BigQuery ML で階層型時系列予測を行う
はじめに
こんにちは、クラウドエース データソリューション部所属の濱です。
データソリューション部では、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。
新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
クラウドエース データソリューション部 について
クラウドエースの IT エンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
今回紹介するリリースは、2024年3月22日にリリースされた「BigQuery ML 時系列モデルで、モデル内のすべての時系列値を集計してロールアップする階層型時系列予測(hierarchical forecasts)を実行できるようになった」というものです。該当リリースは こちら からご覧ください。
階層構造って何?
階層構造とは、weblio 辞書 ではデータ構造の一種で、ある階層に属する一つのデータから、下位階層に位置する複数のデータが枝分かれした状態で配置されている構造のことと定義されています。
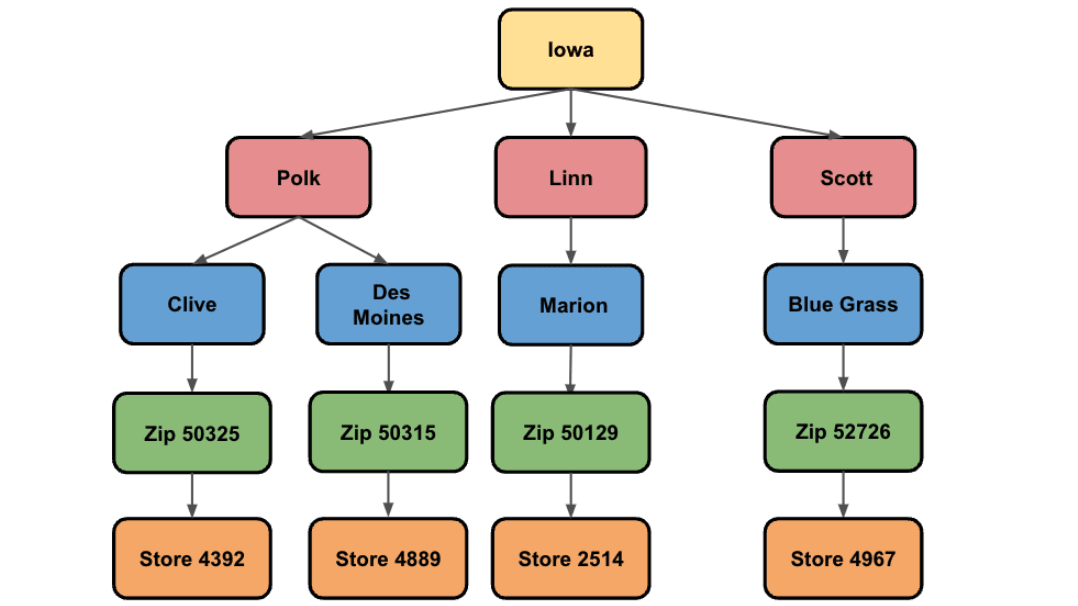
以下の図は、公式ドキュメントで紹介されているものです。
特徴
階層構造データの特徴は以下の3点です。
- 親子関係を持つ
- 複数のレベルに分かれており、上層レベルは一般的な情報、下層レベルは詳細な情報を持つ
- 上層レベルは下層レベルを集約したもの、下層レベルは上層レベルを分解したもの
階層構造の例
簡単な階層構造の例を以下に示します。
- 地理
国 > 都道府県 > 市区 > 町村 - 組織
会社 > 部門 > チーム > 個人 - ファイルシステム
ドライブ > フォルダ > サブフォルダ > ファイル
階層型時系列予測とは
階層型時系列予測とは、前章で示した階層構造データの特徴を活用して予測を行う手法です。その特徴を上手に利用することで、通常の時系列予測より詳細な分析が可能となります。
階層型時系列予測のメリット
階層型時系列予測を行うことのメリットは以下の4点です。
-
予測の一貫性の向上
階層型時系列予測では、データの階層を意識した予測を行うため、階層の異なるレベル間での予測結果は一貫性を持ちます。例えば、市区町村レベルの売上予測と都道府県レベルの売上予測があるとするなら、任意の都道府県の売上予測は、所属する市区町村の売上予測の合計値となります。 -
精度の向上
上位レベルと下位レベルの情報を集約して予測を行うため、単一のレベルで予測を行うよりも精度が向上することがあります。 -
柔軟性の向上
階層構造を持つデータに対して柔軟に対応できるため、異なるレベルのデータを集約して予測を行うことが可能です。例えば、国全体の売上予測から個々の店舗の売上予測まで、さまざまなレベルでの予測を一度に見ることが可能です。 -
計算効率の向上
大規模な時系列データに対して階層型時系列予測を行うとき、ボトムアップ(階層の最下位レベルのデータから予測を行い、その結果を集計して上位レベルに反映)やトップダウン(階層の最上位レベルのデータから予測を行い、その結果を集計して下位レベルに分配)といった手法を用いることで、計算リソースを節約しながら予測することができます。
実際に試してみる
ここから、今回利用可能になった階層型時系列予測を試してみます。
概要
本検証では、従来の時系列予測と、本リリースで利用可能になった階層型時系列予測の結果を比較していきます。
使用するデータは、パブリックデータとして公開されている アイオワ州(Iowa)のお酒の販売データ です。予測対象は、2015年にPolk、Linn、Scott地域で販売されたボトルの1日当たりの合計数 とします。
手順
今回は以下の手順で検証を行います。
- 前準備
- 学習に使用するデータを確認する
- 時系列モデルを作成して予測結果を見る
- 階層型時系列モデルを作成して予測結果を見る
- 3 と 4 を比較し、どのような違いがあるか見る
Google Cloud 公式ドキュメントのチュートリアルに沿って検証を行うため、不明点などがあれば都度、こちら を参考にして作業を進めてください。
前準備
ここから、試すにあたって必要な前準備について説明します。大きく分けて以下の2つの作業を行います。
- 必要な IAM 権限を持っているか確認する
- データセットを作成する
必要な IAM 権限を持っているか確認する
bigquery.datasets.createbigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.createbigquery.connections.getbigquery.connections.delegate
ロールで確認したい場合、以下のロールが付与されているか確認してください。
-
roles/bigquery.connectionAdmin(BigQuery Connection Admin) -
roles/bigquery.dataOwner(BigQuery Data Owner) -
roles/bigquery.user(BigQuery User)
これらを包含する上位のロールが付与されていても問題ありませんが、付与される権限はできるだけ最小にした方がよいとされています。
ロールと権限の対応や詳細は公式ドキュメントをご覧ください。
データセットを作成する
ここからは、ML モデルを保存する BigQuery データセットを作成していきます。
-
Google Cloud コンソール画面から「BigQuery」ページに移動します。
-
「エクスプローラ」ペインでプロジェクト名をクリックします。
-
プロジェクト名の横の「︙」をクリックし、「データセットを作成」をクリックします。
-
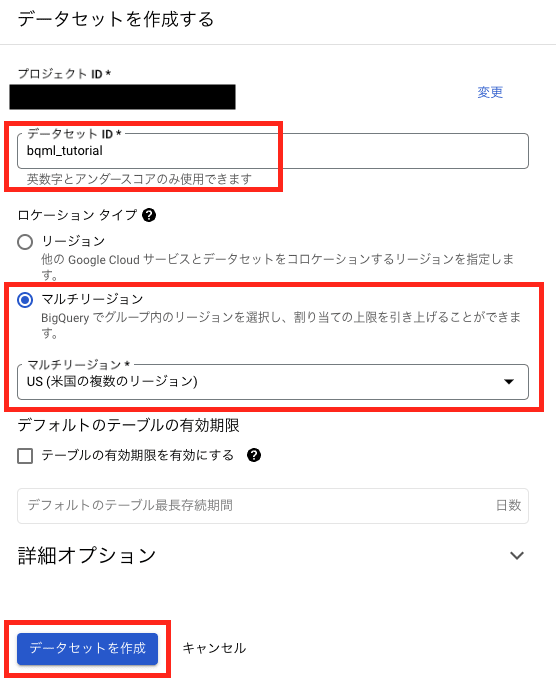
条件を以下のように設定します。今回使用するパブリックデータは、US マルチリージョンに保存されています。わかりやすくするためにデータセットも同じロケーションに保存することとします。
- データセットID:
bqml_tutorial - ロケーションタイプ
- マルチリージョン
- US(米国の複数のマルチリージョン)
設定が完了したら「データセットを作成」をクリックします。
- データセットID:
これで前準備は完了です。
学習に使うデータを確認する
ここから、今回実際に使用するデータの中身を簡単に覗いてみましょう。
データの中身を見る
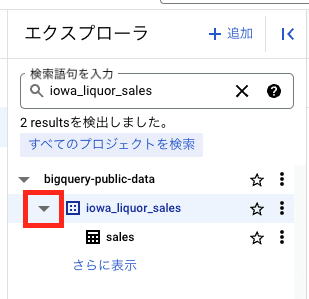
- BigQuery の「エクスプローラ」ペインの「検索語句を入力」欄に、
iowa_liquor_salesと入力して検索します。 - 「エクスプローラ」ペインの下に表示される iowa_liquor_sales の左にある「▶️」をクリックします。
そうすると sales というテーブルが表示されます。それをクリックします。
- テーブルの詳細が表示されました。
このコンソール画面を操作することで、さまざまな情報を知ることができます。
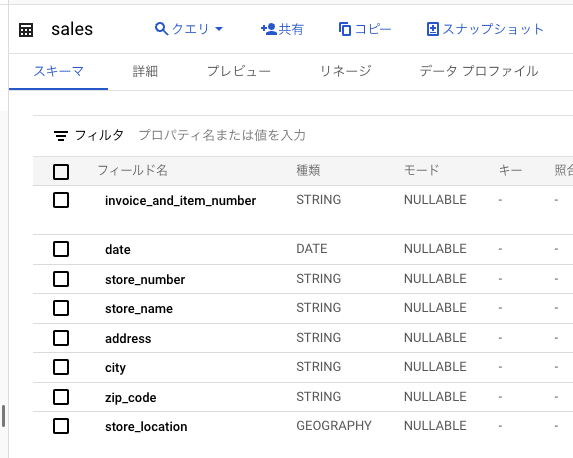
各タブで確認できる内容は以下の通りです。
| タブ名 | 内容 |
|---|---|
| スキーマ | フィールド名・各値の説明 |
| 詳細 | テーブル情報・ストレージ情報 |
| プレビュー | 実際のテーブルの中身 |
| リネージ | テーブルのリネージ情報 |
| データプロファイル | 統計特性の情報 |
| データ品質 | データチェックの定義・結果モニタリングなど |
- 「プレビュー」タブをクリックしてテーブルの詳細を表示します。
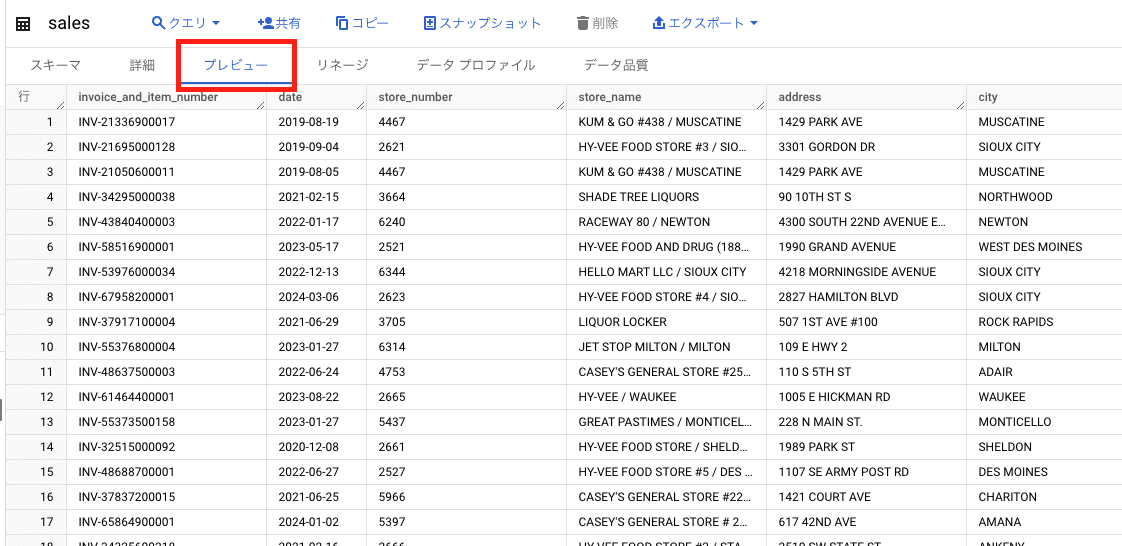
これでテーブルの中身を確認することができました。
データの階層構造を知る
ここから、実際に使用するデータの階層構造がどのようになっているかを見ていきます。
もう一度、公式ドキュメントで紹介されている図を見てみましょう。実はこの図は、今回使用するデータの階層構造を簡略化して示したものでした。
最下層は店舗レベルStore XXXXが示され、そこから順に郵便番号Zip YYYY、市、郡、州と続いています。
時系列モデルを作成して予測結果を見る
ここから、時系列モデルを作成して予測結果を見ていきましょう。
なお、ここで作成するモデルは、階層構造を意識せずに作成しているということを念頭においておきましょう。
時系列モデルを作成する
- BigQuery の「エクスプローラ」ペイン横の「+」をクリックし、「無題のクエリ」というタブを作成します。
- 以下のクエリをコピー&ペーストします。
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast`
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL = 'date',
TIME_SERIES_DATA_COL = 'total_bottles_sold',
TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'],
HOLIDAY_REGION = 'US')
AS
SELECT
store_number,
zip_code,
city,
county,
date,
SUM(bottles_sold) AS total_bottles_sold
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
WHERE
date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31')
AND county IN ('POLK', 'LINN', 'SCOTT')
GROUP BY store_number, date, city, zip_code, county;
擬似コードっぽく表現すると以下のようになります。
モデルを作成または更新する:
モデル名: bqml_tutorial.liquor_forecast
オプション:
モデルタイプは ARIMA_PLUS
タイムスタンプ列は 'date'
データ列は 'total_bottles_sold'
ID列は ['store_number', 'zip_code', 'city', 'county']
休日の地域は 'US'
データを選択する:
列を選択:
store_number
zip_code
city
county
date
total_bottle_sold(bottles_soldの合計として)
どのテーブルから持ってくるか:
'bigquery-public-data.iowa_liquor_sales.sales'
条件:
日付は2015年1月1日から2015年12月31日の間
郡は 'POLK', 'LINN', 'SCOTT' のいずれか
グループ化:
store_number, date, city, zip_code, countyによってグループ化
- コピー&ペーストが完了したら、「実行」をクリックします。

- 「クエリ結果」に liquor_forecastという名前でモデルを作成しました。 と表示されることを確認します。
これで、時系列モデルの作成が完了しました。
作成したモデルを用いて予測をする
続いて、先ほど作成したモデルを用いて、実際に予測をしてみましょう。
- 先ほどと同じようにして、「無題のクエリ」を開きます。
- 以下のクエリをコピー&ペーストします。
SELECT
*
FROM
ML.FORECAST(
MODEL `bqml_tutorial.liquor_forecast`,
STRUCT(30 AS horizon, 0.8 AS confidence_level))
WHERE city = 'LECLAIRE'
ORDER BY store_number, county, city, zip_code, forecast_timestamp
比較がしやすいようにルクレア市に絞って表示させます。
擬似コードっぽく表現すると以下のようになります。
予測を行う:
使用するモデル: bqml_tutorial.liquor_forecast
予測の詳細設定:
予測の範囲: 30
//30日後までの予測を行う
信頼区間レベル: 0.8
//予測の信頼性を示すもので、80%の信頼区間内に予測値が収まる
選択するデータ:
すべての予測結果
データ条件:
ルクレア市のみ
並び替えの基準:
店舗番号、郡、市、郵便番号、予測のタイムスタンプ によって順序付け
- コピー&ペーストが完了したら、「実行」をクリックします。
- 「クエリ結果 > 結果」タブに表が出力されていることを確認します。
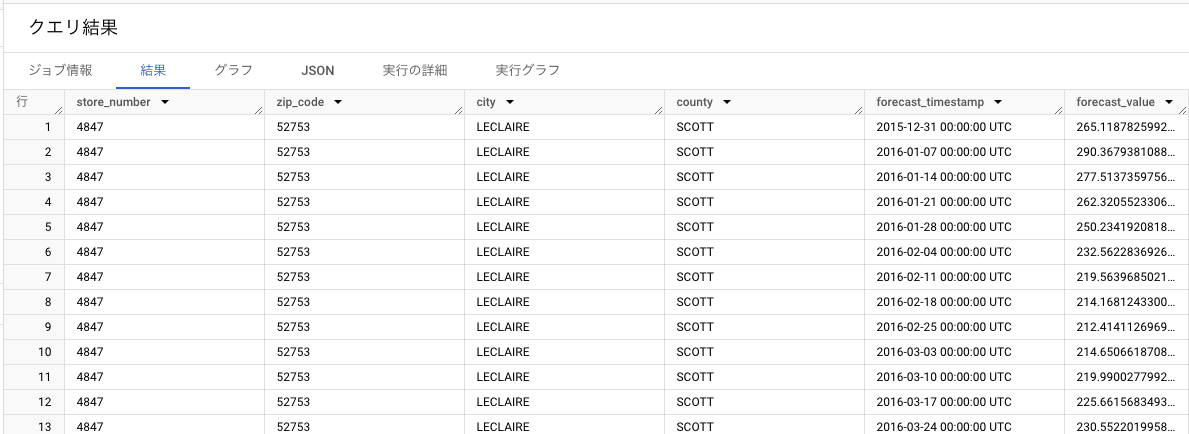
この時系列モデルは、階層構造を意識していないため時系列ごとの予測が生成されています。言い方を変えるならば、各店舗ごとに集計した、ボトルの1日当たりの販売合計数という表現が合っていると思います。
これで、時系列モデルを作成して予測結果を見ることができました。
階層型時系列モデルを作成して予測結果を見る
予測結果としては十分ですが、店舗ごとじゃなく、郡や市ごとの予測結果もまとめて知りたい! となったときに、結果を保存して、新しく「無題のクエリ」を開いてクエリを書いて...という作業はあまりにも大変です。
こういった場面で、階層型時系列予測が輝きます。
階層型時系列モデルを作成する
- 先ほどと同じように、BigQuery の「エクスプローラ」ペイン横の「+」をクリックし、「無題のクエリ」というタブを作成します。
- 以下のクエリをコピー&ペーストします。
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_hierarchical`
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL = 'date',
TIME_SERIES_DATA_COL = 'total_bottles_sold',
TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'],
HIERARCHICAL_TIME_SERIES_COLS = ['zip_code', 'store_number'],
HOLIDAY_REGION = 'US')
AS
SELECT
store_number,
zip_code,
city,
county,
date,
SUM(bottles_sold) AS total_bottles_sold
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
WHERE
date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31')
AND county IN ('POLK', 'LINN', 'SCOTT')
GROUP BY store_number, date, city, zip_code, county;
擬似コードっぽく表現すると以下のようになります。
モデルを作成または更新する:
モデル名: bqml_tutorial.liquor_forecast_hierarchical
オプション:
モデルタイプは ARIMA_PLUS
タイムスタンプ列は 'date'
データ列は 'total_bottles_sold'
ID列は ['store_number', 'zip_code', 'city', 'county']
['zip_code', 'store_number']に基づいて階層型時系列予測を生成
休日の地域は 'US'
データを選択する:
列を選択:
store_number
zip_code
city
county
date
total_bottle_sold(bottles_soldの合計として)
どのテーブルから持ってくるか:
'bigquery-public-data.iowa_liquor_sales.sales'
条件:
日付は2015年1月1日から2015年12月31日の間
郡は 'POLK', 'LINN', 'SCOTT' のいずれか
グループ化:
store_number, date, city, zip_code, countyによってグループ化
時系列モデルを作成するクエリとの違いは、OPTIONSに、以下の設定が追加された点です。
HIERARCHICAL_TIME_SERIES_COLS = ['zip_code', 'store_number'],
HIERARCHICAL_TIME_SERIES_COLSは、指定された列に基づいて階層型時系列予測を作成するための設定です。
今回は['zip_code', 'store_number']が指定されています。このとき、store_numberごとの予測結果が集計され、次の階層のzip_codeの予測結果を作成するために使用します。同じようにして、zip_codeごとの予測結果が集計され、更に上の階層のcounty、cityの予測結果を作成するために使用します。
- コピー&ペーストが完了したら、「実行」をクリックします。
- 「クエリ結果」に liquor_forecast_hierarchicalという名前でモデルを作成しました。 と表示されることを確認します。
これで、階層型時系列モデルの作成が完了しました。
作成したモデルを用いて予測をする
続いて、先ほど作成したモデルを用いて、実際に予測をしてみましょう。
- 先ほどと同じようにして、「無題のクエリ」を開きます。
- 以下のクエリをコピー&ペーストします。
SELECT
*
FROM
ML.FORECAST(
MODEL `bqml_tutorial.liquor_forecast_hierarchical`,
STRUCT(30 AS horizon, 0.8 AS confidence_level))
WHERE city = 'LECLAIRE'
ORDER BY county, city, zip_code, store_number, forecast_timestamp
擬似コードっぽく表現すると以下のようになります。
予測を行う:
使用するモデル: bqml_tutorial.liquor_forecast
予測の詳細設定:
予測の範囲: 30
信頼区間レベル: 0.8
選択するデータ:
すべての予測結果
データ条件:
ルクレア市のみ
並び替えの基準:
店舗番号、郡、市、郵便番号、予測のタイムスタンプ によって順序付け
- コピー&ペーストが完了したら、「実行」をクリックします。
- 「クエリ結果 > 結果」タブに表が出力されていることを確認します。
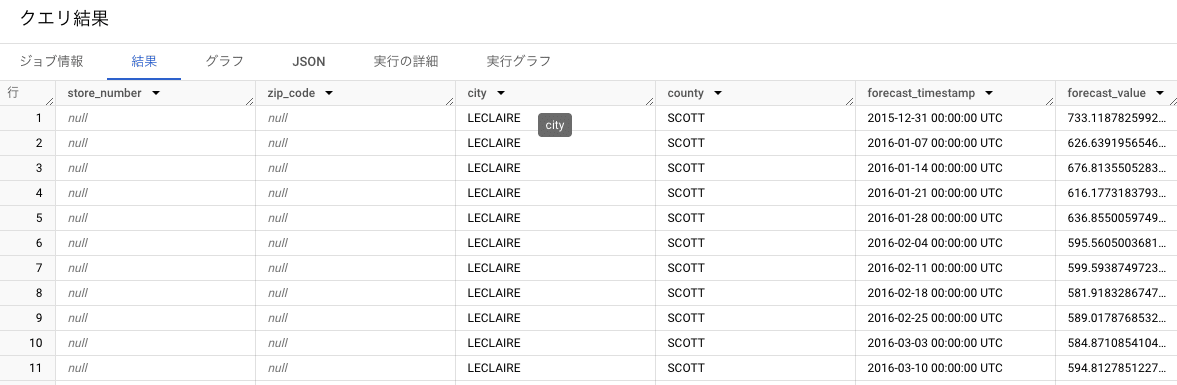
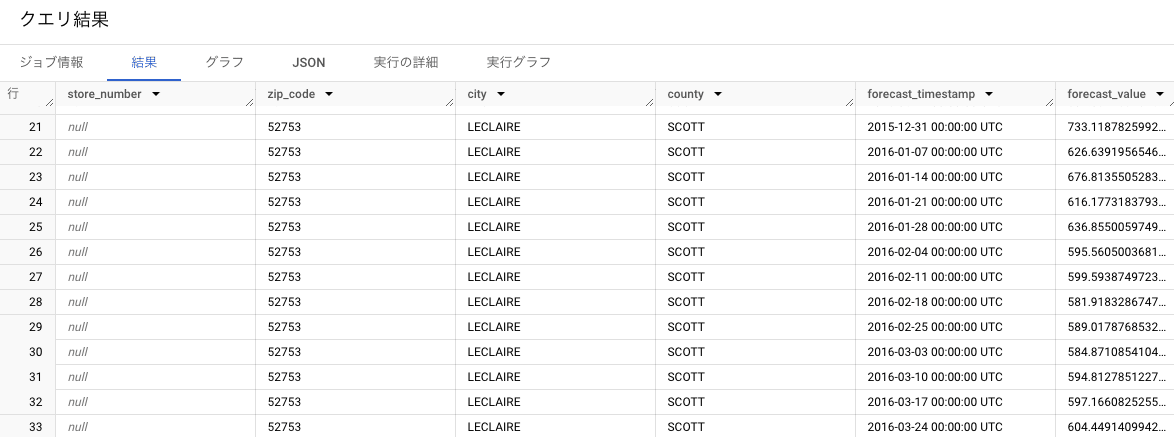
この表を探索してみると、zip_codeとstore_numberがnullとなっている部分が見られると思います。
これは階層構造を意識した時系列モデルが作成されている証拠で、集約された部分がnullとなっています。
-
zip_codeとstore_numberが集約された部分(1行目~20行目)
この部分は、市ごとに集計した、ボトルの1日当たりの販売合計数 となります。
-
store_numberが集約された部分(21行目~40行目)
この部分は、郵便番号ごとに集計した、ボトルの1日当たりの販売合計数 となります。
-
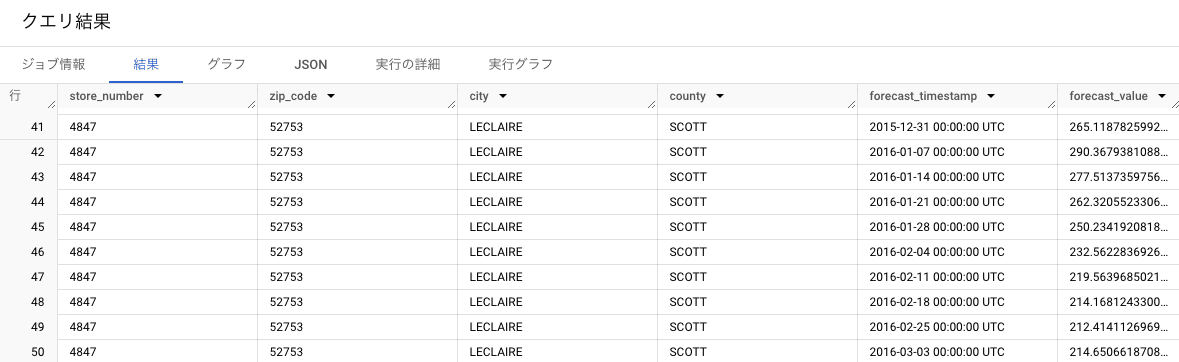
何も集約しなかった部分(41行目~80行目)
この部分は、店舗ごとに集計した、ボトルの1日当たりの販売合計数 、つまり階層構造を意識せずに作成した時系列モデルが出力したものと同じものとなります。
階層型時系列モデルの結果↓
時系列モデルの結果↓
一度にさまざまな階層に対する予測結果を見ることができました。階層構造を意識せずに作成するよりスマートですね。
2つのモデルを比較する
ここまでの過程で作成してきた2つのモデルについて、実行時間と処理量・料金を比較してみましょう。
実行時間
公式ドキュメント では、実行にかかる時間を以下のように表現しています。私自身も体感では同じような秒数でした。
| モデル形式 | 作成時間 | 予測時間 |
|---|---|---|
| 時系列 | 約 37 秒 | 約 5 秒 |
| 階層型時系列 | 約 45 秒 | 約 5 秒 |
単純な時系列モデルの方がやや速いという結果となりました。しかし、あくまでもこの結果は 1回だけ実行した場合であり、階層型時系列モデルで得られた3種の予測結果(市ごと、郵便番号ごと、店舗ごと)を時系列モデルでも得ようとすると、時系列モデルを3回作成する必要があり、単純に作成時間と予測時間が3倍になることが考えられます。
処理量・料金
処理量はクエリ実行前のコンソール画面の右部分から取得し、料金は処理量と公式ドキュメントの料金案内の部分から概算しました。
BigQuery と BigQuery ML で、料金が変わってくるので気をつけましょう。
今回費用がかかった部分だけ以下の表にまとめます。
| サービス | 料金 |
|---|---|
| BigQuery | 1 TiB あたり 6.25 ドル(毎月最初の1TiBは無料) |
| BigQuery ML | 1 TiB あたり 312.5 ドル |
結果は以下の表です。
| モデル形式 | 作成処理量 | 作成料金 | 予測処理量 | 予測料金 |
|---|---|---|---|---|
| 時系列 | 55.59 GB | 約 17.3 ドル | 23.58 MB | 約 0.00014ドル |
| 階層型時系列 | 55.59 GB | 約 17.3 ドル | 39.09 MB | 約 0.0002ドル |
モデル作成処理量は同じで、予測処理量は時系列モデルの方が約 16 MB少ないという結果となりました。これについても実行時間と同じことが言えて、階層型時系列モデルで得られた3種の予測結果を時系列モデルでも得ようとすると、作成処理量と予測処理量が3倍になることが考えられます。料金で考えると約 35 ドルも差が生まれます。
まとめ
本稿では、最初にリリース概要や階層の概念、メリットを説明した後、時系列予測と階層型時系列予測を行い、従来の手法と比較してどう変わったかを紹介してきました。
使用場面によってはかなりの時短と節約になり、かつスマートに予測結果をまとめられるので是非この機能を利用してみてください。
Discussion