のアプリを作成する
1.と 2.の方法だと余計な情報が多く、3.は手間が多いです。できれば、Cloud Monitoring 等と組みあせてアラートできるといいのにな、という状況でした。
Personalized Service Health は、こうしたユーザーが直接確認できない Google Cloud インフラストラクチャの障害情報を適切にフィルタし、必要な情報だけ取得・通知できるサービスです。Google Cloud Service Health ダッシュボードの代わりとして使用できます。

Personalized Service Health で検知するフロー
もちろん、インフラストラクチャの障害情報がアプリケーションのサービス提供に影響するかというと、必ずしもそう言えない部分はありますが、アプリケーションの動作に影響している要因を 1 つでも多く知ることは重要です。
Personalized Service Health の利用方法
Personalized Service Health の使用方法は簡単です。
- Service Health API を有効化する
- Cloud IAM で Personalized Service Health の参照権限(ロール)を付与する
Service Health API を有効化すると、それ以降に発生した Google Cloud のインフラストラクチャ障害が Cloud コンソールと Cloud Logging に記録されます。
Cloud コンソールの内容
ナビゲーションメニュー(左上の三本線ボタン)から、「ツール」カテゴリの「サービスの状態」をクリックすることで、Personalized Service Health のダッシュボード画面を開けます。
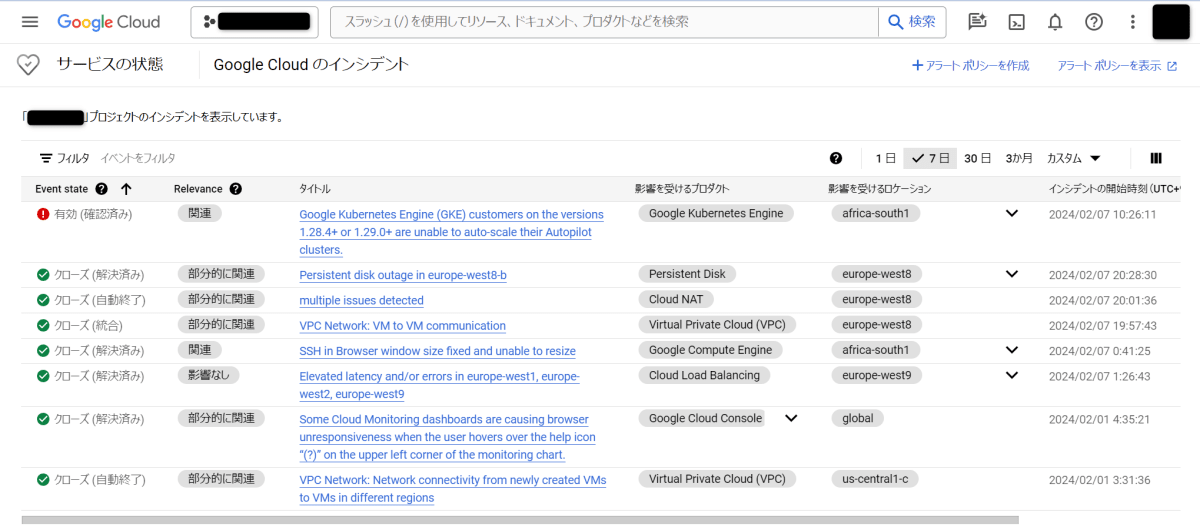
Personalized Service Health ダッシュボード 画面
デフォルトでは Personalized Service Health で収集する全リージョン・プロダクトの障害情報が表示されます。フィルタする場合、インシデント一覧の上部にあるフィルタに条件(フィルタしたい列とフィルタ内容)を記述する必要があります。
記事執筆時点では、フィルタ文字列がサジェストされず、指定する条件も英語版ドキュメントの「View Google Cloud incidents」を意識して設定する必要があるため、英語に不慣れな方にはやや使いづらいなという印象でした。
Personalized Service Health のアラートポリシー
Personalized Service Health で通知を行いたい場合は、Cloud Logging に記録されている障害情報のログベースアラートを設定します。
手っ取り早く設定したい場合は、Cloud コンソールの Personalized Service Health ダッシュボード画面右上にある「+アラートポリシーを作成」をクリックすることで、プリセットされた設定でアラートポリシーを作成可能です。
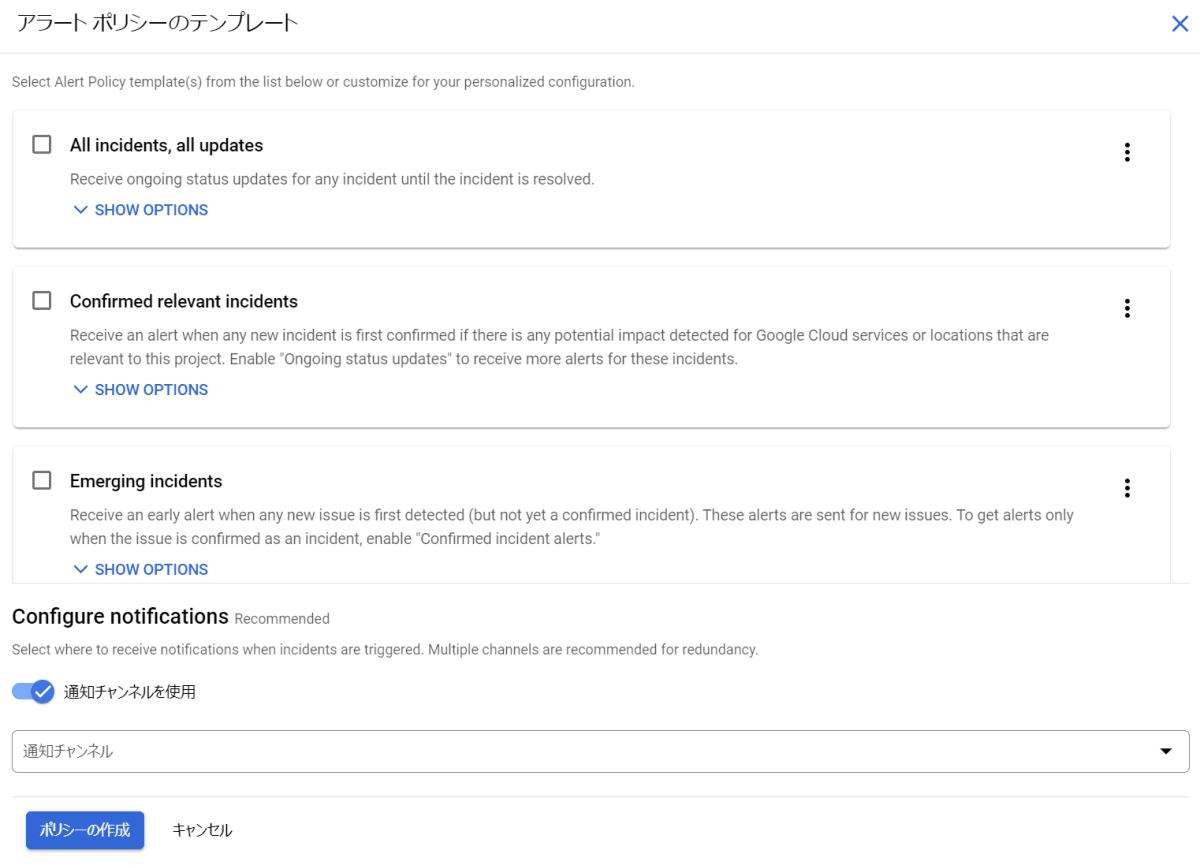
アラートポリシーのテンプレート
下記は、特定のロケーションにフィルタしてアラートポリシーを作成する場合の例です。
まず、アラートポリシーのテンプレート「Location alerts」の右上のボタンを押し、プルダウンメニュー「アラートポリシーをカスタマイズ」を押します。

ログベースアラートの作成画面 ①
ログベースアラートの作成画面が表示されます。Alert details は、アラート名、Severity、Document(アラート本文)を設定します。
アラート名は自分が監視したいロケーションに修正します。Severity と Document は任意で修正してください。Document 内のロケーションを示す文字列は変数を使用しているため、後述の条件を修正しても追従します。修正したら「次へ」を押します。

ログベースアラートの作成画面 ②
Choose logs to include in the alert に遷移します。この画面でフィルタの条件式を設定します。
「Define log entries to alert on」のテキストボックスで jsonPayload.impactedLocations の指定部分を自分が監視したいロケーションに修正しましょう。修正できたら「次へ」を押します。

ログベースアラートの作成画面 ③
通知間隔とインシデント自動クローズ時間の設定画面に遷移します。
特に理由がなければ、デフォルト値のままで問題無いと思います。

ログベースアラートの作成画面 ④
最後に、通知チャンネルの設定画面です。既に Cloud Monitoring で通知チャンネルを作成したことがある場合は、既存の設定が出てきます。
作成したことがない場合は、新規作成が必要です。ここでは細かい説明は省略しますので、詳しくは通知チャンネルの作成のドキュメントを確認してください。
この画面で「SAVE」ボタンを押すと、Personalized Service Health のアラートポリシーが作成されます。
ログベースアラートの作成画面 ⑤
Personalized Service Health のログ構成
Personalized Service Health の障害情報のログ形式は、下記ドキュメントに記載されています。
特に注目するべきログフィールドは以下の通りです。
| フィールド | 内容 |
|---|---|
| relevance | Personalized Service Health を有効化したプロジェクトや組織における関連性を示します。 IMPACTED や RELATED、 PARTIALLY_RELATED を指定することで、関連性のある障害だけフィルタすることが可能です。詳細はこちらを参照してください。 |
| impacted_products | 障害が影響するプロダクト名を示します。リファレンスページに指定可能なプロダクト名の一覧のドキュメントへのリンクがありますが、この記事を執筆している時点ではリンク切れになっていました。現在は正確なプロダクト名を知る手段がないかもしれません。 |
| impacted_locations | 障害が影響するロケーション(リージョン)を示します。このフィールドはリスト形式なので、ログベースアラートの条件に指定するときは正規表現形式を使ってしてするのがよいようです。なお、 global は、全リージョンへの影響ですが、 asia-northeast1 のような個別リージョンとは区別されているため、アラート条件を書くときは注意です。 |
料金
Personalized Service Health は無料でお使いいただくことができます。
ただし、Personalized Service Health は障害情報の履歴をプロジェクトの Cloud Logging に書き込むため、デフォルト設定では _Default バケットに記録され Logging 書き込み料金の対象になります。
まとめ
Google Cloud (に限らずパブリッククラウド全般)で確認が難しかった、インフラストラクチャの障害情報を取得できる Personalized Service Health について紹介しました。
これまでは工夫や運用負担が必要だった部分を Cloud Monitoring と連携して簡単に情報を取得・通知することができます。安定的なサービスには欠かせない設定となりそうだと思います。
この記事が誰かのお役に立てれば幸いです。
Discussion