BigQueryのContinuous Queriesがプレビューになりました
はじめに
こんにちは。クラウドエース データソリューション部所属の橘です。
データソリューション部では、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。
新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
今回紹介するのは、2024/7/22 に preview となった「BigQuery の Continuous Queries 」についてです。
要約
今回 preview リリースされた Continuous Queries は以下のような機能です。
- ストリーミングパイプラインが SQL ベースで定義できる
- source (入力元)は BigQuery table のみ
- destination (出力先)は BigQuery table 、Pub/Sub topic、Bigtable table から選択
- 使用するには BigQuery Editions の設定が必要
- 利用料金は、スロット単位で測定される BigQuery キャパシティコンピューティング料金が使用される
- 出力先でかかる費用(Pub/Sub, Bigtable 等)は別途必要
- 使用できるのは US と EU のマルチリージョンのみ
- 使用できる SQL には様々な制約がある。主な制約は以下の通り
- 集計関数 (sum, average 等) が使えない
- 結合操作 (JOIN) が使えない
-
GROUP BYなどが使えない
- 入力元テーブルとしてワイルドカードテーブル、外部テーブルは利用できない
- ユーザアカウントから実行すると、2日間経過するとジョブは停止される(サービスアカウントからなら停止しない)[1]
以下、詳細に見ていきます。
BigQuery の概要
BigQuery はサーバーレスアーキテクチャにより SQL クエリを使用して、インフラストラクチャ管理なしで大きな課題に対応できるフルマネージドのエンタープライズデータウェアハウスです。
詳しくはこちらをご参照ください。
URL: BigQuery 概要
今回のリリースについて
今回ご紹介するのは 2024/7/22 付で preview となった、BigQuery の Continuous Queries という機能についてです。
URL: BigQuery release notes
こちらの機能は、今年の Google Cloud NEXT '24 Las Vegas にて予告されていたものです。
URL: Google Cloud NEXT '24 Las Vegasセッション BigQuery continuous queries レポート
機能概要
Continuous Queriesは、継続的に実行される SQL 文です。これを用いて、BigQuery に継続的に入ってくるデータをリアルタイムに分析することができます。
言い換えると、SQL 文を書くだけで(データ処理を行うプログラムを記述することなく!)リアルタイムなデータ変換を「継続的に(continuous)」行うパイプラインを作成できます。
参考:Introduction to continuous queries
BigQuery continuous queries are SQL statements that run continuously. Continuous queries let you analyze incoming data in BigQuery in real time. You can insert the output rows produced by a continuous query into a BigQuery table or export them to Pub/Sub or Bigtable. Continuous queries can process data that has been written to standard BigQuery tables by using one of the following methods:
- The BigQuery Storage Write API
- The tabledata.insertAll method
- Batch load
- The INSERT DML statement
例として「BigQuery table に新規書き込みされたレコードのうち、条件を満たすものを抽出して Pub/Sub に投げる」クエリ例は以下の通りです。
EXPORT DATA
OPTIONS (
format = 'CLOUD_PUBSUB',
uri = 'https://pubsub.googleapis.com/projects/myproject/topics/taxi-real-time-rides')
AS (
SELECT
TO_JSON_STRING(
STRUCT(
ride_id,
timestamp,
latitude,
longitude)) AS message
FROM `myproject.real_time_taxi_streaming.taxi_rides`
WHERE ride_status = 'enroute'
);
EXPORT DATA コマンドを用いて出力先について記述すること、および出力データを AS 句の後に記述する以外は、通常のSQL文と似た感覚で記述できそうです。簡単でいいですね。
ちなみに、EXPORT DATA 句の書き方を変えるだけで、 BigQuery table への出力や Bigtable への出力も行うことができます。
参考:Create continuous queries: Examples
使い方
以下、お試ししてみるための手順を記載します。
以下の順序で作業を行います。
- リクエストフォームから利用申請を行う
- 利用可能となった旨の案内メールを受け取る
- BigQuery Reservations の作成を行う
- Reservations の割り当てを(
CONTINUOUSジョブタイプで)作成する - 実行に必要な権限を付与する
- continuous query の作成・実行を行う
- BigQuery Reservations の削除を行う
まず、予めリクエストフォーム[2]から申請を行い、許可を受け取る必要があります(※ 2024/7 現在)。
利用可能になった際は、記入したメールアドレスに電子メールで連絡があるかと思いますので確認しましょう。
次に、BigQuery Reservations の設定を行う必要があります。
「BigQuery → 容量管理」の画面から「予約を作成」を選択したのち、 reservation を構成します。
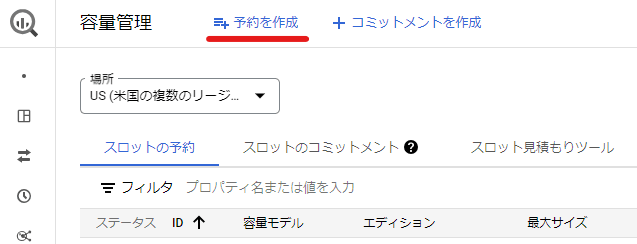
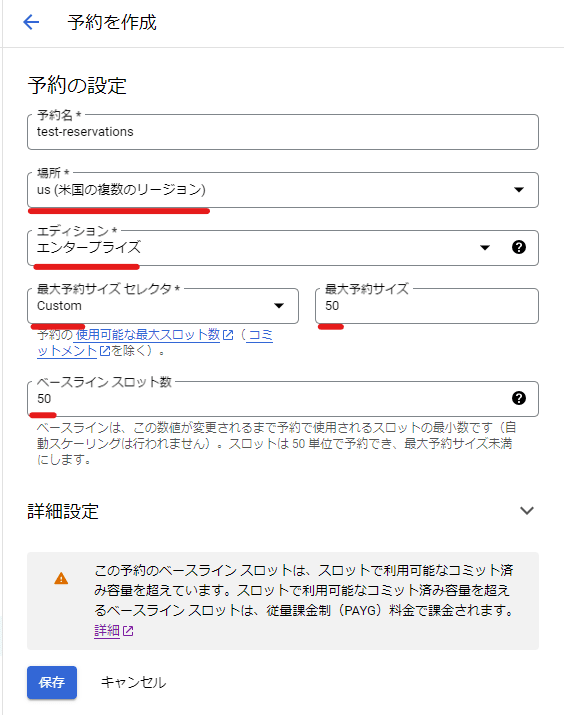
このとき、以下のことに注意します。
- 場所は
USもしくはEUを選択します - エディションは
エンタープライズもしくはEnterprise Plusを選択します - 最大予約サイズセレクタで「Custom」を選んだのち、最大予約サイズに
50を指定します[3] - ベースラインスロット数は
50を指定します[4]
「保存」を押して予約を作成したら、その予約を選択したのち「割り当ての作成」を実行します。
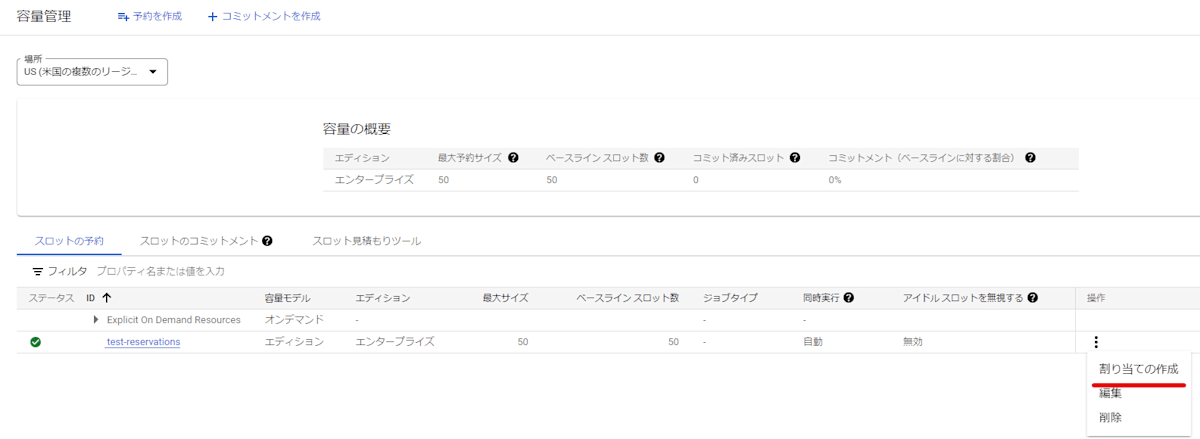
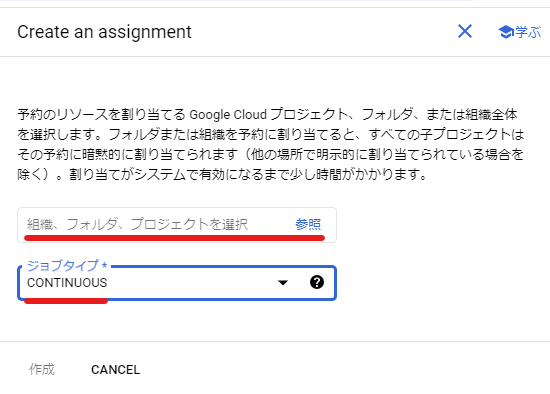
割り当て作成時は以下のように選択します。
- 「組織、フォルダ、プロジェクトを選択」欄: クエリを実行するプロジェクトを指定
- ジョブタイプには
CONTINUOUSを選択
Reservation と予約が作成できたら、次に必要な実行権限を付与します。
実行するプリンシパル(ユーザアカウントもしくはサービスアカウント)に、こちらのページで記載されている権限を付与してください。
ここまで準備できたら、実際にクエリを実行してみることができます。
BigQuery Studio から実行することもできますし、 bq コマンドからも実行できます。
ユーザアカウントを用いて実行する方法はこちらを、サービスアカウントを用いて実行する方法はこちらをご参照ください。
ここでは BigQuery Studio から実行する手順を簡単に紹介します。
「SQL クエリ」 タブを作成したのち、右上の歯車マークを押下したのち 「継続的クエリ」 を選択し、注意事項が表示されるので読んだのち 「確認」 を押下します。
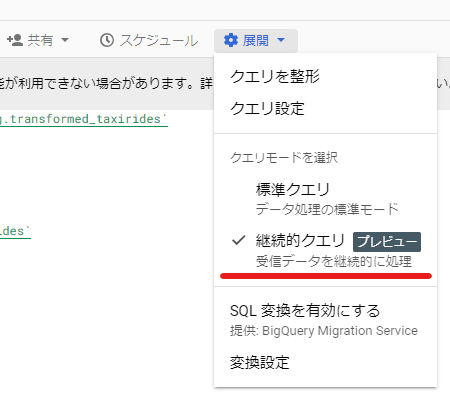
そののち、 「SQL クエリ」 タブで実行したいクエリを記述してから「実行」を押下すると、ジョブの実行が始まります。
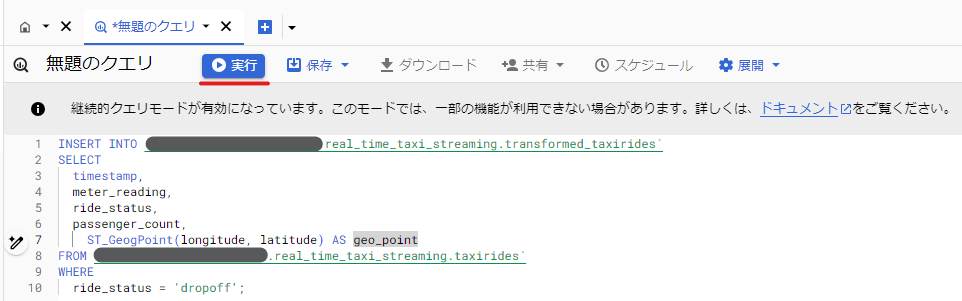
お試しが終わったら、作成したジョブを停止したのち、使い終わった割り当てと reservation を削除します。
クエリ実行画面が開きっぱなしであれば、画面内にある 「キャンセル」 を押下してください。暫く待つとジョブが停止します。
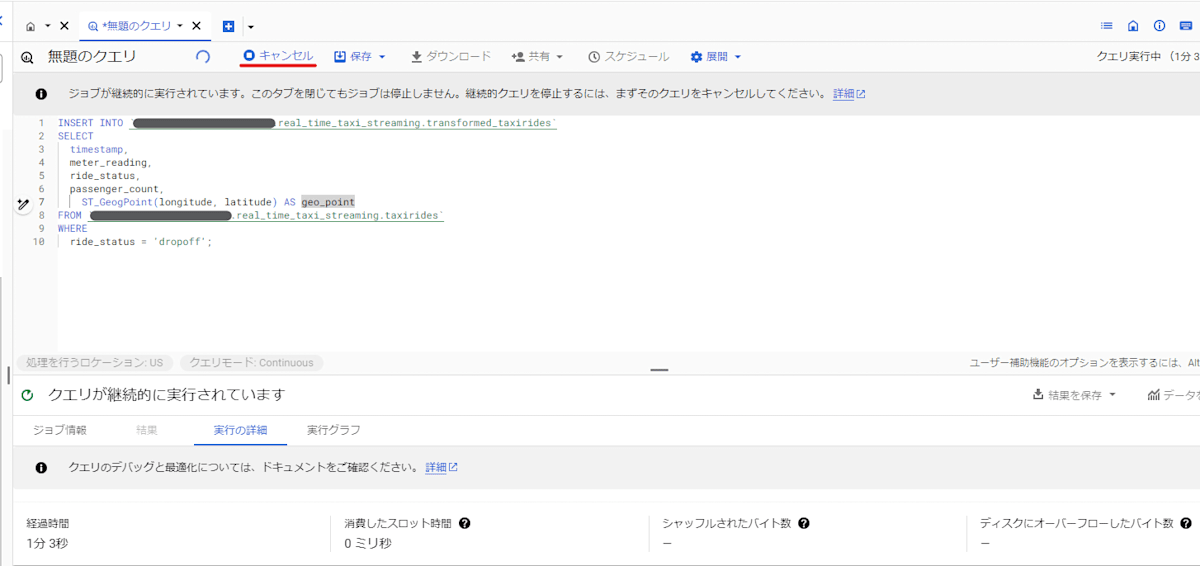
もしクエリ実行画面を閉じてしまった場合は 「BigQuery → ジョブ エクスプローラ」 から該当するジョブを探して停止してください。
そののち、「 BigQuery → 容量管理」の画面で「予約」タブを選んで予約一覧を表示してから、まず「割り当て」を選択して削除したのち、次に「予約」を選んで削除してください[5]。
reservation 以外のリソース(BigQuery データセット、テーブル等)も、不必要となったものは削除してください。
注意点・制限事項
Continuous Queries には 2024/7/24 の preview リリース時点でかなり多くの制限事項があります。
大雑把に分類しつつ、ザっと列挙すると以下の通りです。
- 記述できるクエリに関する制限
- 状態保持の制限: Continuous Queries は、処理されたデータの状態を保持しない。そのため、結合 (JOIN)、集計関数 (SUM, AVG など)、近似集計関数 (APPROX_COUNT_DISTINCT, APPROX_TOP_SUM など)、ウィンドウ分析関数 (LAG, LEAD など) のような、状態に依存する操作はサポートされない
- 非決定的なスカラー関数の制限: CURRENT_DATE 関数 のように、実行のたびに結果が変わる可能性のある非決定的なスカラー関数は使用できない
- 特定の句、演算子、ステートメントの制限: データのグループ化、絞り込み、並び替え、サンプリング、重複排除などを行うための GROUP BY, HAVING, ORDER BY, LIMIT, PIVOT, UNPIVOT, TABLESAMPLE, SELECT DISTINCT, EXISTS/NOT EXISTS サブクエリ、再帰 CTE、ユーザー定義関数、ウィンドウ関数は使用できない
- データ定義、操作、制御に関するステートメントの制限: スキーマやデータの定義、操作、制御を行うための DDL, DML(ただし INSERT は除く), DCLステートメントは実行できない
- 特定の関数、言語、機能の制限: サポート対象(ML.GENERATE_TEXT, ML.GENERATE_EMBEDDING, ML.UNDERSTAND_TEXT, ML.TRANSLATE, ML.NORMALIZER, APPENDS)以外の BigQuery ML 関数、手続き型言語、デバッグステートメントは使用できない
- 入力元テーブルに関する制限
- ワイルドカードテーブルの制限: ワイルドカードテーブルは入力元として利用できない
- 外部テーブルの制限: 外部テーブルは入力元として利用できない
- 出力先に関する制限
-
EXPORT DATAステートメントのターゲット制限: Pub/Sub および Bigtable だけがサポート - Bigtable のリージョン制限: Bigtable にデータをエクスポートする場合、クエリ対象のテーブルを含む BigQuery データセットと同じ Google Cloud リージョン境界内にある Bigtable インスタンスのみ
-
- 実行時間に関する制限
- ユーザーアカウントでの実行時間の制限: ユーザーアカウントを使用して Continuous Queries を実行する場合、ジョブは2日後に停止する
- 7日以上の遅延: Continuous Queries ジョブが7日以上遅延した場合、キャンセルして新しい Continuous Queries ジョブを開始する必要がある。その際
APPENDS change history functionを使用して、前回の停止時点から処理を再開できる
- 課金機能に関する制限
- エディションの制限: Enterprise Edition または Enterprise Plus Edition の予約が必要
- 予約割り当ての制限: 関連付けられている予約は500スロット以下に制限され、自動スケーリングを使用するように構成することはできない。また、Continuous Queries の予約割り当ては、予約が共有するように構成されていても、アイドル状態のスロットを共有しない
- ジョブタイプの制限: Continuous Queries の予約割り当てと同じ予約内で、異なるジョブタイプを使用する予約割り当てを作成することはできない
- セキュリティ機能に関する制限
- 列レベルおよび行レベルのセキュリティ: 特定の列や行へのアクセスを制限する列レベルおよび行レベルのセキュリティはサポートされない
- 顧客管理の暗号化キー(CMEK): データを暗号化するための顧客管理の暗号化キーはサポートされない
- 同時実行時のリソースに関する制限
- 同じ予約を使用して複数の Continuous Queries を実行する場合、BigQuery の公平性で定義されているように、個々のジョブが利用可能なリソースを公平に分割しない場合がある
- Continuous Queries の同時実行性を構成することはできない。BigQuery は、CONTINUOUS ジョブタイプを使用する、使用可能な予約割り当てに基づいて、同時に実行できる Continuous Queries の数を自動的に決定する
- その他の制限
- Continuous Queries ジョブの実行中に、使用されている SQL を変更することはできない。SQL を変更するには、ジョブをキャンセルし、SQL を変更してから、新しい Continuous Queries ジョブを開始する必要がある
- データキャンバスまたはノートブックから実行できない
このように、制限事項はかなり多岐に渡っており、一言で説明できるような内容になっていません。特に、どんなSQLが使えてどんな SQL が使えないのか、パっとみて分かる方は少ないと思います。
ですので、もし「やりたいタスクに Continuous Queries が使えるかな?」と思った際には見込みで判断するのではなく、実際にクエリを組んで動かしてみることをお勧めします。
まとめ
今回の記事では BigQuery の Continuous Queries についてご紹介しました。
Continuous Queries を使うことで、プログラムを記述することなくストリーミングデータ処理を行えます。
現状preview段階であること、および様々な制約事項がある点には注意が必要ですが、様々な活用方法が考えられる機能ですので、ぜひ活用方法を検討してみてください。
Discussion