インボリュームメモリによってメモリの上限が設定できるようになりました
こんにちは。日々何かに追われていて時間がないけど振り返ると何に追われていたのか分からなくなるクラウドエースの吉崎です。
2023 年 5 月 12 日のリリースにより Cloud Run のメモリ上限を設定できる「インメモリ ボリューム」という機能(プレビュー版)が利用できるようになりました。
本稿では従来の「インメモリ ファイルシステム」と今回リリースされた「インメモリ ボリューム」の違いに焦点を当て、その違いを説明します。
その他の Cloud Run のリリースが気になる方がいれば、下記の記事をご覧ください。
インメモリ ファイルシステムとインメモリ ボリュームの違い
インメモリ ファイルシステムは、インスタンスのメモリ上限がおよそ使用できるメモリの上限です。インメモリ ボリュームでは、事前にボリュームに割り当てたメモリの値がメモリの上限です。下図にその違いを表現しました。

インメモリ ファイルシステム

インメモリ ボリューム
インメモリ ファイルシステムはインスタンスのメモリを使用しており、それを超えるとインスタンスがクラッシュします。対してインメモリ ボリュームは、事前に設定したボリュームのメモリ上限(下図では 100MiB) を超えるとエラーが返ってきます。クラッシュはしませんが、インメモリ ファイルシステムと同様にインスタンスに割り当てられたメモリ量を超えるとクラッシュします。このため、違いはアプリケーションがメモリを管理しやすくなったこと、と言えると思います。(インメモリ ファイルシステムのメモリ上限はハードリミット、インメモリ ボリュームの場合はソフトリミット、とも言えます)
インスタンスがクラッシュする
インメモリ ボリュームを使わず、メモリ使用量が上限を超えてしまった場合の動作を確認します。動作確認には以下のコードを用いました。
package main
import (
"fmt"
"log"
"net/http"
"os"
"strings"
"time"
)
func main() {
http.HandleFunc("/", handler)
log.Fatal(http.ListenAndServe(":8080", nil))
}
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Println("Start")
// ファイルパスを定義
filePath := "/tmp/test.txt"
// データを定義(ここでは1MBのテキストデータを作成)
data := strings.Repeat("a", 1024*1024) // 1MB
// ファイルにテキストを追記する処理を100回繰り返す
for i := 0; i < 100; i++ {
// ファイルを開く(存在しない場合は作成、存在する場合は追記モード)
file, err := os.OpenFile(filePath, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
log.Fatalf("Failed to open file: %v", err)
}
// データを10回書き込む(合計で10MB)
for j := 0; j < 10; j++ {
if _, err := file.WriteString(data); err != nil {
log.Fatalf("Failed to write to file: %v", err)
}
}
// ファイルを閉じる
if err := file.Close(); err != nil {
log.Fatalf("Failed to close file: %v", err)
}
// メモリ量を出力する
fmt.Printf("%d MB of memory allocated\n", (i+1)*10)
time.Sleep(1 * time.Second)
}
fmt.Println("End")
}
簡単に説明すると、1MB のデータを用意し、それを /tmp/test.txt に追記します。追記処理は 10 回繰り返すのですが、10 回行うごとに 1 秒待ちます。また、10 回追記する処理を 100 回繰り返します。このため、110100=1000MB=1GB メモリを必要とします。なお、100 回の繰り返し処理の最後で 1 秒待っているのは、使用メモリ量が徐々に増える様子を観察するためで、特に深い意味はありません。/tmp ディレクトリを使用しているのは、後の検証でこのディレクトリをメモリ上限付きボリュームとして使用するためです。
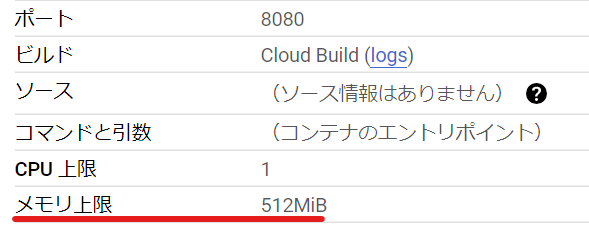
本ソースを gcloud run deploy コマンドによりソースデプロイし、作成されたリビジョンを呼び出したところ、以下のログが出力されました。
Container terminated on signal 9.
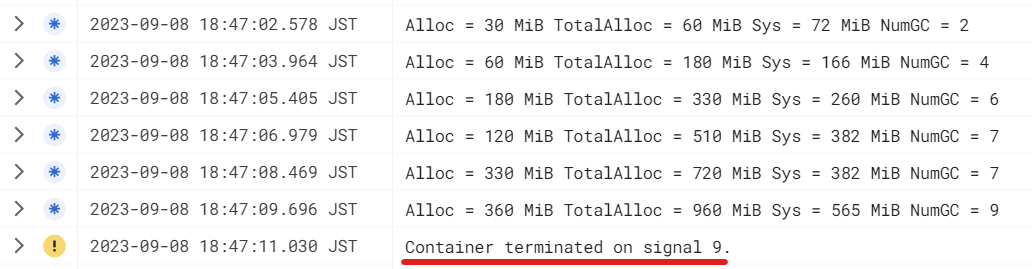
なお、signal 9 というのは Linux のシグナルだと SIGKILL であり、プロセスの強制終了時に使われるものです(kill -9 [PID] でプロセスを強制終了させたことがある方もいるはず)。このため、インスタンスのクラッシュは SIGKILL による強制終了に起因するものだと分かります。
クラッシュするんじゃなくてエラー出なかったっけ?
よくお気づきです。Cloud Run 第一世代の場合はエラーが出力されクラッシュします。下図をご覧ください。

第一世代の場合はメッセージとともにインスタンスがクラッシュする
このエラーが出た際、SIGTERM も SIGKILL も捕捉するコード(余談に記載)でしたので、世代に関係なくインスタンスのメモリ上限を超えた場合はインスタンスのクラッシュは避けられないことが分かります。ただ、第一世代だと「メモリ上限を超えたからメモリを増やすことを検討しようね。」と優しく教えてくれるのに対し、第二世代ではクラッシュしたことしか伝えてくれないのは少し不親切に感じます。
なお、一度に大量のメモリを確保したせいで第二世代で優しいメッセージが出力されないのかと思い、5MB のデータファイルを作成する第二世代のリビジョンをデプロイし、5 秒置きに合計 100 回呼び出した結果も同じでした。このため、メモリ確保の仕方ではなく世代間の差のようです。
インメモリ ボリュームでメモリ上限を設定する
次に、リビジョンのメモリ上限だけではなく、インメモリ ボリュームのメモリ上限を設定します。
公式ドキュメントに従い、YAML を保存した後に編集し、replace コマンドで設定を置き換えます。
$ gcloud run services describe run-inmemory-volume --format export > service.yaml
保存した YAML を下記の通り変更します。(一部の情報はマスクしています)
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
annotations:
run.googleapis.com/ingress: all
run.googleapis.com/ingress-status: all
run.googleapis.com/operation-id: eaeb35cc-7a21-48e8-9c73-110e1d10917f
+ run.googleapis.com/launch-stage: BETA
labels:
cloud.googleapis.com/location: asia-northeast1
name: run-inmemory-volume
namespace: '402164887470'
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/maxScale: '3'
run.googleapis.com/client-name: gcloud
run.googleapis.com/client-version: 445.0.0
run.googleapis.com/execution-environment: gen2
labels:
run.googleapis.com/startupProbeType: Default
- name: run-inmemory-volume-00020-ras
spec:
containerConcurrency: 3
containers:
- image: asia-northeast1-docker.pkg.dev/xxx/cloud-run-source-deploy/run-inmemory-volume@sha256:7255ba7e03f1187fab66b00ba60751c8fbc36b89550a4800d2238f164ba64aff
ports:
- containerPort: 8080
name: http1
resources:
limits:
cpu: '1'
memory: 512Mi
startupProbe:
failureThreshold: 1
periodSeconds: 240
tcpSocket:
port: 8080
timeoutSeconds: 240
+ volumeMounts:
+ - mountPath: /tmp
+ name: tmp
serviceAccountName: 402164887470-compute@developer.gserviceaccount.com
timeoutSeconds: 300
+ volumes:
+ - name: tmp
+ emptyDir:
+ sizeLimit: 100Mi
+ medium: Memory
traffic:
- latestRevision: true
percent: 100
/tmp ディレクトリをメモリ上限が 100Mi の tmp ボリュームとして使用します。
変更時の注意点は、launch-stage: BETA の行を加えるのと、リビジョン名の行を削除することです。(G.A.になると BETA の記述は不要な見込み)
編集後の YAML 構成に更新します。
$ gcloud run services replace service.yaml
Applying new configuration to Cloud Run service [run-inmemory-volume] in project [xxx] region [asia-northeast1]
✓ Deploying... Done.
✓ Creating Revision...
✓ Routing traffic...
Done.
New configuration has been applied to service [run-inmemory-volume].
URL: https://run-inmemory-volume-hqoygfnuxq-an.a.run.app
そしてリビジョンにリクエストを送ります。すると、下図の通り Failed to write to file: write /tmp/test.txt: no space left on device というメッセージが確認できます。上限を設定していない場合はインスタンスがクラッシュしましたが、上限を設定しているとエラーとなり処理は続行します。(もちろん続行するかどうかはプログラムの仕様に依ります)

これで、プログラムでエラーを捕捉し、使用メモリ量が上限に達した場合の制御が行えるようになりました。
ところで制御できるようになると何が嬉しい?
以下の利点が挙げられます。
- アプリケーションを続行できること
- デバッグがしやすくなること
- コールドスタートの回避
- ユーザエクスペリエンスの向上
どれも通じる部分がありますが、クラッシュでアプリケーションが停止するのを避けられるというのが嬉しい点です。Cloud Run の呼び出し元が Web アプリケーションでも API でも、クラッシュにより 500 が返されるよりは 4xx が返った方が情報量が多いです。またインスタンスが一つしかなかった場合にクラッシュが発生すると、直後にコールドスタートが発生してしまいます。これらの利点を活かすためにも、メモリを多く消費するアプリケーションを Cloud Run にデプロイする場合、インメモリ ボリュームを使ってメモリ上限を設定しておいた方が良いでしょう。
余談
「SIGTERM は捕捉可能なので、もしかして SIGKILL も同様に捕捉すれば処理を続行できるのでは?」と思う方もいるかもしれませんので、その検証をしました。
コードはクラッシュを起こす前述のコードにチャンネルの処理を加えたものです。メモリを確保する処理は省略し、チャンネル周りの main 関数のみを記します。
package main
import (
"context"
"fmt"
"log"
"net/http"
"os"
"os/signal"
"strings"
"syscall"
"time"
)
// チャンネルを作成する
var signalChan chan (os.Signal) = make(chan os.Signal, 1)
func main() {
srv := &http.Server{
Addr: ":8080",
Handler: http.HandlerFunc(handler),
}
// SIGHUP, SIGINT, SIGTERM, SIGKILLを監視する
signal.Notify(signalChan, syscall.SIGHUP, syscall.SIGINT, syscall.SIGTERM, syscall.SIGKILL)
go func() {
log.Fatal(srv.ListenAndServe())
}()
// チャンネルのメッセージを受け取る
sig := <-signalChan
log.Printf("%s signal caught", sig)
// タイムアウト
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
// グレースフルにシャットダウン
if err := srv.Shutdown(ctx); err != nil {
log.Printf("server shutdown failed: %+v", err)
}
log.Print("server exited")
}
結果は下図の通り、SIGKILL は捕捉できませんでした。(捕捉できていれば、log.Printf("%s signal caught", sig) によりログが出力されるはずです)
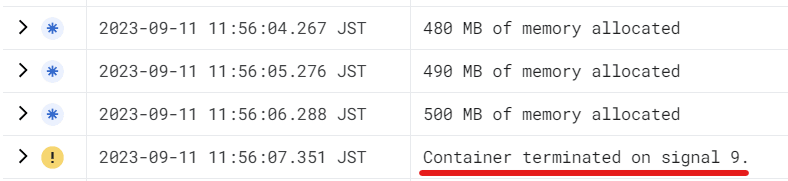
このため、やはりクラッシュが発生しないようインメモリ ボリュームによりメモリ上限を設定しておいた方が良いでしょう。
Discussion