BigQuery の 履歴ベースの最適化 (History-based Optimizations) を試したかった
はじめに
こんにちは、クラウドエース データソリューション部所属の濱です。
データソリューション部では、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。
新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
クラウドエース データソリューション部 について
クラウドエースの IT エンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
今回紹介するリリースは、2024年4月1日にリリースされた「クエリの履歴ベースの最適化 (History-based Optimizations) を有効/無効/分析できるようになった」というものです。該当リリースは こちら からご覧ください。
概要
履歴ベースの最適化とは
公式ドキュメント では、 すでに実行した類似クエリの実行情報を使用して追加の最適化を適用し、消費スロット時間やクエリレイテンシなどのクエリパフォーマンスを向上させる と説明されています。
最適化のイメージも併せて紹介されていたので、こちらでも紹介します。あくまでもイメージですので、この通りに最適化が行われるわけではない点に注意してください。
| 実行回数 | クエリスロットの消費時間 | 最適化の有無 |
|---|---|---|
| 1 | 60 | 最初の実行 |
| 2 | 30 | 1回目の履歴ベースの最適化 |
| 3 | 20 | 2回目の履歴ベースの最適化 |
| 4 | 21 | 適用する追加の最適化がない |
| 5 | 19 | 同上 |
| 6 | 20 | 同上 |
ユースケース
類似の定義は 公式ドキュメント には記載がありません。したがって、ロジックが似ている(= 類似した)処理を繰り返し行う 場合に本機能が適用され、利用料金や時間の節約になると考えられます。
「キャッシュ とか マテリアライズドビュー とかでいいんじゃないの?」と思われる方も多いと思いますが、以下のように分けられるため、微妙に棲み分けができているんですね。
| 名称 | 概要 |
|---|---|
| キャッシュ | 全く同じ処理を再実行 |
| マテリアライズドビュー | 頻繁に実行される結果を事前処理 |
| 履歴ベースの最適化 | 類似クエリの実行情報をもとに最適化 |
試してみる
ここから実際に、履歴ベースの最適化を試してみましょう。
以下の手順で検証を進めていきます。
- 検証に必要な準備を行う(権限やプロジェクト名の確認)。
- 履歴ベースの最適化の有効化を行う。
- 最適化されそうなクエリを作る。
- 基準となるクエリを実行する。
- 最適化されそうなクエリを実行する。
- 実際に最適化されているか確認する。
前準備
権限の確認
最適化を試すにあたり、必要な権限は、bigquery.config.get です。
それを内包するロール一覧が以下となります。
roles/bigquery.jobUserroles/bigquery.dataEditorroles/bigquery.dataUser
これらの権限を持っているかどうかは、「IAM と管理」から確認することができます。詳細は 公式ドキュメント をご覧ください。
プロジェクト名の確認
Google Cloud コンソール画面左上 に常に表示されている情報となります。本稿で掲載しているクエリの中にプロジェクト名と書かれている部分が出てきますので、都度この部分を書き換えながら作業を進めてください。
履歴ベースの最適化を有効にする
履歴ベースの最適化を 有効 にするには、以下のクエリを無題のクエリ内にコピペして実行します。
ALTER PROJECT `プロジェクト名`
SET OPTIONS (
`region-us.default_query_optimizer_options` = 'adaptive=on'
);
実行して数秒待つと、「クエリ結果」に 「ALTER PROJECT が成功しました。既存のクエリが古いデフォルト(デフォルトのタイムゾーンなど)に依存していないことを確認してください。そうしないと、これらのクエリは機能しなくなります。」 と表示されます。
(後半の「これらのクエリは機能しなくなります。」は、公式ドキュメントの Noteによると、無視して大丈夫のようです。)

これが表示されたら、有効化は完了です。
履歴ベースの最適化を無効化する方法
履歴ベースの最適化を 無効 にするには、さきほどのクエリの'adaptive=on'を'adaptive=off'に変更して実行します。
ALTER PROJECT `プロジェクト名`
SET OPTIONS (
`region-us.default_query_optimizer_options` = 'adaptive=off'
);
これについても有効化と同様、「クエリ結果」に 「ALTER PROJECT が成功しました。既存のクエリが古いデフォルト(デフォルトのタイムゾーンなど)に依存していないことを確認してください。そうしないと、これらのクエリは機能しなくなります。」 と表示されたのを確認して、無効化が完了となります。
最適化されそうなクエリを作成する
再度確認しますが、 公式ドキュメント では、「すでに完了した類似のクエリの実行から得た情報で最適化される」 という条件しか明記されていません。
「類似のクエリ」の定義が分からなかったため、さまざまな類似パターンを考えました。
- SELECT するカラムの違い
抽出するカラムの数を変えてみる - 集約関数の違い
例えば、SUM 関数と AVG 関数の違いなど - WHERE 句の違い
WHERE 条件で、別の条件を指定する - データソースの違い
全く脈絡のないデータソースを指定する
基準となるクエリを実行する
ここから、すべての基準となるクエリを実行します。
以下のクエリを「無題のクエリ」にコピペします。このクエリは、bigquery-public-data に存在する野球の試合のデータについて、総得点と試合数をカウントする クエリとなります。
SELECT
homeTeamName,
awayTeamName,
gameId,
SUM(homeFinalRuns) as total_homeFinalRuns,
SUM(awayFinalRuns) as total_awatFinalRuns,
COUNT(gameId) as count_game
FROM `bigquery-public-data.baseball.games_post_wide`
WHERE homeTeamName = "Blue Jays"
GROUP BY 1,2,3
ORDER BY 1
このクエリ結果の「実行の詳細」を確認します。

消費スロット時間は 321 ミリ秒 でした。
最適化されそうなクエリを実行する
ここから、前項で実行したクエリを、類似クエリの条件に基づいて変更し、クエリを実行します。
SELECT するカラムの違い
先ほどと同じように、「無題のクエリ」を作成して以下のクエリをコピペします。基準クエリとの違いは、homeTeamName、awayTeamNameがそれぞれhomeTeamId、awayTeamIdになっています。
SELECT
homeTeamId,
awayTeamId,
gameId,
SUM(homeFinalRuns) as total_homeFinalRuns,
SUM(awayFinalRuns) as total_awatFinalRuns,
COUNT(gameId) as count_game
FROM `bigquery-public-data.baseball.games_post_wide`
WHERE homeTeamName = "Blue Jays"
GROUP BY 1,2,3
ORDER BY 1
「実行の詳細」を確認します。

消費スロット時間は 152 ミリ秒 でした。ほとんど基準クエリと同じクエリを実行しましたが、基準クエリのクエリ結果と比較して、消費スロット時間が約半分になっています。
集約関数の違い
以下のクエリをコピペします。基準クエリとの違いは、SUMだった部分がAVGになっています。
SELECT
homeTeamName,
awayTeamName,
gameId,
AVG(homeFinalRuns) as total_homeFinalRuns,
AVG(awayFinalRuns) as total_awatFinalRuns,
COUNT(gameId) as count_game
FROM `bigquery-public-data.baseball.games_post_wide`
WHERE homeTeamName = "Blue Jays"
GROUP BY 1,2,3
ORDER BY 1
「実行の詳細」を確認します。
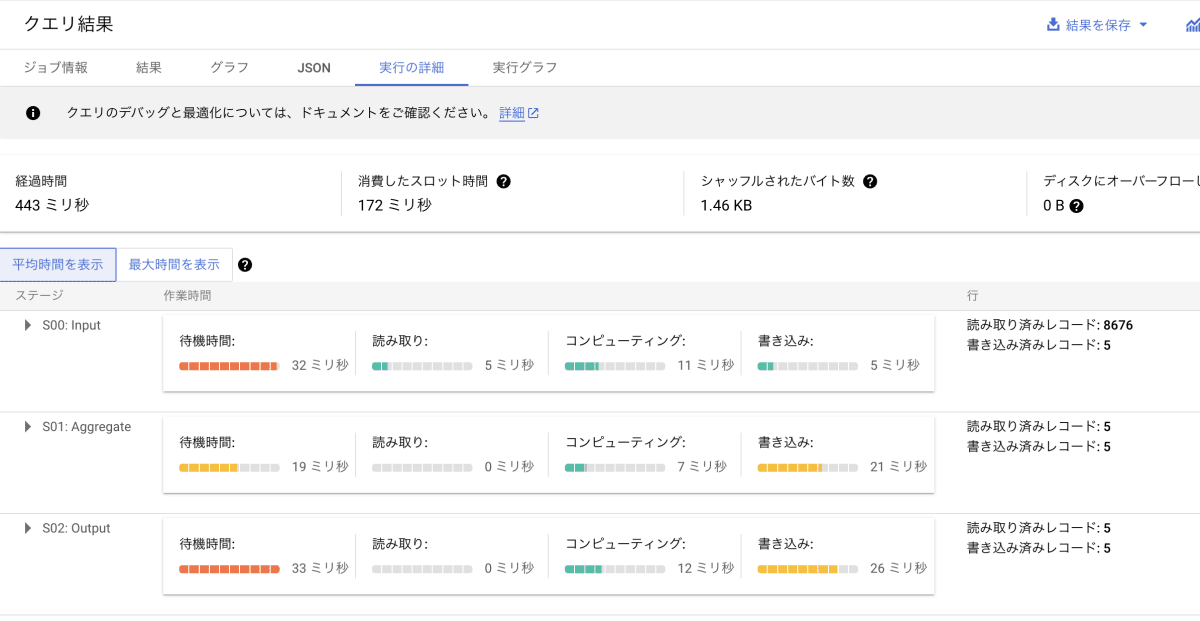
消費スロット時間は 172 ミリ秒 でした。こちらもほとんど基準クエリと同じクエリを実行しましたが、基準クエリのクエリ結果と比較して、消費スロット時間が約半分になっています。
WHERE 句の違い
以下のクエリをコピペします。基準クエリとの違いは、WHERE homeTeamName = "Blue Jays" だった部分が WHERE awayTeamName = "Red Sox" になっています。
SELECT
homeTeamName,
awayTeamName,
gameId,
SUM(homeFinalRuns) as total_homeFinalRuns,
SUM(awayFinalRuns) as total_awatFinalRuns,
COUNT(gameId) as count_game
FROM `bigquery-public-data.baseball.games_post_wide`
WHERE awayTeamName = "Red Sox"
GROUP BY 1,2,3
ORDER BY 1
「実行の詳細」を確認します。
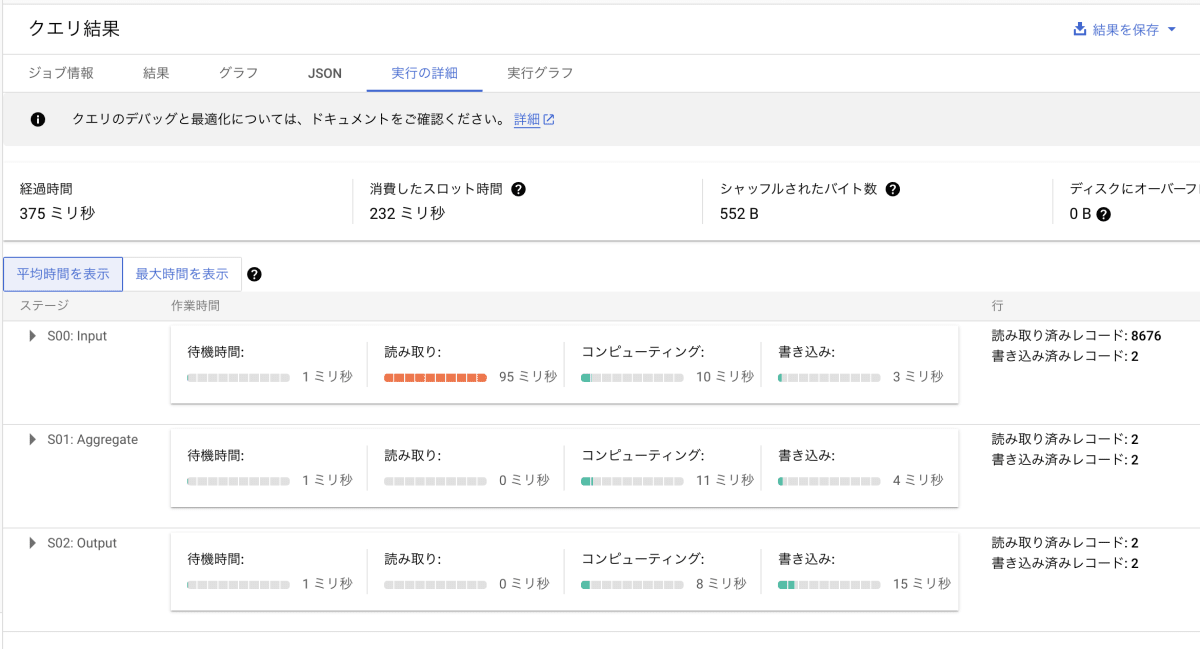
消費スロット時間は 232 ミリ秒 でした。基準クエリと比べて、消費スロット時間が約 70 %となりました。
データソースの違い
以下のクエリをコピペします。こちらは、アイオワ州のお酒の販売データについて、ベンダーと銘柄の売上や合計量に関するクエリと なっています。
データソースは違えど、SUMやCOUNT を用いている点や、FROM 以下の条件についても似た形をとっています。
SELECT
item_description,
vendor_name,
SUM(bottle_volume_ml),
SUM(bottles_sold),
COUNT(item_description)
FROM `bigquery-public-data.iowa_liquor_sales.sales`
WHERE county = 'SCOTT'
GROUP BY 1,2
ORDER BY 1
「実行の詳細」を確認します。
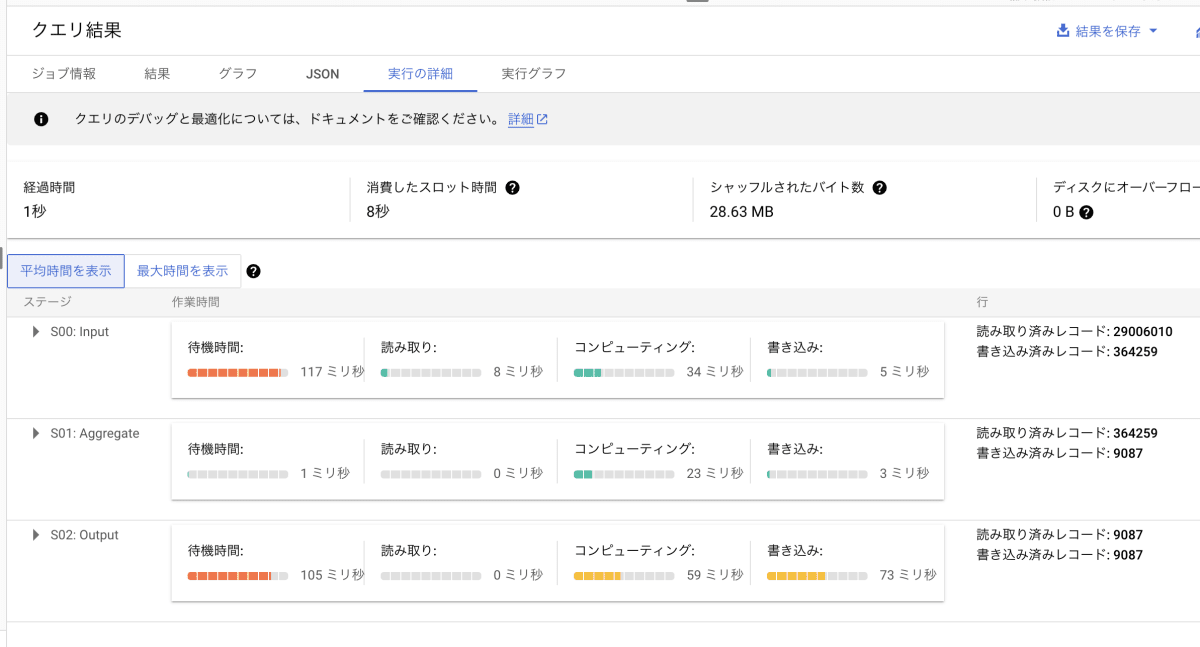
消費スロット時間は 6000 ミリ秒 (6 秒) でした。そもそも処理するデータ量が約 1.82 GB と多く、このような結果になったと思われます。
実際に最適化されているか確認する
ここから、実際に履歴ベースの最適化がされているか確認します。
確認するには、以下のクエリを実行します。このクエリは、job_id が示すジョブについて、何かしらの最適化が行われている場合はその詳細を、最適化されていない場合は null を query_info.optimization_details に表示する クエリとなっています。
SELECT
job_id,
query_info.optimization_details
FROM `プロジェクト名.region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE job_id = 'sample_job' ##Job ID で絞りたいときに使用
LIMIT 1;
ここで書かれている job_id とは、クエリ実行時に割り当てられる一意の文字列のことを指します。
画面下部の「ジョブ履歴」を展開することで確認することができます。

最適化されているか確認したいクエリの job_id を、上記クエリの sample_job 部分にコピペします。
私は一度に全部確認できるように、以下のようなクエリを作成しました。
SELECT
job_id,
query_info.optimization_details
FROM `プロジェクト名.region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
job_id = 'bquxjob_7d6~~~~'
or job_id = 'bquxjob_2da~~~~'
or job_id = 'bquxjob_796~~~~'
or job_id = 'bquxjob_8a66~~~~'
では実際に最適化されているか確認してみます。

全項目の query_info.optimization_details に対して、null が表示されています…。
つまり、今回の検証では最適化が行われませんでした。
最適化が行われなかった原因として、
- 「類似のクエリ」の認識が違うこと
- データセットの規模や処理バイト量が非常に小さかったこと
- 規模が大きければ大きい分、最適化が適用される場所が多い
- 規模が小さすぎて、最適化が必要ないと判断された
などが挙げられると私は考えています。
まとめ
本稿では、履歴ベースの最適化 (History-based Optimizations) について、概要やユースケースの説明、検証を行ってきました。リソース節約手法として非常に有用そうでしたが、今回の検証では最適化される例を見つけることはできませんでした。
公式ドキュメントが「類似のクエリ」と表現するものが一体何者なんでしょうか…。ドキュメントの更新や、本機能の GA が待ち遠しいです。
Discussion