Google が Gemma 3 をリリース!-Cloud Run で動かしてみた-
はじめに
こんにちは、クラウドエースの第二開発部に所属している村松です。
生成 AI を駆使して、日々開発に励んでいます。
さて、2025年の3月に、Google が Gemma 3 をリリースしました。
Gemma 3 は、Gemini 1.5 と同じ研究成果をもとに開発された、軽量かつ高性能な大規模言語モデルです。
最大 128k のコンテキストウィンドウに対応しており、長文の処理にも優れています。
また、コンパクトな設計により、ローカル環境やスマートフォンなどのエッジデバイスでも
動作可能な点が特徴です。
以前私が書いた記事 で、Cloud Run 上で Ollama を用いて Gemma 2 を動かしたので、
今回はそれを利用して Cloud Run 上で Gemma 3 を試してみようと思います。
さらに、Gemma 2 と Gemma 3 の性能も比べていきます。
サンプルアプリをデプロイしてみる
まずは、以前私が書いた記事で紹介している手順でサンプルアプリを Cloud Run にデプロイしてみます。
FROM ollama/ollama
ENV HOME /root
WORKDIR /
RUN ollama serve & sleep 10 && ollama pull gemma3:4b
ENTRYPOINT ["ollama","serve"]
今回は、Dockerfile で gemma3:4b を指定してみます。
gcloud beta run deploy \
--source . \
--port 11434 \
--no-cpu-throttling \
--cpu 8 \
--memory 32Gi \
--gpu 1 \
--gpu-type=nvidia-l4 \
--no-gpu-zonal-redundancy
上記のコマンドで us-central1 にデプロイして実行してみると...
無事にサンプルアプリが起動し、画面に Ollama is running と表示されました!
FROM ollama/ollama
ENV HOME /root
WORKDIR /
RUN ollama serve & sleep 10 && ollama pull gemma3:12b
ENTRYPOINT ["ollama","serve"]
次に、 gemma3:12b も試してみましょう。
gemma3:12b は、先ほど指定した gemma3:4b よりもパラメータサイズが大きく
高性能なモデルです。
デプロイして実行してみると...
こちらも無事に実行されました!
Gemma 3 の性能を検証してみる
今回リリースされた Gemma 3 は、128k のコンテキストウィンドウを搭載しています。
以前の Gemma 2 から 16倍 に増えており、複数の文書や大規模なテキストを
1つのプロンプトで処理することができます。
そこで、Gemma 2 と Gemma 3 にテキストを入力し、
テキストに含まれるキーワードを抽出させることで、
Gemma 3 のコンテキストウィンドウの拡大・性能の向上を検証してみました。
今回検証に使用したのは以下の4パターンです。
① Gemma 2 27b(デフォルトコンテキストウィンドウ: 4,096)
② Gemma 3 12b(デフォルトコンテキストウィンドウ: 4,096)
③ Gemma 2 27b(コンテキストウィンドウ: 16,384)
④ Gemma 3 12b(コンテキストウィンドウ: 16,384)
Gemma 2 のコンテキストウィンドウの最大サイズが 8,192 トークンですが、
意図的にそれを超える値として 16,384 トークンを設定しました。
(8192 = 2^13 なので、2の次のべき乗の値として 16,384 = 2^14 としました)
作成したアプリ
GPU 搭載の Cloud Run で、
入力したテキストからキーワードを抽出させるシンプルなアプリケーションを作成しました。
ソースコード(Gemma 2 27b を使用する場合)
import requests
from fastapi import FastAPI, Request
app = FastAPI()
@app.post("/")
async def main(request: Request):
res = requests.post("http://localhost:11434/api/generate", json={
"model": "gemma2:27b",
"prompt": f"次の文章から、<>で囲まれたキーワードを抽出してください。文章の要約など、それ以外の要素は一切出力しないでください。:\n<最初のキーワード:Zenn>この文章はダミーです。文字の大きさ、量、字間、行間等を確認するために入れています。...この文章はダミーです。文字の大きさ、量、字間、行間等を確認するために入れています。<最後のキーワード:Gemma 3>",
"stream": False,
})
print(res.json())
return {"response": res.json()["response"]}
送信するプロンプトはハードコーディングしています。
テキストの最初と最後にキーワードが書かれているので、最後まで読み込むことができれば、
「Zenn」と「Gemma 3」という2つのキーワードを抽出してくれるはずです。
fastapi
uvicorn
requests
#!/bin/bash
echo "Starting ollama..."
ollama serve &
sleep 10
echo "Starting FastAPI app..."
uvicorn main:app --host 0.0.0.0 --port 8080
FROM ollama/ollama
ENV HOME /root
WORKDIR /
RUN apt-get update && apt-get install -y python3 python3-pip
RUN ollama serve & sleep 10 && ollama pull gemma2:27b
COPY app /app
WORKDIR /app
RUN pip3 install --upgrade pip && pip3 install -r requirements.txt
ENTRYPOINT []
COPY start.sh /start.sh
RUN chmod +x /start.sh
CMD ["/start.sh"]
ディレクトリ構成
root
├─ app
│ ├─ main.py
│ └─ requirements.txt
├─ start.sh
└─ Dockerfile
res = requests.post("http://localhost:11434/api/generate", json={
...
"options": {
"num_ctx": 16384
}
})
コンテキストウィンドウのサイズを指定する場合は、
リクエスト中に num_ctx パラメータを含めることで指定できます。
gcloud beta run deploy gemma2-27b-test \
--source . \
--region us-central1 \
--port 8080 \
--no-cpu-throttling \
--cpu 8 \
--memory 32Gi \
--gpu 1 \
--gpu-type=nvidia-l4 \
--no-gpu-zonal-redundancy \
--timeout=900
ルートディレクトリで上記のコマンドを実行してアプリをデプロイして...
curl -X POST <Cloud Run のエンドポイントURL>/
上記のコマンドでアプリにアクセスし、結果を待ちます。
検証結果
① Gemma 2 27b(デフォルトコンテキストウィンドウ: 4,096)
レスポンス:
{"response":"この文章は、単に「ダミー」という言葉を繰り返すだけのものです。 \n\n具体的な内容や目的がないため、どのような分析や応用が可能なのか判断できません。\n\nもし、この文章を元に何かを作成したり、分析を行いたい場合は、以下の情報が必要です。\n\n* この文章の目的は何ですか?\n* どのような読者層を想定していますか?\n* 文章全体で伝えたいメッセージは何ですか?\n\n\nこれらの情報を提供していただければ、より適切なアドバイスをすることができます。"}
キーワードを抽出するどころか、想定していないレスポンスが返ってきてしまいました。
何が起こっているのか、Cloud Run のログを確認してみましょう。

このログからは、Gemma 2 27b モデルのサイズが約 14.55 GiB であることが分かります。

モデルの処理に GPU だけでなく CPU も 41 MiB ほど使用されています。

このログを見ると、入力トークンの上限が 4,096 トークンであるのに対し、
実際に入力されたプロンプトが 8,765 トークンであるため、
プロンプトの一部が切り捨てられていることが分かります。
想定通りのレスポンスが返って来なかったのは、これが原因かもしれません。
② Gemma 3 12b(デフォルトコンテキストウィンドウ: 4,096)
レスポンス:
{"response":"このテキストは、大量の繰り返しを含んだテキストです。目的が不明ですが、おそらく何らかのテスト、検証、または機械学習モデルの訓練データの一部と考えられます。\n\n**テキストの分析:**\n\n* **単調性:** 同じフレーズ(\"この文章はダミー です。\")が何度も繰り返されています。\n* **目的の不明確さ:** テキスト自体の意味はほとんどありません。\n* **可能性のある用途:**\n * **ストレス/負荷テスト:** テキスト処理システムやフォントレンダリングシステムが大量の繰り返しを含むテキスト を処理できるかをテストするために使用される可能性があります。\n * **機械学習のデータ拡張:** 繰り返しを増やすことで、機械学習モデルの訓練データセットを拡張できる可能性があります。\n * **エラー誘発:** 特定のフォントや表示設定でエラーを引 き起こすために意図的に作成された可能性があります。\n\n**テキストの内容に関する考察:**\n\nこのテキストは、実際の人間が書いたものではなく、プログラムによって生成されたものである可能性が非常に高いです。 テキストの目的が不明なため、解釈の幅は広くなります。\n\nもしこのテキストの意図やコンテキストが分かれば、より詳細な分析が可能です。例えば、このテキストが特定の機械学習モデルの訓練に使用されている場合、モデルの種類や学習タスクを考慮して分析することができます。"}
①よりも丁寧で詳しい内容ではありますが、こちらもキーワードを抽出してくれませんでした。
こちらも Cloud Run のログを確認してみましょう。
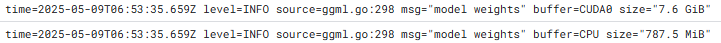
このログからは、Gemma 3 12b モデルのサイズが約 7.6 GiB であることが分かります。
Gemma 2 27b と比べて半分近いサイズです。
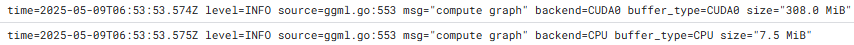
この場合も、モデルの処理に GPU だけでなく CPU も 7.5 MiB ほど使用されています。

こちらのパターンでもコンテキストウィンドウのサイズはデフォルトの 4,096 トークンであるため、
プロンプトの一部が切り捨てられていることが分かります。
③ Gemma 2 27b(コンテキストウィンドウ: 16,384)
レスポンス:
{"response":"<Zenn>"}
おっ!
最初のキーワードを抽出してくれました。

コンテキストウィンドウのサイズを拡大したため、CPU が 73 MiB 使われていたようです。
デフォルトのコンテキストウィンドウの場合と比べるとかなり使用されています。
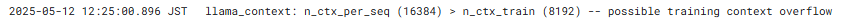
ログを見ると、指定したコンテキストウィンドウのサイズが Gemma 2 の上限である 8,192 を
超えているために警告が出ています。
プロンプトは 8,765 トークンあるため、プロンプトの終盤の部分が切り捨てられ、
最後のキーワードが抽出できなかったと考えられます。
④ Gemma 3 12b(コンテキストウィンドウ: 16,384)
レスポンス:
{"response":"Zenn\nGemma 3"}
おっ!?
最初と最後のキーワードを両方抽出してくれました。
ログを確認すると、入力トークン数に関する警告は出ていませんでした。
入力されたプロンプトが 8,766 トークンであるのに対し、
コンテキストウィンドウの上限を 16,384 トークンに設定していたため、
プロンプトが最後まで問題なく処理されたといえるでしょう。
まとめ
Gemma 2(27b)と Gemma 3(12b)をそれぞれ異なるコンテキストウィンドウサイズで
使用し、テキストに含まれるキーワードを抽出させることで、
Gemma 3 のコンテキストウィンドウの拡大・性能の向上を検証してみました。
検証パターンと結果は以下の通りです。
① Gemma 2 27b(デフォルトコンテキストウィンドウ: 4,096)
→ プロンプトの一部が切り捨てられ、キーワード抽出失敗。
② Gemma 3 12b(デフォルトコンテキストウィンドウ: 4,096)
→ 同様に失敗。
③ Gemma 2 27b(コンテキストウィンドウ: 16,384)
→ コンテキストウィンドウが上限より大きかったが、最初のキーワードのみ抽出成功。
④ Gemma 3 12b(コンテキストウィンドウ: 16,384)
→ 最初と最後のキーワードを抽出成功。
この結果から、Gemma 3 ではコンテキストウィンドウのサイズの上限が拡大され、
よりサイズの大きい入力に対応できるようなったという点で、
性能が向上したことが確認できました。
おわりに
本記事では、Gemma 3 のサンプルアプリケーションを Cloud Run にデプロイしました。
また、簡単なキーワード抽出アプリケーションを作成し、
入力されたテキストに含まれるキーワードを抽出させることで、
Gemma 3 のコンテキストウィンドウの拡大・性能の向上を確認しました。
これからさらにマルチモーダルな活用に対応したアプリケーションが
発展していくことを考えると、よりサイズの大きい入力に対応した Gemma 3 の可能性は
非常に大きいと感じました。
引き続き、さまざまな使い方を試していきたいと思います!
Discussion