trocco®でお手軽ETLワークフロー管理
クラウドエースData/MLディビジョン所属のODRです。
今回は、データ分析基盤構築・運用の支援 SaaS である trocco® のワークフロー機能を使用して、GUIでワークフローを作成してみたので、手順と感想をまとめました。
最後に、Google Cloud のワークフロー管理ツールとの比較も行いました。
trocco とは
trocco®は、ELT/データ転送・データマート生成・ジョブ管理・データガバナンスなどの
データエンジニアリング領域をカバーした、分析基盤構築・運用の支援SaaSです。
今回は、ワークフロー(ジョブ管理)機能を使用して、ETL/ELTジョブのワークフローを構築してみました。
ワークフローとは
データエンジニアリングにおけるワークフローとは、複数のETL/ELTジョブの依存関係を定義したり、ジョブを決められた時間に起動して、実行状況を監視し、必要に応じてリトライを行う処理全般のことを指します。
trocco®のワークフロー機能では、以下のようなことができます。
- 指定のジョブが実行された後に、別のジョブを実行
- 複数のジョブを並列で実行
- ジョブのスケジュール実行
- ジョブの失敗時のリトライ
- ジョブ完了時の通知
ワークフロー(ジョブ管理)機能を使ってみた
今回の検証で構築するワークフローは、以下の2つのジョブからなります。
- Cloud Storage から BigQuery へのCSVファイルの転送ジョブ
- BigQuery での データマート生成ジョブ
そして、この2つのジョブが成功したら、通知機能を利用してSlackに通知してみます。

事前準備
ワークフロー機能の使用に必要な準備をします。
① Cloud Storage にファイルを配置
まずは、Cloud Storage にワークフローのソースとなるCSVファイルを配置します。
任意の名前でCloud Storage バケットを作成し、trocco-testで始まる名前のCSVファイルを配置します。

CSVファイルの中身は以下の通りで、id・name・ageからなるユーザーデータです。

② BigQueryテーブルの作成
次に、Cloud Storage のCSVファイルを書き込むBigQueryテーブルと、データマート生成ジョブで書き込むBigQueryテーブルを作成します。
2テーブルとも、Cloud Storage に配置したCSVファイルと同じカラムを持ったスキーマです。

③ ジョブの作成
次に、ワークフローを構成する以下2つのジョブを作成します。
- Cloud Storage から BigQuery へのCSVファイルの転送ジョブ
- BigQuery での データマート生成ジョブ
今回のメインは、ワークフロー管理であるため、詳しいジョブの作成方法は省略します。
Cloud Storage から BigQuery へのCSVファイルの転送ジョブは、ETL/データ転送機能を使用して、CSVファイルをそのままBigQueryにロードします。
BigQuery から BigQuery への データマート生成ジョブは、データマート生成 (ELT)機能を使用して、SQLでユーザーをフィルタしたテーブルを作成します。

④Slackの通知設定
ワークフローの実行結果を通知するSlackの設定を行います。
SlackでWebhook URLを発行する方法を参考に、通知先のSlackチャンネルのwebhook URLを発行しておきます。
これで、事前準備は完了です。
ワークフローの作成
それでは、ワークフローを作成していきます。
trocco®にログインして、ワークフロー定義の「新規追加」をクリックします。

任意のワークフロー名を入力します。
ジョブ実行設定を入力します。

各種設定は、以下の表の通りです。
リトライ・エラーハンドリングなど、ワークフローで欲しい機能が一通り揃っています。
詳細は、ワークフロー定義をご参照ください。
| 設定名 | 設定概要 |
|---|---|
| タスク同時実行上限数 | ワークフロー内で設定する並列のタスクを同時実行する上限数を設定します |
| タイムアウト設定 | 有効にした場合、ワークフロージョブが開始してから設定した時間が経過すると、ジョブをキャンセルします |
| リトライ回数 | ワークフローが失敗したときに、自動リトライを行う回数、および次回リトライ実行までの時間間隔を設定します |
| ジョブの重複実行 | ジョブが、次のスケジュールの時間になってもまだ実行中の場合、次のスケジュールをスキップするか重複実行するかを選択します |
| タスクのエラーハンドリング | 前のタスクが失敗したとき、以降のタスクを実行するかどうかを選択します |
設定後、保存します。
ワークフローの編集をしていきます。

「trocco転送ジョブ」から、作成したCloud Storage から BigQuery へのCSVファイルの転送ジョブを追加します。
「troccoデータマートシンク」から、作成したBigQuery から BigQuery への データマート生成ジョブを追加します。
「Slack通知」から作成した通知先を追加します。
そして、それぞれのジョブを繋げて保存するだけでワークフローの完成です。
このように、簡単にワークフローを構築することができました。
ワークフロー実行
では、作成したワークフローを実行してみます。
「実行」をクリックします。

成功しました。

実際に、BigQueryテーブルが作成されたか確認してみます。
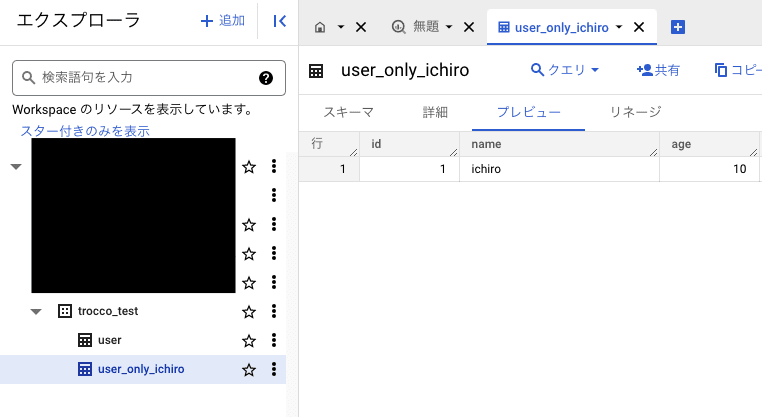
転送ジョブによって、userテーブルが作成されています。

データマート生成ジョブによって、ユーザーがフィルタされたuser_only_ichiroテーブルが作成されています。
slackを確認すると、ワークフローが実行完了したという通知が届いています。
今回は、ワークフローの最後にSlackへ通知する構成にしましたが、ジョブ単位で通知を構成することも可能です。(参考:通知設定を作成する)
定期的に実行されるワークフローの結果を毎回確認するのは大変なので、Slackに自動で通知されるのはありがたいですよね。

以上のように、trocco®のワークフロー機能で、簡単にワークフローを作成することができました。
今回は、シンプルなワークフロー構成にしましたが、trocco®のワークフロー機能には、dbtジョブ連携・SQLベースのBigQueryデータチェック機能など、便利な機能も備わっています。
Google Cloud のワークフロー管理サービスとの比較
Google Cloud のワークフロー管理が可能なサービスであるComposer、Workflows、DataFusionと比較をしてみます。
| Composer | Workflows | DataFusion | trocco | |
|---|---|---|---|---|
| 構文 | Python | YAML or JSON | GUI | GUI |
| 実装難易度 | 高 | 中 | 低 | 低 |
| 基礎とするOSSなど | Kubernetes上で、Airflowが動く | なし(非公開) | Dataproc(Hadoopのマネージドサービス)上で、CDAPが動く | Kubernets上で、Embulkが動く |
| 料金体系 | 常時課金 | 従量課金 | 常時課金 | 3つの定額プラン |
| 実装で困った時のサポート | 高 使用実績が豊富で、多くの解説記事が存在 |
低 使用実績・解説記事ともに少ない |
低 使用実績・解説記事ともに少ない |
高 専任のカスタマーサクセスがサポート(有償プラン) |
DataFusion・trocco® はGUIでのワークフロー作成が可能なため、プログラムで作成するComposer・Workflows に比べて、実装難易度が低いです。
Google Cloudで一番 trocco® に近いサービスは、DataFusionになります。
trocco®は、3つの定額プランがあるため、常時課金のDataFusionと比べて料金が安くなる可能性があります。
また、専任のカスタマーサクセスチームからのサポート(有償プランに付帯)もあるため、実装までの困りどころの解消を行うことでクイックな実装を実現しやすいと言えます。
まとめ
今回は、trocco® のワークフロー機能を使用して、GUIで簡単にワークフローを作成することができました。
リトライやエラー処理などワークフローに必須の機能はもちろん、dbtジョブ連携・SQLベースのBigQueryデータチェック機能など、便利な機能も備わっており、GUIにもかかわらず高機能なワークフローが作成できます。
trocco®は、Google Cloud のワークフロー管理サービスではカバーできていない需要をカバーできており、Google Cloud メインでデータ分析基盤を構築するときの良い選択肢になると思います。
Discussion