BigQuery ML の時系列予測の新機能(予測値の制限 & カスタム休日)を試してみた
はじめに
こんにちは、クラウドエース データ ML ディビジョン所属の ジェスター です。
データ ML ディビジョン では、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。 新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
今回紹介するリリースは、「BigQuery ML の時系列予測機能に予測値の制限、カスタム休日が追加されたこと」についてです。
記事対象プロダクトの概要
今回の記事で触れていくのは、Google Cloud の BigQuery というプロダクトの機能の一つである BigQuery ML についてです。
BigQuery とは
Google Cloud の BigQuery は、大規模なデータを高速に分析するためのフルマネージドのデータウェアハウス サービスです。
(詳しくは BigQuery についての公式ドキュメント をご参照ください。)
BigQuery ML とは
BigQuery ML は、上で紹介した BigQuery のデータに対しての機械学習モデルの作成、訓練、予測を SQL で記述したクエリのみの使用で実行できる機能です。
(詳しくは BigQuery ML についての公式ドキュメント をご参照ください。)
時系列予測とは
時系列予測とは、過去の時系列データからパターンを検出し、将来の時系列データを予測することです。
例えば、株価の動きなど、時間によって変動するデータに対して使用されます。
(詳しくは 時系列予測についての公式ドキュメント をご参照ください。)
BigQuery ML でサポートされている時系列予測モデル
BigQuery ML で利用できる内部で訓練された時系列予測モデルは ARIMA_PLUS (旧 ARIMA) と ARIMA_PLUS_XREG です。
これらのモデルを使用することで、データウェアハウスからデータを移動させることなく 1 つの SQL クエリで大規模な時系列予測が可能です。
ARIMA_PLUS
時系列データのトレンドや季節性など、時間に依存するパターンを自動的に検出し、それを考慮した上で予測を行うモデルです。
ARIMA_PLUS_XREG
ARIMA_PLUS の機能に加えて、外部の説明変数(exogenous variables、別名 XREG)を追加できるモデルです。
予測に影響を与えるであろう追加の情報をモデルに組み込むことができるため、予測精度を高めることが可能です。
詳細は下記リンクをご参照ください:
リリース内容
今回ご紹介するリリースは 2023 年 11 月 06 日付のもので、 BigQuery の時系列予測機能に、複数の ML 機能が追加されたことについてです。
具体的には、以下の 2 つの機能が追加されました。
1. 予測値を制限する機能
【機能概要】
時系列予測モデル作成時のクエリにオプションとして、出力される予測値に対して上限と下限が指定できるようになりました。
これによって、時系列モデルから返される予測結果を絞り込むことが可能です。
【ユースケースの一例】
在庫予測:
予測される在庫が一定の範囲内に収まるように予測値を設定することで、意図しない予測がされることを防ぐことができます。これによって、在庫切れや在庫過剰を防ぐことが可能です。
【制約】
- このオプションは、ARIMA_PLUS モデルでのみ使用が可能です。
- このオプションを使用してモデルを訓練した場合、
ML.EXPLAIN_FORECAST関数が使用できません。
※ 上記の注意点は公式ドキュメントでは見つからないものの、実際に使ってみた際に出たエラーによりわかったことです。
【チュートリアル】
実際にこの機能を試してみたい方はこちらのチュートリアルをご参照ください。
2. カスタム休日モデリング機能
【機能概要】
今までは時系列予測モデルを作成する上で組み込み休日(HOLIDAY_REGION オプションで指定された地域の公的な休日)のみが使用可能でしたが、任意の日を休日に設定できるカスタム休日も使用することが可能になりました。
これにより、組み込み休日とされている指定の国の連邦休日以外の特定の日やイベントを考慮に入れた時系列予測が可能になります。
【ユースケースの一例】
小売業の売上予測:
ブラックフライデーなど、売り上げに大きな影響のある特定のイベントを休日としてモデルに組み込むことが可能です。これにより、より正確な売り上げを予測できるようになります。
【制約】
-
date_frequencyがDAILYまたはAUTO_FREQUENCYであるモデルでのみカスタム休日が使用可能です。 - カスタム休日を用いてモデルを作成する際に
TRANSFORM句は使用できません。 - モデルがカスタム休日のパターンを学習するために、カスタム休日として設定した日が過去のデータに含まれている必要があります。
(参照:カスタム休日の制約についての公式ドキュメント(英語版のみ))
【注意点】
- カスタム休日を追加した場合、モデルの訓練時間が長くなる可能性があります。
※ 上記の注意点は公式ドキュメントでは見つからないものの、下の検証で証明されます。
【チュートリアル】
実際にこの機能を試してみたい方はこちらのチュートリアルをご参照ください。
料金
追加された機能の使用にあたって追加の料金は発生せず、BigQuery と BigQuery ML の通常料金が発生します。
具体的に発生する料金は:
- 分析料金
- モデルの作成、訓練、予測の実行、のクエリ処理にかかる費用
- 使用されるデータの量に基づいて変動
- ストレージ料金
- モデルや訓練データの保存にかかる費用
- 保存されるデータの量に基づいて変動
※ 一部無料枠あり
(詳しくは BigQuery の料金についての公式ドキュメント でご確認ください。)
検証
検証目的
今回追加された時系列予測に関する 2 つの新機能が、具体的にどのような場面で便利なのかを説明することを目的として検証します。
検証内容
毎日何回タクシーが利用されるか、というタクシーの利用を予測します。
まず、比較のために組み込み休日による予測を行ったのち、カスタム休日を適用した際に予測値がどう変化するのかを確認します。
最後に、予測値の上下限を設定した際の挙動を確認してみます。
手順
事前準備
1. BigQuery API が有効であることを確認する
2. BigQuery のデータセットを作成する
今回は bqml_test というデータセット ID を持ったデータセットを作成します。
3. 予測の元となる時系列データを準備する
BigQuery の bigquery-public-data.chicago_taxi_trips.taxi_trips というパブリックデータを使用して、データテーブルを作成します。
このパブリックデータにはタクシー ID、利用開始時間、利用終了時間、移動時間、移動距離、料金や支払い方法など、各タクシー利用についての詳細が格納されています。
今回は各日に何回タクシーが利用されたかに着目したいため、「日付」と「その日に合計何回タクシーが利用されたか」というデータを抽出する必要があります。
しかし、元データにはこれらを直接的に表す項目が存在しないため、次のようにフィールドを変換します。
-
trip_start_timestamp
このフィールドは「その回のタクシー利用が開始された年月日時分秒」を表すものです。
このフィールドにDATE()を適用して「その回のタクシー利用が開始された年月日」に変換することで、データを日ごとに整理できるようにします。 -
unique_key
このフィールドは「レコードごと、つまりタクシー利用ごとに割り当てられる一意の値」を指します。
各レコードを日ごとにグルーピング(GROUP BY)した上で、このフィールドを集計(COUNT())することで、毎日のタクシー利用の合計回数を算出することができます。
bigquery-public-data.chicago_taxi_trips.taxi_trips に対しこれらの変換を行った状態のデータでテーブルを作成するために、下記のステートメントを Google Cloud コンソールで新規クエリとして実行します。
CREATE OR REPLACE TABLE `bqml_test.taxi_trips`
AS
SELECT
DATE(trip_start_timestamp) AS date,
COUNT(unique_key) AS trip_count
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
DATE(trip_start_timestamp) > '2017-01-01'
AND DATE(trip_start_timestamp) < '2023-12-01'
GROUP BY date
ORDER BY date
結果は次のようになります。

taxi_trips という名前のテーブルが作成できたことがわかります。
組み込み休日のみを使用した時系列予測
1. 組み込み休日のみを使用する時系列予測モデルを作成する
先ほど用意したデータで学習させたモデルを作成するため、下記のステートメントを新規クエリとして実行します。
CREATE OR REPLACE MODEL `bqml_test.forecast_rides_original`
OPTIONS (
model_type = 'ARIMA_PLUS',
holiday_region = 'US',
time_series_timestamp_col = 'date',
time_series_data_col = 'trip_count',
data_frequency = 'DAILY',
horizon = 365)
AS
SELECT
*
FROM
`bqml_test.taxi_trips`;
ここでは、 bqml_test.forecast_rides_original というモデルを作成しようとしています。
各オプションについて触れていきましょう
-
model_typeは作成するモデルのタイプを指定しています。 -
holiday_regionは組み込み休日のリージョン(今回の場合シカゴ市のデータなのでUS)を指定しています -
time_series_timestamp_colは時系列データのタイムスタンプを含む列の名前(今回の場合date)を指定しています。 -
time_series_data_colは時系列データのデータ値を含む列の名前(今回はtrip_count)を指定しています。 -
data_frequencyは時系列データの頻度を指定しており、DAILYであることからデータは 1 日単位で収集されていることを表します。 -
horizonはモデルが予測する期間(日数)を指定します。この場合、今後の 365 日間を見越して訓練を行うことを表しています。
※ その他詳しいオプションについては The CREATE MODEL statement のオプション一覧表(英語版のみ) をご残照ください。
結果はこちらです。
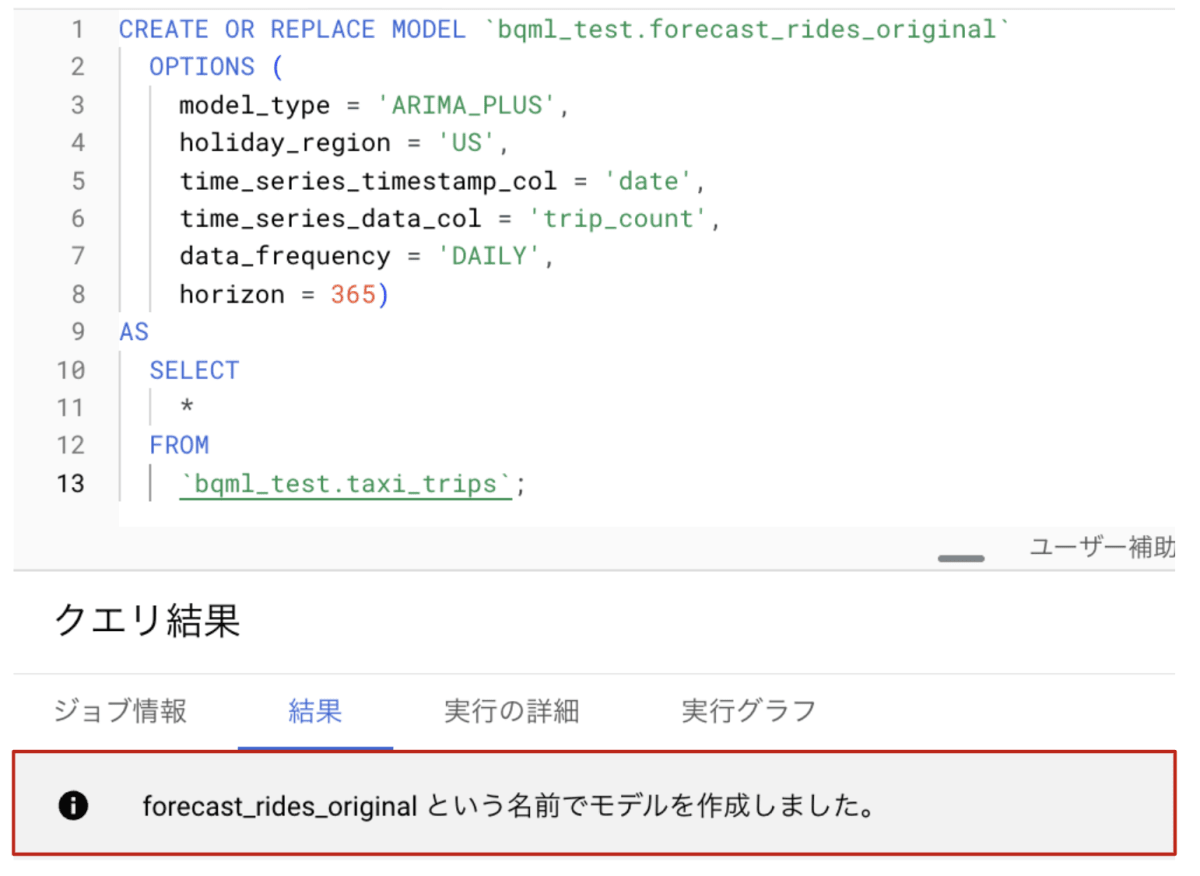
モデルの作成が成功したことがわかります。
2. 上のモデルを使って予測結果を表示する
では、先ほど作成したモデルを使った予測結果を表示してみます。
下記のステートメントを新規クエリとして実行します。
こちらのクエリでは、 bqml_test.taxi_trips に格納された各日程の実際のタクシー利用回数と、上のモデルで予測した各日程のタクシー利用回数を結合し、出力します。
SELECT
original.date,
original.trip_count AS original_trip_count,
ROUND(explain_forecast.time_series_adjusted_data) AS adjusted_trip_builtin
FROM
`bqml_test.taxi_trips` original
INNER JOIN
(
SELECT
*
FROM
ML.EXPLAIN_FORECAST(
MODEL `bqml_test.forecast_rides_original`,
STRUCT(365 AS horizon))
) explain_forecast
ON
TIMESTAMP(original.date)
= explain_forecast.time_series_timestamp
ORDER BY original.date;
まず、SELECT 句(1 行目)で選択されているのは下記の行です:
-
original.trip_count:bqml_test.taxi_tripsに格納されている各日程の実際のタクシー利用回数 -
explain_forecast.time_series_adjusted_data:上のモデルを使用して予測した各日程のタクシー利用回数
次に、12 行目に登場する ML.EXPLAIN_FORECAST 関数とは、時系列予測モデルから予測を生成するための関数です。
また、それぞれの予測値は予測の成分(トレンド、季節性、休日効果)を説明するための情報も含みます。
10 行目の * で取得できる予測の全成分(time_series_trend、time_series_seasonality、time_series_holiday_effect など)が 15 行目に記載のある explain_forecast というテーブルに保存されています。
そのうち、このクエリでは time_series_adjusted_data 列だけを使用しています(4 行目)。
ここで使用したキーワードを説明すると:
-
MODEL:予測を生成するために使う時系列モデル(今回はbqml_test.forecast_rides_original)を指定します。 -
STRUCT:フィールドを作成し、その値を設定するためのもの。この場合、horizonというフィールドを作成し、その値を 365 と設定しています。 -
horizon:予測期間(日数)を表すフィールドです。ここでは 365 なので、未来の 365 日間の予測を生成することを表します。今回の検証では扱わないため未来分は表示されません。
(ML.EXPLAIN_FORECAST 関数についての詳細は 公式ドキュメント(英語版のみ) をご参照ください。)
次に INNER JOIN 句(7 行目)です。INNER JOIN 句は実績データと予測データを比較するにあたって、両テーブルを結合するために使用します。
(INNER JOIN 句についての詳細はQuery 構文に対する公式ドキュメント(英語版のみ) をご参照ください。)
また、ROUND(explain_forecast.time_series_adjusted_data) と ROUND (四捨五入)している理由は、予測した値をそのまま使用してしまうと小数点以下の数も含まれてしまうためです。
タクシーの利用回数に、例えば 0.7 回などは相応しくないため、値を整数に四捨五入しておきます。
実行の結果がこちらです。
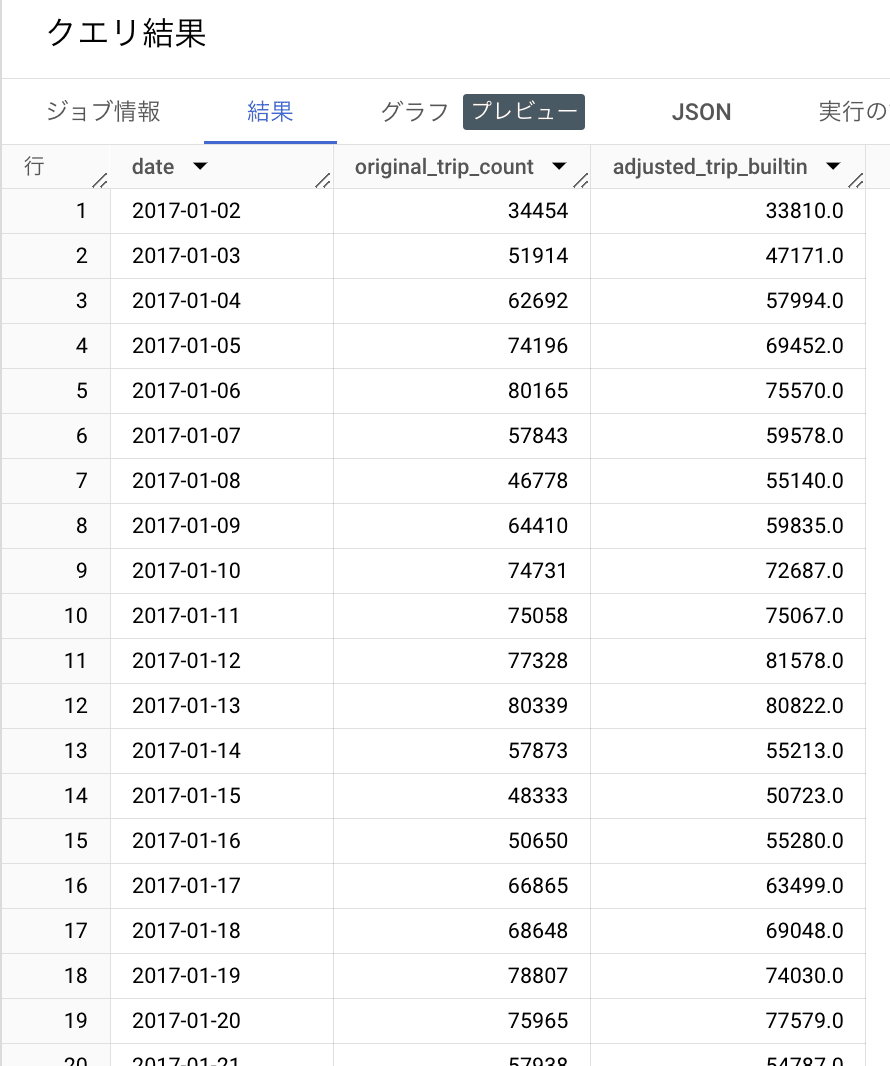
実績データと予測データ、それぞれが時系列に沿って出力されました。
3. 予測結果を可視化する
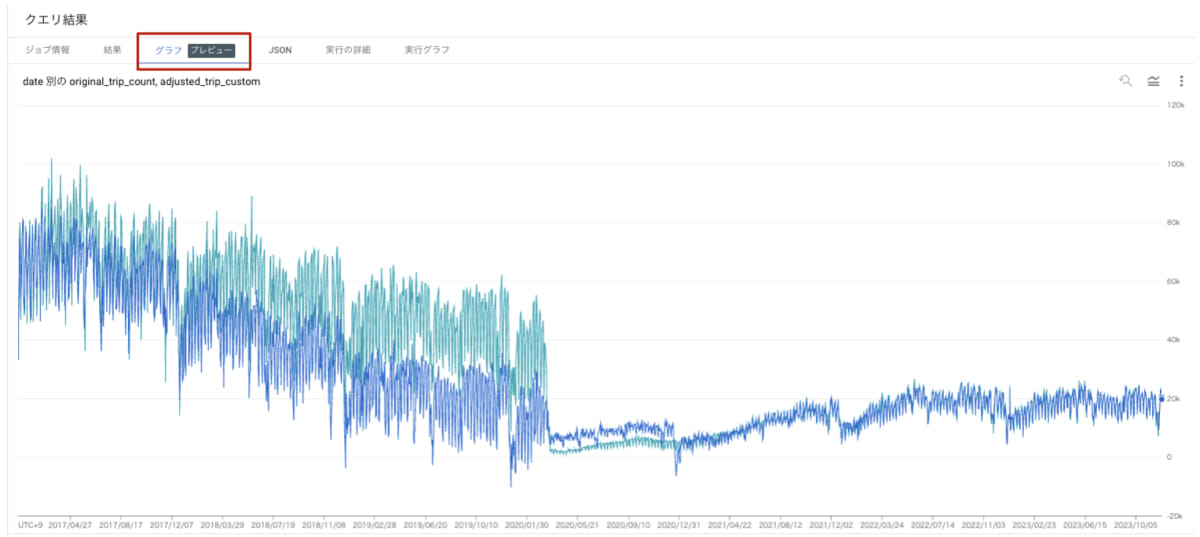
クエリ実行結果のテーブルでは差がわかりづらいので、[クエリ結果] ペインより結果を [グラフ] で結果をグラフとして表示します。
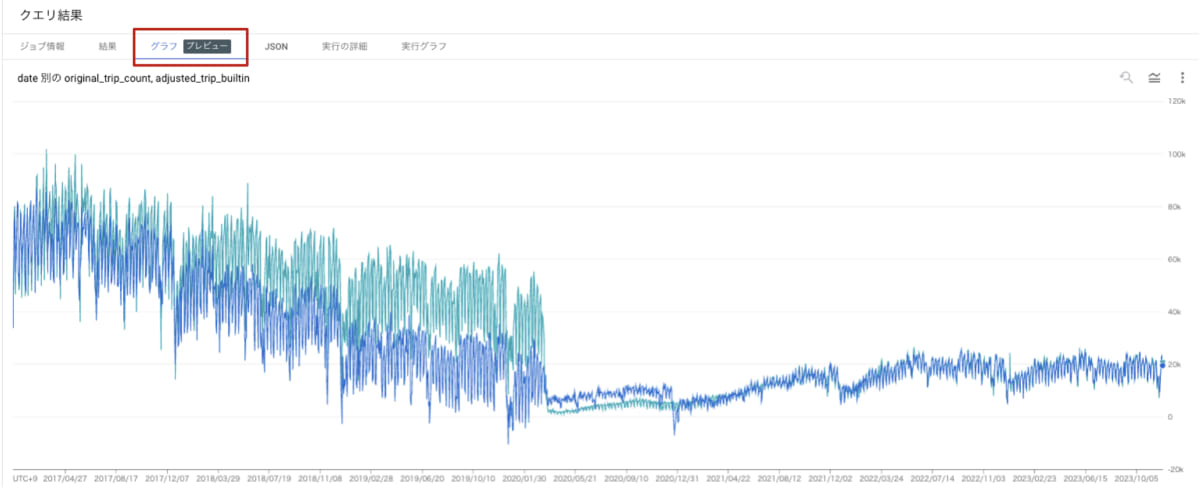
着目したいポイント
ここで一旦、この予測結果のどこを改善したいか分析してみましょう。
1. 予測値が実際の利用回数を大きく下回っている

2022 年 12 月 31 日の実際の利用回数が 24,440 回のところ、予測値は 16,210 回と上回っています。
そのため、この日をカスタム休日として設定することで、モデルに その日の利用回数が通常より多い ということを学習させることが可能です。
これによって予測精度が向上し、このずれを埋めることができそうです。
2. 利用回数が負の数になっている

利用回数が 0 であることはあっても、マイナスになることは現実的にありえません。
モデルに下限を設定することで、この不自然な予測にならないように調整します。
カスタム休日と組み込み休日を使用した時系列予測
上記の手順を、今度はカスタム休日を含めた時系列予測を行うために実行します。
1. カスタム休日と組み込み休日を使用する時系列予測モデルを作成する
下記のステートメントを新規クエリとして実行します。
CREATE OR REPLACE MODEL `bqml_test.forecast_rides_custom`
OPTIONS (
model_type = 'ARIMA_PLUS',
holiday_region = 'US',
time_series_timestamp_col = 'date',
time_series_data_col = 'trip_count',
data_frequency = 'DAILY',
horizon = 365)
AS (
training_data AS (
SELECT
*
FROM
`bqml_test.taxi_trips`
),
custom_holiday AS (
SELECT
'US' AS region,
'NewYearsEve' AS holiday_name,
DATE('2022-12-31') AS primary_date
)
);
ここで前回と違うのが、一番最初の AS 句 ( 9 行目)以降の部分です。
まず、 下記の部分は前回も使用しています。
training_data AS (
SELECT
*
FROM
`bqml_test.taxi_trips`
),
どのデータを用いて予測モデルを学習させるか、を指定しています。
その後の custom_holiday の部分が新しいですね。
custom_holiday AS (
SELECT
'US' AS region,
'NewYearsEve' AS holiday_name,
DATE('2022-12-31') AS primary_date
)
ここでは NewYearsEve という名前のカスタム休日を作成しています。
日程は、着目ポイント 1 で指摘した 2022 年 12 月 31 日です。
カスタム休日は自由に名前がつけられるのですが、今回は New Year's Eve(大晦日)とわかりやすいのでその名前にしています。
実行結果がこちらです。

新しいモデルが正しく作成できました。
モデルの訓練時間の比較
次に進む前に、この新機能の注意点でも記載のあるモデルの訓練時間について調べてみましょう。
各モデルの [トレーニング] タブより、モデルの訓練にかかった時間が下の通りに表示されました。
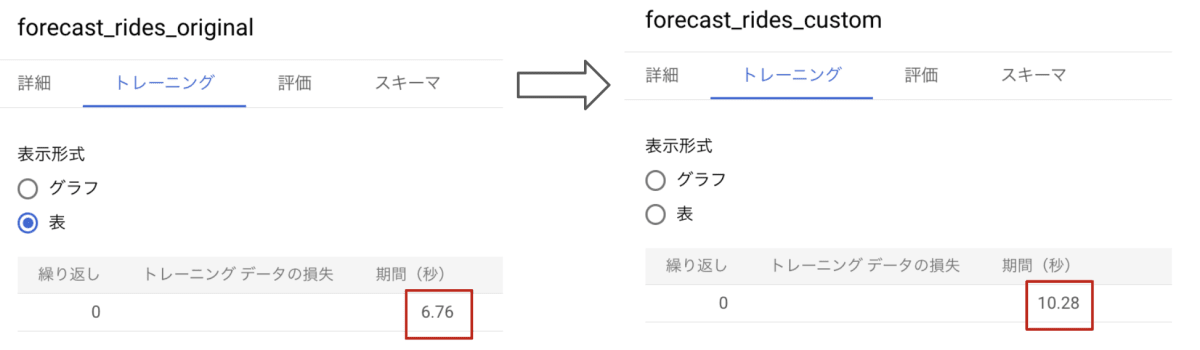
カスタム休日を追加することによってモデルの訓練時間が 3.52 秒増えたことがわかります。
今回はカスタム休日として 1 日だけを追加したので訓練時間はそれほど変わりませんでしたが、より多くの日を追加する場合には時間が長くなると考えられます。
2. 上のモデルを使って予測結果を表示する
では今回も新しく作った時系列予測モデルを使って予測した結果が実際のデータとどれくらい離れているかを調べてみましょう。
下記のステートメントを新規クエリとして実行します。
SELECT
original.date,
original.trip_count AS original_trip_count,
ROUND(explain_forecast.time_series_adjusted_data) AS adjusted_trip_custom
FROM
`bqml_test.taxi_trips` original
INNER JOIN
(
SELECT
*
FROM
ML.EXPLAIN_FORECAST(
MODEL `bqml_test.forecast_rides_custom`,
STRUCT(365 AS horizon))
) explain_forecast
ON
TIMESTAMP(original.date)
= explain_forecast.time_series_timestamp
ORDER BY original.date;
ここでは、FROM 句で指定しているモデルが違うということ以外は前回と同じ内容です。

やはりクエリ実行結果のテーブルでは差がわかりづらいので、グラフ化します。
3. 予測結果を可視化する
手順は前回と同じです。
着目ポイント 1 で調整したかった予測値と実際の値のずれをみてみましょう。
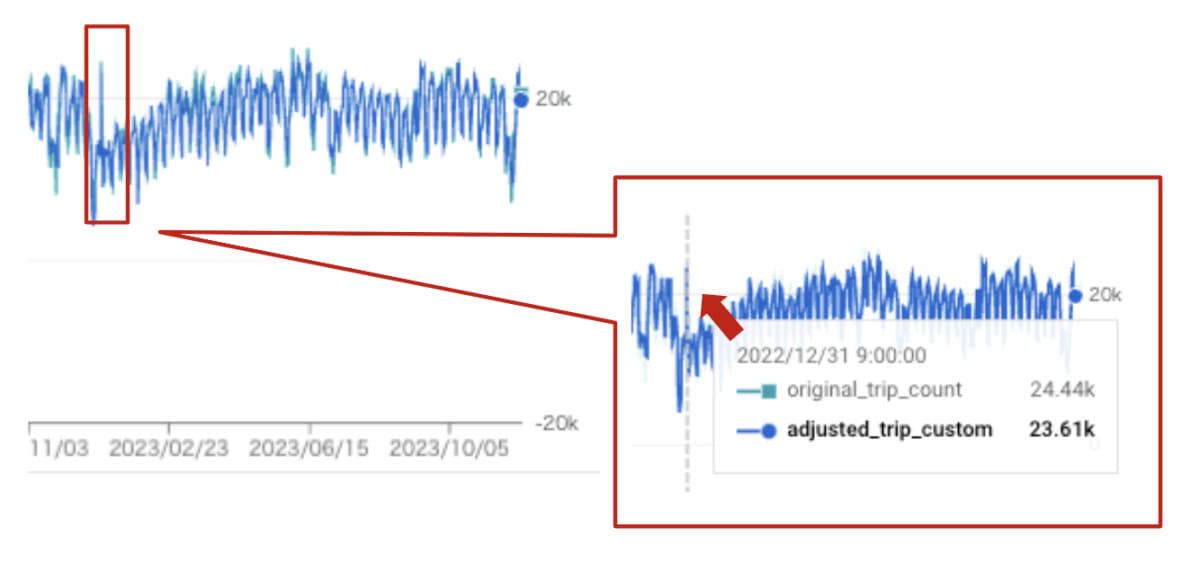
実測と予測の差を、カスタム休日を組み込む前の 10 % ほどに減らすことができました。
休日効果を調べる
休日効果 とは、特定の休日やイベントがその日のデータ値にどれくらい影響を与えるかを表したものです。
例えば、今回はタクシーの利用回数おけるカスタム休日の影響を調べようとしています。
このとき、休日効果が正の数であれば、ある日をカスタム休日として追加した場合とそうでない場合で、前者の方がタクシーの利用回数が多くなることを意味します。負の数であればこの逆になります。また休日効果の絶対値が大きいほど、カスタム休日による影響(利用回数の増加または減少)が大きいことを意味します。
(詳細は ML.EXPLAIN_FORECAST 関数の出力についての公式ドキュメント(英語版のみ) をご参照ください。)
今回は予測を行う際に ML.EXPLAIN_FORECAST 関数を使用したため、予測値には休日効果に関する情報があらかじめ含まれています。
そのため、休日効果を調べるには下記のステートメントを新規クエリとして実行します。
SELECT
time_series_timestamp,
holiday_effect_NewYearsEve,
holiday_effect_NewYear,
holiday_effect_US_IndependenceDay,
holiday_effect_Christmas
FROM
ML.EXPLAIN_FORECAST(
model
`bqml_test.forecast_rides_custom`,
STRUCT(365 AS horizon))
ORDER BY holiday_effect_NewYearsEve DESC;
ここでは、カスタム休日である NewYearsEve の他に比較として、組み込み休日に含まれる NewYear、US_IndependenceDay そして Christmas の休日効果を調べます。
また、NewYearsEve の休日効果を見つけやすくするために、このフィールドを降順でソートしています(ORDER BY holiday_effect_NewYearsEve DESC)。
実行の結果がこちらです。

このテーブルを見ると、カスタム休日 NewYearsEve が 2022 年 12 月 31 日と 2023 年 1 月 1 日に正の影響をもたらしていることがわかります。
言い換えると、2022 年 12 月 31 日と 2023 年 1 月 1 日は カスタム休日のNewYearsEve の影響でタクシーの利用回数が通常より多いということです。
時系列予測モデルに制限を追加する
着目ポイント 2 で記載したように、利用回数が負の数になることを防ぐために下限を設定します。
1. カスタム休日と組み込み休日を使用する時系列予測モデルに制限を追加します
下記のステートメントを新規クエリとして実行します。
CREATE OR REPLACE MODEL `bqml_test.forecast_rides_limits`
OPTIONS (
model_type = 'ARIMA_PLUS',
holiday_region = 'US',
time_series_timestamp_col = 'date',
time_series_data_col = 'trip_count',
data_frequency = 'DAILY',
horizon = 365,
forecast_limit_lower_bound = 0)
AS (
training_data AS (
SELECT
*
FROM
`bqml_test.taxi_trips`
),
custom_holiday AS (
SELECT
'US' AS region,
'NewYearsEve' AS holiday_name,
DATE('2022-12-31') AS primary_date
)
);
ここではモデルを作成する際に、予測の下限値を設定するためのオプションである forecast_limit_lower_bound に 0 を指定しています。
結果は以下のとおりです。
制限付きのモデルの作成に成功しました。
2. 上のモデルを使った予測結果を表示します
新しく制限付きで作成したモデルを使用して、未来のタクシー利用回数を予測します。
今回は先ほどまで使用していた ML.EXPLAIN_FORECAST ではなく ML.FORECAST を使用して予測結果を出力します。
その理由は、機能紹介の制約に記載したように、予測値に制限がついた(今回の場合、下限値の設定であるforecast_limit_lower_bound を含んだ)モデルでは ML.EXPLAIN_FORECAST 関数を使用できないためです。
そのため、代わりに ML.FORECAST 関数を使用します。
これらの関数の違いは下の通りです:
-
ML.FORECAST:時系列予測モデルを使用して未来の値を予測する関数です。 -
ML.EXPLAIN_FORECAST:時系列予測モデルを使用して未来の値を予測すると同時に、予測のトレンド、季節性、休日効果などを説明するための情報も提供する関数です。
(ML.FORECAST 関数に関する詳細は 公式ドキュメント(英語版のみ) をご参照ください。)
それでは、実際に ML.FORECAST 関数を使ってみましょう。
下記のステートメントを新規クエリとして実行します。
SELECT
forecast_timestamp AS forecast_timestamp,
history_value AS history_value,
forecast_value AS forecast_value
FROM ( (
SELECT
DATE(forecast_timestamp) AS forecast_timestamp,
NULL AS history_value,
forecast_value AS forecast_value
FROM
ML.FORECAST(MODEL `bqml_test.forecast_rides_limits`,
STRUCT(365 AS horizon,
0.9 AS confidence_level)) )
UNION ALL (
SELECT
date AS forecast_timestamp,
trip_count AS history_value,
NULL AS forecast_value
FROM
`bqml_test.taxi_trips`))
ORDER BY
forecast_timestamp
このステートメントを分解して解説します。
- 【6 行目から 13 行目】
ML.FORECAST関数を使用して未来のタクシー利用回数を予測し、選択する
SELECT
DATE(forecast_timestamp) AS forecast_timestamp,
NULL AS history_value,
forecast_value AS forecast_value
FROM
ML.FORECAST(MODEL `bqml_test.forecast_rides_limits`,
STRUCT(365 AS horizon,
0.9 AS confidence_level))
ML.FORECAST 関数を使用して生成した予測結果から、以下の 3 つの列を選択して取得しています。
-
forecast_timestamp:データのタイムスタンプ(日付)が格納される行 -
history_value:過去の実際のデータが格納される行 (※) -
forecast_value:予測データが格納される行
※ 最終的に過去データと結合する際に必要な列。予測結果としては存在しないため null を指定しています。
次に、FROM 句(5 行目)の中身を見てみると、ML.FORECAST 関数を使用して予測を生成しているのがわかります。
ここで新しく登場するのが confidence_level パラメータで、予測の信頼区間を指定するものです。
今回 confidence_level が 0.9 に設定されているため、生成された予測が信頼区間内に真の値を含む可能性が 90%ある、ということです。
つまり、ここで出力される予測値が実際の値の近くにある(つまり、信憑性の高い)可能性が 90% である、と解釈できます。
(confidence_level についての詳細は ML.FORECAST 関数についての公式ドキュメントをご参照ください。)
- 【15 行目から 20 行目】実際のタクシー利用回数を選択する
SELECT
date AS forecast_timestamp,
trip_count AS history_value,
NULL AS forecast_value
FROM
`bqml_test.taxi_trips`
ここの SELECT 句(1 行目)でも ML.FORECAST 関数を使用して未来のタクシー利用回数を予測したときと同じ 3 つの行が選択されています。
今回は先ほどと異なり実際の過去のデータなので、forecast_value つまり予測値が null となっています。
- 【14 行目】
UNION ALL句でデータを結合する
過去から未来の値の変動を確認するために、14 行目で UNION ALL 句を使って予測データ(上記 1)と過去のデータ(上記 2)を結合しています。
このクエリを実行した結果が以下の通りです。
3. グラフを表示して可視化します。
[クエリ結果] ペインより結果をグラフとして表示すると下のように出ました。

ここで、予測したタクシーの利用回数に負の数がないことが確認できました。
検証まとめ
カスタム休日を使用することで、モデルの予測精度が向上したことがわかりました。
また、予測モデルに下限を設けることで、予測結果を現実的なものに制限することができました。
まとめ
今回は BigQuery ML での時系列予測機能に追加された 2 機能を紹介しました。
記事の内容をまとめると、以下のとおりです。
- BigQuery の時系列予測機能に、予測値を制限する機能と、カスタム休日を追加する機能が追加された。
- 予測値を制限する機能が追加されたことで、予測結果をより現実的なものに絞ることが可能になった。
- カスタム休日モデリング機能により、予測結果に影響すると考えられる任意の日付を休日に設定できるようになり、モデルをより正確なものに調整ができるようになった。
これらの機能をぜひ BigQuery ML での時系列予測に活用してみてください。
Discussion