Vertex AI の自然言語モデルを Cloud Spanner のテキストデータに適用してみる
こんにちは、クラウドエース データMLディビジョン所属の松山です。
データMLディビジョンでは、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。
新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
1. リリース概要
今回ご紹介するリリースは、2023 年 10 月 9 日付に発表されたCloud Spanner のリリースについてです。
本リリースによって、Vertex AI の自然言語モデル(「textembedding-gecko モデル」と「text-bison モデル」)を Cloud Spanner に保存されているテキストデータに対して適用できるようになりました。
適用の際、Spanner Vertex AI インテグレーションを有効化する必要があります。
1-1. Cloud Spannerとは?
Cloud Spanner とは、フルマネージドのリレーショナルデータベースサービスです。 最大99.999%の可用性、柔軟なスケーリング、強力な整合性・一貫性を持ち、大規模データのトランザクション処理を高速で実現できます。
-
Spanner Vertex AI インテグレーションとは?
GoogleSQL のインターフェースを介して Vertex AI にホストされているモデルにアクセスできるようにするものです。
1-2. VertexAIとは?
Vertex AI とは、フルマネージドの機械学習プラットフォームです。機械学習モデルの構築からデプロイまでを包括的に実施できます。
-
textembedding-geckoモデル とは?
テキストを高次元ベクトルに変換するモデルです。変換したベクトルを使って、テキスト分類やセマンティック検索などを行なうことができます。 -
text-bisonモデル とは?
様々な自然言語タスク(要約・分類・感情分析・質問回答・エンティティの抽出など)を実施できるモデルです。
1-3. Spanner Vertex AI インテグレーションのメリット
Spanner Vertex AI インテグレーションを使用した場合、Cloud Spanner のデータアクセスと Vertex AI のモデルアクセスが別々に実行される場合と比較して、以下 3 つのメリットがあります。
- パフォーマンス向上
-
レイテンシの改善
Spanner Vertex AI インテグレーションが Vertex AI と直接通信するため、Cloud Spanner のクライアントを実行しているコンピューティング ノードと Vertex AI 間の追加のラウンド トリップがなくなります。 -
スループットと並列性の向上
Cloud Spanner の高度な分散クエリ処理インフラストラクチャを使って、Vertex AI モデルを実行できます。
-
ユーザーエクスペリエンスの向上
データ変換や Vertex AI モデルを使った予測を、1 つの SQL インターフェースを使用して簡単に実現できます。 -
コスト削減
Cloud Spanner のコンピューティング容量を使用して、ML コンピューティングと SQL クエリ実行の結果をマージするため、追加のコンピューティング(Compute Engine や Google Kubernetes Engine など)をプロビジョニングする必要がありません。
2. 【検証 A】textembedding-gecko モデルを試してみる
2-1. 概要
検証 A の概要は、以下の 3 点にまとめることができます。
- 「textembedding-gecko モデル」を Cloud Spanner に登録する。
- Cloud Spanner に以下のテキストデータを保存する。
| id | text |
|---|---|
| 1 | リンゴ |
| 2 | Apple |
| 3 | 日本語の「リンゴ」は、英語では「Apple」です。 |
- Cloud Spanner に保存したテキストデータに対して「textembedding-gecko モデル」を適用する。テキストデータを高次元ベクトルに変換できることを確認する。
2-2. 手順
-
Cloud Spanner インスタンスの作成 or 既存インスタンスの選択
Google Cloud Console から Cloud Spanner のページを開き、検証用のインスタンスを作成する。または既存インスタンスを選択する。

-
データベースの作成 or 既存データベースの選択
検証用のデータベースを作成する。または既存データベースを選択する。

-
Spanner Vertex AI インテグレーションの有効化
作成したデータベースのページにある「有効にする」ボタンを押す。

-
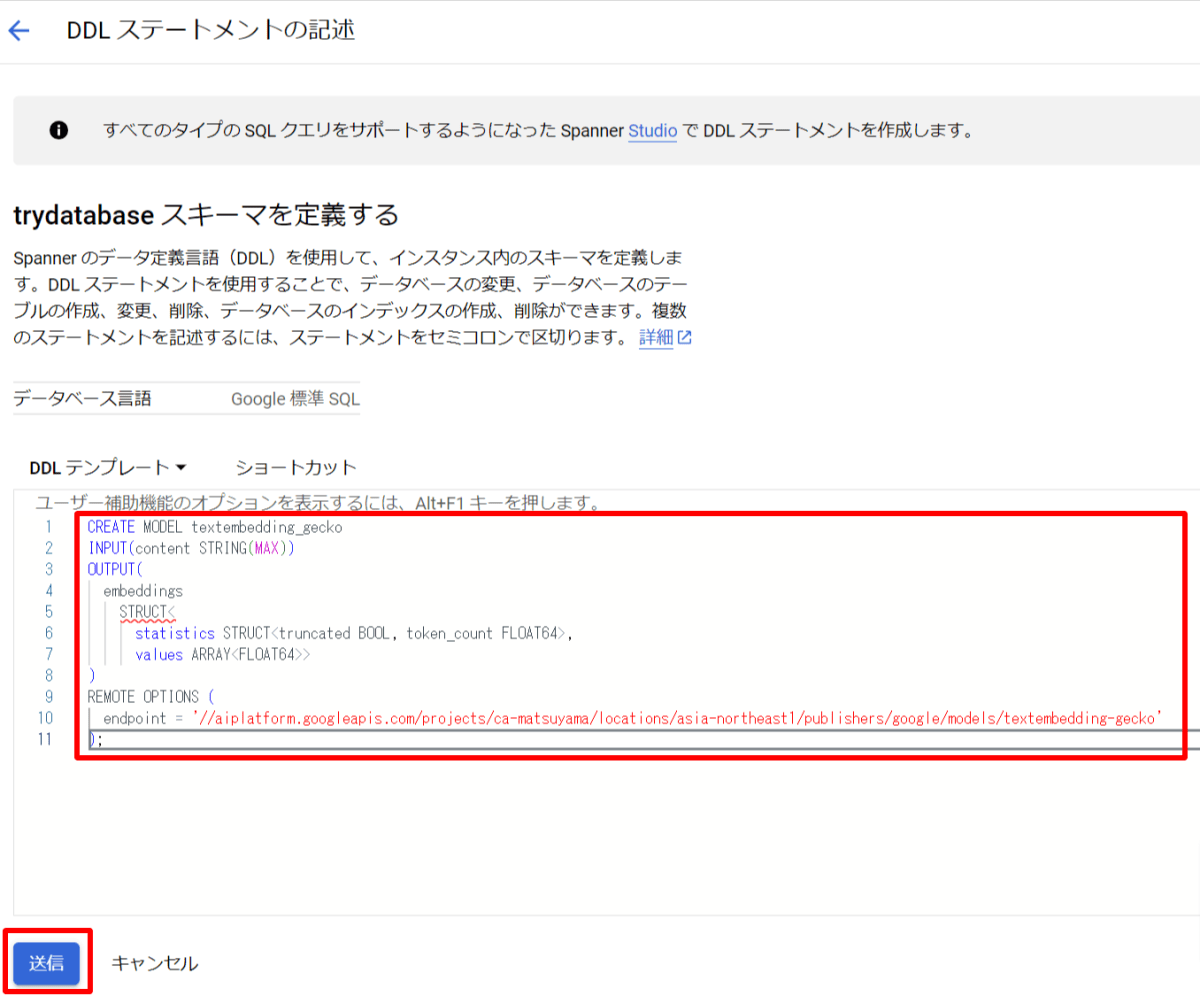
DDL ステートメントの記述
以下の DDL ステートメントを記述し、「送信」ボタンを押す。
CREATE MODEL ${MODEL_NAME}
INPUT(content STRING(MAX))
OUTPUT(
embeddings
STRUCT<
statistics STRUCT<truncated BOOL, token_count FLOAT64>,
values ARRAY<FLOAT64>>
)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/${PROJECT}/locations/${LOCATION}/publishers/google/models/textembedding-gecko'
);
- ${MODEL_NAME}: モデルの名前(任意)
- ${PROJECT}: Vertex AIエンドポイントをホストするプロジェクトID
- ${LOCATION}: Vertex AIエンドポイントの場所
-
モデルの登録を確認
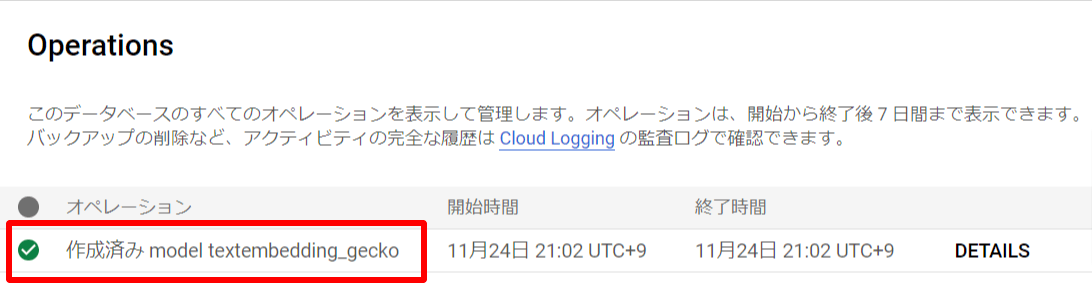
-
テーブルスキーマの登録
画面右上の鉛筆マークをクリックする。

以下のスキーマを記述し、「送信」ボタンを押す。
CREATE TABLE ${TABLE_NAME} (
id INT64 NOT NULL,
text STRING(255)
) PRIMARY KEY (id);
- ${TABLE_NAME}: テーブルの名前(任意)

-
テーブルスキーマの登録を確認

-
Spanner Studio を開く
画面左のナビゲーションペインから「Spanner Studio」を開く。

-
テキストデータの登録
以下のクエリを実行し、テキストデータをテーブルに追加する。
INSERT INTO ${TABLE_NAME} (id, text)
VALUES (1, 'リンゴ'), (2, 'Apple'), (3, '日本語の「リンゴ」は、英語では「Apple」です。');
- ${TABLE_NAME}: テーブルの名前(任意)

- モデルの適用
以下のクエリを実行する。
SELECT id, embeddings.values
FROM ML.PREDICT(
MODEL ${MODEL_NAME},
(SELECT id, text as content FROM ${TABLE_NAME})
);
- ${MODEL_NAME}: モデルの名前(任意)
- ${TABLE_NAME}: テーブルの名前(任意)
Text列のテキストデータをベクトル化できていることが分かります。

| id | text |
|---|---|
| 1 | -0.0026604468002915382,0.02634146623313427,-0.003313597524538636,0.003234213450923562,0.018140884116292,-0.051342710852622986,0.032363928854465485,・・・ |
| 2 | -0.002589644631370902,-0.030254140496253967,-0.005284039303660393,0.033260196447372437,-0.003124704584479332,-0.07534682005643845,0.04191019386053085,・・・ |
| 3 | -0.0027795331552624702,0.0013411781983450055,0.004375485237687826,0.03498736396431923,0.022517427802085876,-0.07539568096399307,0.04857306927442551,・・・ |
3. 【検証 B】text-bisonモデルを試してみる
3-1. 概要
検証 B の概要は、以下の 3 点にまとめることができます。
- 「text-bison モデル」をCloud Spannerに登録する。
- Cloud Spanner に以下のテキストデータを保存する。
| id | text |
|---|---|
| 1 | おはようございます。いいお天気ですね。 |
| 2 | 早起きのコツを端的に3つ教えてください。 |
| 3 | 日記を作成してください。 |
- Cloud Spanner に保存したテキストデータに対して「text-bison モデル」を適用する。id=1 のテキストに対しては会話、id=2 のテキストに対しては質問回答、id=3 のテキストに対しては文章作成が実施できることを確認する。
3-2. 手順
手順 1~3 は検証 A と同一です。
-
Cloud Spanner インスタンスの作成 or 既存インスタンスの選択
Google Cloud ConsoleからSpannerのページを開き、検証用のインスタンスを作成する。または既存インスタンスを選択する。
-
データベースの作成 or 既存データベースの選択
検証用のデータベースを作成する。または既存データベースを選択する。
-
Spanner Vertex AI インテグレーションの有効化
作成したデータベースのページにある「有効にする」ボタンを押す。
-
DDL ステートメントの記述
以下の DDL ステートメントを記述し、「送信」ボタンを押す。
CREATE MODEL ${MODEL_NAME}
INPUT(prompt STRING(MAX))
OUTPUT(
content STRING(MAX),
citationMetadata STRUCT<
citations ARRAY<STRUCT<
startIndex INT64,
endIndex INT64,
url STRING(MAX),
title STRING(MAX),
license STRING(MAX),
publicationDate STRING(MAX)
>>
>,
safetyAttributes STRUCT<
scores ARRAY<FLOAT64>,
categories ARRAY<STRING(MAX)>,
blocked BOOL
>
)
REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/${PROJECT}/locations/${LOCATION}/publishers/google/models/text-bison'
);
- ${MODEL_NAME}: モデルの名前(任意)
- ${PROJECT}:Vertex AIエンドポイントをホストするプロジェクトID
- ${LOCATION}:Vertex AIエンドポイントの場所

-
モデルの登録を確認

-
テーブルスキーマの登録
画面右上の鉛筆マークをクリックする。
以下のスキーマを記述し、「送信」ボタンを押す。
CREATE TABLE ${TABLE_NAME} (
id INT64 NOT NULL,
text STRING(255)
) PRIMARY KEY (id);
- ${TABLE_NAME}: テーブルの名前(任意)

-
テーブルスキーマの登録を確認

-
Spanner Studio を開く
画面左のナビゲーションペインから「Spanner Studio」を開く。
-
テキストデータの登録
以下のクエリを実行し、テキストデータをテーブルに追加する。
INSERT INTO ${TABLE_NAME} (id, text)
VALUES (1, 'おはようございます。いいお天気ですね。'), (2, '早起きのコツを端的に3つ教えてください。'), (3, '日記を作成してください。');
- ${TABLE_NAME}: テーブルの名前(任意)

- モデルの適用
以下のクエリを実行する。
SELECT prompt, content
FROM ML.PREDICT(
MODEL ${MODEL_NAME},
(SELECT text as prompt FROM ${TABLE_NAME} WHERE id=1), STRUCT(250 AS maxOutputTokens)
);
- ${MODEL_NAME}: モデルの名前(任意)
- ${TABLE_NAME}: テーブルの名前(任意)

以下のように会話できていることが分かります。
| prompt | content |
|---|---|
| おはようございます。いいお天気ですね。 | おはようございます。いいお天気ですね。今日は20度くらいまで気温が上がるそうです。日差しが強いですから、日焼け止めを塗って、水分を十分に摂るようにしてください。 |
SELECT prompt, content
FROM ML.PREDICT(
MODEL ${MODEL_NAME},
(SELECT text as prompt FROM ${TABLE_NAME} WHERE id=2), STRUCT(250 AS maxOutputTokens)
);
- ${MODEL_NAME}: モデルの名前(任意)
- ${TABLE_NAME}: テーブルの名前(任意)

以下のように質問に回答できていることが分かります。
| prompt | content |
|---|---|
| 早起きのコツを端的に3つ教えてください。 | 1. 十分な睡眠をとる。 これは、早起きするための最も重要なコツです。十分な睡眠をとっていないと、朝起きるのが難しく、一日中疲れを感じてしまいます。ほとんどの大人は、一晩に7~8時間の睡眠を必要としています。2. 就寝前にリラックスする。 就寝前の数時間は、リラックスしてストレスを解消するのに費やしましょう。これは、読書、入浴、落ち着いた音楽を聴くなど、好きなことをして過ごすことを意味します。就寝前にテレビを見たり、電子機器を使ったりするのは避けましょう。これらの機器から発せられる青い光は、睡眠を妨げる可能性があります。3. 目覚まし時計を手の届かないところに置く。 これは、スヌーズボタンを押して二度寝するのを防ぐのに役立ちます。目覚まし時計が手の届かないところに置いてあれば、起き上がって止める必要があります。これは、一日を始めるのに役立ちます。 |
SELECT prompt, content
FROM ML.PREDICT(
MODEL ${MODEL_NAME},
(SELECT text as prompt FROM ${TABLE_NAME} WHERE id=3), STRUCT(250 AS maxOutputTokens)
);
- ${MODEL_NAME}: モデルの名前(任意)
- ${TABLE_NAME}: テーブルの名前(任意)

以下のように文章を作成できていることが分かります。
| prompt | content |
|---|---|
| 日記を作成してください。 | 2023年3月8日 火曜日 今日は、朝起きてからずっと、日記を書くことを考えていました。日記を書くのは久しぶりです。最後に日記を書いたのは、いつだったか思い出せません。でも、日記を書くことは、私にとって大切なことだと思っています。日記を書くことで、自分の考えや感情を整理することができます。また、日記を読み返すことで、自分の成長を振り返ることができます。今日は、最近あった出来事について書きたいと思います。先週、私は新しい仕事に就きました。新しい仕事は、とてもやりがいのある仕事です。でも、同時に、とてもプレッシャーのかかる仕事でもあります。私は、この新しい仕事で成功したいと思っています。でも、同時に、失敗するのではないかと不安に思っています。私は、この新しい仕事で成功するために、毎日努力しています。毎日、新しいことを学び、新しいことに挑戦しています。また、毎日、自分の仕事に責任を持とうとしています。・・・ |
まとめ
本ページでは、Vertex AI の自然言語モデル(「textembedding-gecko モデル」と「text-bison モデル」)を Cloud Spanner のテキストデータに適用する検証を行ないました。
今後、Cloud Spanner と Vertex AI の統合が進むにつれて、適用できるモデルが更に増えていくことが期待できます。今後の発展を楽しみに見守りましょう。
Discussion