BigQuery クエリ性能改善: グループ化した Foreign key と Primary key の結合結果確認
本記事は、BigQuery の主キーと外部キーにより、クエリの性能改善が得られるかどうか検証してみたの検証の一部になります。
ここでは、Foreign key で GROUP BY した後、この Foreign key と Primary key で結合したときでも、正しい結果になるのか・PK / FKの効果を受けることができるのか確認します。
1. データセット・テーブルの準備
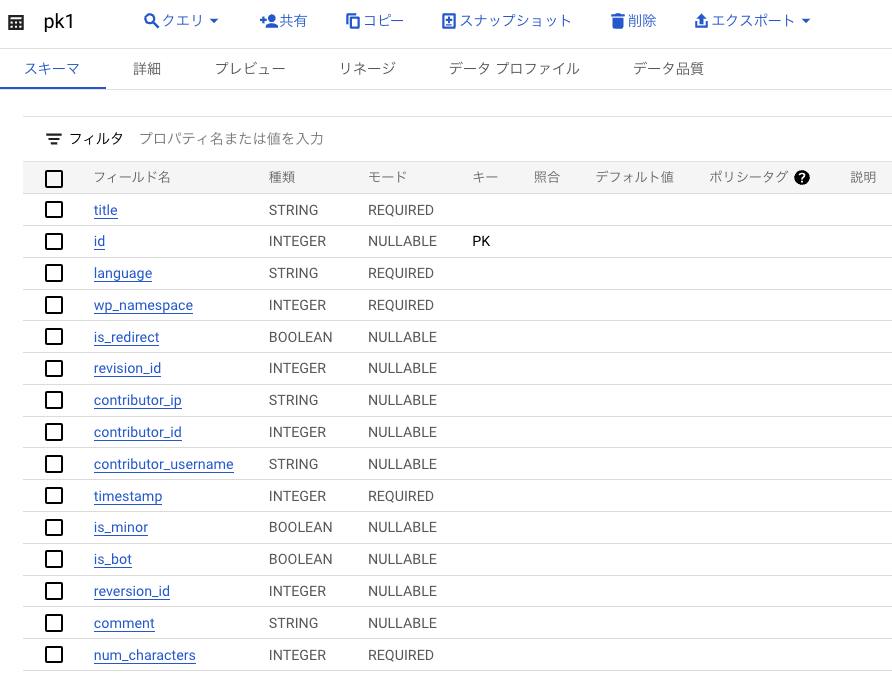
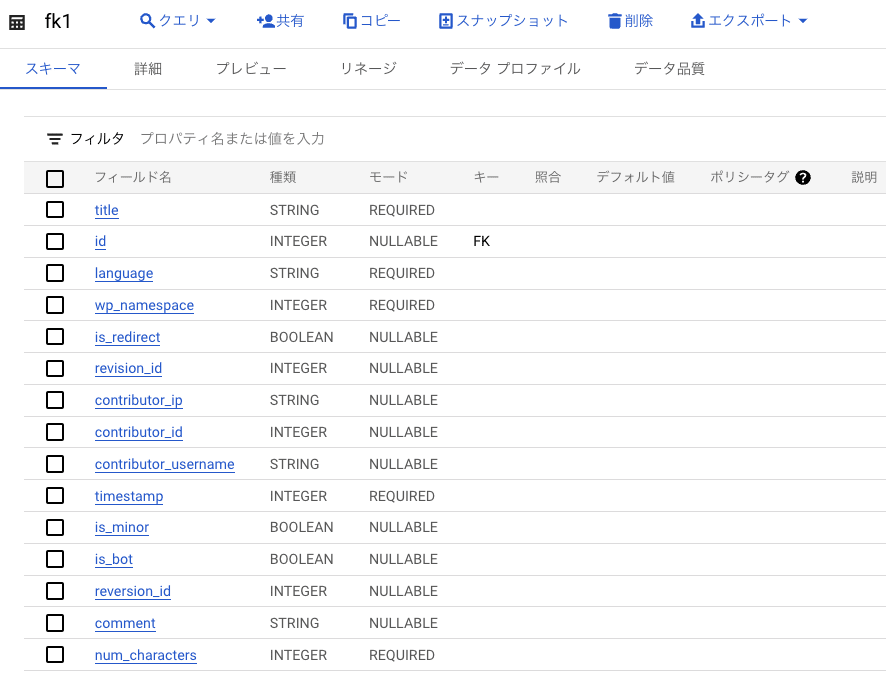
BigQuery public datasets の wikipedia テーブルから、以下 4 つのテーブルを用意します。
- normal1
- normal2
- pk1
- fk1
normal1 と normal2 は通常テーブルです。
pk1 と f1 では、id カラムを Primary key / Foreign key として設定します。
normal1 テーブルと pk1 テーブルでは、id カラムが一意になるようにします。
-- データセット作成
CREATE SCHEMA IF NOT EXISTS pk_fk_dataset;
-- 通常テーブル作成
CREATE OR REPLACE TABLE pk_fk_dataset.normal1
(
title STRING NOT NULL,
id INTEGER,
language STRING NOT NULL,
wp_namespace INTEGER NOT NULL,
is_redirect BOOLEAN,
revision_id INTEGER,
contributor_ip STRING,
contributor_id INTEGER,
contributor_username STRING,
timestamp INTEGER NOT NULL,
is_minor BOOLEAN,
is_bot BOOLEAN,
reversion_id INTEGER,
comment STRING,
num_characters INTEGER NOT NULL,
) AS (
SELECT
* except(rn)
FROM (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY id ORDER BY timestamp) as rn,
FROM
bigquery-public-data.samples.wikipedia
QUALIFY
rn = 1
)
);
CREATE OR REPLACE TABLE pk_fk_dataset.normal2
(
title STRING NOT NULL,
id INTEGER,
language STRING NOT NULL,
wp_namespace INTEGER NOT NULL,
is_redirect BOOLEAN,
revision_id INTEGER,
contributor_ip STRING,
contributor_id INTEGER,
contributor_username STRING,
timestamp INTEGER NOT NULL,
is_minor BOOLEAN,
is_bot BOOLEAN,
reversion_id INTEGER,
comment STRING,
num_characters INTEGER NOT NULL,
) AS (
SELECT
*
FROM
bigquery-public-data.samples.wikipedia
);
-- Primary key, Foreign keyを設定したテーブル作成
CREATE OR REPLACE TABLE
pk_fk_dataset.pk1
CLONE pk_fk_dataset.normal1;
CREATE OR REPLACE TABLE
pk_fk_dataset.fk1
CLONE pk_fk_dataset.normal2;
ALTER table pk_fk_dataset.pk1 ADD PRIMARY KEY(id) NOT ENFORCED;
ALTER table pk_fk_dataset.fk1 ADD FOREIGN KEY(id) REFERENCES pk_fk_dataset.pk1(id) NOT ENFORCED;
2. 結合の検証
fk1 テーブルを id カラムで GROUP BY してから pk1 テーブルと結合する SQL を実行し、PK / FK の効果を受けることができるのかを確認します。
2.1. 内部結合 (左: PK, 右: FK)
PK / FK テーブルでの結果 (行数: 19,376,810) は、通常テーブルの結果 (行数: 19,376,810) と同じでした。
通常テーブル
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.normal2
GROUP BY
id
)
SELECT
normal1.*
FROM
pk_fk_dataset.normal1
INNER JOIN
sum_num_characters
ON
normal1.id = sum_num_characters.id
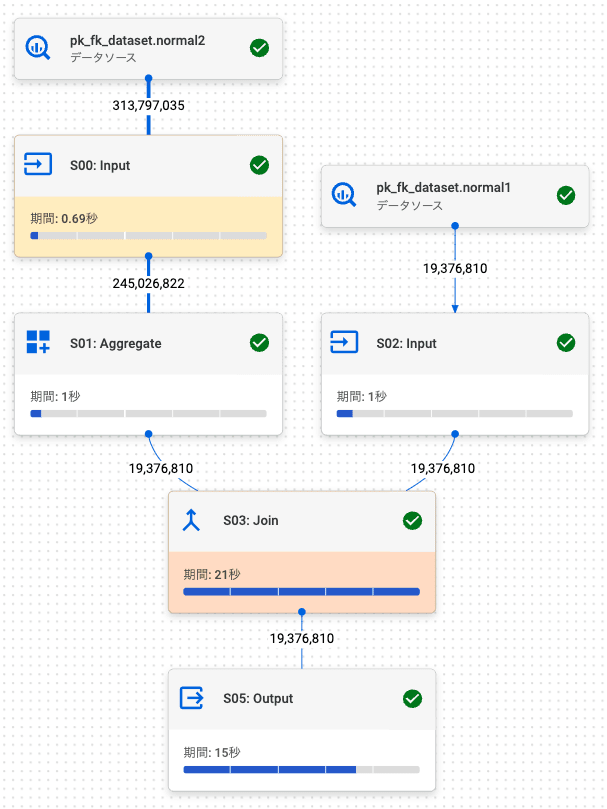
PK / FK テーブル
PK / FK テーブルでの結果 (行数: 19,376,810) は、通常テーブルの結果 (行数: 19,376,810) と同じでした。
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.fk1
GROUP BY
id
)
SELECT
pk1.*
FROM
pk_fk_dataset.pk1
INNER JOIN
sum_num_characters
ON
pk1.id = sum_num_characters.id
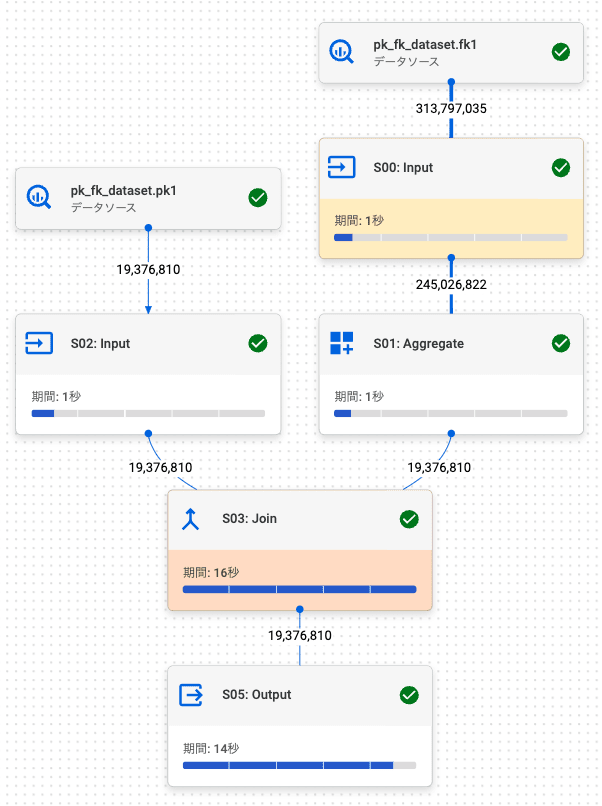
2.2. 内部結合 (左: FK, 右: PK)
PK / FK テーブルでの結果 (行数: 19,376,810) は、通常テーブルの結果 (行数: 19,376,810) と同じでした。
通常テーブル
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.normal2
GROUP BY
id
)
SELECT
sum_num_characters.*
FROM
sum_num_characters
INNER JOIN
pk_fk_dataset.normal1
ON
sum_num_characters.id = normal1.id
PK / FK テーブル
PK / FK テーブルでの結果 (行数: 19,376,810) は、通常テーブルの結果 (行数: 19,376,810) と同じでした。
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.fk1
GROUP BY
id
)
SELECT
sum_num_characters.*
FROM
sum_num_characters
INNER JOIN
pk_fk_dataset.pk1
ON
sum_num_characters.id = pk1.id
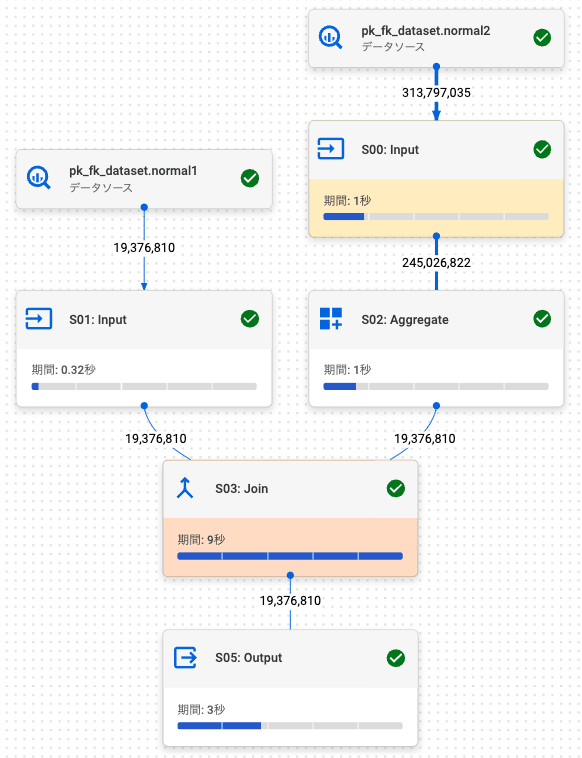
2.3. 左外部結合 (左: PK, 右: FK)
PK / FK テーブルでの結果 (行数: 19,376,810) は、通常テーブルの結果 (行数: 19,376,810) と同じでした。
通常テーブル
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.normal2
GROUP BY
id
)
SELECT
normal1.*
FROM
pk_fk_dataset.normal1
LEFT JOIN
sum_num_characters
ON
normal1.id = sum_num_characters.id
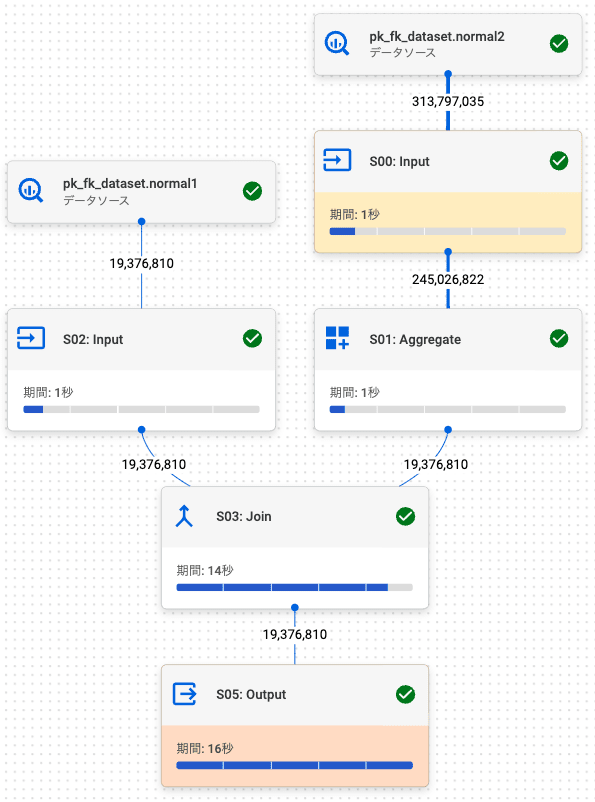
PK / FK テーブル
PK / FK テーブルでの結果 (行数: 19,376,810) は、通常テーブルの結果 (行数: 19,376,810) と同じでした。
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.fk1
GROUP BY
id
)
SELECT
pk1.*
FROM
pk_fk_dataset.pk1
LEFT JOIN
sum_num_characters
ON
pk1.id = sum_num_characters.id
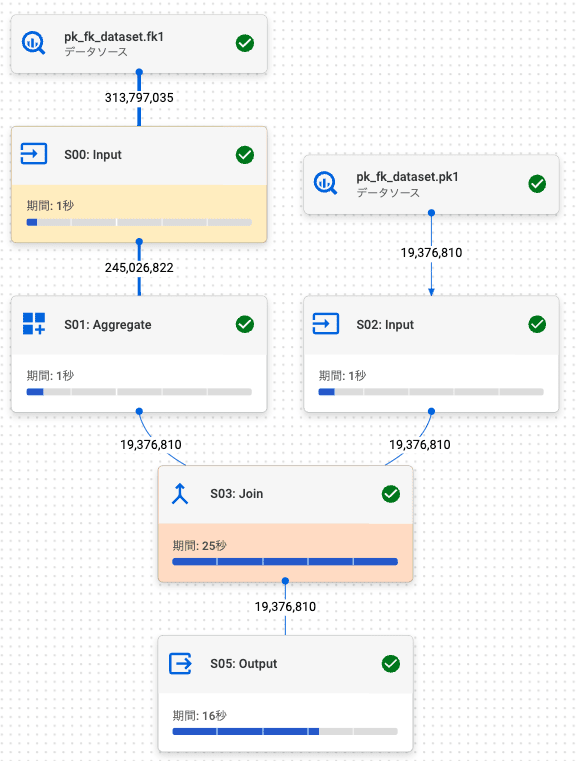
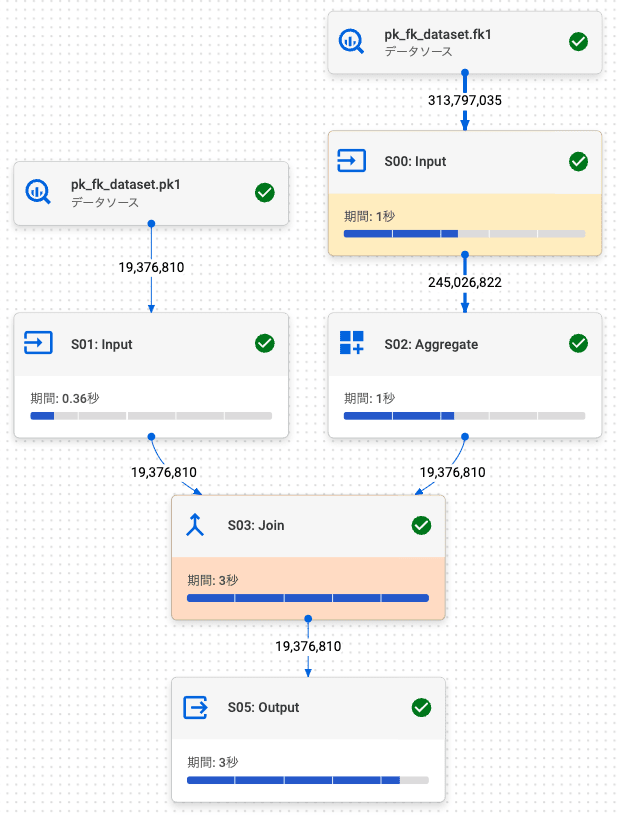
2.4. 左外部結合 (左: FK, 右: PK)
PK / FK テーブルでの結果 (行数: 19,376,810) は、通常テーブルの結果 (行数: 19,376,810) と同じでした。
また、結合解除も発生しました。
通常テーブル
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.normal2
GROUP BY
id
)
SELECT
sum_num_characters.*
FROM
sum_num_characters
LEFT JOIN
pk_fk_dataset.normal1
ON
sum_num_characters.id = normal1.id
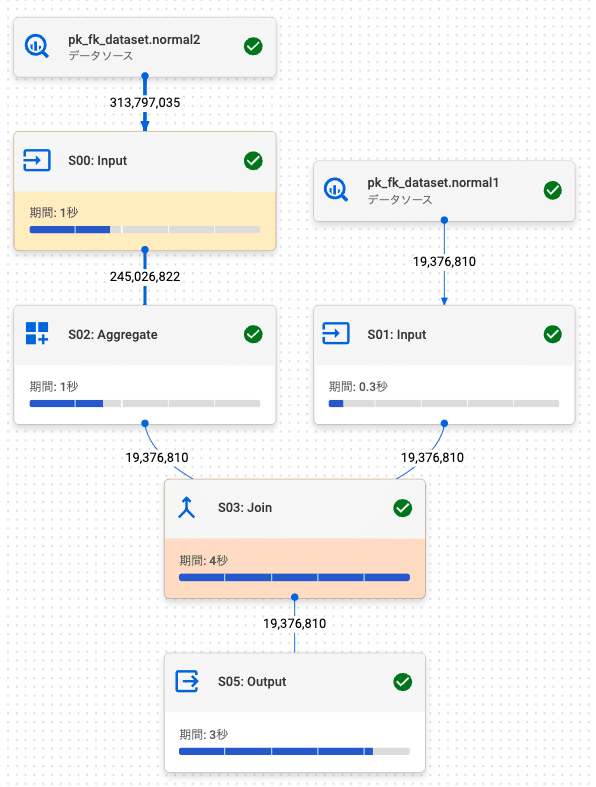
PK / FK テーブル
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.fk1
GROUP BY
id
)
SELECT
sum_num_characters.*
FROM
sum_num_characters
LEFT JOIN
pk_fk_dataset.pk1
ON
sum_num_characters.id = pk1.id
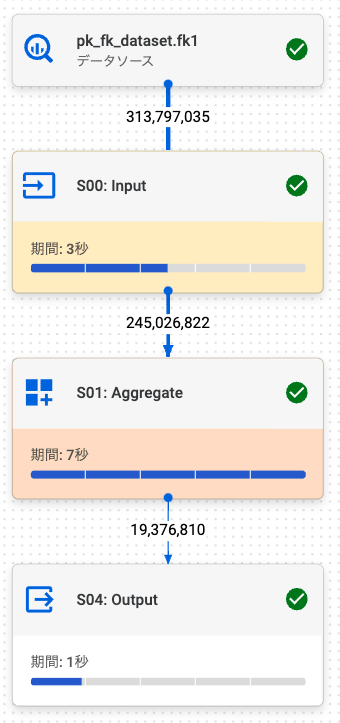
2.5. 結合解除されないときの PK / FK の効果確認 (内部結合)
sum_num_characters と normal1 (pk1) 両方のカラムを取得するように 2.2. 内部結合 (左: FK, 右: PK) の SQL を変更し、PK / FK により結合性能が改善されるか確認します。
通常テーブル
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.normal2
GROUP BY
id
)
SELECT
sum_num_characters.*,
normal1.*
FROM
sum_num_characters
INNER JOIN
pk_fk_dataset.normal1
ON
sum_num_characters.id = normal1.id
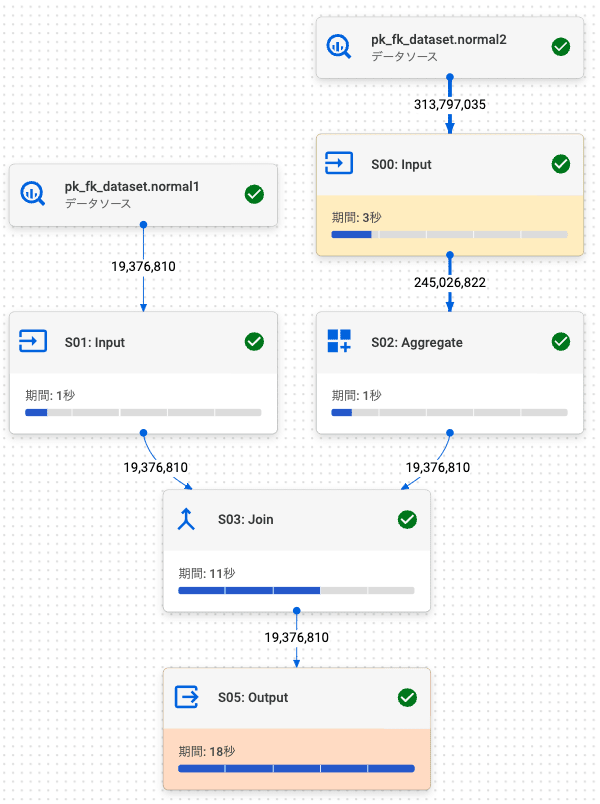
PK / FK テーブル
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.fk1
GROUP BY
id
)
SELECT
sum_num_characters.*,
pk1.*
FROM
sum_num_characters
INNER JOIN
pk_fk_dataset.pk1
ON
sum_num_characters.id = pk1.id
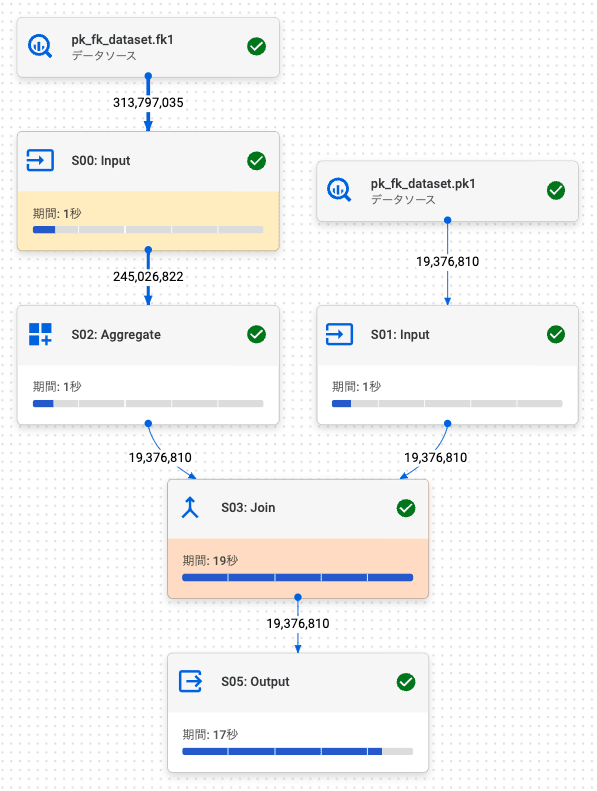
通常テーブルと PK / FK テーブルそれぞれ 10 回実行した結果は以下のようになりました。
通常テーブル
| # | 経過時間 (s) | 消費したスロット時間 (s) |
|---|---|---|
| 1 | 35 | 1694 |
| 2 | 50 | 1600 |
| 3 | 44 | 1636 |
| 4 | 42 | 1509 |
| 5 | 36 | 1695 |
| 6 | 31 | 1329 |
| 7 | 33 | 1373 |
| 8 | 43 | 1352 |
| 9 | 45 | 1338 |
| 10 | 40 | 1280 |
| 平均 | 39.9 | 1481 |
PK / FK テーブル
| # | 経過時間 (s) | 消費したスロット時間 (s) |
|---|---|---|
| 1 | 41 | 1387 |
| 2 | 47 | 1489 |
| 3 | 43 | 1501 |
| 4 | 46 | 1758 |
| 5 | 45 | 1416 |
| 6 | 50 | 1518 |
| 7 | 35 | 1383 |
| 8 | 32 | 1422 |
| 9 | 32 | 1283 |
| 10 | 46 | 1341 |
| 平均 | 41.7 | 1450 |
今回の場合、PK / FK テーブルは、通常テーブルよりもクエリの処理速度が遅くなりました。
2.6. 結合解除されないときの PK / FK の効果確認 (左外部結合)
sum_num_characters と normal1 (pk1) 両方のカラムを取得するように 2.4. 左外部結合 (左: FK, 右: PK) の SQL を変更することで、結合解除されないようにし、PK / FK により結合性能が改善されるか確認します。
通常テーブル
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.normal2
GROUP BY
id
)
SELECT
sum_num_characters.*,
normal1.*
FROM
sum_num_characters
LEFT JOIN
pk_fk_dataset.normal1
ON
sum_num_characters.id = normal1.id
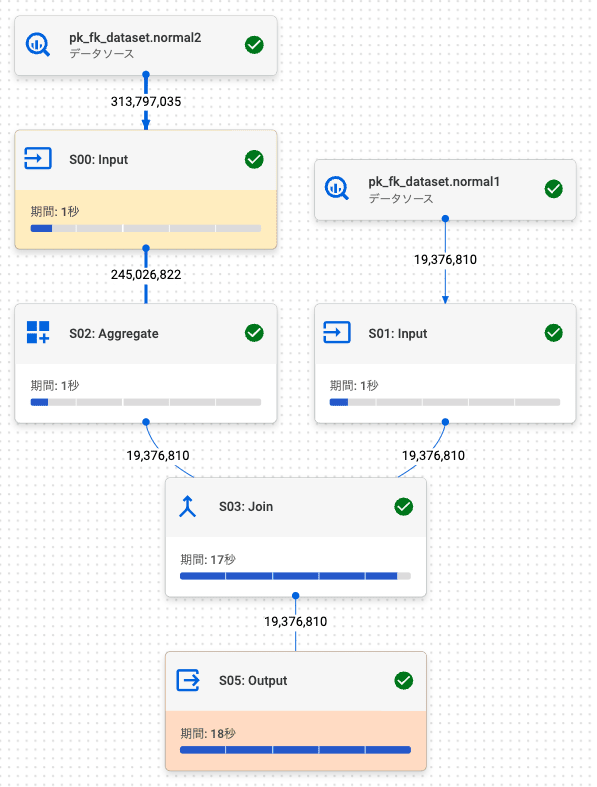
PK / FK テーブル
WITH sum_num_characters AS (
SELECT
id,
SUM(num_characters) as total_num_characters
FROM
pk_fk_dataset.fk1
GROUP BY
id
)
SELECT
sum_num_characters.*,
pk1.*
FROM
sum_num_characters
LEFT JOIN
pk_fk_dataset.pk1
ON
sum_num_characters.id = pk1.id
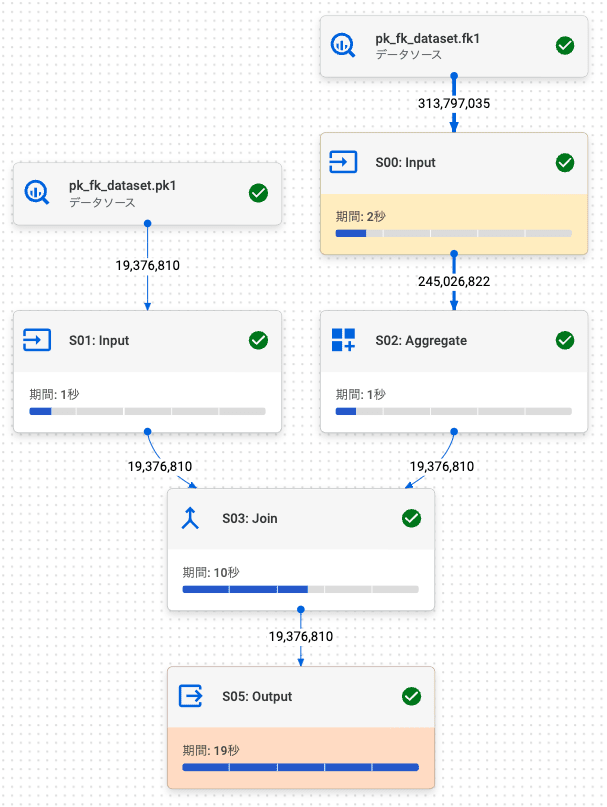
通常テーブルと PK / FK テーブルそれぞれ 10 回実行した結果は以下のようになりました。
通常テーブル
| # | 経過時間 (s) | 消費したスロット時間 (s) |
|---|---|---|
| 1 | 40 | 1392 |
| 2 | 42 | 1274 |
| 3 | 42 | 1510 |
| 4 | 46 | 1570 |
| 5 | 45 | 1370 |
| 6 | 36 | 1405 |
| 7 | 45 | 1465 |
| 8 | 39 | 1477 |
| 9 | 33 | 1294 |
| 10 | 51 | 1396 |
| 平均 | 41.9 | 1415 |
PK / FK テーブル
| # | 経過時間 (s) | 消費したスロット時間 (s) |
|---|---|---|
| 1 | 35 | 1848 |
| 2 | 42 | 1769 |
| 3 | 33 | 1516 |
| 4 | 46 | 1613 |
| 5 | 35 | 1425 |
| 6 | 52 | 1493 |
| 7 | 43 | 1537 |
| 8 | 49 | 1780 |
| 9 | 41 | 1485 |
| 10 | 45 | 1656 |
| 平均 | 42.1 | 1612 |
今回の場合、PK / FK テーブルは、通常テーブルよりもクエリの処理速度が遅くなりました。(0.2秒差なので、ほぼ同じ)
3. まとめ
Foreign key で GROUP BY した後、この Foreign key と Primary key で結合したとき、内部結合解除は発生しませんでした。一方、外部結合解除は発生可能でした。
Discussion