[検証] BigQueryテーブルに対して、data profilingとAutoDQのそれぞれのスキャンを使ってみた
こんにちは、クラウドエース データML ディビジョン所属のZUMA SEAです。
クラウドエースのITエンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータML ディビジョンです。
データML ディビジョンでは活動の一環として、毎週Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。
その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回紹介するリリースは、「BigQueryのテーブルに対して、DataplexのAutoDQスキャンとdata profilingスキャンが利用可能になったこと」についてです。
このリリースによって、今まではサポートされていなかったBigQueryのテーブルを対象としたデータの品質問題を自動で検知できるようになりました。
本記事の目的
本記事では、BigLakeを介さず、直接BigQueryテーブルに対して、data profilingスキャンとAutoDQスキャンができるようになったので、機能紹介と次の検証をして見たいと思います。
- data profilingスキャンによるBigQueryテーブルの統計情報を取得してみる
- AutoDQスキャンによるBigQueryテーブルのデータ品質を管理してみる
リリース内容
プレビュー
- Dataplex auto data quality (AutoDQ)スキャン と data profilingスキャン が任意の BigQuery テーブル (Dataplex レイクの一部でないテーブルも含む) に対して利用可能になった。したがって、Dataplex AutoDQスキャンやdata profilingスキャンを実行するために、Dataplexレイクを作成する必要がなくなった。
- Dataplex AutoDQスキャンとdata profilingスキャンは、BigQueryのビュー、BigLakeテーブル、BigQueryの外部テーブルに対してもサポートするようになった。
- 時間とコストの節約のため、全データだけではなく、サンプリングされたデータでもDataplex AutoDQスキャンとdata profilingスキャンを実行できるようになった。
data profilingの概要
Dataplex の「data profiling」を使うことで、BigQueryテーブルの列に関する統計情報を可視化できます。
統計情報を可視化するために「data profiling スキャン」を実行します。
具体的には、「data profilingスキャン」で、次の統計情報を取得できます。
数値列
- null値の割合
- 一意の値の割合
- 最頻値上位10個の値
- 統計的な指標
- 平均
- 標準偏差
- 最小値
- 近似下位四分位
- 近似中央値
- 近似上位四分位
- 最大値
文字列
- null値の割合
- 一意の値の割合
- 最頻値上位10個の値
- 文字列の長さをもとにした次の値
- 平均値
- 最小値
- 最大値
JSONなどのようなネストされたデータ型、または複雑なデータ型
- null値の割合
ネストされていないその他のデータ列(日付、時刻、タイムスタンプ、バイナリ、等)
- null値の割合
- 一意の値の割合
- 最頻値上位10個の値
data profilingスキャンの制限事項
- data profilingスキャンの結果はData Catalogに公開できません。
- BIGNUMERIC列を含むテーブルのスキャンは対応していません。
- プロジェクトごとに1日あたりスキャンするデータは5TBが上限です。
- スキャンする BigQuery テーブルは300列以下にする必要があります。
- スキャンする BigQuery テーブルは100行以上にする必要があります。
data profilingスキャンのスケジュールについて
オンデマンドと繰り返しの2パターンのスケジュールを設定することができます。
- オンデマンド
- スキャンしたいタイミングで実行できる
- 繰り返し
- スキャンを次のスケジュール実行できる
- 毎日
- 毎週
- 毎月
- カスタム
- スキャンを次のスケジュール実行できる
data profilingスキャンの料金について
2023年6月16日まで無料でしたが、2023年7月6日時点では、すでにdata profilingスキャンに対する課金が開始されています。
data profilingスキャンはDataplex プレミアム処理 SKU として課金されます(最小1分として秒単位で課金)。
料金は、1時間の処理につき$0.089000 かかります。
その他、料金の制限については公式ドキュメントをご覧ください。
AutoDQの概要
データ品質ルールに基づいて、データ品質の監視を自動的にしてくれる機能です。
データソースからのデータを定期的に監視し、欠損値などのデータ品質に関する問題を検出することが可能です。
検出するためには「AutoDQスキャン」を実行します。
ここで「データ品質」とは、データがその目的に適しているかどうかの評価値です。
また、「データ品質ルール」とは、評価値を求めるためにディメンションにより定義されたルールです。
なお、ディメンションの詳細については後述します。
設定可能なルール
ユーザーが独自のデータ品質ルールを定義することも可能です。基本的には次の3つの方法でルールを作成できます。
- data profilingルールの推奨事項
- data profilingスキャンで可視化された統計情報をルールとして使うことができる
- 事前定義ルール
- 行レベル
- 各行に対して、個別にルールを適用することができる
- 集計ルール
- データ全体に集計関数を用いて、集計された1つの値に適用できる。
- テーブル全体にのみ適用可能である。つまり、行ごとに個別でルールを適用することはできない。
- 行レベル
- カスタムSQLルール
- 記述したSQLをルールとして適用できる
- 行レベルまたは集計ルールで適用できる
次のドキュメントにAutoDQのサンプルルールがあるので参考にしてください。
AutoDQスキャンに設定可能なディメンション
ディメンションとは、データ品質を評価、分析、測定するための指標です。
AutoDQスキャンでは、次のディメンションがサポートされています。
- 鮮度
- ボリューム
- 完全性
- 有効性
- 一貫性
- 精度
- 一意性
AutoDQスキャンのモニタリングとアラートについて
モニタリングとアラートにも対応しています。スキャンが成功した場合は、次の詳細情報が保持されます。
- スキャン実行の詳細
- スキャン実行に使用されるルールの詳細
- ルールレベルの成功または失敗
- ディメンションの成功または失敗
これらの情報は、APIとGoogle Cloudコンソールから利用できます。
AutoDQスキャンのスケジュールについて
オンデマンドと繰り返しの2パターンを設定することができます。
- オンデマンド
- スキャンしたいタイミングで実行するときに設定する
- 繰り返し
- スキャンをスケジュール実行したいときに設定する
- 設定できるスケジュール
- 毎日
- 毎週
- 毎月
- カスタム
AutoDQスキャンの料金について
2023年6月16日まで無料でしたが、2023年7月6日時点では、すでにAutoDQスキャンに対する課金が開始されています。
AutoDQスキャンはDataplex プレミアム処理 SKU として課金されます(最小1分として秒単位で課金)。
料金は、1時間の処理につき$0.089000 かかります。
その他、料金の制限については公式ドキュメントをご覧ください。
AutoDQスキャンの制限事項
- AutoDQスキャンの結果はData Catalogに公開できません。
- ルールの推奨事項は、GoogleCloudコンソールでのみサポートされています。
- スキャンする BigQuery テーブルは300列以下である必要があります。
- ディメンションの選択は、事前定義された7つのディメンション以外選択できません。
- 1スキャンあたりのルール数は1000に制限されています。
検証
今回の検証は次の2つを行います。
- [Part1]data profilingスキャンによるBigQueryテーブルの統計情報を取得してみる
- [Part2]AutoDQスキャンによるBigQueryテーブルのデータ品質を管理してみる
[Part1]data profilingスキャンによるBigQueryテーブルの統計情報の取得をしてみる
ここからは、実際にdata profilingでプロファイルを作成し、BigQueryテーブルに対してスキャンを行います。
その後、テーブル全体のカラムに対して統計情報を取得してみたいと思います。
今回、使用するデータはGoogle Cloudの公開データセットである「MLB 2016 Pitch-by-Pitch」です。
手順1:Cloud Dataplex APIの有効化
Cloud Dataplex APIを有効にします。
手順2:「プロファイル」を選択
Google Cloudコンソールのメニューから「プロファイル」を選択します。
手順3:data profilingスキャン構成を作成
下図のパラメータを設定をして、data profilingスキャンの構成を作成します。

サンプリングサイズはデータ全体から一部をランダムに抽出したデータ量を指しています。
次の項目から選択できます。
- すべてのデータ
- 1%
- 5%
- 10%
- 15%
- 20%
- カスタム
今回はスキャンにかかる費用の兼ね合いでサンプリングサイズを10%としています。
サンプリングサイズが大きいほど、正確な分析ができます。
手順4:data profilingスキャン結果の確認
対象テーブルはINTEGER,STRING,TIMESTAMPが含まれていたので、それぞれのスクリーンショットを添付しています。
記事前半の「data profilingの機能について」で記載した統計情報を取得できました。
各カラムの統計データがグラフで表示されているので一目でわかり、感動しました!
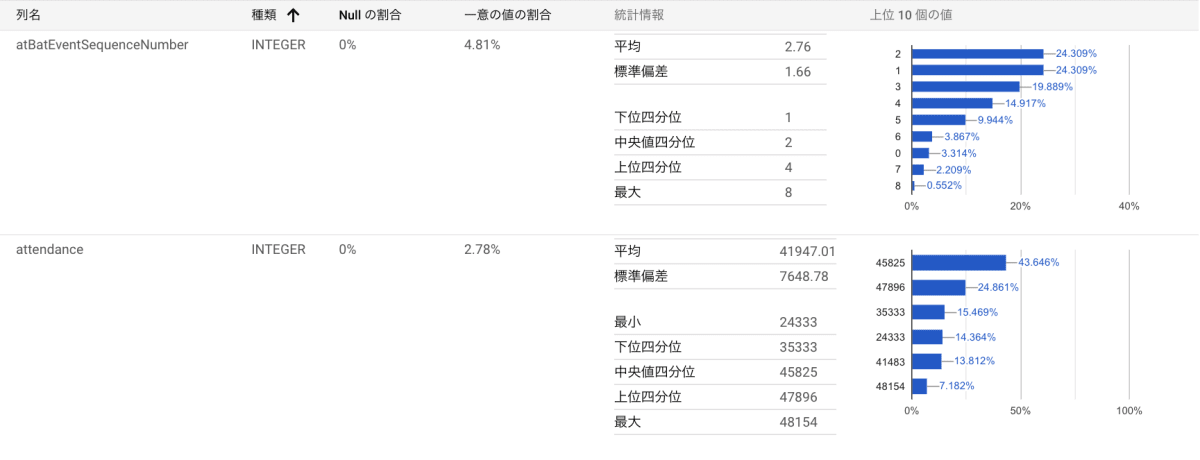

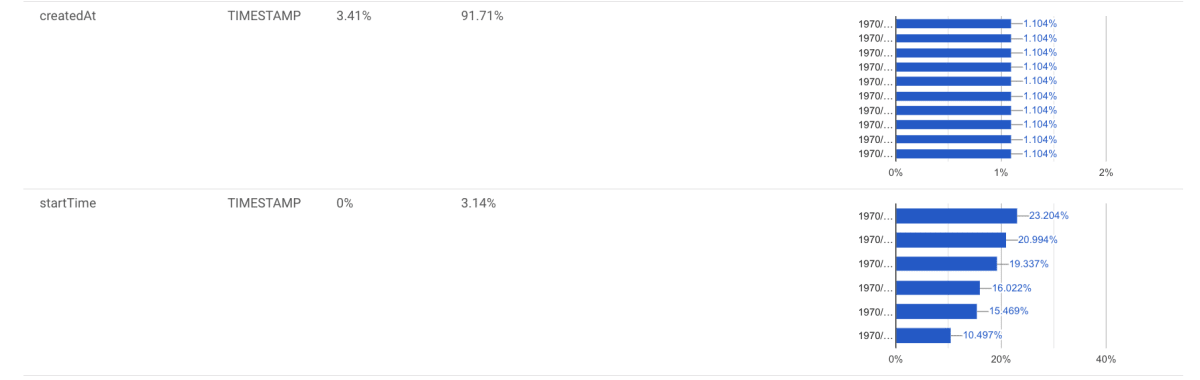
[Part2] AutoDQスキャンによるデータ品質を管理をしてみる
次は、AutoDQスキャンを検証します。
使用するデータはGoogle Cloudの公開データセットである「MLB 2016 Pitch-by-Pitch」です。
手順1:Cloud Dataplex APIの有効化
Cloud Dataplex APIを有効にする。
手順2:データ品質スキャンを作成
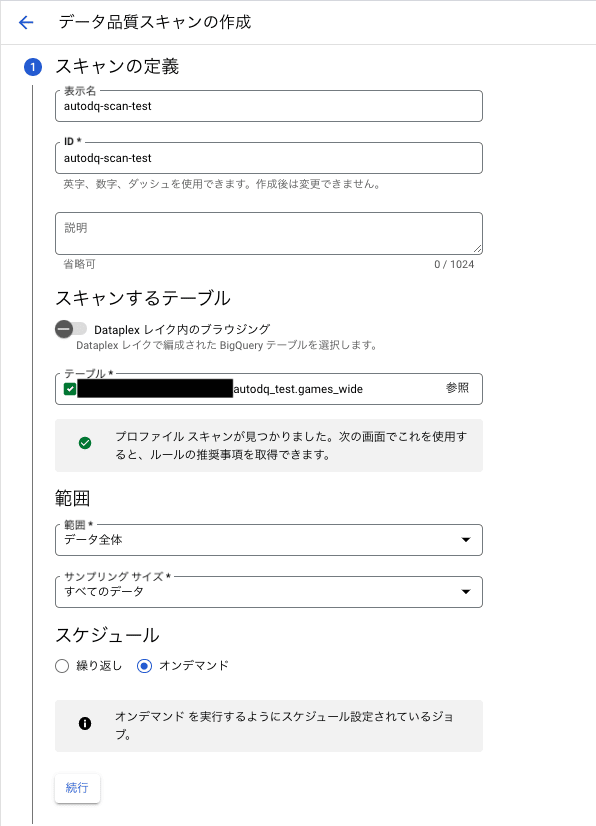
2.1 スキャン定義を設定
本検証では、下図のスキャン定義にしました。
2.2 品質ルールを定義
今回は、「data profilingルールの推奨事項」を選択して、スキャンを行ってみます。
対象のカラムは、「atBatEventType」カラムで、野球の打席でのイベント(「ヒット」、「ホームラン」、「四球」、「三振」など)の種類を示しています。
今回は「atBatEventType」カラムに対して次の3つのルールを設定しました。
- Null Check
- Value Set Check
- Row Condition Check

結果は、下図のエラーが出たので作成できませんでした。

エラー内容は、「しきい値が0.0から1.0の範囲内である必要がある」というものでした。
しきい値を見てみたところ、atBatEventType列の「Value Set Check」のしきい値が104%でした。
なので、しきい値を100%未満もしくは「Value Set Check」のルールを除外する必要がありました。
今回は、ルールからatBatEventType列の「Value Set Check」を外しました。
気を取り直し、次のルールを適用して実際にスキャンを実行していきます。
[ルール1] データセット全体のyearカラムに対して、フィールドのNULLチェック、しきい値を5%に設定してスキャンを行ってみる。
- 「year」カラムに含まれるNULLが5%以上存在した場合に失敗し、NULLが5%未満であれば成功します。
[ルール2] データセット全体の「description」カラムに対して、フィールドのNULLチェック、しきい値を100%に設定してスキャンを行ってみる。
- 「description」カラムに含まれるNULLが1つでも存在した場合に失敗し、NULLが1つも存在しなければ成功します。
AutoDQスキャン結果の確認
スキャン結果は、
- 「year」カラムは、NULLが0%だったのでステータスが成功
- 「description」カラムは、4.8%のNULLが存在したのでステータスが失敗
となっていました。

まとめ
今回は、BigQueryテーブルに対して、data profilingスキャンとAutoDQスキャンを試してみました。
どちらのスキャンもGoogle Cloudコンソール上でサクッと設定できました。
さらに、Google Cloud コンソール上でBigQueryテーブルに存在する各カラムについての統計データが可視化され、データ分析にとても役立つと感じました。
本リリースの最大のメリットとしては、AutoDQスキャンやdata profilingスキャンを実行するために、Dataplex レイクを作成せず、直接BigQueryテーブルの分析ができることだと思います。
既存環境に対しても導入しやすいと思うので、試してみてはいかがでしょうか。
最後まで読んでいただきありがとうございました。
参考
Discussion