BigQuery のテーブル定義書を自動生成してみた
はじめに
こんにちは、クラウドエース データソリューション部所属の木村です。
BigQuery でテーブルスキーマの変更や新しいテーブルの追加を行うたびに、ドキュメントの更新作業にうんざりした経験はありませんか?手動での更新は時間もかかり、ミスも起きやすいです。「これが自動でできたら楽なのに」と思ったことは、私だけではないはずです。
そこで、今回の記事では、BigQuery のデータセットからテーブル定義書を自動生成する方法をご紹介します。
なお、本記事のサンプルコードは、こちらの GitHub リポジトリに公開しています。
全体像
データ処理の流れです。
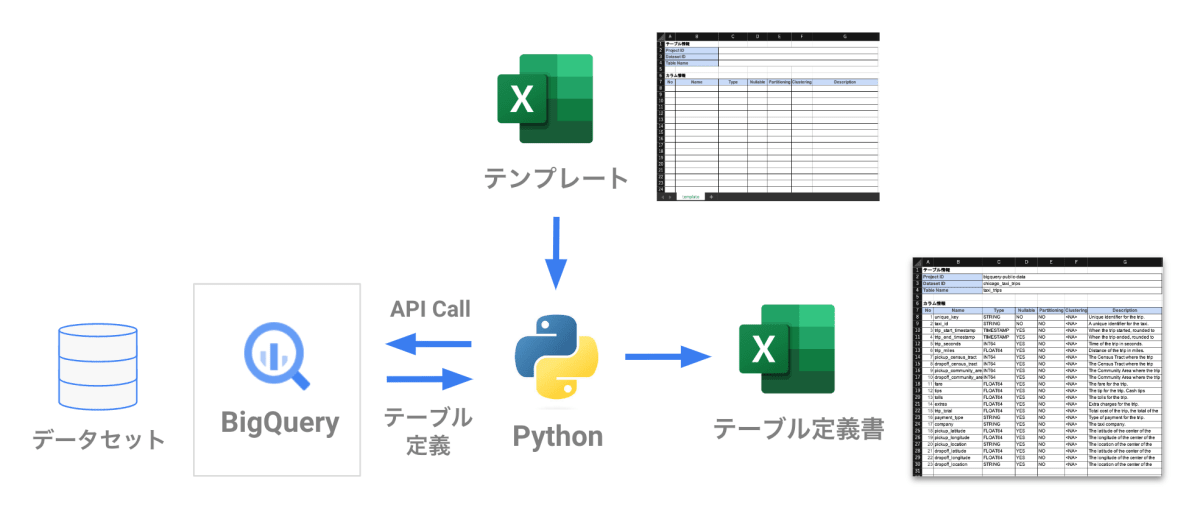
BigQuery の Python 用クライアントライブラリ を使って、対象のデータセットからテーブルやカラムのスキーマ情報(メタデータ)を抽出します。その後、テーブル定義書のテンプレートに合わせてデータを整形し、エクセルに出力します。
下図は、テーブル定義書のアウトプットイメージです。テーブルごとに、シートが分かれています。
環境準備
今回は、面倒な環境構築は不要で Python ノートブック環境が利用できる BigQuery Studio を利用します。
BigQuery Studio については、こちらの記事で紹介しています。
BigQuery Studio の準備
BigQuery のコンソールを開いて、スタートページ画面から「PYTHON ノートブックを作成」をクリックします。
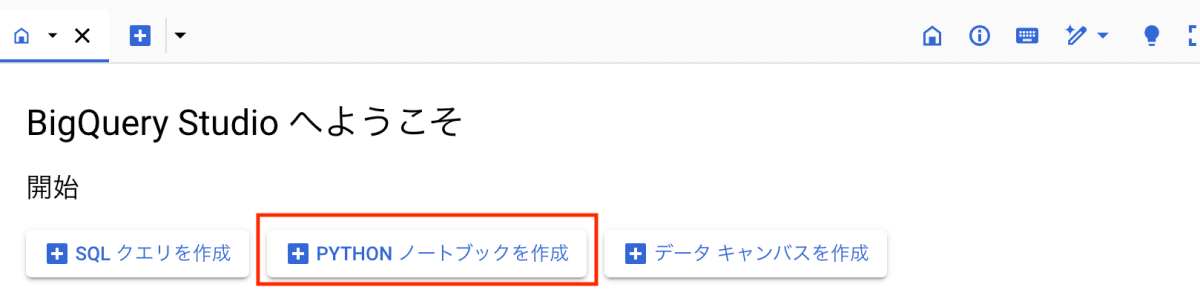
ノートブックを作成すると、既にデモ用のサンプルコードが用意されていますが、こちらのセルは使用しないため、削除していただいて問題ありません。
「接続」を押して、新しいランタイムに接続します。
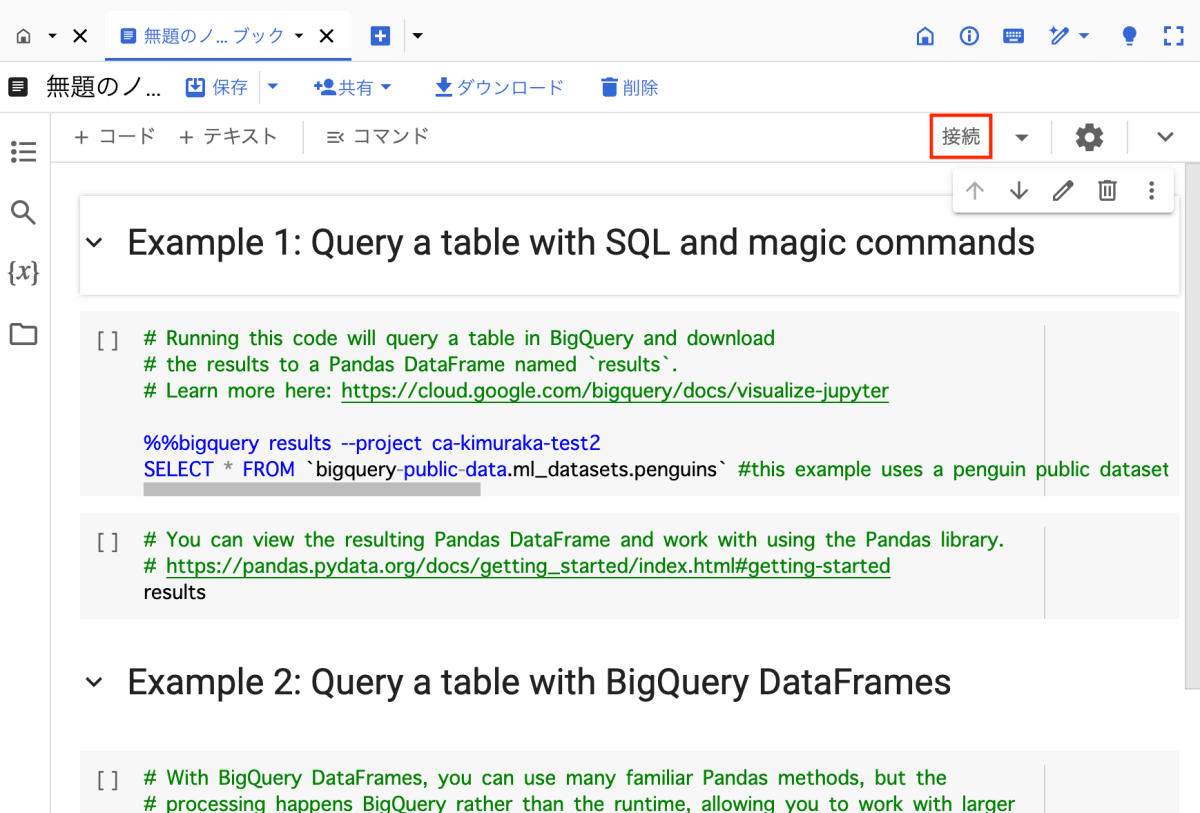
これにて実行環境の構築は終わりです。追加のライブラリインストールも必要ありませんでした。お手軽ですね!
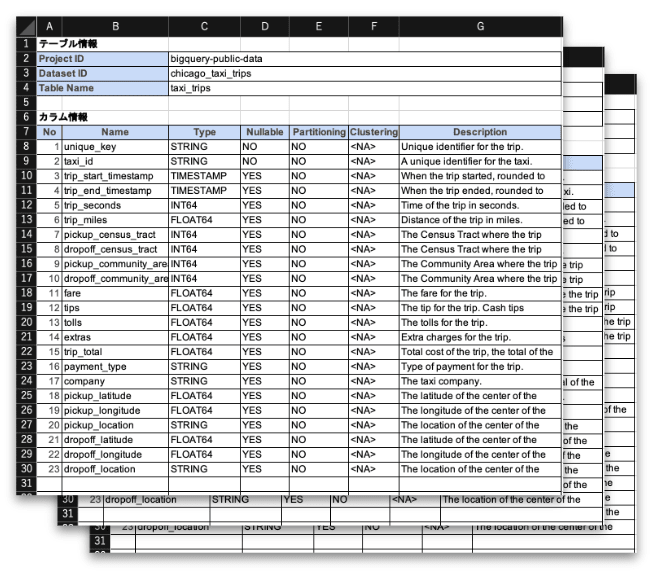
テーブル定義書のテンプレートを用意
次に、テーブル定義書のテンプレートファイルを用意します。
今回は、こちらのエクセルファイル table_template.xlsx を使用します。
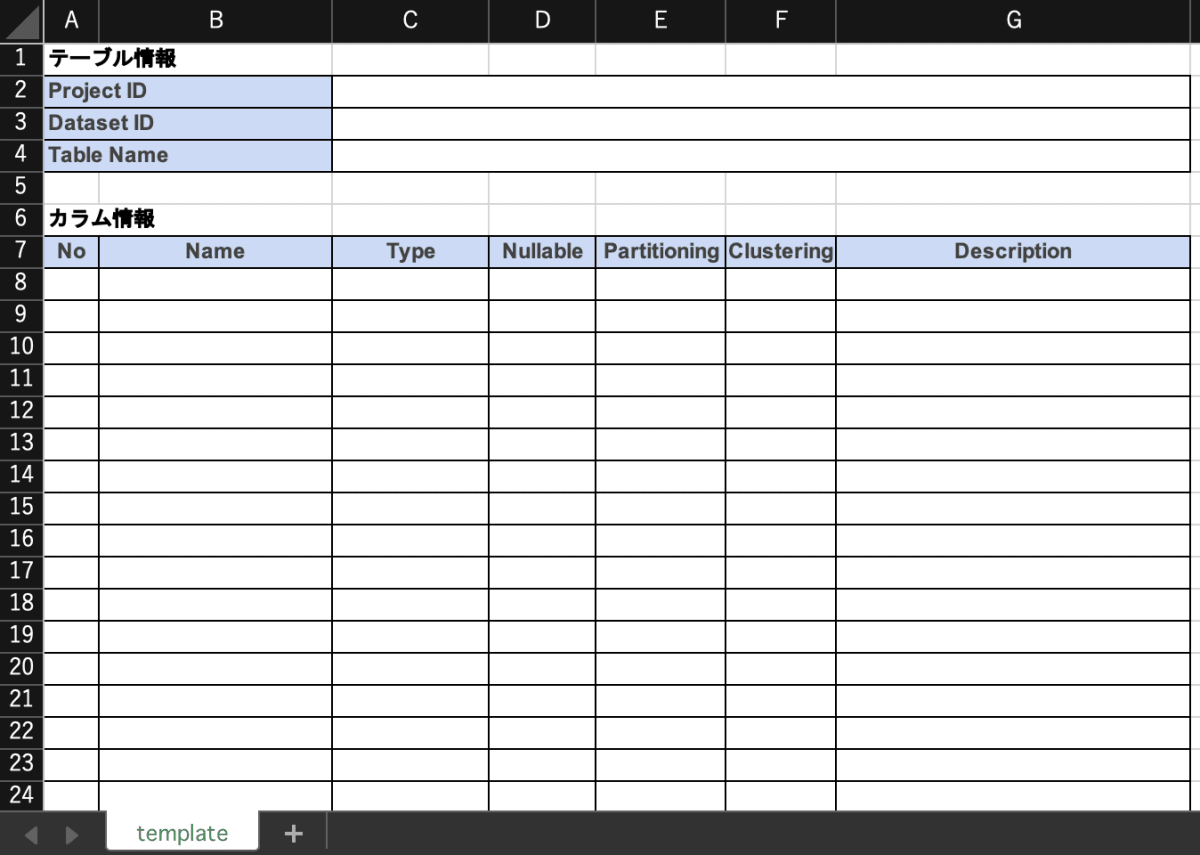
テーブル定義書のテンプレート
テーブル定義書に記載するカラム(列)のメタデータは、以下としました。
| 項目 | 説明 |
|---|---|
| No | テーブル内の列の 1 から始まるオフセット |
| Name | 列の名前 |
| Type | 列の GoogleSQL データ型 |
| Nullable | YES または NO(列のモードが NULL 値を許可するかどうか) |
| Partitioning | YES または NO(列がパーティショニング列かどうか) |
| Clustering | テーブルのクラスタリング列内の列の 1 から始まるオフセット |
| Description | 列の説明 |
対象のデータセット
本来であれば、自前のデータセットを準備するのですが、今回は手順の紹介ということで、Google が提供している一般公開データセットを使います。
下記のデータセットを対象に、テーブル定義書の自動生成を試してみます。
こちらは、米国シカゴ市のタクシー利用に関するデータセットです。
テーブルは1つですが、カラムの説明(Description)があります。
テーブル定義書の自動生成
BigQuery Studio のノートブックで、下記のコードを実行していきます。
BigQuery のテーブル定義を抽出
最初に、モジュールをインポートし、対象となるデータセットを設定します。
import pandas as pd
from google.cloud import bigquery
# 対象データセットの設定
PROJECT_ID = "bigquery-public-data"
DATASET_ID = "chicago_taxi_trips"
# BigQueryクライアントのインスタンスを生成
client = bigquery.Client()
次に、テーブル定義書に必要なメタデータを、INFORMATION_SCHEMA ビューから取得していきます。
INFORMATION_SCHEMA の概要については、こちらの公式ドキュメントをご覧ください。
BigQuery INFORMATION_SCHEMA ビューは、BigQuery オブジェクトに関するメタデータ情報を提供するシステム定義の読み取り専用ビューです。次の表は、メタデータ情報を取得するためにクエリできるすべての INFORMATION_SCHEMA ビューを示しています。
カラムに関するメタデータを取得したいので、
INFORMATION_SCHEMA.COLUMNS と INFORMATION_SCHEMA.COLUMN_FIELD_PATHS を使用します。
INFORMATION_SCHEMA.COLUMNS で取得できるメタデータ
INFORMATION_SCHEMA.COLUMNSビュー では、カラム名やデータ型などのメタデータを取得できます。
今回は、太字箇所のメタデータを使用します。
INFORMATION_SCHEMA.COLUMNSのスキーマは次のとおりです。
| 列名 | データ型 | 値 |
|---|---|---|
| TABLE_CATALOG | STRING | データセットを含むプロジェクトのプロジェクトID |
| TABLE_SCHEMA | STRING | datasetId とも呼ばれる、テーブルを含むデータセットの名前 |
| TABLE_NAME | STRING | テーブルまたはビューの名前(tableId とも呼ばれる) |
| COLUMN_NAME | STRING | 列の名前 |
| ORDINAL_POSITION | INT64 | テーブル内の列の 1 から始まるオフセット。_PARTITIONTIME や _PARTITIONDATE などの疑似列の場合、値は NULL |
| IS_NULLABLE | STRING | YES または NO(列のモードが NULL 値を許可するかどうかによる) |
| DATA_TYPE | STRING | 列の GoogleSQL データ型 |
| IS_GENERATED | STRING | 値は常に NEVER |
| GENERATION_EXPRESSION | STRING | 値は常に NULL |
| IS_STORED | STRING | 値は常に NULL |
| IS_HIDDEN | STRING | YES または NO(列が _PARTITIONTIME や _PARTITIONDATE などの疑似列であるかどうかによる) |
| IS_UPDATABLE | STRING | 値は常に NULL |
| IS_SYSTEM_DEFINED | STRING | YES または NO(列が _PARTITIONTIME や _PARTITIONDATE などの疑似列であるかどうかによる) |
| IS_PARTITIONING_COLUMN | STRING | YES または NO(列がパーティショニング列かどうかによる) |
| CLUSTERING_ORDINAL_POSITION | INT64 | テーブルのクラスタリング列内の列の 1 から始まるオフセット。テーブルがクラスタ化テーブルでない場合、値は NULL |
| COLLATION_NAME | STRING | 照合順序の仕様の名前(存在する場合)。それ以外の場合は NULL。STRING または ARRAY<STRING> が渡されると、照合順序の仕様が存在する場合はそれが返されます。それ以外の場合は、NULL が返されます。 |
| COLUMN_DEFAULT | STRING | 列のデフォルト値(存在する場合)。それ以外の場合、値は NULL になります。 |
| ROUNDING_MODE | STRING | フィールドの型がパラメータ化された NUMERIC または BIGNUMERIC の場合、フィールドに書き込まれる値に使用される丸めモード。それ以外の場合は、値が NULL になります。 |
INFORMATION_SCHEMA.COLUMN_FIELD_PATHS で取得できるメタデータ
INFORMATION_SCHEMA.COLUMN_FIELD_PATHS ビューでは、説明などのメタデータを取得できます。
今回は、太字箇所のメタデータを使用します。
INFORMATION_SCHEMA.COLUMN_FIELD_PATHSビューのスキーマは次のとおりです。
| 列名 | データ型 | 値 |
|---|---|---|
| TABLE_CATALOG | STRING | データセットを含むプロジェクトのプロジェクト ID |
| TABLE_SCHEMA | STRING | datasetId とも呼ばれる、テーブルを含むデータセットの名前 |
| TABLE_NAME | STRING | テーブルまたはビューの名前(tableId とも呼ばれる) |
| COLUMN_NAME | STRING | 列の名前 |
| FIELD_PATH | STRING | RECORD 列または STRUCT 列内でネストされた列のパス |
| DATA_TYPE | STRING | 列の GoogleSQL データ型 |
| DESCRIPTION | STRING | 列の説明 |
| COLLATION_NAME | STRING | 照合順序の仕様の名前(存在する場合)。それ以外の場合は NULL。STRUCT の STRING、ARRAY<STRING>、または STRING フィールドが渡された場合、照合順序の仕様が存在する場合はそれが返されます。それ以外の場合は、NULL が返されます。 |
| ROUNDING_MODE | STRING | パラメータ化された NUMERIC 値または BIGNUMERIC 値に精度とスケールを適用するために使用される丸めモード。それ以外の場合は NULL の値になります。 |
それでは、Chicago Taxi Trips データセットに対して、それぞれSQLを実行してメタデータをデータフレームに格納していきます。
まずは、INFORMATION_SCHEMA.COLUMNS ビューからメタデータを取得します。
query = f"""
SELECT
*
FROM
`{PROJECT_ID}.{DATASET_ID}.INFORMATION_SCHEMA.COLUMNS`;
"""
# クエリを実行してDataFrameとして取得
df = client.query(query).to_dataframe()
df.head()
出力
| table_catalog | table_schema | table_name | column_name | ordinal_position | is_nullable | data_type | is_generated | generation_expression | is_stored | is_hidden | is_updatable | is_system_defined | is_partitioning_column | clustering_ordinal_position | collation_name | column_default | rounding_mode |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| bigquery-public-data | chicago_taxi_trips | taxi_trips | unique_key | 1 | NO | STRING | NEVER | NO | NO | NO | <NA> | NULL | NULL | ||||
| bigquery-public-data | chicago_taxi_trips | taxi_trips | taxi_id | 2 | NO | STRING | NEVER | NO | NO | NO | <NA> | NULL | NULL | ||||
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_start_timestamp | 3 | YES | TIMESTAMP | NEVER | NO | NO | NO | <NA> | NULL | NULL | ||||
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_end_timestamp | 4 | YES | TIMESTAMP | NEVER | NO | NO | NO | <NA> | NULL | NULL | ||||
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_seconds | 5 | YES | INT64 | NEVER | NO | NO | NO | <NA> | NULL | NULL |
この中からテーブル定義書に必要な列を抽出します。
df_columns = df[
[
"table_catalog",
"table_schema",
"table_name",
"column_name",
"ordinal_position",
"data_type",
"is_nullable",
"is_partitioning_column",
"clustering_ordinal_position",
]
]
# Excel書き込み時のNA対策でstr型に変換
df_columns = df_columns.astype({"clustering_ordinal_position": str})
df_columns.head()
出力
| table_catalog | table_schema | table_name | column_name | ordinal_position | data_type | is_nullable | is_partitioning_column | clustering_ordinal_position |
|---|---|---|---|---|---|---|---|---|
| bigquery-public-data | chicago_taxi_trips | taxi_trips | unique_key | 1 | STRING | NO | NO | <NA> |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | taxi_id | 2 | STRING | NO | NO | <NA> |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_start_timestamp | 3 | TIMESTAMP | YES | NO | <NA> |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_end_timestamp | 4 | TIMESTAMP | YES | NO | <NA> |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_seconds | 5 | INT64 | YES | NO | <NA> |
次に、INFORMATION_SCHEMA.COLUMN_FIELD_PATHS ビューからメタデータを取得します。
query = f"""
SELECT
*
FROM
`{PROJECT_ID}.{DATASET_ID}.INFORMATION_SCHEMA.COLUMN_FIELD_PATHS`;
"""
# クエリを実行してDataFrameとして取得
df = client.query(query).to_dataframe()
df.head()
出力
| table_catalog | table_schema | table_name | column_name | field_path | data_type | description | collation_name | rounding_mode |
|---|---|---|---|---|---|---|---|---|
| bigquery-public-data | chicago_taxi_trips | taxi_trips | unique_key | unique_key | STRING | Unique identifier for the trip. | NULL | |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | taxi_id | taxi_id | STRING | A unique identifier for the taxi. | NULL | |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_start_timestamp | trip_start_timestamp | TIMESTAMP | When the trip started, rounded to the nearest 15 minutes. | NULL | |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_end_timestamp | trip_end_timestamp | TIMESTAMP | When the trip ended, rounded to the nearest 15 minutes. | NULL | |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_seconds | trip_seconds | INT64 | Time of the trip in seconds. | NULL |
この中からテーブル定義書に必要な列を抽出します。
df_description = df[["table_name", "column_name", "description"]]
df_description.head()
出力
| table_name | column_name | description |
|---|---|---|
| taxi_trips | unique_key | Unique identifier for the trip. |
| taxi_trips | taxi_id | A unique identifier for the taxi. |
| taxi_trips | trip_start_timestamp | When the trip started, rounded to the nearest 15 minutes. |
| taxi_trips | trip_end_timestamp | When the trip ended, rounded to the nearest 15 minutes. |
| taxi_trips | trip_seconds | Time of the trip in seconds. |
最後に、取得した df_columns と df_description をマージします。
ここで、レコードを一意に特定するため、table_name と column_name の2つのキーを使用しています。
df_table_def = df_columns.merge(df_description, on=["table_name", "column_name"])
df_table_def.head()
出力
| table_catalog | table_schema | table_name | column_name | ordinal_position | data_type | is_nullable | is_partitioning_column | clustering_ordinal_position | description |
|---|---|---|---|---|---|---|---|---|---|
| bigquery-public-data | chicago_taxi_trips | taxi_trips | unique_key | 1 | STRING | NO | NO | <NA> | Unique identifier for the trip. |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | taxi_id | 2 | STRING | NO | NO | <NA> | A unique identifier for the taxi. |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_start_timestamp | 3 | TIMESTAMP | YES | NO | <NA> | When the trip started, rounded to the nearest 15 minutes. |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_end_timestamp | 4 | TIMESTAMP | YES | NO | <NA> | When the trip ended, rounded to the nearest 15 minutes. |
| bigquery-public-data | chicago_taxi_trips | taxi_trips | trip_seconds | 5 | INT64 | YES | NO | <NA> | Time of the trip in seconds. |
テーブル定義書に必要なメタデータをデータフレームとして抽出することができました。
エクセルに出力
データフレームの内容をエクセルに出力します。
前準備として、テーブル定義書のテンプレートファイルを作業ディレクトリに保存します。
ノートブックでは、次のコマンドを実行して table_template.xlsx をダウンロードします。
!wget https://github.com/cloud-ace/zenn-bq-table-definition/raw/main/table_template.xlsx

Python で Excel ファイルを操作するためのライブラリ openpyxl をインポートします。
また、テンプレートファイルの設定として、メタデータを記入するセルの開始位置を指定します。
from openpyxl import load_workbook
# テンプレートファイルの設定
STRT_TBL = (2, 3) # テーブル情報の開始位置 (行, 列)
STRT_COL = (8, 1) # カラム情報の開始位置 (行, 列)
あとは、データフレームの内容(テーブル定義のメタデータ)をエクセルファイルに書き込みます。
# テンプレートファイルを開く
wb = load_workbook("./table_template.xlsx")
# templateシートを取得
ws_template = wb["template"]
# tableごとにテーブル定義書を作成
for table_name, df in df_table_def.groupby("table_name"):
# templeteシートをコピペ
ws = wb.copy_worksheet(ws_template)
print(f"Table Name: {table_name}")
# シート名をテーブル名に変更
ws.title = table_name
# テーブル情報の書き込み
ws.cell(
row=STRT_TBL[0],
column=STRT_TBL[1],
value=df["table_catalog"].iloc[0],
)
ws.cell(
row=STRT_TBL[0] + 1,
column=STRT_TBL[1],
value=df["table_schema"].iloc[0],
)
ws.cell(
row=STRT_TBL[0] + 2,
column=STRT_TBL[1],
value=df["table_name"].iloc[0],
)
# カラム情報の書き込み
for i, (_, sr) in enumerate(df.iterrows()):
row = STRT_COL[0] + i
ws.cell(row=row, column=STRT_COL[1], value=sr["ordinal_position"])
ws.cell(row=row, column=STRT_COL[1] + 1, value=sr["column_name"])
ws.cell(row=row, column=STRT_COL[1] + 2, value=sr["data_type"])
ws.cell(row=row, column=STRT_COL[1] + 3, value=sr["is_nullable"])
ws.cell(row=row, column=STRT_COL[1] + 4, value=sr["is_partitioning_column"])
ws.cell(row=row, column=STRT_COL[1] + 5, value=sr["clustering_ordinal_position"])
ws.cell(row=row, column=STRT_COL[1] + 6, value=sr["description"])
# templeteシートを削除
wb.remove(ws_template)
# テーブル定義書(エクセルファイル)の保存
save_path = f"./table_definition_{PROJECT_ID}.{DATASET_ID}.xlsx"
wb.save(save_path)
print(f"Saved file at {save_path}")
書き込みが完了すると、テーブル定義書のエクセルファイルが出力されます。これをローカルにダウンロードして、
ファイルを開くと、テーブル定義書が作成されていることが確認できます。
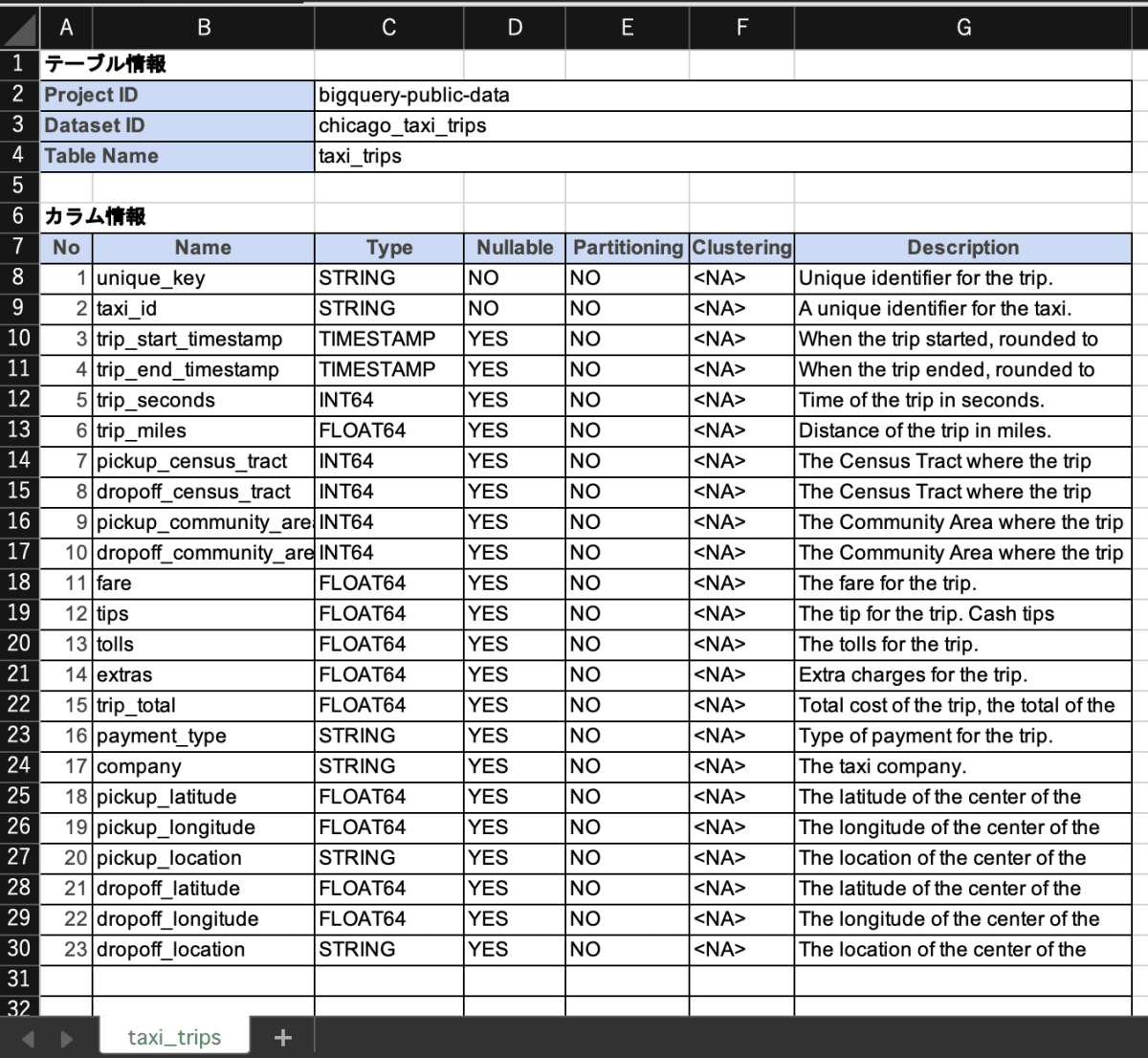
以上です。お疲れ様でした!
コード全体
全体の Python ソースコードはこちらです。
make_table_definition.py
import pandas as pd
from google.cloud import bigquery
from openpyxl import load_workbook
# 対象データセットの設定
PROJECT_ID = "bigquery-public-data"
DATASET_ID = "chicago_taxi_trips"
# テンプレートファイルの設定
STRT_TBL = (2, 3) # テーブル情報の開始位置 (行, 列)
STRT_COL = (8, 1) # カラム情報の開始位置 (行, 列)
# BigQueryクライアントのインスタンスを生成
client = bigquery.Client()
query = f"""
SELECT
*
FROM
`{PROJECT_ID}.{DATASET_ID}.INFORMATION_SCHEMA.COLUMNS`;
"""
# クエリを実行してDataFrameとして取得
df = client.query(query).to_dataframe()
df_columns = df[
[
"table_catalog",
"table_schema",
"table_name",
"column_name",
"ordinal_position",
"data_type",
"is_nullable",
"is_partitioning_column",
"clustering_ordinal_position",
]
]
# Excel書き込み時のNA対策でstr型に変換
df_columns = df_columns.astype({"clustering_ordinal_position": str})
query = f"""
SELECT
*
FROM
`{PROJECT_ID}.{DATASET_ID}.INFORMATION_SCHEMA.COLUMN_FIELD_PATHS`;
"""
# クエリを実行してDataFrameとして取得
df = client.query(query).to_dataframe()
df_description = df[["table_name", "column_name", "description"]]
df_table_def = df_columns.merge(df_description, on=["table_name", "column_name"])
# テンプレートファイルを開く
wb = load_workbook("./table_template.xlsx")
# templateシートを取得
ws_template = wb["template"]
# tableごとにテーブル定義書を作成
for table_name, df in df_table_def.groupby("table_name"):
# templeteシートをコピペ
ws = wb.copy_worksheet(ws_template)
print(f"Table Name: {table_name}")
# シート名をテーブル名に変更
ws.title = table_name
# テーブル情報の書き込み
ws.cell(
row=STRT_TBL[0],
column=STRT_TBL[1],
value=df["table_catalog"].iloc[0],
)
ws.cell(
row=STRT_TBL[0] + 1,
column=STRT_TBL[1],
value=df["table_schema"].iloc[0],
)
ws.cell(
row=STRT_TBL[0] + 2,
column=STRT_TBL[1],
value=df["table_name"].iloc[0],
)
# カラム情報の書き込み
for i, (_, sr) in enumerate(df.iterrows()):
row = STRT_COL[0] + i
ws.cell(row=row, column=STRT_COL[1], value=sr["ordinal_position"])
ws.cell(row=row, column=STRT_COL[1] + 1, value=sr["column_name"])
ws.cell(row=row, column=STRT_COL[1] + 2, value=sr["data_type"])
ws.cell(row=row, column=STRT_COL[1] + 3, value=sr["is_nullable"])
ws.cell(row=row, column=STRT_COL[1] + 4, value=sr["is_partitioning_column"])
ws.cell(row=row, column=STRT_COL[1] + 5, value=sr["clustering_ordinal_position"])
ws.cell(row=row, column=STRT_COL[1] + 6, value=sr["description"])
# templeteシートを削除
wb.remove(ws_template)
# テーブル定義書(エクセルファイル)の保存
save_path = f"./table_definition_{PROJECT_ID}.{DATASET_ID}.xlsx"
wb.save(save_path)
print(f"Saved file at {save_path}")
まとめ
この記事では、BigQuery のデータセットからテーブル定義書を自動生成する方法をご紹介しました。
INFORMATION_SCHEMA を活用することで、他にも多様なメタデータを取得できます。今回は簡易的なテーブル定義書の生成を紹介しましたが、カスタマイズすれば、より詳細な情報を盛り込んだ定義書の作成も可能です。また、出力形式についても、Excel に限定せず、Google スプレッドシートなど、様々な形式への応用もできそうです。
この記事がドキュメントメンテナンスの負担を軽減する一助となれば幸いです。
それでは、引き続き充実した BigQuery ライフを!
Discussion