Google Cloud の Spanner に 新機能「Spanner Graph」が追加されました
はじめに
こんにちは、クラウドエース データソリューション部の森です。
データソリューション部では、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週開催しています。
新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
クラウドエース データソリューション部 について
クラウドエースの IT エンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
本記事では、2024 年 8 月 1 日にリリースされた、Spanner の新機能である「Spanner Graph」について紹介します。
要約
本記事の要約は以下の通りです。
- Spanner Graph は Spanner に追加された新しいグラフ データベース機能です。
- グラフ データベースの概念を使用してデータの関連性に着目して分析できます。
- 例:「誰がどの口座からローンを返済したか」、「誰が誰と友達か」などが挙げられます。
- 主な利点は以下です。
- データの関係性を直感的に可視化できます。
- 既存の Spanner データを利用できるため、データ移行や複製は不要です。
- 簡潔に深い関係性を持つデータの探索ができます。
- SQL(GoogleSQL、PostgreSQL) と GQL を組み合わせて使用できます。
- SQL:リレーショナルデータベースで使用するクエリです。GoogleSQL のみ ANSI 標準に準拠しています。
- GQL:Spanner Graph で使用するクエリです。ISO 標準に準拠しています。
Spanner とは
Spanner は、Google Cloud が提供するフルマネージドのデータベース サービスです。
具体的には、以下の特徴があります。(Google Cloud データベースページから引用)
- 無制限のスケール、グローバルな整合性、最大 99.999% の可用性、クラウドネイティブ。
- ピーク時には毎秒 30 億以上のリクエストを処理します。
- 10 GB のストレージを利用できる 90 日間の Spanner 無料トライアル インスタンスを作成できます。
- Oracle や DynamoDB のようなデータベースから移行できます。
Spanner の詳細は公式ドキュメントをご覧ください。
Spanner Graph とは
Spanner Graph の概要
Spanner Graph は、Spanner に新たに追加されたグラフ データベース機能です。
Spanner の基盤に、グラフ データベースの有用な機能を組み合わせて使用できます。
Spanner Graph を利用することで、従来のリレーショナル データベースでは表現が難しかった複雑なデータ関係を、これまでの手順より簡易的に表現できるようになります。
また、Spanner のテーブルデータを移行・複製することなく Spanner Graph で利用できるため、既存データが活用しやすいのもポイントです。
Spanner Graph を含むグラフ データベースでは、データをノード(点)とエッジ(線)という概念を使用して、データを表現します。
以下図のように、個人が所有する口座と、その口座で返済されたローンの関係を確認できるイメージです。

出典:Codelabs Spanner グラフを使ってみる
- ノード:個人(Person)、口座(Account)、ローン(Loan)
- エッジ:所有(Owns)、返済(Repays)
Spanner Graph のクエリでは、上記画像のような関係を以下のように表現します。
-
(Person {name: "Bob"})-[Owns]->(Account {id:18})-[Repays]->(Loan{to_id:27})
ノード((Person, Account, Loan))の間をエッジ(-[Owns, Repays]->)が繋いでいることが確認できます。
Spanner Graph の実際の処理では、以下の画像赤枠内のように表形式の結果が出力されます。
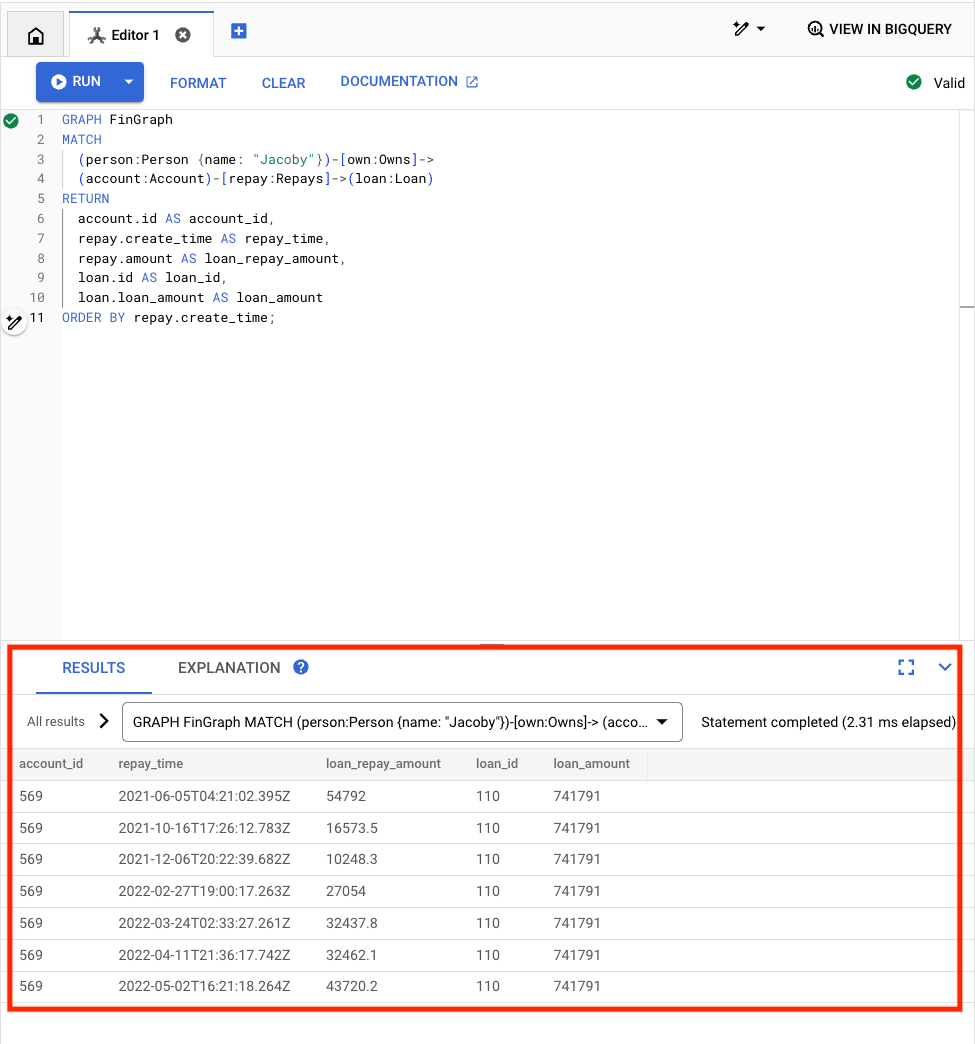
出典:Codelabs Spanner グラフを使ってみる
出力結果だけを見ると、SQL と変わりないように見えますが、データベースの概念や、クエリ言語が根本的に異なります。それらについては「Spanner Graph の前提知識」以降の項目で紹介します。
Spanner Graph の利点
Spanner Graph の利点は以下です。
-
データの関係性可視化
- データ同士のつながりを直感的に表現できます。
- 「誰が誰と友達か」、「どの商品がよく一緒に買われるか」といった関係性を、わかりやすく探索できます。
-
既存データの移行や複製が不要
- Spanner の既存のテーブルに対して、GQL(後述)を使用したデータ探索が可能です。
- データの移行や複製なしに、リレーショナル データベースとグラフ データベースの両方を活用できます。
-
クエリの簡潔性
- 深い関係性を持つデータの探索が、従来の SQL よりも簡潔(複数のテーブルを結合する複雑なクエリが不要)に記述できます。
-
ハイブリッドクエリ
- SQL と GQL を組み合わせて使用でき、柔軟なデータ分析が可能です。
-
国際標準への準拠
- GQL の国際標準である ISO GQL を採用しています。
Spanner Graph の前提知識
Spanner Graph の基本機能紹介の前に、以下の概念について理解しておく必要があります。
グラフ データベース
グラフ データベースは、データをノード(点)とエッジ(線)で表現するデータベースです。
グラフ データベースで使われる用語も把握しておきましょう。
-
GQL(Graph Query Language)
- グラフ データベースを操作するための専用言語です。
- ノードやエッジ、ラベル、プロパティを使用してデータをクエリすることが可能です。
-
ノード
- 分析対象となる「モノ」や「人」を表現します。
「顧客」、「製品」、「場所」などを表すことができます。
- 分析対象となる「モノ」や「人」を表現します。
-
エッジ
- ノードとノードの関係性を表現します。
「フォローしている」、「購入した」、「〜にある」といった関係性を表すことができます。
- ノードとノードの関係性を表現します。
-
ラベル
- ノードとエッジの種類を分類するために使用します。
「ユーザー」、「商品」、「購入」といったラベルを付けることができます。
ラベル単位でクエリができるため、特定のラベルが付与された対象に対して一括で同じ処理をすることが可能です。
- ノードとエッジの種類を分類するために使用します。
-
プロパティ
- ノードとエッジにキーと値のペアを情報として追加できます。
「年齢: 〇歳」、「顧客名: △△様」、「商品名: □□」といった情報を追加できます。
クエリの条件にキーや値を使用することができるため、細かなデータの絞り込みや探索が可能です。
- ノードとエッジにキーと値のペアを情報として追加できます。
Spanner Graph の基本機能
Spanner Graph の基本機能である以下 2 つの内容を紹介します。
- Spanner Graph スキーマ
- Spanner Graph クエリ
Spanner Graph スキーマ
Spanner Graph では、特定のスキーマ(データの構造)に従って、ノードやエッジなどを定義します。
GQL を使用するには、Spanner のテーブルに Spanner Graph スキーマを作成する必要があります。
具体的には、CREATE PROPERTY GRAPH ステートメントを使用してテーブルからノードやエッジなどを定義します。
例として、4 つのリレーショナル テーブルから、各個人が所有する口座間の送金情報を表現するために FinGraph という Spanner Graph スキーマを作成します。
イメージは以下画像をご確認ください。

次に、4 つのリレーショナル テーブルと Spanner Graph スキーマを作成するクエリを見ていきます。
-- 個人情報 テーブル作成
CREATE TABLE Person (
id INT64 NOT NULL,
name STRING(MAX),
birthday TIMESTAMP,
country STRING(MAX),
city STRING(MAX),
) PRIMARY KEY (id);
-- 口座情報 テーブル作成
CREATE TABLE Account (
id INT64 NOT NULL,
create_time TIMESTAMP,
is_blocked BOOL,
nick_name STRING(MAX),
) PRIMARY KEY (id);
-- 個人が所有する口座情報 テーブル作成
CREATE TABLE PersonOwnAccount (
id INT64 NOT NULL,
account_id INT64 NOT NULL,
create_time TIMESTAMP,
FOREIGN KEY (account_id) REFERENCES Account (id)
) PRIMARY KEY (id, account_id),
INTERLEAVE IN PARENT Person ON DELETE CASCADE;
-- 個人間の送金情報 テーブル作成
CREATE TABLE AccountTransferAccount (
id INT64 NOT NULL,
to_id INT64 NOT NULL,
amount FLOAT64,
create_time TIMESTAMP NOT NULL,
order_number STRING(MAX),
FOREIGN KEY (to_id) REFERENCES Account (id)
) PRIMARY KEY (id, to_id, create_time),
INTERLEAVE IN PARENT Account ON DELETE CASCADE;
-- Spanner Graph スキーマ作成
CREATE OR REPLACE PROPERTY GRAPH FinGraph
NODE TABLES (Account, Person) -- ノードとして口座と個人のテーブルを指定
EDGE TABLES ( -- エッジとして個人が所有する口座と個人間の送金情報を指定
PersonOwnAccount
SOURCE KEY (id) REFERENCES Person (id)
DESTINATION KEY (account_id) REFERENCES Account (id)
LABEL Owns,
AccountTransferAccount
SOURCE KEY (id) REFERENCES Account (id)
DESTINATION KEY (to_id) REFERENCES Account (id)
LABEL Transfers
);
まずは、Spanner Graph のラベルについて説明します。
Spanner Graph では、ノードとエッジの識別にラベルを使用します。これは、スキーマに対するクエリ発行時にラベルを指定する必要があるためです。
ラベルは、ノードとエッジを作成する際に任意の値を付与できます。ラベルを明示的に指定しなかった場合は、入力テーブル名が自動的にラベルとして付与されます。
続いて「Spanner Graph スキーマ作成」の内容を確認します。
CREATE OR REPLACE PROPERTY GRAPH FinGraph 内で、以下のノードとエッジを指定しています。
-
ノード指定
-
NODE TABLESでは、口座を表すAccountテーブルと個人を表すPersonテーブルをノードに指定しています。 - ラベルを明示的に指定しないため、入力テーブル名(
Account、Person)が自動的にラベルとして付与されます。
-
-
エッジ指定
-
EDGE TABLESでは、以下の 2 種類の関係を指定することで、個人が所有する口座と個人間の送金情報をエッジとして指定しています。-
PersonOwnAccount:PersonノードとAccountノードを繋ぐエッジです。Ownsラベルを付与しています。 -
AccountTransferAccount:Accountノードから別のAccountノードを繋ぐエッジです。Transfersラベルを付与しています。
-
-
各リレーショナル テーブルへのデータの格納は本記事の要旨ではないため、省略しています。
詳細は公式ドキュメント(Set up and query Spanner Graph using the Google Cloud console)をご覧ください。
ノード、エッジ、ラベル、プロパティを含むスキーマの設定方法については、公式ドキュメント(GQL schema statements)をご覧ください。
Spanner Graph クエリ
Spanner Graph では、GQL を使用して Spanner Graph スキーマにクエリを発行します。
ノードやエッジを検索したり、関係性を辿ったりすることで、必要な情報を抽出します。
それでは、「Spanner Graph スキーマ」の項目で作成したスキーマに対してクエリを発行してみましょう。
以下のクエリは、FinGraph 内の全てのノードを検索し、そのノードに付与されているラベルと ID を取得するものです。
GRAPH FinGraph
MATCH (n) -- マッチするノードを抽出
RETURN LABELS(n) AS label, n.id; -- label と id を返す
--出力結果
/*---------------+
| label | id |
+---------------+
| Account | 7 |
| Account | 16 |
| Account | 20 |
| Person | 1 |
| Person | 2 |
| Person | 3 |
+---------------*/
MATCH (n) は、グラフ内の全てのノードを対象とし、RETURN LABELS(n) でそのノードのラベルを返し、n.id でノードのIDを返します。
クエリ下部の出力結果の表を確認すると、グラフスキーマで定義した Account ノードと Person ノードの ID が確認できました。
続いて、特定の人物が所有する口座から他の口座への送金の関係を取得するクエリを記載します。
GRAPH FinGraph
MATCH
(p:Person {id: 2})-[:Owns]->(account:Account)-[t:Transfers]->
(to_account:Account)
RETURN
p.id AS sender_id, -- 送金者の ID
account.id AS from_id, -- 送金元口座の ID
to_account.id AS to_id; -- 送金先口座の ID
--出力結果
/*-----------------------------+
| sender_id | from_id | to_id |
+-----------------------------+
| 2 | 20 | 7 |
| 2 | 20 | 16 |
+-----------------------------*/
MATCH の処理を具体的に見ていきます。
-
ノード
-
(p:Person {id: 2})-
Personのラベルが付与されたノードを指定しています。 -
{id: 2}で、idが 2 のPersonノードを条件に指定しています。 -
p:は、マッチしたPersonノードを参照するための変数名です。
-
-
(account:Account)-
Accountのラベルが付与されたノードを指定しています。 - 条件を指定しないため、
Accountラベルを持つすべてノードが対象です。 -
account:は、マッチしたPersonノードを参照するための変数名です。
-
-
-
ラベル
-
-[:Owns]->- 前のノードと後のノードをつなぐエッジを指定しています。
-
PersonノードからOwnsのラベルが付与されたエッジを辿り、Accountノードに接続します。
これにより、idが 2 の人物が所有する口座が辿れます。
-
-[t:Transfers]->-
AccountノードからTransfersのラベルが付与されたエッジを辿り、別のAccountノードに接続します。
これにより、idが 2 の人物が所有する口座の送金先口座が辿れます。
-
-
クエリ下部の出力結果の表を確認すると、送金者の ID、送金元口座の ID、送金先口座の ID を探索できていることがわかりました。
SQL と GQL を組み合わせたクエリ
FinGraph 内のノードから特定の name と id を抽出する処理を、SQL と GQL を組み合わせて記述する方法を紹介します。
処理内容は、1 つ前のクエリで確認した FinGraph のクエリ結果を元に、name の値が Alex の行を抽出しています。
SELECT name, id -- name と id を選択
FROM GRAPH_TABLE(
FinGraph
MATCH (n) -- マッチするノードを抽出
RETURN n.name AS name, n.id AS id -- name と id を返す
)
WHERE name = "Alex"; -- 名前が Alex の行を抽出
--出力結果
/*-----------+
| name | id |
+-----------+
| Alex | 1 |
+-----------*/
クエリ結果では、name に Alex が格納されている 1 行のみが抽出できます。
このように、SQL と GQL を組み合わせた処理が記述できるため、SQL で結合を多用している箇所を部分的に GQL に置き換えるなど、処理の複雑さ解消が見込めます。
Spanner Graph クエリの詳細は、Spanner Graph クエリ構造をご覧ください。
SQL と GQL の組み合わせ使用の詳細は、公式ドキュメント(GQL within SQL)をご覧ください。
Spanner Graph の制限・注意事項
記事執筆時点(2024 年 9 月 27 日)では、Spanner Graph はプレビュー版として提供されており、サポートが制限されている可能性があります。
詳細については、リリース ステージの説明を参照してください。
また Spanner では 2024 年 9 月 24 日に、Spanner Editions がリリースされました。これによって、 Spanner を利用するにあたり利用者はまずどの Edition を利用するかを決めなければならなくなりました。今回ご紹介した Spanner Graph の機能は、Spanner Enterprise エディションおよび Enterprise Plus エディションのいずれかでないと利用できないため注意してください。
Spanner Graph の料金
Spanner 自体の利用には料金がかかりますが、Spanner Graph の利用による追加料金はかかりません。
Spanner 自体の料金情報は、Spanner の料金ページをご覧ください。
また、Spanner Editions では、上記の料金体系ではなく Spanner Editions の料金体系が適用されるため注意が必要です。
Spanner Editions の料金詳細は公式ドキュメントをご覧ください。
まとめ
Spanner Graph はリレーショナル データベースのパフォーマンスを維持しつつ、グラフ データベースの特長を取り入れることで、複雑なデータ関係の理解を容易にする新機能です。
従来の SQL ベースのデータ分析に加え、グラフ データベースの概念を使用したデータの関連性分析が可能になります。
今後の正式版リリースが待ち遠しいですね。
Discussion
とありますが
なので現状 GoogleSQL 専用ではないでしょうか。
apstndb 様
この度はコメントをくださりありがとうございます。
ご指摘について、社内にて確認の上、ご返答いたします。
指摘通り、現状 GoogleSQL 専用のため、「SQL(GoogleSQL、PostgreSQL) と GQL を組み合わせて使用できます。」の文言は誤りとなり、正しくは、「SQL(GoogleSQL)と GQL を組み合わせて使用できます。」になります。
この度は、貴重なご指摘をくださり、心より感謝を申し上げます。
引き続き、弊社 Zenn をよろしくお願いいたします。