Cloud Run は本当に十分なインスタンス数を用意してくれるようになったのか
こんにちは。フルマラソンは 2 ヶ月前から準備する吉崎です。
マイナーな変更かもしれませんが、Cloud Run の新しいリビジョンをデプロイした際、十分なインスタンスが起動するようになったのをご存知でしょうか。
以下、短文ですのでリリースノートを転記します。
When deploying a new revision, Cloud Run now starts enough instances of the new revision before directing traffic to it. This reduces the impact of new revision deployments on request latencies, notably when serving high levels of traffic.
私は、このリリースを見たとき、「何を以て enough なんだ?」と感じました。
このため、本稿ではこの enough (「十分な」の意)の根拠を考察します。
予想
このリリースを以て enough になったということは、これまでは not enough だったということです。以前は下図のようだったのだろうと予想しています。
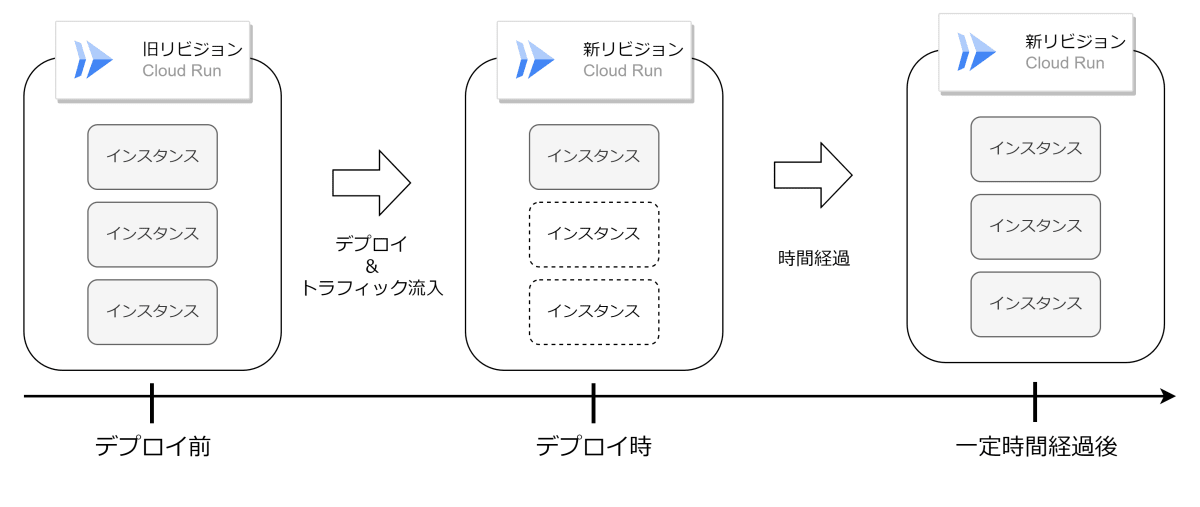
予想(リリース前)
インスタンスが複数立ち上がるような負荷が続いている状況で新リビジョンをデプロイしたとき、旧リビジョンで起動していたインスタンスは確保されず、負荷に応じて新リビジョンのインスタンスが徐々に起動していったことを表しています。デプロイ時にリクエストを処理しきる十分なインスタンスが確保されていないため、たとえば 429(Too Many Requests)や 500(Internal Server Error)を引き起こしてしまったのだろうと思います。対して、リリース後は下図のようになったものと予想しています。
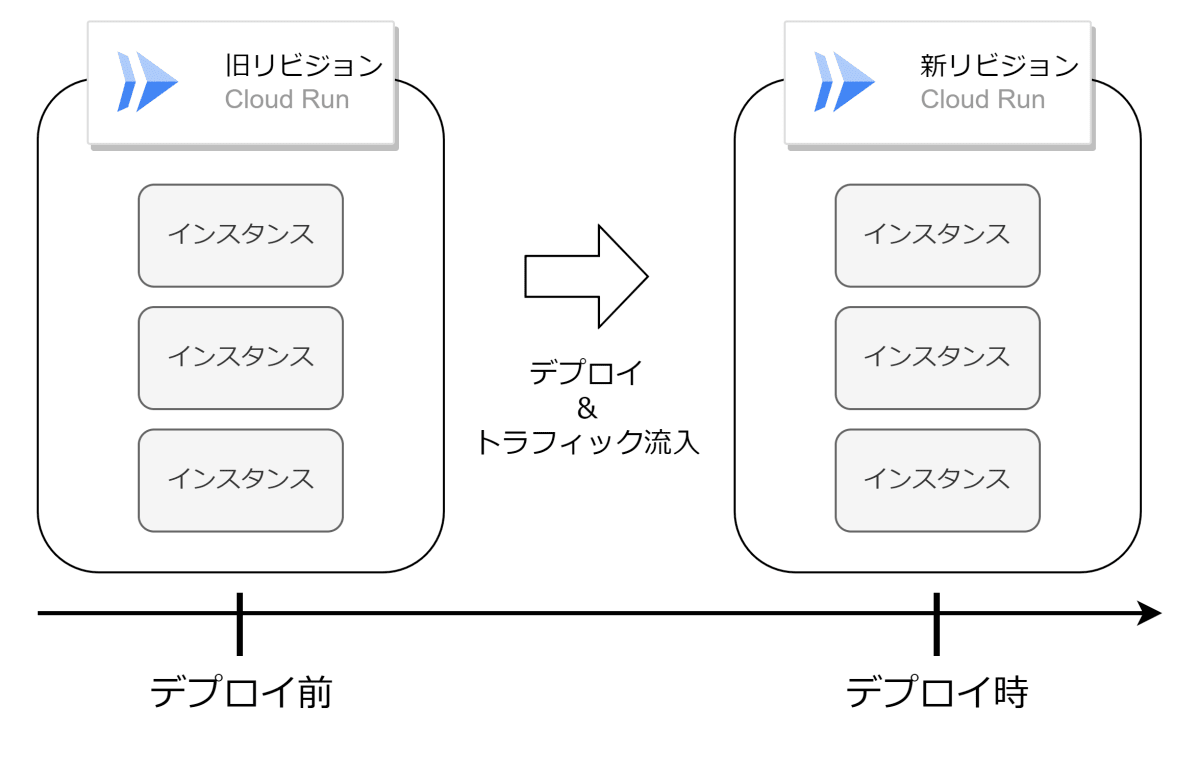
予想(リリース後)
新リビジョンのデプロイ時、旧リビジョンで起動していたインスタンスと同じ数だけインスタンスを起動していることを表しています。つまり、このリリースでいう enough とは、新旧で同じインスタンスの数を確保する、ということだと予想します。残念ながら本リリースが Cloud Run の第一世代、第二世代ともに適用されている場合、リリース前後の検証はできません。リリースノートを見る限り世代の別に言及していないため、恐らく両世代に適用されたものと思います。
enough を実現するためのパラメータ
Cloud Run には、スループット[1]を左右するパラメータに以下のものがあります。
- 最小/最大インスタンス数
- 起動時の CPU ブースト
- メモリ
- CPU
- リクエストタイムアウト
- 最大同時リクエスト数
- 第1世代/第2世代
enough を実現する上でメモリ・CPU・最大同時リクエスト数は重要な要素と考えられるため、今回はこの 3 つの要素に着目して検証します。
検証方法
以下のパターンに分けて実施します。
- 新旧リビジョンで何も変更しなかった場合
- 新リビジョンの CPU を減らした場合
- 新リビジョンの最大同時リクエスト数を減らした場合
- 新リビジョンのメモリを減らした場合
※スペックダウンの場合のみ検証し、スペックアップの場合は検証しません。
なお、すべての検証で下記の設定は共通です。
| 最小/最大インスタンス数 | リクエストタイムアウト |
|---|---|
| 0/100 | 3600s |
以下、検証に用いたプログラムを説明します。
メモリの検証に用いたプログラム
500KB のデータをインメモリ ファイルシステムにファイルとして書き込み、500 ミリ秒待機するというプログラムです。500KB と 500 ミリ秒という数字は、メモリ上限が 1024MiB のときにメモリ使用率が 100%を超えず、インスタンス数を 10 程度で維持することが確認出来た際の数字です。
memory.go
package main
import (
"log"
"net/http"
"os"
"strings"
"github.com/google/uuid"
"time"
)
func main() {
http.HandleFunc("/", handler)
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatal(err)
}
}
func handler(w http.ResponseWriter, r *http.Request) {
log.Printf("SERVICE:%s, REVISION:%s\n", os.Getenv("K_SERVICE"), os.Getenv("K_REVISION"))
// ファイルパスを定義
uuid := uuid.NewString()
filePath := "/tmp/" + uuid + ".txt"
// データを定義(ここでは1MBのテキストデータを作成)
data := strings.Repeat("a", 500*1024) // 500KB
// ファイルを開く(存在しない場合は作成、存在する場合は追記モード)
file, err := os.OpenFile(filePath, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
log.Fatalf("Failed to open file: %v", err)
}
if _, err := file.WriteString(data); err != nil {
log.Fatalf("Failed to write to file: %v", err)
}
// ファイルを閉じる
if err := file.Close(); err != nil {
log.Fatalf("Failed to close file: %v", err)
}
time.Sleep(500 * time.Millisecond)
}
メモリ以外の検証に用いたプログラム
10^10 回ループをするだけのものです。CPU をよく使用し、実行時間を稼ぎます。なお 10^10 という数字も深い意味はなく、2vCPU のリビジョンに負荷をかけて 10 程度のインスタンスが維持されることを確認した際の数字です。
main.go
package main
import (
"log"
"math"
"net/http"
"os"
)
func main() {
http.HandleFunc("/", handler)
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatal(err)
}
}
func handler(w http.ResponseWriter, r *http.Request) {
log.Printf("SERVICE:%s, REVISION:%s\n", os.Getenv("K_SERVICE"), os.Getenv("K_REVISION"))
// 10^10回ループ
for i := 0; i < int(math.Pow10(10)); i++ {
continue
}
}
負荷かけツール
負荷かけには、siege を使いました。メモリ検証の場合はプログラムがすぐに実行終了するため同時接続数(-c)を 100 にしています。メモリ以外の検証の場合は 10^10 回のループにより処理時間が 6,7 秒かかる点、CPU 使用率が 80%程度となる点から同時接続数を 10 にしています。どちらも 10 程度のインスタンスが維持されることを確認しています。
# メモリ検証の場合
siege -t 600s -c 100 https://foobar-an.a.run.app
# メモリ以外の検証の場合
siege -t 600s -c 10 https://hogehoge-an.a.run.app
検証結果
新旧リビジョンで何も変更しなかった場合
新旧リビジョンで設定を何も変えなかった結果、enough なようです。
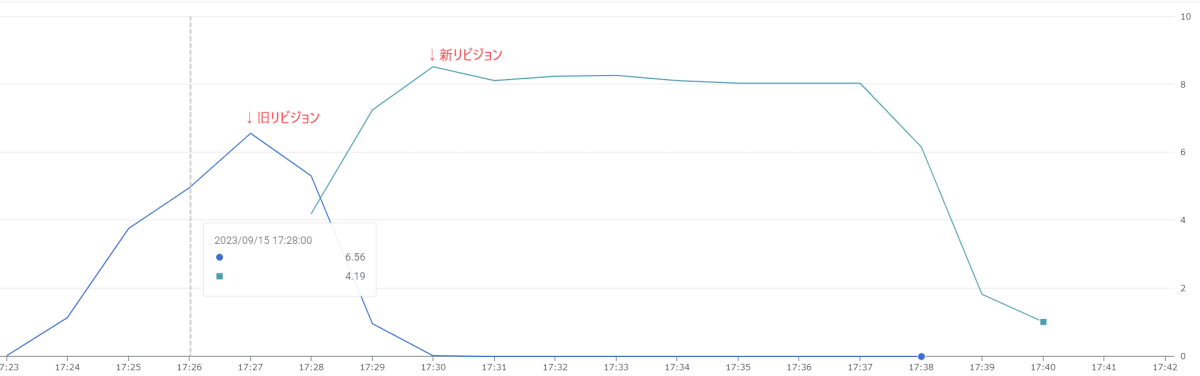
新旧リビジョンのインスタンス数の遷移(設定の変更なし)
X 軸は時間、Y 軸はインスタンスの数[2]を表しています。新旧の線が交差する 17:28 の時点で新リビジョンのインスタンス数=旧リビジョンのインスタンス数となっています。また、交差する前から旧リビジョンのインスタンス数が減少しています。このことから、旧リビジョンと同じ数のインスタンスが起動してから新リビジョンにトラフィックが流入したものと判断できます。なお、本ケースは何度か実施しましたが、いずれも旧リビジョンのインスタンス数<新リビジョンのインスタンス数となることが確認できています。

17:26:42 に新リビジョンの最初のログが出力されている
なお、モニタリングのサンプリング レートは 1 分間隔であり、データの取得には最大 4 分かかる場合があります(下記ドキュメント参照)。このため、ログの時刻とモニタリングの時刻は 1 分以上ずれると見るのが適切です。今回も、ログでは 17:26 の時点で新リビジョンが READY ですが、モニタリング上では 17:28 あたりに新リビジョンのインスタンス数が増加しています。
新リビジョンの CPU を減らした場合
| 旧リビジョン | 新リビジョン |
|---|---|
| 2vCPU | 1vCPU |
何も変更しなかったときと同様、旧リビジョンより新リビジョンの方がインスタンス数が多くなり enough だろうという結果になりました。エラーはありませんでした。vCPU が半分になりインスタンス数はおよそ 2 倍になっています。CPU 使用率は 2vCPU のときでさえ 1 リクエストにより 80%を超えていたため、インスタンス数が 2 倍になることは有効ではなさそうです。(本来は CPU 負荷が半分程度のプログラムであることが望ましいです...)
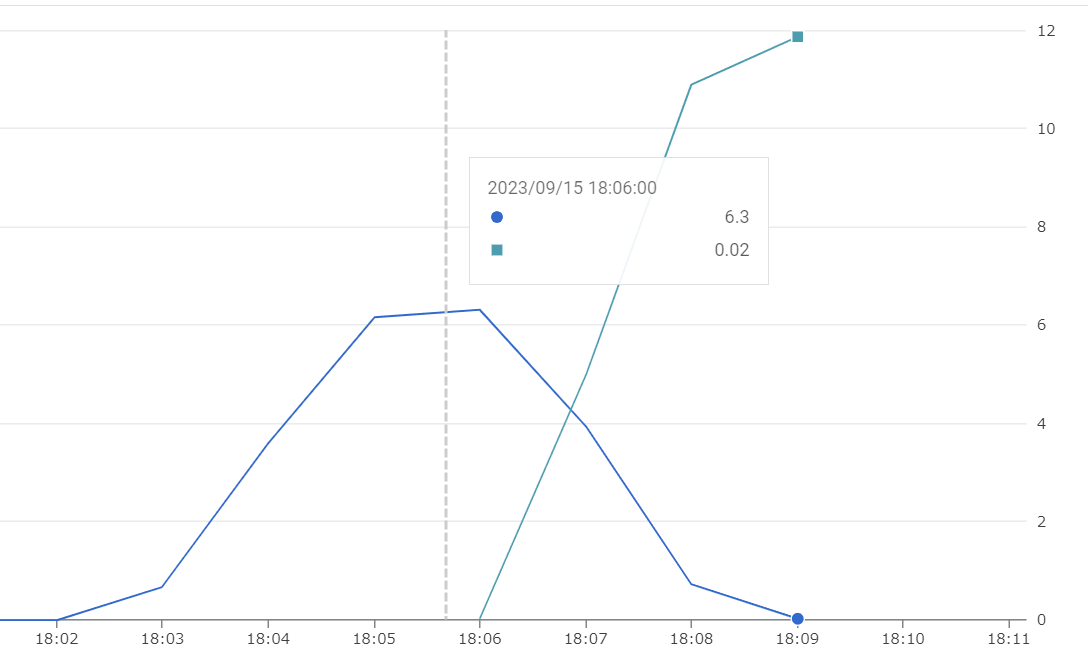
新旧リビジョンのインスタンス数の遷移(CPU ダウン)
ログ上は 18:05 に新リビジョンが READY になっていますが、モニタリング上は 18:06 からインスタンスが起動しているように見えます。

新リビジョンのメモリを減らした場合
| 旧リビジョン | 新リビジョン |
|---|---|
| 1024MiB | 512MiB |
下図のログの通り、デプロイ後にメモリ不足によりインスタンスがクラッシュしたため、not enough という結果になりました。

メモリ上限を超えクラッシュが発生しているログ
インスタンス数は下図の通りとなりました。

新旧リビジョンの数はほとんど変わらない
旧リビジョンの最大インスタンス数である 10 程度に対し、新リビジョンでは 9 程度のインスタンスが起動されました。メモリはリビジョンごとではなくインスタンスごとに割り当てられますので、メモリを減らした場合は同程度のインスタンス数では足らず、クラッシュが発生する結果となりました。参考に、下記はデプロイ前後のメモリ使用率です。
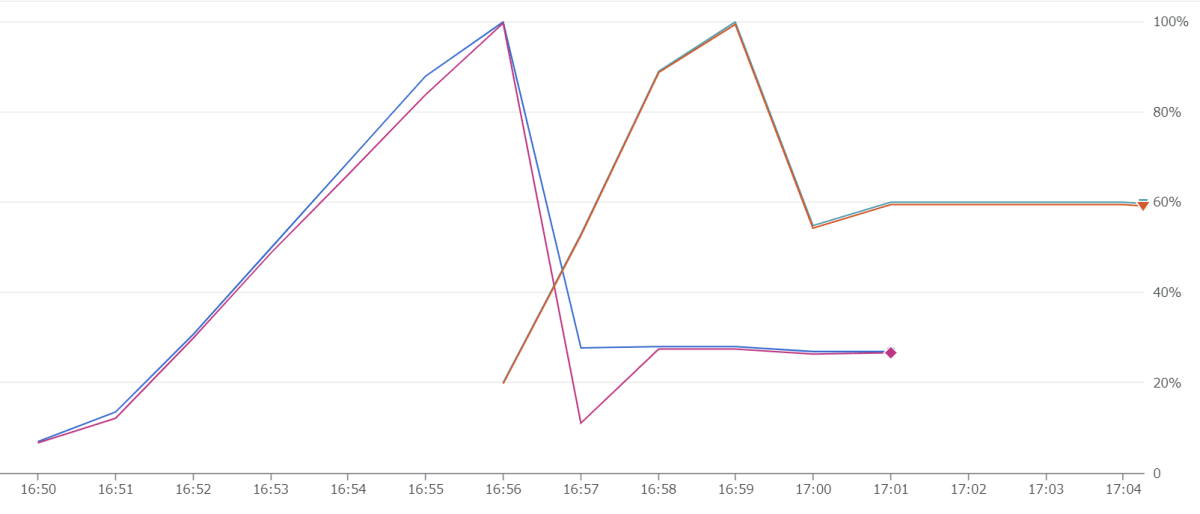
新旧リビジョンでメモリ使用率が 100%に到達している
※実はデプロイ前もメモリ不足によりクラッシュは発生しているのですが、デプロイ後はインスタンス数が enough であればクラッシュしないはずです。
新リビジョンの最大同時リクエスト数を減らした場合
| 旧リビジョン | 新リビジョン |
|---|---|
| 10 | 5 |
最大同時リクエスト数を半分にした結果は、enough なようです。エラーはありませんでした。直感的には必ず 2 倍のインスタンスが必要だろうと思っていましたが、9→14 程度と 1.5 倍程度です。なお繰り返しになりますが負荷は 10 分間継続するため、途中でリクエスト数が減ったとは考えにくいです。リクエスト数の指標を確認しましたが、およそ同じ RPS(Requst Per Second) でした。

約 1.5 倍のインスタンスが起動している
結果考察
検証の妥当性
今回のリリース適用前との比較が出来ないため、enough に見えるだけ、という可能性を捨てきれません。念のため、各検証においてはデプロイせずに負荷をかけ続けた場合のインスタンス数を観察しています。また、たとえば CPU を減らすケースでは、デプロイ後である 1vCPU の状態で負荷をかけ 10 インスタンス程度しか起動しないことを確認しています。このため、デプロイによるインスタンス数の増加であることは間違いないと思います。
また、Cloud Run のオートスケーラがスケーリングに用いる指標はドキュメントに記載されています。具体的には以下の指標です。
- 受信リクエストまたはイベントのレート
- リクエストまたはイベントを 1 分以上処理中の既存インスタンスの CPU 使用率(スケジュールされたインスタンスを CPU 使用率 60% に維持するためのターゲティング)。
- 1 分間でのリクエストの最大同時実行数と比較した現在の同時実行数。
- インスタンスの最大数の設定
- インスタンスの最小数の設定
これらが 5 秒ごとに評価されますが、本検証においては上記の指標に応じたスケーリングとは考えにくいです。どの指標も新旧リビジョンで同等なためです。つまり、ドキュメントに記載されていない指標をもとに新リビジョンのインスタンスがスケーリングされたと判断できます。
また、すべて Cloud Run 第二世代の結果を載せましたが、第一世代で実施した場合も同様の結果となることを確認しています。このため、リリース前後の比較が出来ず、妥当性の論拠が少し弱いのが痛い点です。
結論
結果をまとめると以下の通りです。
| パターン | 旧リビジョン インスタンス数 |
新リビジョン インスタンス数 |
enough? |
|---|---|---|---|
| 何も変更しなかった | 7 | 8 | Yes |
| CPU を減らした | 6 | 12 | Yes |
| メモリを減らした | 10 | 9 | No |
| 最大同時リクエスト数を減らした | 9 | 14 | Yes |
これらの結果より、以下の結論を導けます。
- CPU・最大同時リクエスト数については十分なインスタンスを起動するために考慮されている
- メモリについては考慮されていない
- 新旧で同程度もしくは新リビジョンの方が多くのインスタンスが確保される
3 点目は予想と似ており、本リリースによる変更を的確に示す結論かと思います。
読者皆様におかれましては
本検証は不確実性をはらむ結論を導いていますので、ご自身の環境に合った試験を実施の上 Cloud Run リビジョンを更新してください。高負荷が続くアプリケーションを更新する際は、なるべく負荷の低い時間帯を選んで更新しましょう。やむなく高負荷状態でスペックを落とす際は、適切なデプロイ戦略を選択しましょう。たとえば、新旧アプリケーションに互換性があれば、一度にトラフィックをすべて新リビジョンに流すのではなく、カナリア デプロイのようにトラフィックを少しずつ新リビジョンに流すのも 1 つの手です。また、ロードバランサを用いることでもトラフィック分割は可能です。不確実性を低減したアプリケーション更新を模索しましょう。
最後に
メモリを消費するプログラム、実行時間を稼ぐプログラムは powered by GPT です。この程度の簡単なプログラムであればすぐに動作するプログラムを書いてくれる GPT は便利ですね。また、負荷かけにあたっては siege を用いましたが、apache bench の代替を謳う hey も使い勝手が良さそうです。筆者環境は Ubuntu 22.04 on WSL2 であり、siege が apt のパッケージとして簡単に入手できるため siege を使いました。負荷かけにあたっては、Cloud Run のインスタンスは最大で 15 分アイドル状態を維持する特性より次の負荷かけまで待つのが惜しかったため、新しいサービスを作成してそちらで実施することで時間効率を高めました。同様の実験をされる方はご参考ください。
最後に、本稿の検証方法、結果について知見のある方はコメントにて教えていただけると嬉しいです。吉崎でした。
Discussion