Document AI と BigQuery を活用して請求書データを効率的に構造化してみた
初めに
こんにちは、クラウドエース 第三開発部の王です。
デジタル化が進む現代、企業や組織では注文書、納品書、請求書などのビジネス文書(PDF、Word、Excel など。以降、ドキュメントデータと呼びます)が日々大量に生成されています。これらのデータには貴重な価値が含まれており、適切に分析することで有益なインサイトを得ることができます。しかし、データの整理や解析に多くの時間と手間がかかり、より効率的なソリューションが求められています。
Google Cloud は BigQuery と Document AI の統合を提供しており、これによりドキュメントデータの解析が大幅に簡素化されました。本記事では、BigQuery と Document AI を活用し、ドキュメントデータの効率的な構造化方法をご紹介します。具体的には、作成した Document AI プロセッサを BigQuery に登録し、実際に活用する方法を説明します。
Document AI プロセッサの作成
Document AI は、ドキュメント処理と解釈のプラットフォームであり、ドキュメントから非構造化データを取得して構造化データに変換し、解釈、分析、利用を容易にします。
Document AI プロセッサ は、ドキュメントファイルと、ドキュメント処理と解釈アクションを実行する ML モデルの間にあります。ドキュメントの分類、分割、解析、分析に使用できます。
プロセッサは以下のいずれかのカテゴリに分類されます。
- 文書のデジタル化: OCR(光学文字認識)
- 抽出: カスタムエクストラクタ、フォームパーサー、レイアウトパーサー、事前構築済みパーサー
- 分類: カスタム分類器、カスタムスプリッター
カスタムプロセッサを構築することも可能ですが、Document AI にはすぐに利用できる事前構築済みプロセッサが用意されており、請求書、領収書、税務フォームなど、さまざまなシナリオに対応しています。
今回は、非構造化の請求書ファイルから構造化データを抽出するため、プロセッサギャラリーから事前に構築済みの「Invoice Parser」を選択して作成します。
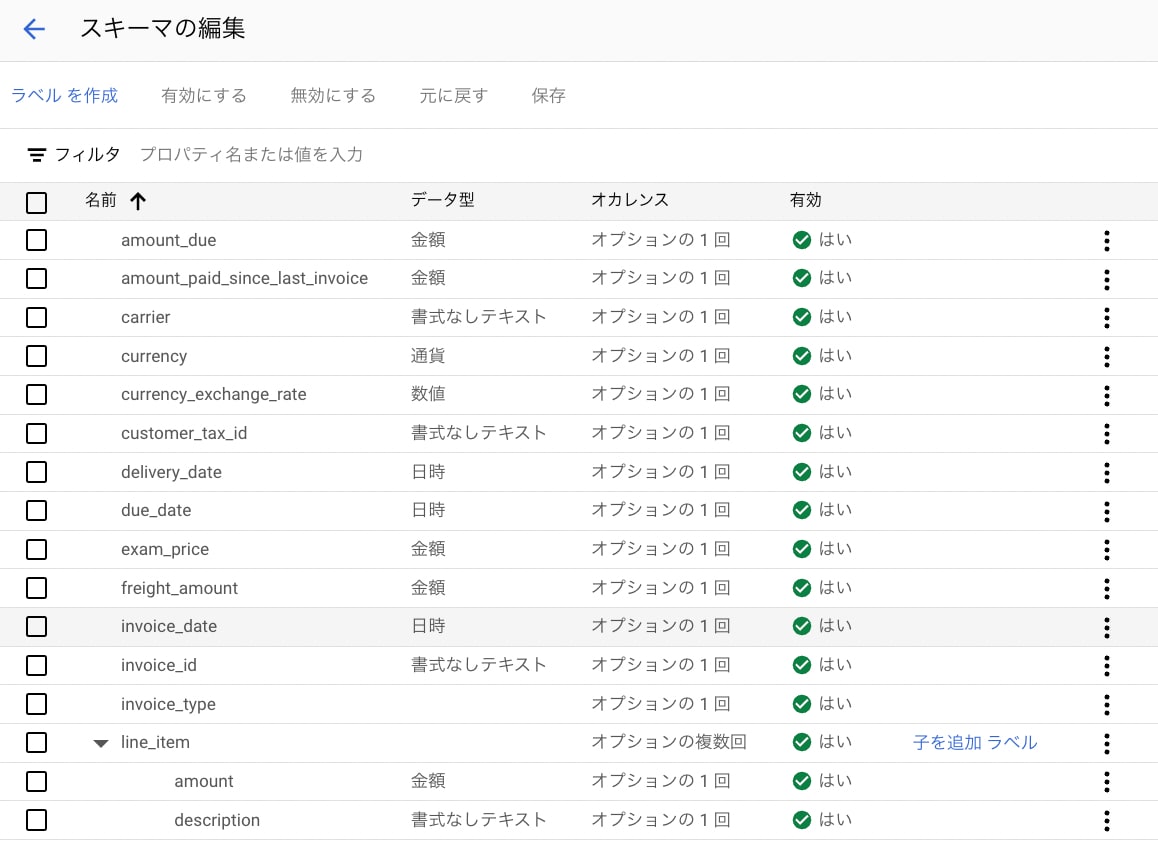
また、事前構築済みプロセッサには既存のスキーマが定義されていますが、これを編集することも可能です。スキーマの編集は、作成したプロセッサを開き、「トレーニング」タブをクリックし、「スキーマの編集」ボタンを選択することで行えます。
BigQuery で Document AI を利用する
1.外部接続の作成
BigQuery では、接続 で BigQuery の外部に保存されているデータをクエリできます。
外部データソースに対して、さまざまな接続タイプが提供されますが、今回、Document AI プロセッサと Cloud Storage バケットのデータにアクセスするために、Google Cloud リソース接続 の作成が必要です。
以下のコマンドを利用して、Google Cloud リソース接続を作成できます。
# `CONNECTION_ID` は任意の識別名を設定してください
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connection_type=CLOUD_RESOURCE ${CONNECTION_ID}
接続リソースを作成すると、BigQuery は、一意のシステムサービスアカウントを作成し、それを接続に関連付けます。
以下のコマンドで、作成した接続リソースの詳細を確認できます。
bq show --connection ${PROJECT_ID}.${REGION}.${CONNECTION_ID}
作成した接続リソースを通じて Document AI プロセッサと Cloud Storage バケットにアクセスするため、接続リソースのサービスアカウントに必要な権限を付与します。
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member='serviceAccount:${MEMBER}' --role='roles/documentai.viewer'
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member='serviceAccount:${MEMBER}' --role='roles/storage.objectViewer'
2.BigQuery に Document AI プロセッサを登録
BigQuery では、外部の機械学習モデルをリモートモデルとして登録することで、SQL クエリから直接利用できます。
今回、Document AI のプロセッサをリモートモデルとして登録し、BigQuery からドキュメント解析を実行できるようにします。
※ データセットがまだ無い場合は、事前に作成してください。
BigQuery で以下のクエリを実行して、プロセッサを登録します。
CREATE OR REPLACE MODEL `${DATASET_NAME}.${MODEL_NAME}` -- `MODEL_NAME` には任意の識別名を設定してください
REMOTE WITH CONNECTION `${PROJECT_ID}.${REGION}.${CONNECTION_ID}` -- `CONNECTION_ID` には作成済みの接続リソース ID を指定してください
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='${PROCESSOR_ID}' -- `PROCESSOR_ID` には作成済みのプロセッサ ID を指定してください
);
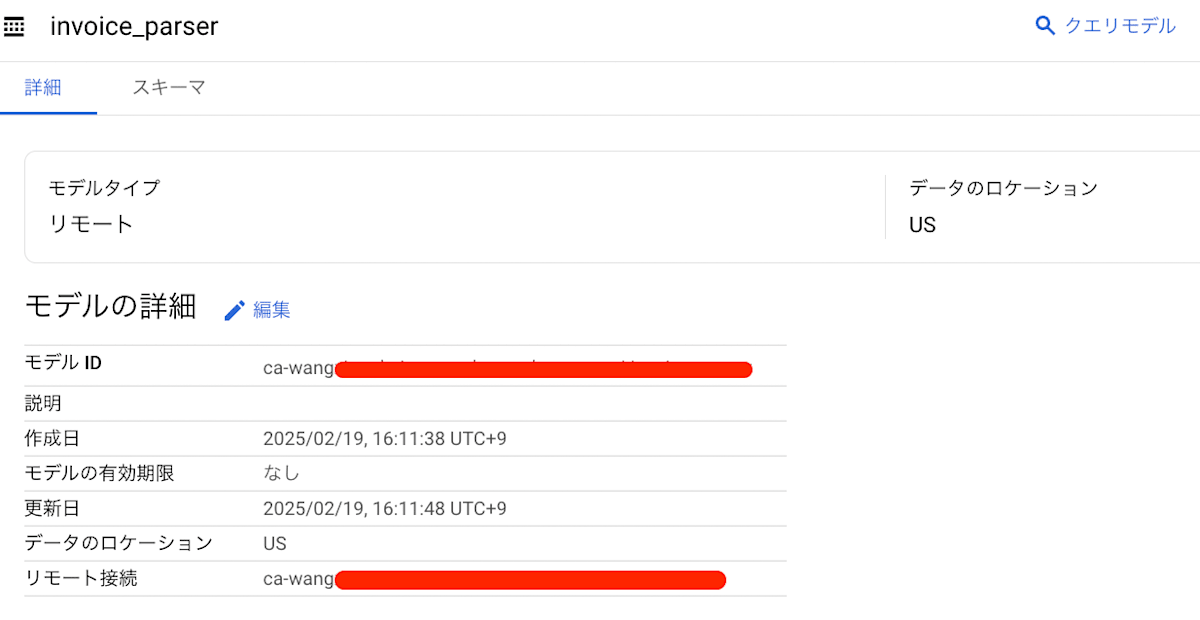
登録が完了すると、モデル一覧にリモートモデルが表示されます。クリックすると、以下のような情報を確認できます。
これで、BigQuery から Document AI プロセッサを呼び出し、ドキュメントのデータ抽出を SQL で実行できるようになります。
3.オブジェクトテーブルを作成する
BigQuery の オブジェクトテーブル は、Cloud Storage 内にある非構造化データオブジェクトの読み取り専用テーブルです。これにより、BigQuery から Cloud Storage 上のドキュメントに直接アクセスし、データの処理や分析を行えます。
最初に、処理対象のドキュメントを保存するための Cloud Storage バケットを準備します。もし事前にバケットが作成されていない場合は、以下のコマンドを実行して新たに作成してください。作成後、処理したい請求書ファイルをアップロードすることができます。
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
次に、BigQuery で以下のクエリを実行して、オブジェクトテーブルを作成します。
CREATE OR REPLACE EXTERNAL TABLE `${DATASET_NAME}.${TABLE_NAME}` -- `TABLE_NAME` には任意の識別名を設定してください
WITH CONNECTION `${PROJECT_ID}.${REGION}.${CONNECTION_ID}` -- `CONNECTION_ID` には作成済みの接続リソース ID を指定してください
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://${BUCKET_NAME}/*'], -- `BUCKET_NAME` には作成済みのバケットを指定してください
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
作成されたオブジェクトテーブルのデータは、各オブジェクト(ファイル)ごとに 1 行として登録され、以下のようなスキーマで表示されます。このスキーマには、Cloud Storage に保存された非構造化データのメタデータ情報が含まれます。

4.ドキュメントデータの抽出
次に、登録したリモートモデルを使用して、以下のクエリを実行し、Cloud Storage に保存されたファイルから情報を抽出します。
SELECT *
FROM ML.PROCESS_DOCUMENT(
MODEL `${DATASET_NAME}.${MODEL_NAME}`,
TABLE `${DATASET_NAME}.${TABLE_NAME}`
);
このクエリにより、オブジェクトテーブルが含まれる行だけでなく、モデルで定義されたスキーマに基づいたデータも抽出されます。
このデータを利用して、他のデータと突合し、会社にとって有益な洞察を得ることができます。

最後に
本記事では、非構造化の請求書データから構造化データを抽出するために、BigQuery と Document AI を活用する方法を紹介しました。このプロセスを通じて、効率的にデータを構造化し、ビジネスに役立つインサイトを得ることができます。ぜひ、皆さんも実際に試してみてください。
Discussion