BigQuery の RANGE 関数まとめ
はじめに
こんにちは、クラウドエースの柏倉です。
今回は、BigQuery の RANGE 関数についてご紹介します。
RANGE 関数
BigQuery における RANGE 関数(Range functions)は、RANGE 型の区間データを使って、区間同士が隣接しているか、重複しているかといった関係を調べることができます。
区間における「重複」と「隣接」の違い
- 重複:区間が重なりあっている (区間 1 の一部の区間と区間 2 の一部の区間が重なる)
- 隣接:区間が隣り合っている (区間 1 の終了値と区間 2 の開始値が同じ)
RANGE 型とは
RANGE 型は BigQuery において、区間を表現するデータ型です。
BigQuery では RANGE 型のデータを [2025-01-01, 2025-01-31) のように表現します。
[) という記号は、数学における「半開区間」の表記に基づいています。
「半開区間」とは、一方の端点を含み、もう一方の端点を含まない区間のことです。
[ は端点を含むことを、) は含まないことを意味します。
本記事では、以下の RANGE 関数についてご説明します。
- RANGE
- RANGE_START / RANGE_END
- RANGE_CONTAINS
- RANGE_OVERLAPS
- RANGE_INTERSECT
- GENERATE_RANGE_ARRAY
- RANGE_BUCKET
- RANGE_SESSIONIZE
RANGE
RANGE は、DATE、DATETIME、TIMESTAMP いずれかの区間を作成する関数です。
RANGE(lower_bound, upper_bound)
各引数の説明は以下の通りです。
-
lower_bound: 作成する区間の開始値 -
upper_bound: 作成する区間の終了値
仕様の詳細については、以下の Google Cloud ドキュメントをご確認ください。
使用例
RANGE 関数を使用して区間を表現すると、次のようになります。
以下は、2025 年 1 月 1 日から 2025 年 1 月 31 日までの区間を作成する例です。
SELECT
RANGE(DATE '2025-01-01', DATE '2025-01-31') AS result;

RANGE_START / RANGE_END
RANGE_START および RANGE_END は、指定した区間の開始値と終了値をそれぞれ取得する関数です。
RANGE_START(range_to_check) -- 開始値を取得
RANGE_END(range_to_check) -- 終了値を取得
引数の説明は以下の通りです。
-
range_to_check: 開始値または終了値を取得したい区間
仕様の詳細については、以下の Google Cloud ドキュメントをご確認ください。
RANGE_START: RANGE_END:
使用例
以下のように使用することで、[2025-01-01, 2025-01-31) 区間の開始日と終了日を取得できます。
SELECT
RANGE_START(RANGE(DATE '2025-01-01', DATE '2025-01-31')) AS result1,
RANGE_END(RANGE(DATE '2025-01-01', DATE '2025-01-31')) AS result2;

このようにして取得した区間の開始日と終了日を使用して、区間内の日数を求めることもできます。
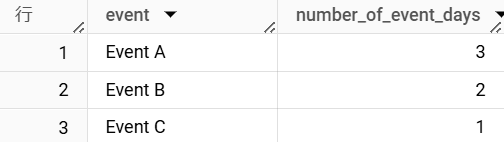
以下の例では、イベントの開始日と終了日を取得し、イベントの開催日数を計算しています。
WITH event_info AS (
-- イベント情報
SELECT
'Event A' AS event,
RANGE(DATE '2025-01-11', DATE '2025-01-14') AS event_duration
UNION ALL
SELECT
'Event B',
RANGE(DATE '2025-01-18', DATE '2025-01-20')
UNION ALL
SELECT
'Event C',
RANGE(DATE '2025-02-11', DATE '2025-02-12')
)
SELECT
event,
DATE_DIFF(
RANGE_END(event_duration),
RANGE_START(event_duration),
DAY
) AS number_of_event_days
FROM
event_info
RANGE_CONTAINS
RANGE_CONTAINS 関数には、2 種類のシグネチャがあります。
- 区間全体が特定の区間に含まれているかを判定する
RANGE_CONTAINS(outer_range, inner_range)
-
outer_range: 包含判定の際に基準となる区間 -
inner_range:outer_rangeに完全に含まれているかを判定したい区間
区間全体が重なっているかどうかではなく、一部でも重なっているかを判定したい場合は、後述する RANGE_OVERLAPS 関数を使用します。
- ある日時が特定の区間に含まれているかを判定する
RANGE_CONTAINS(range_to_search, value_to_find)
-
range_to_search: 包含判定の際に基準となる区間 -
value_to_find:range_to_searchに含まれているかを判定したい日時
仕様の詳細については、以下の Google Cloud ドキュメントをご確認ください。
使用例
以下のように使用することで、ある区間や特定の日時が基準区間に包含されているかを確認できます。
以下のクエリでは、次の 2 点を確認しています。
- 2025-01-01 から 2025-12-31 の区間に 2025-04-01 から 2025-09-30 の区間が包含されているか (result1)
- 2025-01-01 から 2025-12-31 の区間に 2025-04-01 が含まれているか (result2)
SELECT
RANGE_CONTAINS(
RANGE(DATE '2025-01-01', DATE '2025-12-31'),
RANGE(DATE '2025-04-01', DATE '2025-09-30')
) AS result1,
RANGE_CONTAINS(
RANGE(DATE '2025-01-01', DATE '2025-12-31'),
DATE '2025-04-01'
) AS result2;

このように、RANGE_CONTAINS 関数を使用すると、2 つの区間が包含関係にあるかを簡単に判定できます。
例えば、A から B という区間に C から D という区間が含まれているかを確認する場合、RANGE_CONTAINS を使わない方法では次のようなクエリで確認することができます。
C BETWEEN A AND B
AND D BETWEEN A AND B
RANGE_CONTAINS 関数を使用すると、このクエリを次のようにシンプルに書くことができます。
RANGE_CONTAINS([A, B), [C, D))
この関数の具体的な活用例として、次のようなシナリオが考えられます。
- 前提: あるプロジェクトに従事するには、有効期間のある特別な資格が必要
- 目的: プロジェクトにアサインされる期間全体を通して、必要な資格が有効であるかを判定したい
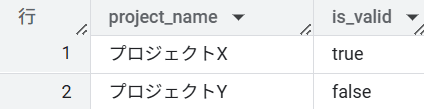
以下のクエリでは、このシナリオに基づき、従業員の資格有効期間内(2024-04-01 から 2025-04-01)にプロジェクトへのアサイン期間が完全に含まれているかを RANGE_CONTAINS 関数で判定しています。
WITH project_assignments AS (
SELECT
'プロジェクトX' AS project_name,
RANGE(DATE '2024-04-01', DATE '2025-04-01') AS assignment_period
UNION ALL
SELECT
'プロジェクトY',
RANGE(DATE '2025-07-01', DATE '2026-04-01')
)
SELECT
project_name,
RANGE_CONTAINS(
RANGE(DATE '2024-04-01', DATE '2025-04-01'), -- 資格有効期間
assignment_period -- プロジェクトアサイン期間
) AS is_valid
FROM
project_assignments
RANGE_OVERLAPS
RANGE_OVERLAPS 関数は、2 つの区間が一部でも重なっているかどうかを判定する関数です。
RANGE_OVERLAPS(range_a, range_b)
各引数の説明は以下の通りです。
-
range_a: 重複を判定したい 1 つ目の区間 -
range_b: 重複を判定したい 2 つ目の区間
この関数と似た機能を持つ関数に、RANGE_INTERSECT と RANGE_CONTAINS がありますが、それぞれの動作は以下のように異なります。
-
RANGE_INTERSECT関数:2 つの区間が重なっている範囲を取得 -
RANGE_CONTAINS関数:ある区間がもう一方の区間を完全に含んでいるかどうかを判定
仕様の詳細については、以下の Google Cloud ドキュメントをご確認ください。
使用例
以下のように使用することで、2025-01-01 から 2025-07-01 の区間と 2025-04-01 から 2025-10-01 の区間が一部でも重なっているかを確認できます。
SELECT
RANGE_OVERLAPS(
RANGE(DATE '2025-01-01', DATE '2025-07-01'),
RANGE(DATE '2025-04-01', DATE '2025-10-01')
) AS result;

このように、RANGE_OVERLAPS 関数を使用すると、2 つの区間が一部でも重なっているかを簡単に判定できます。
例えば、A から B という区間に C から D という区間が一部でも重なっているかを確認する場合、RANGE_OVERLAPS を使わない方法では次のようなクエリで確認することができます。
NOT (
B < C
OR D < A
)
RANGE_OVERLAPS 関数を使用すると、このクエリを次のようにシンプルに書くことができます。
RANGE_OVERLAPS([A, B), [C, D))
以下の例では、ユーザーが 2025 年 1 月 10 日の午前 8 時から午前 10 時の間に Web サービスを利用したかを RANGE_OVERLAPS 関数を用いて判定し、その時間帯に利用したユーザーの数を算出しています。
WITH usage_logs AS (
-- 利用履歴
SELECT
'A' AS user_name,
TIMESTAMP '2025-01-10 09:00:00' AS start_time,
TIMESTAMP '2025-01-10 09:30:00' AS end_time
UNION ALL
SELECT
'B',
'2025-01-10 07:30:00',
'2025-01-10 08:30:00'
UNION ALL
SELECT
'C',
'2025-01-10 10:30:00',
'2025-01-10 11:00:00'
)
SELECT
COUNT(*) AS cnt
FROM
usage_logs
WHERE
RANGE_OVERLAPS(
RANGE(start_time, end_time),
RANGE(TIMESTAMP '2025-01-10 08:00:00', TIMESTAMP '2025-01-10 10:00:00')
)

RANGE_INTERSECT
RANGE_INTERSECT は、2 つの区間の重なっている部分を取得する関数です。
RANGE_INTERSECT(range_a, range_b)
各引数の説明は以下の通りです。
-
range_a: 区間 a -
range_b: 区間 b
仕様の詳細については、以下の Google Cloud ドキュメントをご確認ください。
使用例
以下のように使用することで、2025-01-01 から 2025-07-01 の区間と 2025-04-01 から 2025-10-01 の区間のうち、重なっている範囲を取得できます。
この場合は、2025-04-01 から 2025-07-01 の区間が返されます。
SELECT
RANGE_INTERSECT(
RANGE(DATE '2025-01-01', DATE '2025-07-01'),
RANGE(DATE '2025-04-01', DATE '2025-10-01')
) AS result;

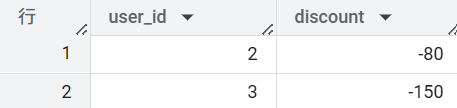
また、以下の例では、RANGE_INTERSECT 関数を使用してサブスクリプション会員の契約期間とキャンペーン期間の重複部分を取得し、それを基に割引額を算出しています。
キャンペーン概要
- 対象:キャンペーン期間中にサブスクリプションを契約中の会員
- 期間:2025 年 2 月 21 日 ~ 2025 年 3 月 8 日
- 割引内容:月額サブスクリプション料金を 1 日あたり 10 円割引
- 備考:キャンペーン期間の途中で契約または解約した場合は、サブスクリプションを利用した日数に基づき、日割り計算にて割引を適用する。
WITH campaign_info AS (
SELECT
"キャンペーン1" AS campaign_name,
RANGE(DATE '2025-02-21', DATE '2025-03-08') AS campaign_period,
), user_info AS (
-- サブスクリプション契約期間
SELECT
1 AS user_id,
RANGE(DATE '2022-01-01', DATE '2025-02-01') AS subscription_period,
UNION ALL
SELECT
2,
RANGE(DATE '2023-01-01', DATE '2025-03-01')
UNION ALL
SELECT
3,
RANGE(DATE '2025-01-01', NULL)
)
SELECT
user_id,
-- 割引額(discount)を計算
-- 割引額の計算式は「キャンペーン期間とサブスクリプション会員の契約期間が重なる日数 × 10 円」
DATE_DIFF(
RANGE_START(RANGE_INTERSECT(campaign_period, subscription_period)),
RANGE_END(RANGE_INTERSECT(campaign_period, subscription_period)),
DAY
) * 10 AS discount
FROM
user_info
INNER JOIN
campaign_info
-- サブスクの登録期間とキャンペーン期間が一部でも重なるデータだけを残す
ON RANGE_OVERLAPS(
campaign_period,
subscription_period
)
GENERATE_RANGE_ARRAY
GENERATE_RANGE_ARRAY 関数は、指定した区間を一定の間隔で分割し、それぞれの部分区間を 1 つの配列(ARRAY<RANGE>)として返す関数です。
GENERATE_RANGE_ARRAY(range_to_split, step_interval, include_last_partial_range)
各引数の説明は以下の通りです。
-
range_to_split: 分割対象となる区間 -
step_interval: 分割する際の幅 -
include_last_partial_range: 最後の区間がstep_intervalより短い場合に、それを出力結果に含めるかを指定する BOOL 型の値(デフォルトはTRUE)
仕様の詳細については、以下の Google Cloud ドキュメントをご確認ください。
使用例
以下のように使用することで、2025-01-01 から 2025-01-06 の区間を分割し、配列として出力できます。
引数を変えて 3 つのパターンを試してみます。
SELECT
GENERATE_RANGE_ARRAY(
RANGE(DATE '2025-01-01', DATE '2025-01-06'),
INTERVAL 1 DAY
) AS results1,
GENERATE_RANGE_ARRAY(
RANGE(DATE '2025-01-01', DATE '2025-01-06'),
INTERVAL 2 DAY,
TRUE
) AS results2,
GENERATE_RANGE_ARRAY(
RANGE(DATE '2025-01-01', DATE '2025-01-06'),
INTERVAL 2 DAY,
FALSE
) AS results3;
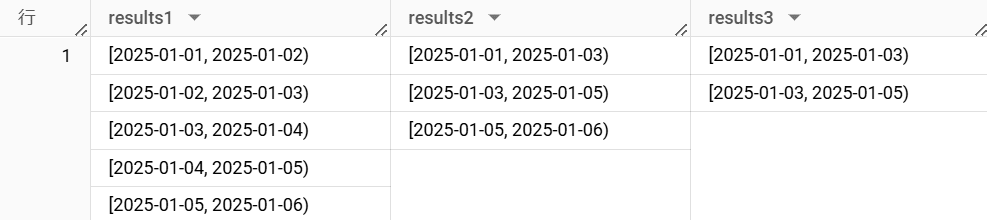
各パターンの処理は以下の通りです。
- result1:2025-01-01 から 2025-01-06 までの日付範囲を 1 日間隔で分割する。
-
result2:2025-01-01 から 2025-01-06 までの日付範囲を 2 日間隔で分割する。最後の区間には 2025-01-05 の 1 日のみが含まれるが、
include_last_partial_rangeがTRUEのため、この区間も出力する。 -
result3:2025-01-01 から 2025-01-06 までの日付範囲を 2 日間隔で分割する。最後の区間には 2025-01-05 の 1 日のみが含まれるが、
include_last_partial_rangeがFALSEのため、この区間は出力しない。
GENERATE_RANGE_ARRAY 関数は、期間内のデータを数日ごとに集計する際に役立ちます。
以下の例では、GENERATE_RANGE_ARRAY 関数を用いて分析対象期間(2025-01-01 ~ 2025-01-10)を 3 日間隔で分割し、3 日ごとの売上合計を算出しています。
WITH three_day_ranges AS (
-- 分析対象期間(2025-01-01 ~ 2025-01-10)を 3 日間隔で分割
SELECT
date_period
FROM
UNNEST(
GENERATE_RANGE_ARRAY(
RANGE(DATE '2025-01-01', DATE '2025-01-10'),
INTERVAL 3 DAY
)
) AS date_period
), sales AS (
-- 売上データ
SELECT
DATE '2025-01-01' AS sale_date,
1000 AS amount
UNION ALL
SELECT
'2025-01-02',
2000
UNION ALL
SELECT
'2025-01-04',
1500
UNION ALL
SELECT
'2025-01-08',
2500
)
-- 3 日間ごとに売上を集計
SELECT
tdr.date_period,
SUM(s.amount) AS three_day_sales
FROM
three_day_ranges AS tdr
-- LEFT JOIN: 売上が存在しない範囲も結果に含めるため
LEFT JOIN
sales AS s
ON RANGE_CONTAINS(tdr.date_period, sale_date)
GROUP BY
tdr.date_period
ORDER BY
tdr.date_period;

RANGE_BUCKET
RANGE_BUCKET 関数は、指定した値が与えられた配列内で、どの区間に属するかを示すインデックスを返す関数です。
RANGE_BUCKET(point, boundaries_array)
各引数の説明は以下の通りです。
-
point: 任意の値(日付・数値・文字列) -
boundaries_array:pointと同じデータ型の値を要素とする配列
仕様の詳細については、以下の Google Cloud ドキュメントをご確認ください。
使用例
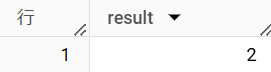
以下のように使用することで、入力した値が ['2025-02-01', '2025-02-11', '2025-02-21'] のどの区間に属するかを示すインデックスを返します。
'2025-02-12' を入力した時、'2025-02-11' から '2025-02-21' の区間に該当するため、2 が返ってきます。
SELECT
RANGE_BUCKET(
DATE '2025-02-12',
[DATE '2025-02-01', '2025-02-11', '2025-02-21']
) AS result;
このように、RANGE_BUCKET 関数を使用することで、データの分類をシンプルに行うことができます。
例えば、年齢を 0 ~ 5 のカテゴリに分類する場合、CASE 文では以下のようになります。
CASE
WHEN age < 20 THEN 0
WHEN age < 30 THEN 1
WHEN age < 40 THEN 2
WHEN age < 50 THEN 3
WHEN age < 60 THEN 4
ELSE 5
END
RANGE_BUCKET 関数を使用すると、これと同じ分類を次のようにシンプルに記述することができます。
RANGE_BUCKET(age, [20 ,30, 40, 50, 60])
この式は上記の CASE 文と同じ結果を返します。
それでは、この RANGE_BUCKET 関数を使った別の例を見てみましょう。
以下の例では、RANGE_BUCKET 関数を用いてユーザーを購入金額の範囲ごとにグループ分けし、それぞれのグループに属するユーザー数を集計しています。
グループ分けの条件
- インデックス 0:1000 円未満
- インデックス 1:1000 円以上 5000 円未満
- インデックス 2:5000 円以上 10000 円未満
- インデックス 3:10000 円以上
WITH purchase_info AS (
-- 販売データ
SELECT
'A' AS user_name,
5000 AS purchase_amount
UNION ALL
SELECT
'B',
2000
UNION ALL
SELECT
'C',
1000
UNION ALL
SELECT
'D',
10000
UNION ALL
SELECT
'E',
500
)
SELECT
RANGE_BUCKET(purchase_amount, [1000, 5000, 10000]) AS purchase_amount_range,
COUNT(*) AS user_count
FROM
purchase_info
GROUP BY
purchase_amount_range
ORDER BY
purchase_amount_range;

RANGE_SESSIONIZE
RANGE_SESSIONIZE 関数は、重複や隣接する区間をまとめて 1 つの区間とし、session_range 列を追加するテーブル関数です。
RANGE_SESSIONIZE(
TABLE table_name,
range_column,
partitioning_columns,
sessionize_option
)
各引数の説明は以下の通りです。
-
table_name: セッション化したい区間データがあるテーブルの名前 -
range_column: セッション化したい区間のカラム名 -
partitioning_columns: 区間をグループ分けする際に基準となるカラム名の配列 -
sessionize_option: 重複する区間だけでなく、隣接する区間もセッションに含めるかを指定する文字列(デフォルトはMEETS)-
MEETS: 隣接する区間を含める(重複+隣接) -
OVERLAPS: 隣接する区間を含めない(重複のみ)
-
仕様の詳細については、以下の Google Cloud ドキュメントをご確認ください。
使用例
では、実際に RANGE_SESSIONIZE 関数を使用してみます。
今回の例では、以下のテーブルを用意しました。

このテーブルを RANGE_SESSIONIZE 関数に代入すると、セッション化された区間のデータ(session_range)が作成されます。
SELECT
user_name,
duration,
session_range
FROM
RANGE_SESSIONIZE(
TABLE `mydataset.test_table`,
'duration',
['user_name']
)
ORDER BY
user_name;

RANGE_SESSIONIZE 関数の活用例として、重複したり隣接したりする複数の期間データを、1 つの連続した期間にまとめたいケースが考えられます。
以下の例では、この関数を使用して、従業員がいずれかのプロジェクトにアサインされている期間を特定しています。

assignment_info テーブル
SELECT DISTINCT
user_id,
session_range AS total_assignment_period
FROM
RANGE_SESSIONIZE(
TABLE `range_sessionize_test.assignment_info`,
'assignment_period',
['user_id']
)
ORDER BY
user_id, total_assignment_period;
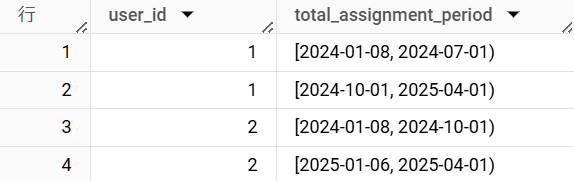
出力結果
この結果を活用することで、従業員がいずれのプロジェクトにもアサインされていない期間を分析し、効率的なアサイン管理につなげることができます。
このように、RANGE_SESSIONIZE 関数は、各要素に関連付けられた区間を要素ごとに統合し、区間の連続性や断続性を分析するのに役立ちます。
まとめ
今回の記事では、BigQuery の RANGE 関数について解説しました。
RANGE 関数を使えば、区間の比較、重複判定、統合などを複雑なロジックを組むことなく簡単に実現することができます。とても便利な関数ですので、興味のある方はぜひお試しください。
最後までご覧いただきありがとうございました。
Discussion