BigQuery の取り込み時間パーティショニングのテーブルを日本時間でフィルタクエリする方法まとめ
こんにちは。
クラウドエース株式会社 第一開発部の髙木です。
私が入社してから半年が経ちました。オンボーディングで様々な Google Cloud のサービスに触り、苦労しながら知識を吸収してきました。
オンボーディング課題をこなしていく中で、仕様に悩まされた機能の 1 つである BigQuery のパーティショニングについて執筆します。
はじめに
BigQuery のパーティションは、特定の順序データに基づいてテーブルを(内部的に)分割する機能です。現在、パーティションとして指定できる順序データは日時か整数のみです。
この分割により、フィルタクエリを実行したときのスキャンするデータ量を減らすことができます。
パーティショニングは「取り込み時間による分割」と「フィールドによる分割」の 2 種類あります。
「フィールドによる分割」はあらかじめ指定した列をパーティションとする方法です。取り扱うデータに順序データがある場合に有効です。
「取り込み時間による分割」はテーブルにデータをロードする日時をパーティションとする方法です。パーティションを取り込み時間にしたい場合や取り扱うデータに順序データがない場合に有効です。
一般的に、ほとんどのデータにはデータの発生時刻や記録時刻を表すカラムがあるため、そのカラムを指定した「フィールドによる分割」を使うことになると思います。今回は「取り込み時間による分割」に着目します。
パーティショニングに「取り込み時間による分割」を選択した場合、BigQuery へ記録される取り込み時間が UTC のタイムゾーンになるため、JST の日時指定のフィルタクエリが正確にできていない可能性があります。
「いやいや、クエリ時にタイムゾーンを変更すればできるでしょ」と思う方もいらっしゃるかもしれません。しかし、大抵の場合はそんなに単純なことではなく、タイムゾーンを変更できていない可能性があります。
本記事では、パーティショニングを「取り込み時間による分割」とした場合の、タイムゾーンを変更できないパターン及びその理由と、日本標準時(以下、JST )でフィルタクエリする方法を 2 つ紹介します。
タイムゾーンを変更できないパターン及びその理由
先に結論から申し上げると、パーティショニングタイプが「1 日ごと」、「1 か月ごと」、「1 年ごと」ではタイムゾーンの変更ができません。
その理由を解説していきます。
解説
タイムゾーン
タイムゾーンの変更とは、ある地域の時刻を基準時間が異なる他の地域の時刻にすることです。基準時刻が異なるのは時差による影響です。例えば日本であれば JST が基準時間であり、世界協定時(以下、UTC )との差は +9 時間です。

BigQuery では DATE(timestamp, time_zone) や DATETIME(timestamp, time_zone) などのクエリを利用すればタイムゾーンを変更できます。
TIMESTAMP 型と DATETIME 型
パーティションの話に入る前にデータ型の話をします。こちらの記事を参照しました。
TIMESTAMP 型と DATETIME 型はどちらも日時を表すデータ型ですが、違いがあります。
TIMESTAMP 型はタイムゾーンが指定された日時のデータ型です。
BigQuery のデフォルトのタイムゾーンが UTC のため、TIMESTAMP 型でデータロードすると日付が UTC として格納されます。JST でデータロードしたい場合は、ロード前に日付に 9 時間足す変換をしなければなりません。
ロード前の変換に労力はかかるものの、複数のタイムゾーンでデータを取り扱うときに有効となる型です。
DATETIME 型はタイムゾーンの指定がない日時のデータ型です。
タイムゾーンの指定がないため、タイムゾーンの変更ができません。単一のタイムゾーンでデータを取り扱うときに有効となる型です。
取り込み時間パーティションの値
BigQuery の取り込み時間パーティショニングのテーブルを作成すると、_PARTITIONTIME というパーティション時間を表す擬似的な列が作成されます。詳しくは公式ドキュメントをご覧ください。
このとき、_PARTITIONTIME はUTC のロードした時間を、指定されたパーティショニングタイプを基準に切り捨てた TIMESTAMP 型の値になります。
「ちょっと何を言っているかわからない」と感じるかもしれませんが、きちんと説明するので安心してください。
例としてパーティショニングタイプが 1 日ごとの場合を考えます。このときパーティションは時間・分・秒の情報が削ぎ落とされます。つまり、パーティション列の日時が日単位で切り捨てられます。
日本で 2024/10/07 12時 に パーティションテーブルへデータロードしたとします。このとき、_PARTITIONTIME は
- UTC の時刻(2024/10/07 3時)
- 日単位で切り捨て(2024/10/07 0時)
- TIMESTAMP 型(2024-10-07 00:00:00 UTC)
と変換され、最終的には 2024-10-07 00:00:00 UTC になります。
ロードする時間によって、この変換の際にタイムゾーンの不都合が生じます。
例えば、2024/10/07 12:00 (JST) は 2024/10/07 03:00 (UTC) ですので、日時を日単位で切り捨てるとどちらも 2024/10/07 です。
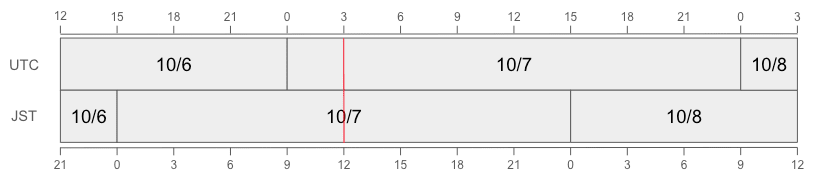
しかし、2024/10/07 06:00 (JST) は 2024/10/06 21:00 (UTC) ですので、日時を日単位で切り捨てると JST では 2024/10/07、UTC では 2024/10/06 となります。

これらのことから、UTC と JST で日が異なる時間帯(日本時間で 0:00 から 9:00 まで)は異なるパーティションになると結論づけられます。
また、日時を日単位で切り捨てた後にタイムゾーンの変更を行なっても、タイムゾーンが反映された日時にはなりません。
パーティショニングタイプが「1 日ごと」の場合を見てきましたが、「1 か月ごと」、「1 年ごと」も同様に、異なるパーティションとなる時間帯があると言えます。
検証
実際に「TIMESTAMP 型と DATETIME 型の違い」と「取り込み時間パーティションの値」について、データロードとクエリをして確かめます。
検証方法
- ロードするテーブルは以下のクエリで作成します。ロードするファイルの時刻データを TIMESTAMP 型と DATETIME 型の列それぞれで受け取ります。
CREATE OR REPLACE TABLE
`partition_test.test1` (
row_id INT64,
string_val STRING,
datetime_val DATETIME,
timestamp_val TIMESTAMP
)
PARTITION BY
DATE(_PARTITIONTIME);
- ロードするファイルは、作成日時の列が 2 つある CSV ファイルです。これらの列の時刻とロードする時刻を近づけるため、CSV ファイルはコマンドで作成します。
- 1つ目のレコードは作成日時を JST で、2つ目のレコードは作成日時を UTC でロードしています。
- 時間をずらして CSV ファイルを 2 回ロードします。
| row_id | string_val | datetime_val | timestamp_val |
|---|---|---|---|
| 1 | JST | 2024-10-21 09:00:00 | 2024-10-21 09:00:00 |
| 2 | UTC | 2024-10-21 00:00:00 | 2024-10-21 00:00:00 |
cat << _EOD_ > $temp_file
1,"JST",$(date +"%Y-%m-%d %H:%M:%S"),$(date +"%Y-%m-%d %H:%M:%S")
2,"UTC",$(date -u +"%Y-%m-%d %H:%M:%S"),$(date -u +"%Y-%m-%d %H:%M:%S")
_EOD_
- ロードは以下の bq コマンドを使用します。
bq load --source_format=CSV 'partition_test.test1' $temp_file
結果
結果は以下の図のようになりました。
2024/10/21 08:19:11 (JST) にロードしたデータが 1 行目と 2 行目です。2024/10/21 09:45:49 (JST) にロードしたデータが 3 行目と 4 行目です。
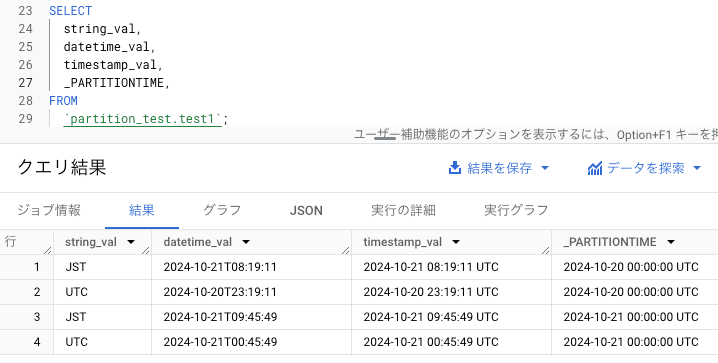
TIMESTAMP 型と DATETIME 型の違い
datetime_val は、タイムゾーンが指定されていません。timestamp_val は、タイムゾーンが UTC に指定されています。例えば、2 行目のように UTC に変換したデータなら timestamp_val は正確な値になりますが、1 行目のように JST のままデータを取り込んだ場合は timestamp_val が 9 時間先の値になってしまいます。
取り込み時間パーティションの値
全てのレコードは 2024/10/21 (JST) に取り込まれていますが、_PARTITIONTIME の日付部分が 2024/10/20 となっているレコードもあります。これより、_PARTITIONTIME は UTC でロードされていることがわかります。
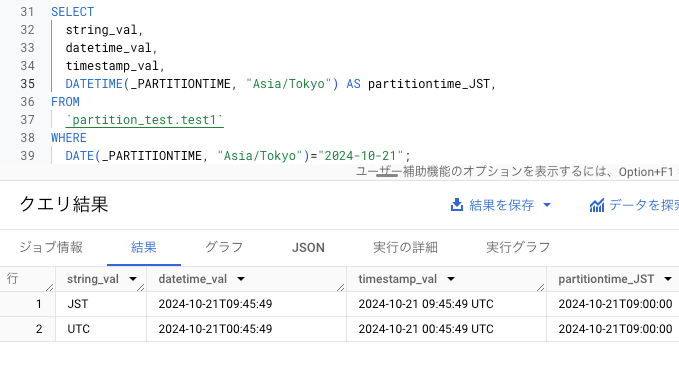
ここで、ロードした日付が 2024/10/21 (JST) であるものを取り出してみます。
取り込み時間パーティション _PARTITIONTIME を JST に変更した値を "2024-10-21" と指定したフィルタクエリを実行すると、上図のようにクエリ結果のレコードが 2 つ(JST で 9 時より前にロードしたデータ)しかありません。
クエリ結果の partitiontime_JST をご覧ください。_PARTITIONTIME に対してタイムゾーン変更を施すと、"2024-10-21T09:00:00" のような値になります。これはパーティション時間が日単位で切り捨てられた上で 9 時間足されていることが原因です。そのため、正確なタイムゾーンの変更はできていません。
JST でフィルタクエリする方法
UTC 以外のタイムゾーンに基づいてフィルタクエリする方法は公式ドキュメントに載っていますが、これを安直に(例えば DATE(_PARTITIONTIME, "Asia/Tokyo")="2024-10-21" など)実装しても正しい結果にならない可能性があります。
以下 2 つの方法を、メリット・デメリットも併せてご紹介いたします。
- パーティショニングタイプを 1 時間ごとにしてテーブルを作成する。
- パーティション時間を指定してロードする。
1. パーティショニングタイプを 1 時間ごとにしてテーブルを作成する。
公式ドキュメントには「SQL クエリのタイムゾーンの違いを調整する。」と載っていますが、これだけでは先ほど検証したタイムゾーンを変更できない問題に直面します。
これはパーティショニングタイプを 1 時間ごとにすることで解決できます。UTC と JST の差が 9 時間なので、1 時間ごとのパーティションでは、分や秒の情報が省略されても問題ありません。
フィルタクエリした結果が以下の図になります。レコード 4 つともpartitiontime_JST の日付が 2024/10/21 と一致しています。
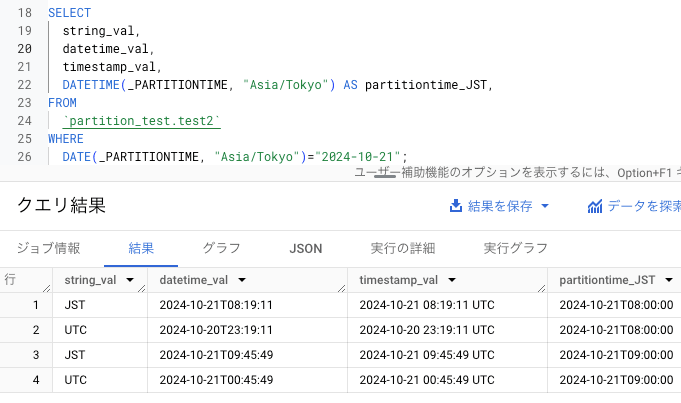
また、1 時間単位のフィルタクエリをしても正確な結果が得られます。
この方法には以下のメリットがあります。
-
_PARTITIONTIMEが正確に UTC の時刻を表しているため、他のタイムゾーンへ変更できます。(ただし、時差が 30 分含まれるタイムゾーンなど、一部のタイムゾーンには適用できません。)
デメリットは以下のとおりです。
- 日本時間でクエリするときは毎回タイムゾーンを変更するクエリ構文を使う必要があります。
- パーティションが多くなりやすいため、テーブルあたりのパーティション数の上限に達する可能性があります。
2. パーティション時間を指定してロードする。
もう一つはパーティション デコレータを使用してデータロードする方法です。
パーティション デコレータは、「テーブル」と「そのテーブル内のパーティション」の両方を参照する表現方法です。パーティション デコレータを使用すると、任意のパーティションを指定してロードすることができます。
bq コマンドでパーティション デコレータを取り込み時間(JST)に指定する方法は以下のとおりです。
destination='partition_test.test3$'$(date +"%Y%m%d")
bq load --source_format=CSV $destination $temp_file
下図はフィルタクエリした結果です。パーティションを指定しているため、タイムゾーンの変更はしていません。なお、テーブルのパーティショニングタイプは 1 日ごとにしています。
レコード 4 つとも_PARTITIONTIME の日付が 2024/10/21 と一致しています。
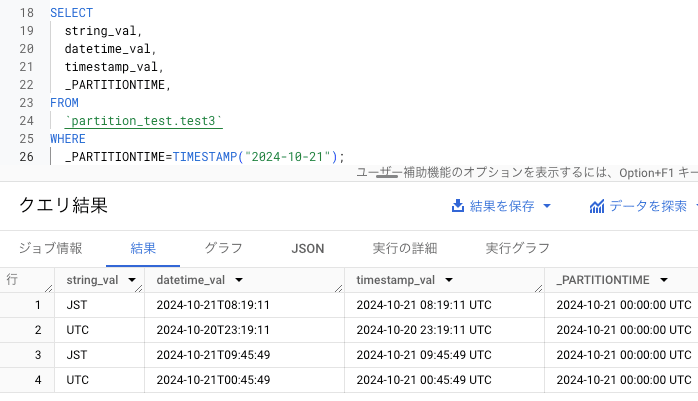
この方法は以下のメリットがあります。
- タイムゾーンを変更するクエリ構文を使わなくて済みます。
デメリットは以下のとおりです。
- ロード設定が少し複雑になります。
- 他のタイムゾーンに変更できません。
おわりに
本記事では BigQuery の取り込み時間パーティショニングのテーブルを日本時間でフィルタクエリする方法を 2 つ紹介しました。
1 つ目はパーティショニングタイプを 1 時間ごとにする方法で、2 つ目はパーティション デコレータを使う方法でした。どちらもメリットデメリットがあり、使い分けが必要です。
Google Cloud のプロダクト・サービスは使いやすいですが、中には仕様が複雑で理解しにくい機能もあることに気づきました。
これからもこのような難しい機能に触れ、Google Cloud を使いこなせるようにしていきたいと思います。
Discussion