Cross-cloud join を使ってクラウド間データ活用境界を越える
はじめに
こんにちは。クラウドエース データソリューション部所属の金です。
クラウドエースの データソリューション部 では、IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門としています。
データソリューション部の活動の一環として、Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
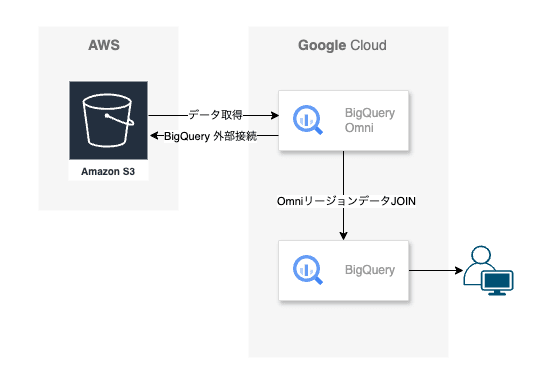
本記事で紹介する内容は、BigQuery における Cross-cloud join 機能についてです。

BigLake Table Architecture diagram
Cross-cloud join とは?
Cross-cloud join を使用すると、Google Cloud と BigQuery Omni リージョンの両方をまたいだクエリを実行できます。Google Cloud SQL のJOIN演算を使用して、AWS、Azure、および他のパブリックデータセットなど、さまざまなストレージソリューションを横断してデータを分析できます。Cross-cloud join により、クエリを実行する前にデータをソース間でコピーする必要がなくなります。

BigQuery Omni cross cloud queries demo
すごくシンプルに言うと、データ分析などのため、他のクラウドデータと簡単に結合が可能になる機能となります。
Cross-cloud join demo 動画(Google Cloud 公式)
Cross-cloud join はこんな人におすすめ
- Google Cloud のデータを AWS、Azure などのデータと簡単(複数のステップが関わる長く複雑なプロセスを使用しない)に結合したい人
- 他クラウドのデータと結合する時、低コストで、データの更新頻度が高く、消費しやすい形で実行したい人
- クラウド間でのデータの移動は非常に扱いが難しく、セキュリティ境界と信頼境界が非常に重要だと思う人
- BigQuery の新機能を学びたい人
Cross-cloud join のメリット
- クラウド間で直接結合を実行できる。BigQuery でテーブルを明示的に作成または実体化し、結合操作を実行する必要がない。
- クラウド プラットフォーム全体に分散されているデータの分析がシンプルかつ容易になり、費用も削減される。
- ETL 経由で AWS または Azure データレイクのデータを BigQuery にコピーする際のパイプラインの構築と実行の複雑さを解消できる。
Cross-cloud join のユースケース
-
マーケティング分析 : ある大手小売業者は、Azure 上にメディアデータを、Google Cloud 上に顧客データを保管しています。実施中のキャンペーンから指標を得るには、Azure から Google Cloud へのファイルの転送、データの取り込み、データの移動などの従来型のデータ交換パターンを使用する必要がありました。BigQuery Omni の Cross-cloud join 機能を使用すれば、BigQuery のペタバイト規模のパフォーマンスを活用しながら、Azure データとの結合を実現できます。
-
統合データ プラットフォーム : ある大手医療機関は、AWS 上に大量のデータを保管している別の医療機関を買収しました。分析を実行するには、データサイロや、Google Cloud アーキテクチャと AWS アーキテクチャに分割されているデータ プラットフォーム アーキテクチャに対応する必要がありました。今では Cross-cloud join を実行できるため、アーキテクチャが大幅に簡素化され、一括表示を使用した統合データ プラットフォームを構築できるようになりました。
-
クロスクラウド分析 : アジアの大手ゲーム プラットフォームには 2 つの分析プラットフォームがあり、それぞれ BigQuery と AWS を使用しています。どちらの分析プラットフォームにも大量のデータが保管されているため、1 つのプラットフォームに統合するのは困難です。アナリストは、ゲームプレーヤーのデータを分析し、ゲームのラインナップを最適化するために、重要なビジネス インサイトを構築する必要があるときはいつでも、Cross-cloud join をアドホックに活用しています。
Cross-cloud join のコスト
BigQuery Omni で Cross-cloud join を実行すると、クエリはローカル部分とリモート部分に分割されます。
- ローカル部分 : BigQuery リージョンでの標準クエリとして扱われます。
- リモート部分 : BigQuery Omni リージョンの参照された BigLake テーブル上で
CREATE TABLE AS SELECT(CTAS)操作に変換され、一時テーブルが BigQuery リージョンに作成されます。BigQuery は、この一時テーブルを使用してCross-cloud join を実行し、自動的に8時間後にテーブルを削除します。
参照された BigLake テーブルのデータ転送コストが発生します。ただし、BigQuery は、クエリで参照される BigLake テーブルの列と行のみを転送し、テーブル全体ではないため、これらのコストを削減します。さらに転送コストを削減するために、できるだけ狭い範囲の列フィルターを指定することをおすすめします。CTAS ジョブはジョブ履歴に表示され、転送されたバイト数などの情報が表示されます。メインのクエリジョブが失敗した場合でも、正常に転送された場合はコストが発生します。詳細については、BigQuery Omni の価格設定を参照してください。
1つの転送でもコスト発生するクエリの例
SELECT *
FROM bigquery_dataset.bigquery_table AS clients
WHERE clients.sales_rep IN (
SELECT id
FROM aws_dataset.aws_table1 AS employees
INNER JOIN aws_dataset.aws_table2 AS active_employees
ON employees.id = active_employees.id
WHERE employees.level > 3
);
この例では、従業員テーブル(レベルフィルター付き)の転送とアクティブ従業員テーブルの転送の2つがあります。転送後にBigQuery リージョンでJOINが実行されます。1つの転送が失敗した場合でも、1つが成功した場合、データ転送料金が発生します。
Cross-cloud join の制限
一般的な制限事項
- free tier と BigQuery sandbox では使用できません。
- 同じリージョンにある複数の BigLake テーブルの
JOINは、BigQuery Omni リージョンにプッシュダウンされません。 - クエリに
JOIN句が含まれている場合、集計が BigQuery Omni リージョンにプッシュダウンされない可能性があります。 - 各一時テーブルは、単一 Cross-cloud クエリでのみ使用され、同じクエリが複数回実行されても再利用されません。
- プッシュダウンとは、データ統合および抽出、変換、ロード(ETL)プロセスにおけるデータ処理の最適化手法
データ転送とクォータ
- 転送サイズの上限は、転送ごとに
20GBです。特に、BigLake テーブルにフィルターをかけて結果をロードする場合でも、その結果は20GB未満でなければなりません。必要であれば、クォータの上限を引き上げることが可能です。スキャンしたバイト数に制限はありません。 - 内部クォータによってクエリのレートが制限されます。クォータを超過すると
All our servers are busy processing data transferred between regionsというエラーメッセージが表示される場合があります。ほとんどの場合、クエリの再実行が動きます(より高いクォータが必要な場合はサポートに連絡してください)。 -
同じロケーションに配置された BigQuery リージョンと
USまたはEUのマルチリージョンでのみサポートされます。
USまたはEUのマルチリージョンで実行される Cross-cloud join は、それぞれUSまたはEUの BigQuery Omni リージョンにあるデータのみアクセスできます。
クエリの動作
- デフォルトで、Cross-cloud join はアルファベット順で並べたすべてのデータセットの中で最初に来るデータセットが属する BigQuery リージョンで実行されます。ただし、最初の10個のデータセットしかスキャンされないため、10個を超えるデータセットが BigQuery Omni リージョンの BigLake テーブルだった場合、BigQuery テーブルが含まれているとジョブは失敗します。
この問題を回避するために、10個を超えるデータセットを参照する Cross-cloud join を実行する場合は、明示的にロケーションを指定することをおすすめします。ただし、明示的に BigQuery リージョンを指定し、クエリで BigLake テーブルのみを使用した場合でも、そのクエリは Cross-cloud クエリとして実行され、データ転送コストが発生しますので注意してください。 -
_FILE_NAME疑似列カラムは使用できません。 - BigLake テーブルを参照する WHERE 句では、特定のデータ型 (NUMERIC、BIGNUMERIC、BYTES、TIME、INTERVAL) は使用できません。
- Cross-cloud join は別のクラウドから処理されて、転送されたバイト数は表示されませんが、下位 CTAS(一時テーブル生成の CREATE TABLE AS SELECT 操作) ジョブで確認できます。
Cross-cloud join の例
- BigQuery リージョン内の注文テーブルと BigQuery Omni リージョン内のラインアイテムテーブル
JOIN
SELECT
l_shipmode,
o_orderpriority,
count(l_linenumber) AS num_lineitems
FROM bigquery_dataset.orders
JOIN aws_dataset.lineitem
ON orders.o_orderkey = lineitem.l_orderkey
WHERE
l_shipmode IN ('AIR', 'REG AIR')
AND l_commitdate < l_receiptdate
AND l_shipdate < l_commitdate
AND l_receiptdate >= DATE '1997-01-01'
AND l_receiptdate < DATE '1997-02-01'
GROUP BY l_shipmode, o_orderpriority
ORDER BY l_shipmode, o_orderpriority;
このクエリは、ローカルとリモートの2つの部分に分割されています。
最初に BigQuery Omni リージョン次のクエリを送信されます。その結果が BigQuery リージョンに一時テーブルとして転送されます。
CREATE OR REPLACE TABLE temp_table
AS (
SELECT
l_shipmode,
l_linenumber,
l_orderkey
FROM aws_dataset.lineitem
WHERE
l_shipmode IN ('AIR', 'REG AIR')
AND l_commitdate < l_receiptdate
AND l_shipdate < l_commitdate
AND l_receiptdate >= DATE '1997-01-01'
AND l_receiptdate < DATE '1997-02-01'
);
一時テーブルが作成された後、JOIN操作を完了し、次のクエリが実行されます。
SELECT
l_shipmode,
o_orderpriority,
count(l_linenumber) AS num_lineitems
FROM bigquery_dataset.orders
JOIN temp_table
ON orders.o_orderkey = lineitem.l_orderkey
GROUP BY l_shipmode, o_orderpriority
ORDER BY l_shipmode, o_orderpriority;
- Cross-cloud join の
LIMIT句
SELECT c_mktsegment, c_name
FROM bigquery_dataset.customer
WHERE c_mktsegment = 'BUILDING'
UNION ALL
SELECT c_mktsegment, c_name
FROM aws_dataset.customer
WHERE c_mktsegment = 'FURNITURE'
LIMIT 10;
このクエリでのLIMIT句は BigQuery Omni リージョンにプッシュダウンされません。
まず、c_mktsegmentがFURNITUREのすべてのデータが BigQuery リージョンに転送され、その後、10件のLIMITが適用されます。
Cross-cloud join の検証
ここからは実際に、AWS にあるデータをBigQuery Omni 上に持って来て、BigQuery に保存されているデータと結合を試してみます。
全体的な流れ
- AWS の S3 にデータ配置
- AWS IAM ポリシーと IAM ロールの作成
- BigQuery 外部接続の作成
- BigQuery データセット、テーブル作成
- クエリ実行
はじめる準備
Cross-cloud join を開始するには、下記の準備が必要となります。
- free tier と BigQuery sandbox ではない事を確認
- 使用するプロジェクトの BigQuery Connection API の有効化
- 必要な権限を付与
- BigQuery Data Editor (roles/bigquery.dataEditor)
AWS の S3 にデータ配置
-
AWS の S3 にバケットを作成します。

米国東部(バージニア北部)us-east-1リージョンにバケットを作成しました。 -
作成した CSV ファイルを S3 にアップロードします。
- 今回、 BigQuery 側で公開しているデータセット
bigquery-public-data.baseball.schedulesを利用するため、それに合わせた CSV を作成しました。
作成した CSV ファイル
Marlins,マイアミ・マーリンズ
Braves,アトランタ・ブレーブス
Phillies,フィラデルフィア・フィリーズ
Diamondbacks,アリゾナ・ダイヤモンドバックス
Athletics,オークランド・アスレチックス
Rockies,コロラド・ロッキーズ
Cardinals,セントルイス・カージナルス
Pirates,ピッツバーグ・パイレーツ
Giants,サンフランシスコ・ジャイアンツ
Reds,シンシナティ・レッズ
Padres,サンディエゴ・パドレス
Nationals,ワシントン・ナショナルズ
Brewers,ミルウォーキー・ブルワーズ
Astros,ヒューストン・アストロズ
Dodgers,ロサンゼルス・ドジャース
Mets,ニューヨーク・メッツ
Cubs,シカゴ・カブス
Tigers,デトロイト・タイガース
Indians,クリーブランド・ガーディアンズ
Royals,カンザスシティ・ロイヤルズ
Blue Jays,トロント・ブルージェイズ
Mariners,シアトル・マリナーズ
Angels,ロサンゼルス・エンゼルス
Orioles,ボルチモア・オリオールズ
Red Sox,ボストン・レッドソックス
Yankees,ニューヨーク・ヤンキース
Twins,ミネソタ・ツインズ
Rangers,テキサス・レンジャーズ
White Sox,シカゴ・ホワイトソックス
Rays,タンパベイ・レイズ

AWS IAM ポリシーと IAM ロールの作成
S3 バケット作成、データ配置が終わったので次は BigQuery Omni 向けに IAM ポリシーと IAM ロールを作成します。
- IAM ポリシーを作成します。
ナビゲーションで「IAM」→「ポリシー」→「ポリシーの作成」→「JSON」をクリックして、以下の JSON コードを貼り付けます。
「作成したバケット名」には先ほど S3 に作成したバケット名を入れ換えてください。
ポリシー JSON
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::作成したバケット名"]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": ["arn:aws:s3:::作成したバケットの名/*"]
}
]
}

- ポリシー名を入力してポリシーを作成します。
- 今回は「
google-cross-connect」という名前を付けています。
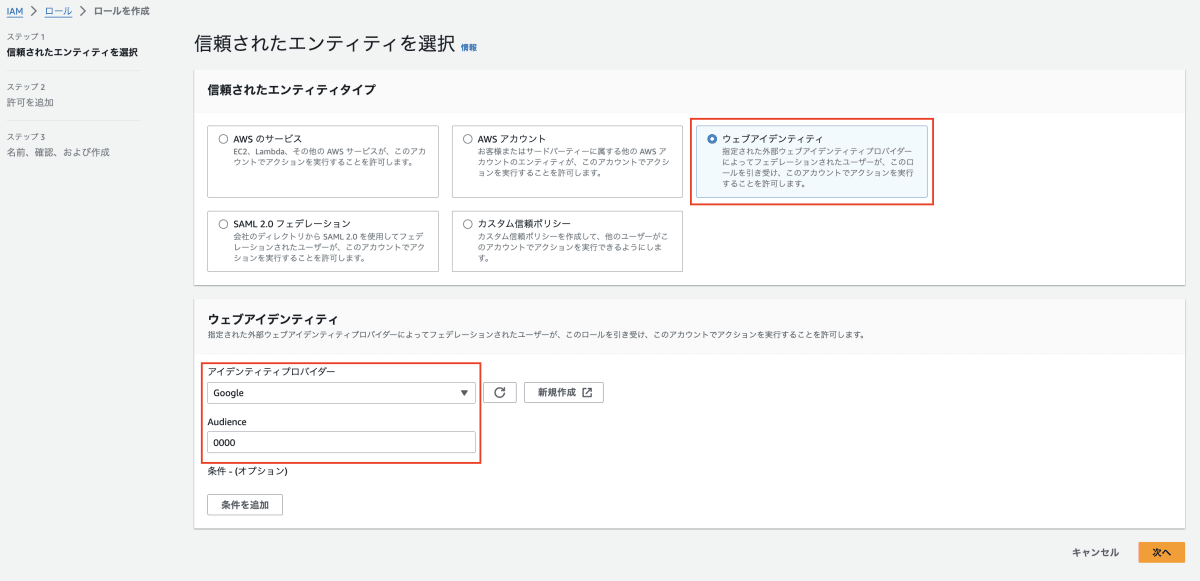
- IAM ロールを作成します。
ナビゲーションで「IAM」→「ロール」→「ロールを作成」をクリックします。
下記の表のように選択および入力します。
ロール
| 信頼されたエンティティタイプ | ウェブアイデンティティ |
|---|---|
| アイデンティティプロバイダー | |
| Audience | 0000(仮で作成して、あとで正しい値に修正します) |
-
ロールにポリシーをアタッチします。
検索で先ほど作成したポリシー名「google-cross-connect」を入力してポリシーを選択します。

-
最後にロール名を入力してロールを作成します。
- 今回は「
google-cross-connect-role」という名前を付けています。
BigQuery 外部接続の作成
BigQuery から AWS S3 に接続するために、外部接続を作成します。
-
外部接続の作成は、BigQuery のコンソールから「+追加」→「外部データソースへの接続」を選択します。

-
外部データソースは、下記の内容を入力し、外部接続を作成します。
外部データソース
| 接続タイプ | AWS 上の BigLake(BigQuery Omni 経由) |
|---|---|
| 接続 ID | 外部接続リソースの名(任意) |
| リージョン | aws-us-east1 |
| AWS ロール ID | AWS で作成したロールの ARN |

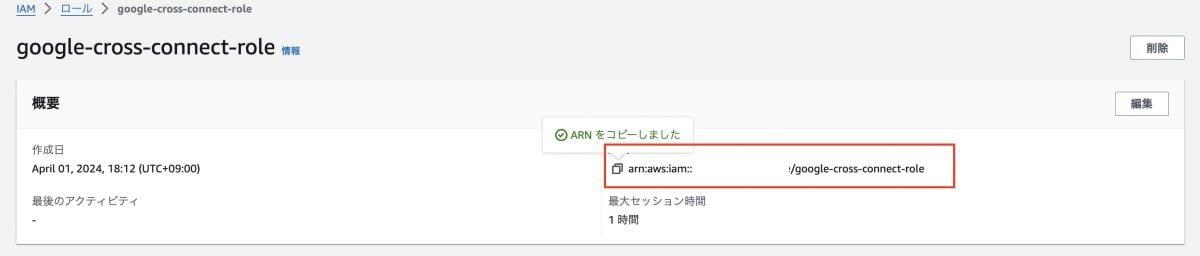
- 今回は「
aws-connect」という名前を付けています。 - AWS ロール ID は AWS ロール画面で作成したロールを選択すると ARN がコピーできます。
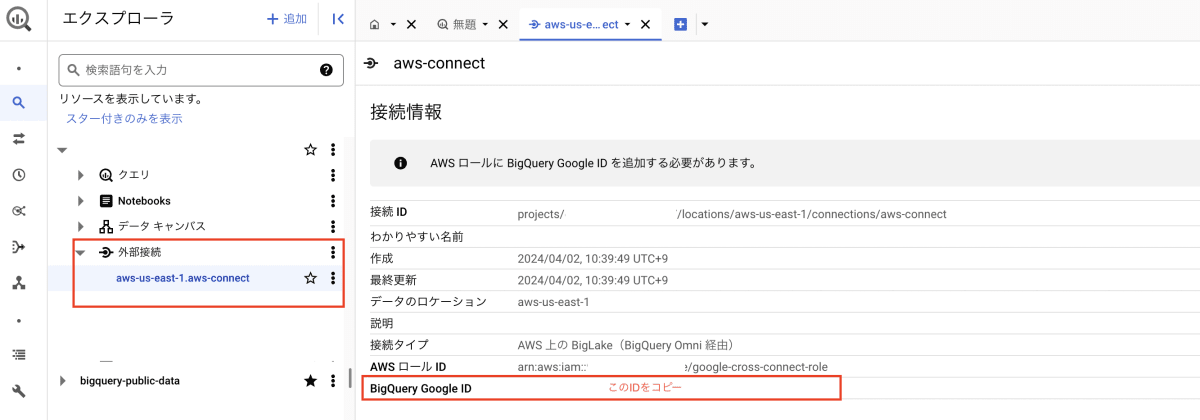
これだけではまだ AWS と接続できないので作成した外部接続をクリックして、「BigQuery Google ID」を AWS ロール(Audience:0000に入力した部分)に入れ替えます。
AWS ロールで「信頼関係タブ」→「信頼ポリシーを編集」→「0000を入れ替える」


AWS ロール最大セッション時間エラー & 編集
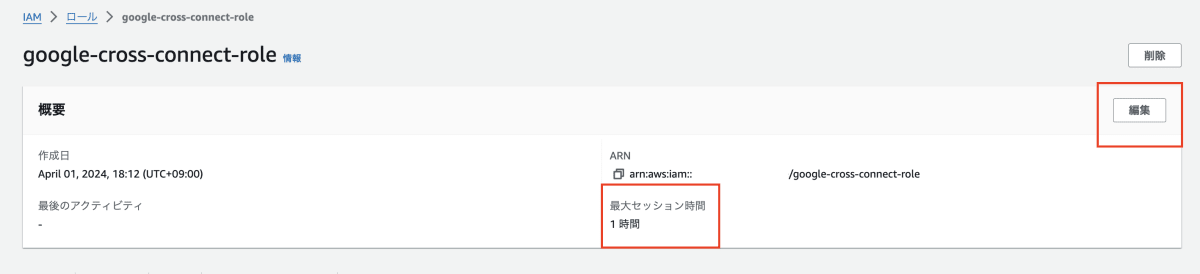
- テーブル作成の時エラー内容

- ロール画面で編集をクリックします。
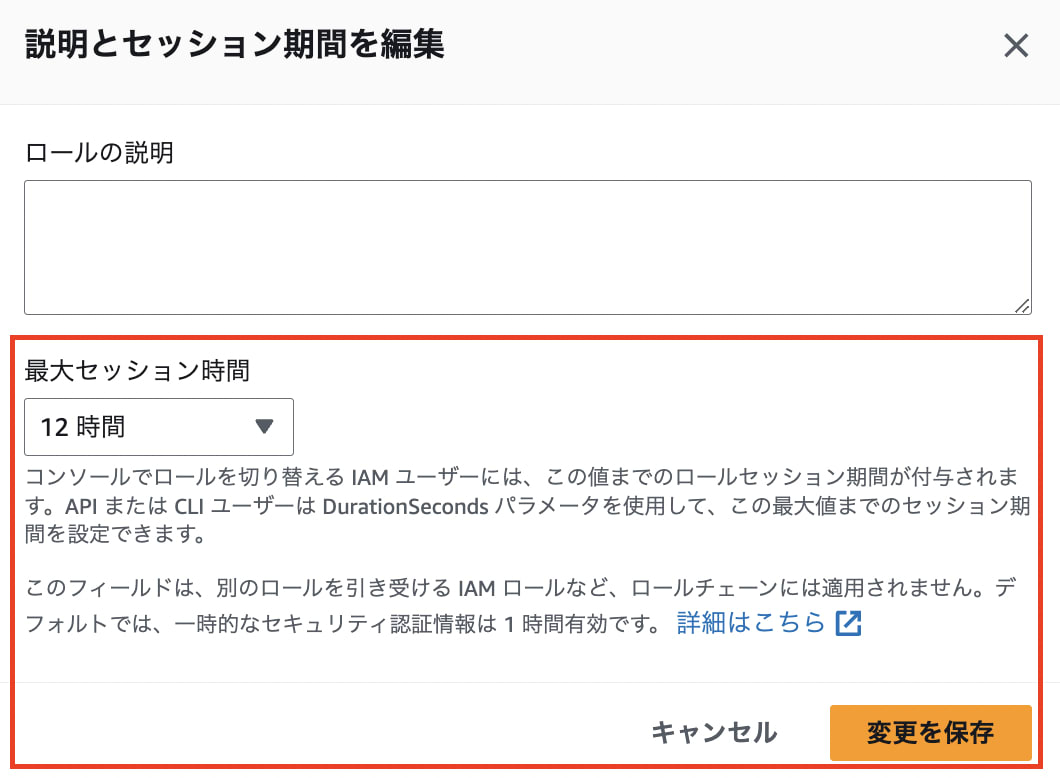
- 最大セッション時間を
12時間にして、保存します。
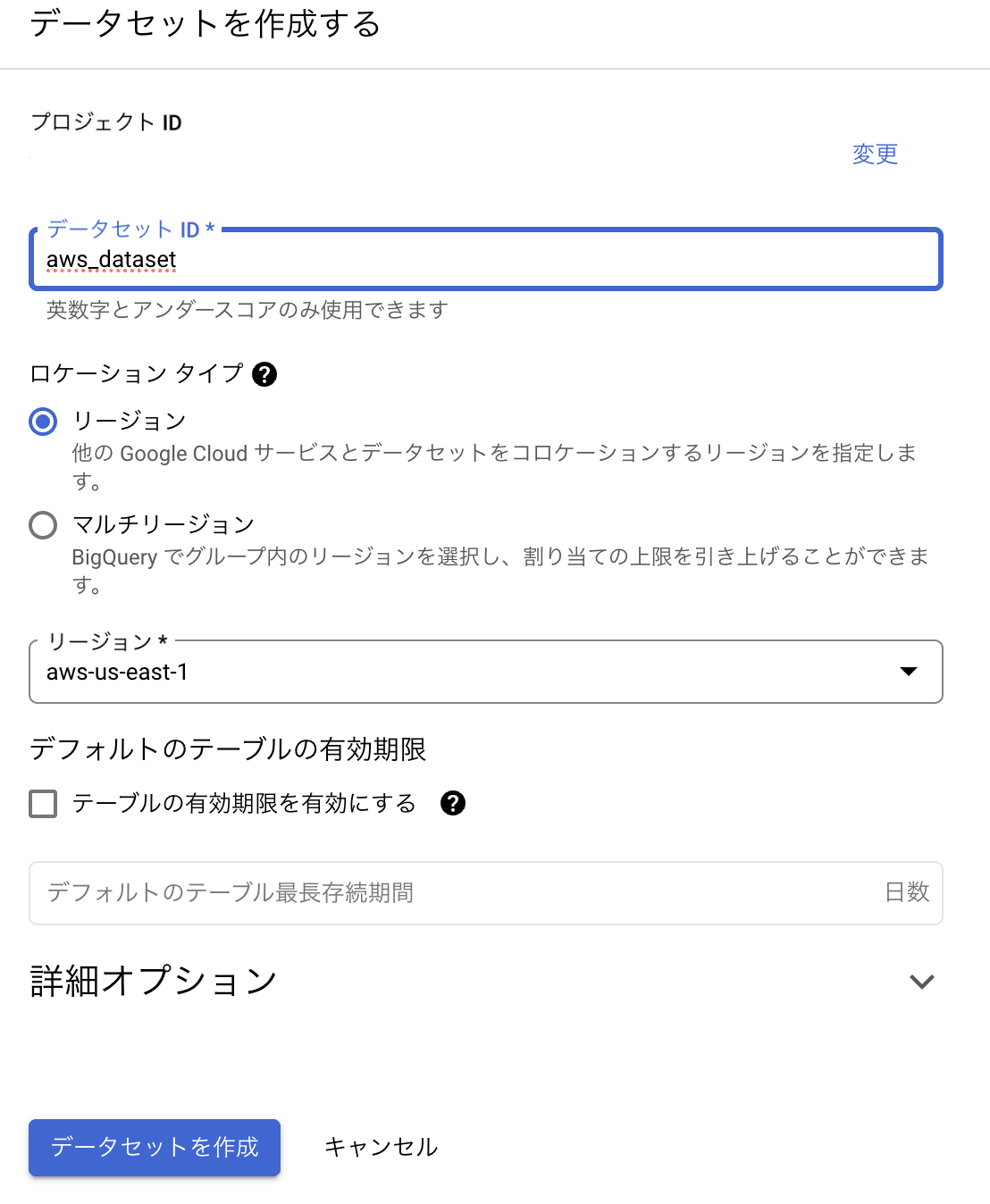
- データセットとテーブル作成
作成するデータセットには AWS S3 を指定したいので「ロケーションタイプ:aws-us-east1」を指定します。
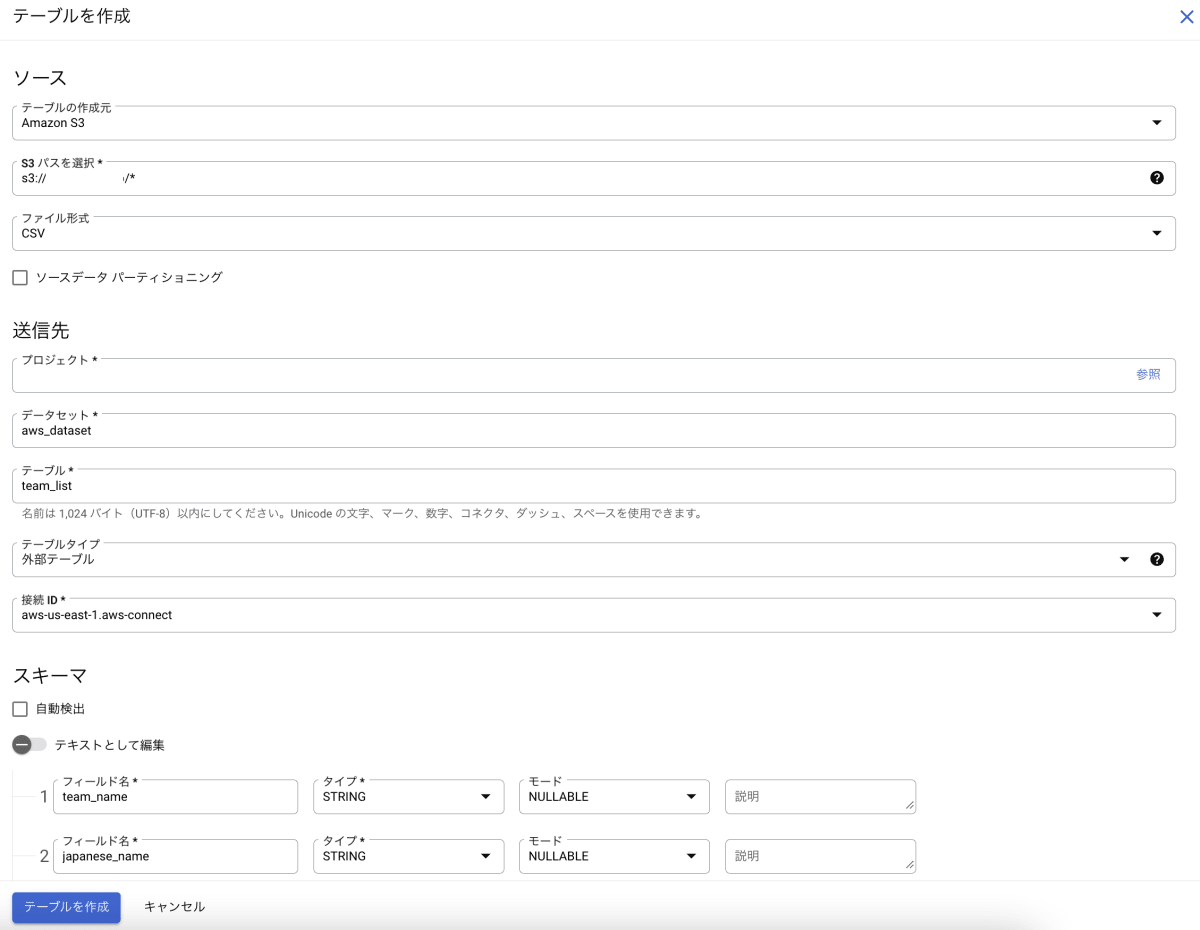
最後に BigQuery のテーブルを作成します。
テーブル作成
| テーブルの作成元 | Amazon S3 |
|---|---|
| S3 パスを選択 | s3://<mybucket>/* |
| テーブル名 | team_list(任意) |
| スキーマ | データに合わせて作成 |
クエリ実行
問題なく AWS S3 にある CSV からデータを読み込めました。
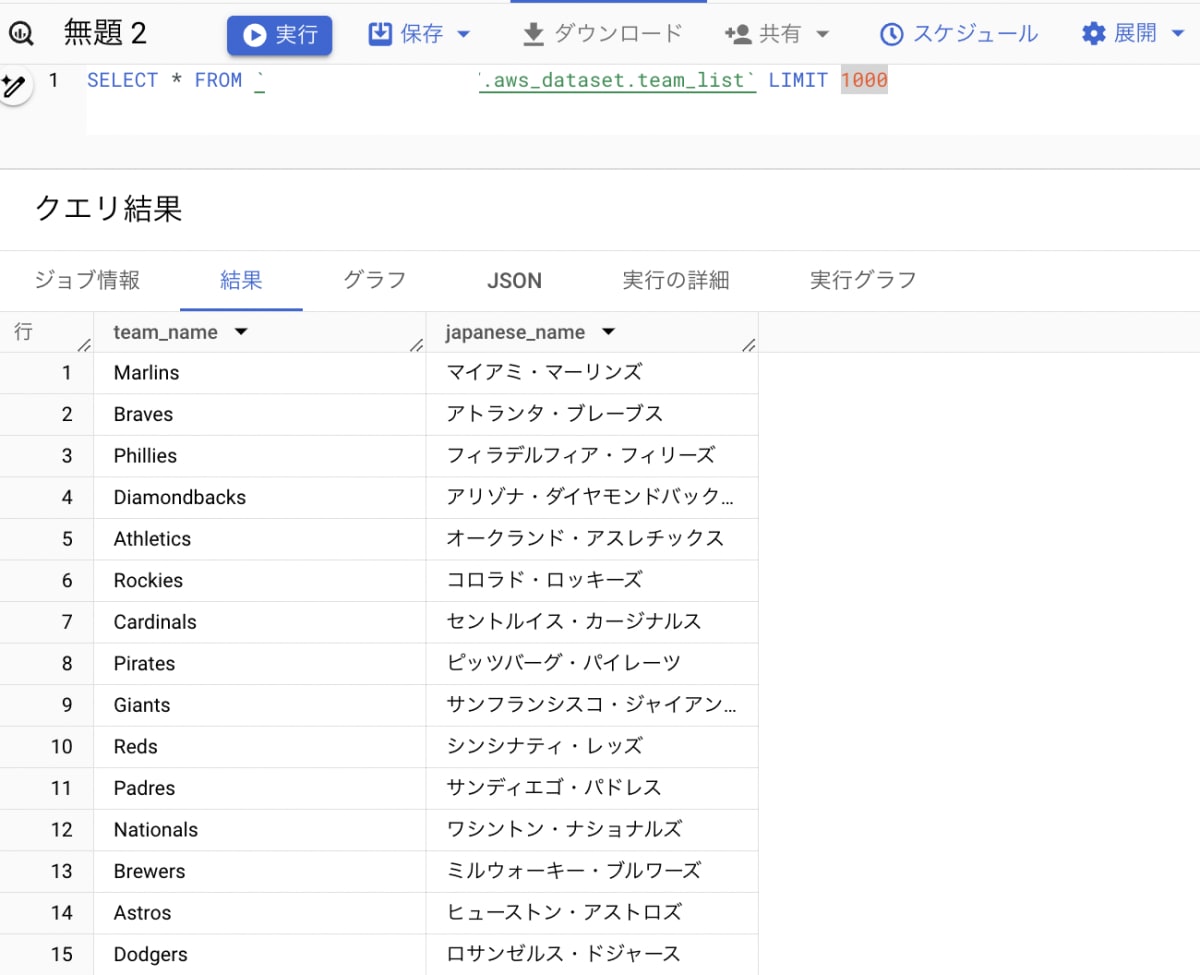
- Cross-cloud join を実行
それでは本題の Cross-cloud join を実行してみます。
SELECT
gcp.homeTeamName,
aws.japanese_name,
SUM(gcp.duration_minutes) AS total_min
FROM
`bigquery-public-data.baseball.schedules` gcp
JOIN
`<my-project>.aws_dataset.team_list` aws
ON
gcp.homeTeamName = aws.team_name
WHERE
gcp.year = 2016
GROUP BY
gcp.homeTeamName,
aws.japanese_name
ORDER BY
total_min DESC
- BigQuery のパブリックデータを AWS S3 からのデータと
JOINして、チーム別2016年トータル試合時間、日本語名(aws.japanese_name)を表示するようにします。
AWS S3 からのデータ(チームの日本語名)も問題なく表示されているのが確認できました。

ジョブの実行グラフをみましょう。
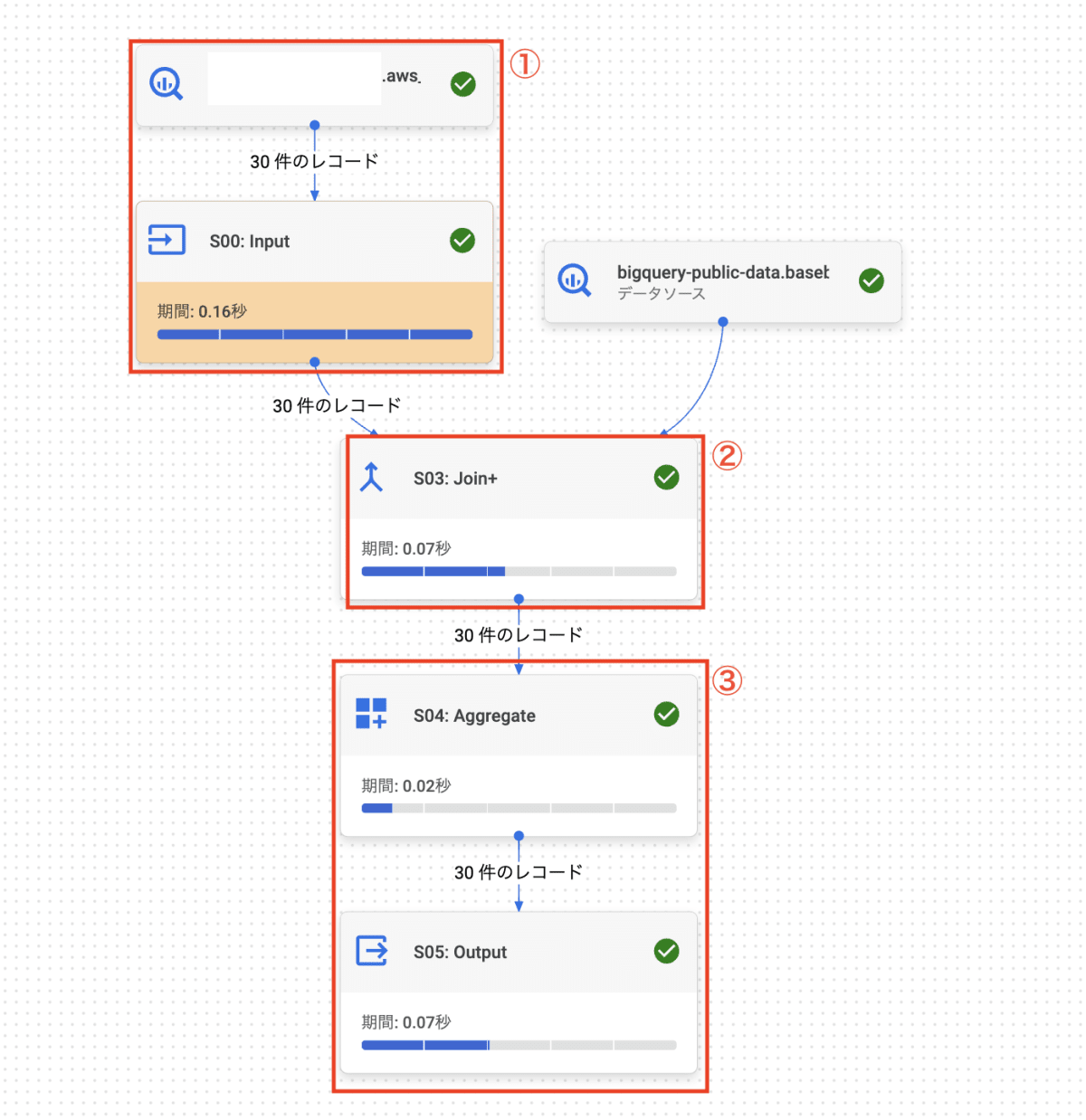
① AWS S3 からのデータが Input → ② BigQuery のデータと JOIN → ③ 集計後、Output されるのが確認できます。

次にジョブ履歴を見てみると、 ① Cross-cloud join クエリが実行されると下位 CTAS ジョブが ② BigQuery リージョンに一時テーブルとして生成されるのが確認できます。
- Cross-cloud join の
LIMIT句
SELECT homeTeamName
FROM `bigquery-public-data.baseball.schedules`
GROUP BY homeTeamName
UNION ALL
SELECT japanese_name FROM `<my-project>.aws_dataset.team_list`
LIMIT 10;

① 全てのデータが BigQuery リージョンに一時テーブルとして生成され ② Input後、10件のLIMITが適用されます。
- 追加検証
外部テーブルなので AWS S3 側でファイルの内容が修正、追加された場合、その内容が反映されると思いますが、実際どうか検証してみましょう。
作成した CSV ファイルに1行(New,新しいチーム)を追加してクエリを実行します。
Marlins,マイアミ・マーリンズ
...
New,新しいチーム
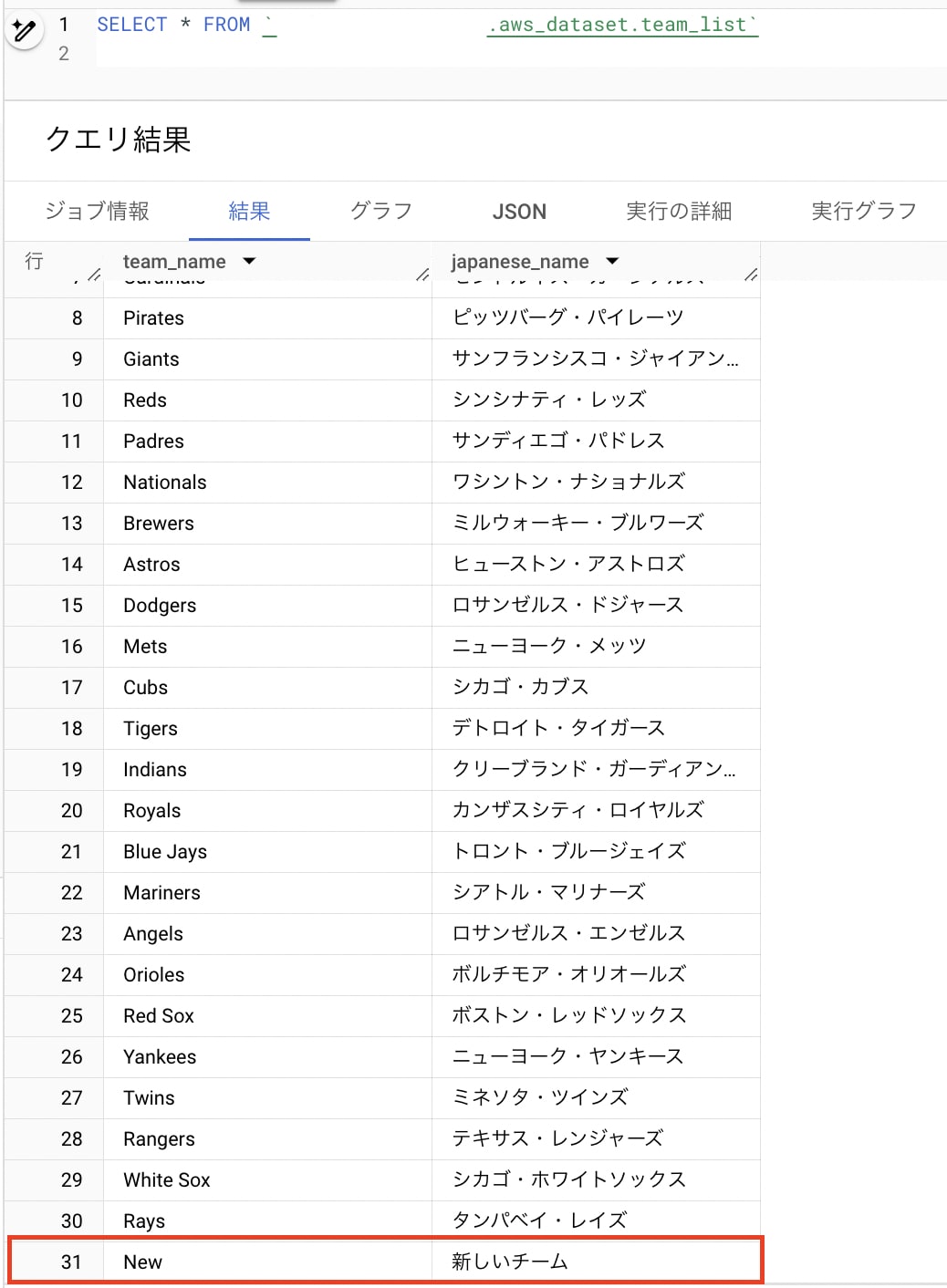
想像した通り追加されたデータが反映されているのが確認できます。
終わりに
今回は、Cross-cloud join 機能を試してみました。
クラウド間データ活用ができるのは結構嬉しいし、重要な機能の1つだと思いました。もちろん既存のデータ連携方法も色々ありますが、複雑なデータ連携プローを作ったりすると、開発+運用のコストも高くなるので結合に必要な一部のデータ(マスターデータ、分析に必要な一部のカラムを持っているテーブルなど)を参照する規模だとCross-cloud joinでもっと簡単にデータ活用ができると思いました。
どのくらいのデータ量までCross-cloud joinを利用してパフォーマンス的、効率的に良いかは少し疑問にはなっていますが、制限が20GBなのでおそらく20GB以下だとCross-cloud joinを利用するのが良いかと思いました。みなさんもぜひお試しください。
最後まで読んでいただきありがとうございました。
関連記事
Cross-cloud joins
Amazon S3 BigLake テーブルを作成する
BigQuery Omni の概要
So long data silos: Announcing BigQuery Omni cross-cloud joins
BigQuery OmniでAmazon S3のデータをクエリしてみた
Discussion