Google の最新マルチモーダル生成 AI モデル Gemini 1.0 を紹介
はじめに
こんにちは、クラウドエース データ ML ディビジョン所属の 川人 です。
データ ML ディビジョン では、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。 新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
本記事では、2023 年 12 月 7 日に Google によって発表された、最新のマルチモーダル生成 AI モデル Gemini 1.0 について紹介します。
Gemini とは
Gemini とは Google で開発された高機能なマルチモーダル生成 AI モデルです。 マルチモーダル生成 AI モデルとは、画像、音声、動画、およびテキストデータといった異なる種類のデータを同時に学習し、推論する能力を持ったモデルのことです。
※ 読み方は、英語だとジェミナイと発音されていますが、日本語だとジェミニのようです。
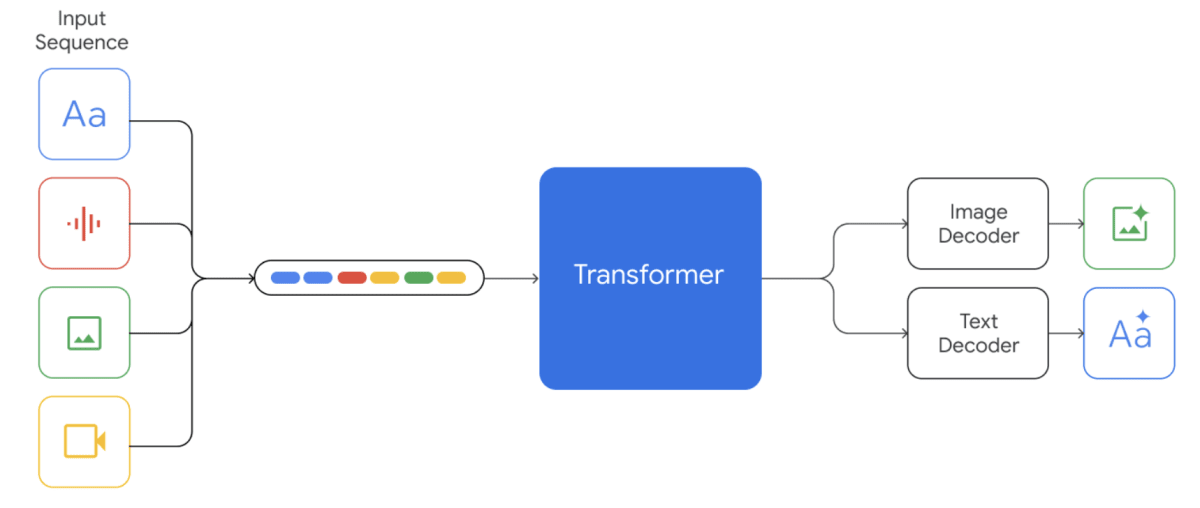
モデルは、スケーラブルな訓練と最適化された推論を可能にするために改良された Transformer のデコーダ部分に構築されています。
入力には、テキスト、画像、音声、動画を混在させることができ、テキストと画像を生成することができます(現在プレビュー版で公開されている Vertex AI の Gemini Pro、Gemini Pro Vison では、音声データ、画像と動画が混在したデータの入力と、テキストデータ以外の出力はサポートされておりません)。
3 つのモデルサイズ
Gemini 1.0 は、Ultra、Pro、Nano の 3 つのサイズで構成されます。
そのうち Pro と Nano は、ともに Gemini Ultra をもとに生成された、蒸留モデルのようです。
| モデルサイズ | モデルの説明 |
|---|---|
| Ultra | 理論的なタスクやマルチモーダルなタスクを含む、非常に複雑なタスクの幅広い範囲で最先端のパフォーマンスを発揮する最も能力のあるモデル。 |
| Pro | 幅広いタスクで顕著なパフォーマンスを発揮する、コストとレイテンシーの両方の観点から最適化されたパフォーマンスのモデル。 |
| Nano | デバイス上で実行するために設計された最も効率的なモデル。低メモリデバイスと高メモリデバイスを対象に、2つのバージョンが訓練されている。 |
Gemini 1.0 のメリット
性能
テクニカルレポートによれば、自然な画像の理解から数学的推論、音声や動画の理解に至るまで、広く使用されている 32 の業界ベンチマークのうち 30 で、Gemini 1.0 のパフォーマンスは既存の最高水準の結果を上回っています。
テキストベンチマーク
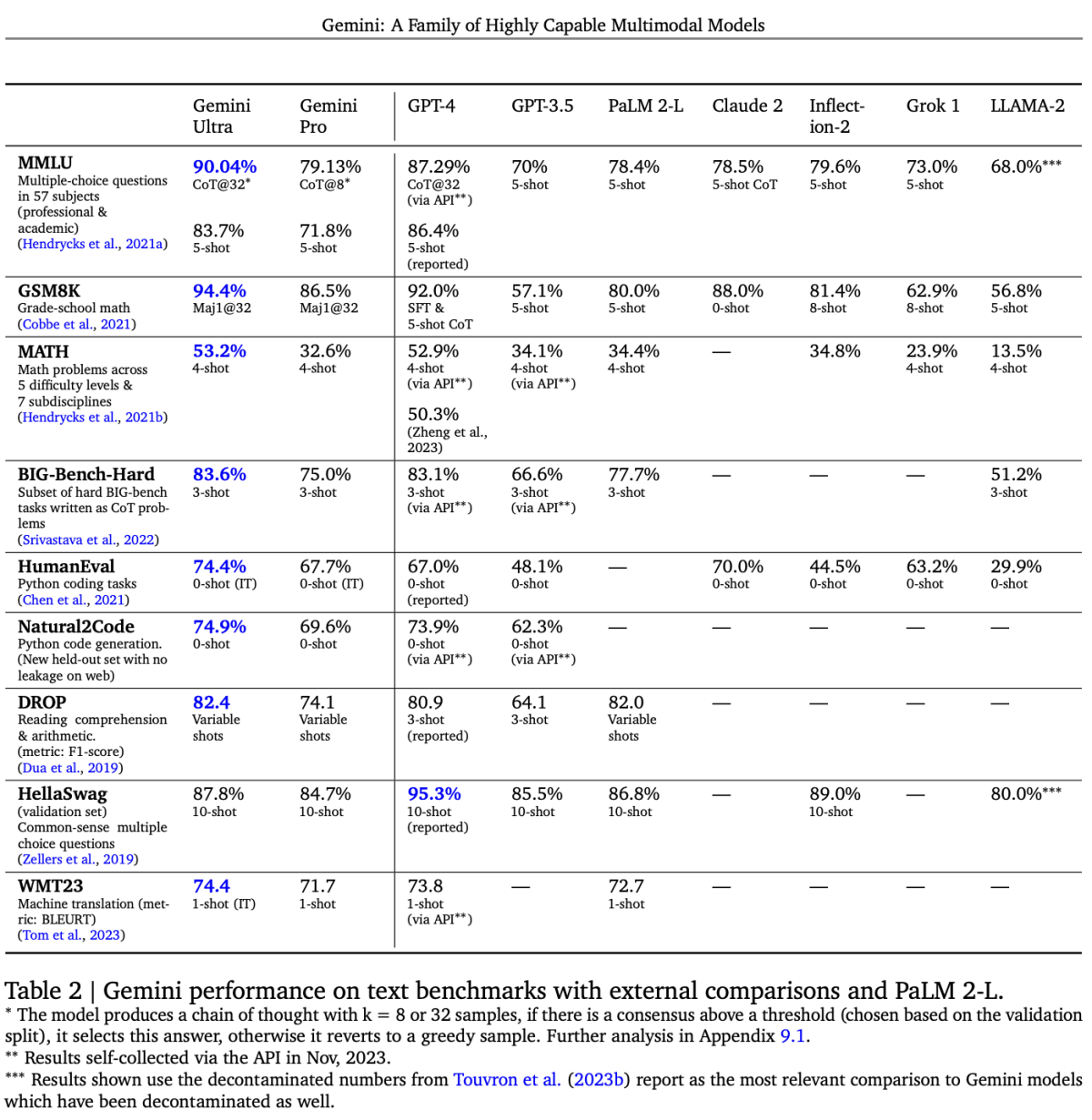
テキストベンチマークでは、Gemini Ultra および Gemini Pro を、その他 GPT-4 や PaLM 2 などのモデルと比較しています。
MMLU は、57 科目にもわたる、さまざまな分野における知識の総合的な試験ベンチマークで、作成者によって人間の専門家のパフォーマンスは 89.8% と評価されています。Gemini Ultra は、このしきい値を超えた最初のモデルであり、それ以前の最高スコアは GPT-4 の 86.4% でした。
また、算数や数学、コーディング、機械翻訳などの分野においても、Gemini Ultra は最高スコアを記録しています。
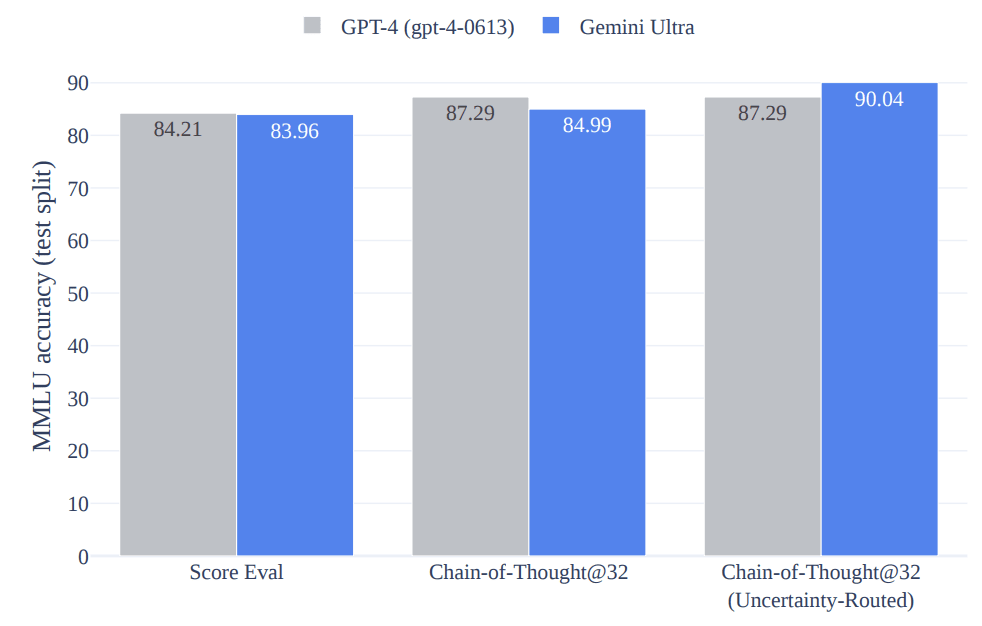
MMLU ベンチマークでは、CoT@32 でのスコアと 5-shot でのスコアを比較しています。
5-shot のスコアでは、GPT-4 が勝っていますが、CoT@32 のスコアでは Gemini Ultra が勝っています。
CoT@32 の CoT とは、Chain-of-Thought プロンプティングのことで、AI に複雑な問題を解かせる際、質問に対して段階的にモデルに答えさせることで、高精度の回答を引き出すプロンプトエンジニアリングの手法です。
また、 CoT@k=32 では、それぞれの段階でモデルがk=32 個の回答を生成し、その中で単純に確率が最も高いものを選ぶというのが最も自然ですが、今回のベンチマークでは、Uncertainty-Routed Chain-of-Thought というアプローチを取っています。このアプローチでは、各段階において k=32 の回答を生成し、確率がしきい値(モデルのパフォーマンスに基づいて調整される)を超えるものがあればその中から多数決で回答を選択、しきい値を超えるものがなかった場合、確率が最も高い回答を選択します。
この Uncertainty-Routed Chain-of-Thought のアプローチを取ることで、Gemini Ultra は GPT-4 のスコアを超える、最高スコア 90.04 を出すことができるようです(このアプローチを取らないと Gemini Ultra は GPT-4 の精度を超えていないということになります)。
マルチモーダルベンチマーク
テキストだけでなく、画像、動画、音声といったマルチモーダルなベンチマークにおいても、Gemini 1.0 は各ベンチマークセットに対して最高スコアを叩き出しています。
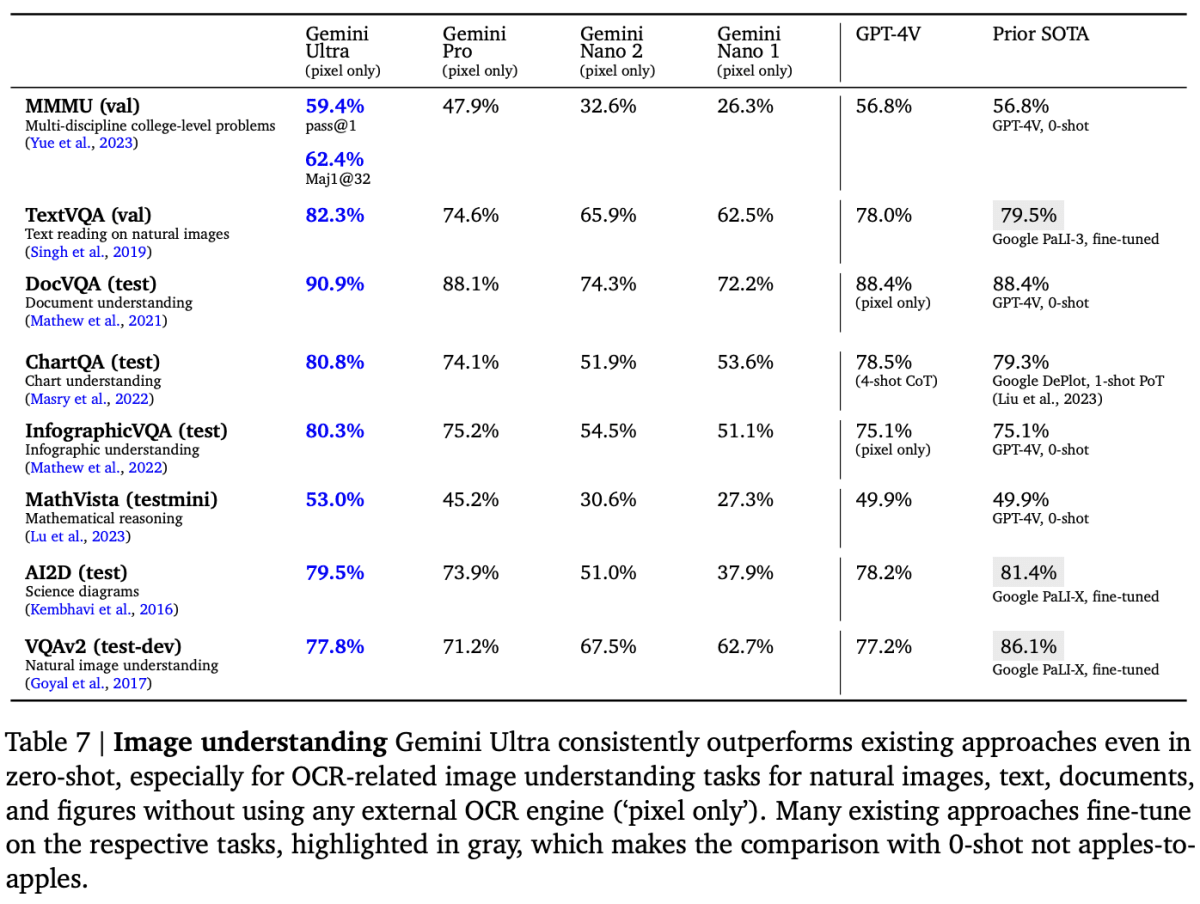
画像
画像ベンチマークでは画像データに対して、外部 OCR ツールを一切使用せずに、特定のベンチマークに合わせた短い回答を行うことでスコアを測定します。
MMMU は、30 科目にもわたる大学レベルの多分野マルチモーダル理解と推論に特化したベンチマークで、様々なタイプの画像(例:チャート、地図、楽譜)を含んでいます。
動画
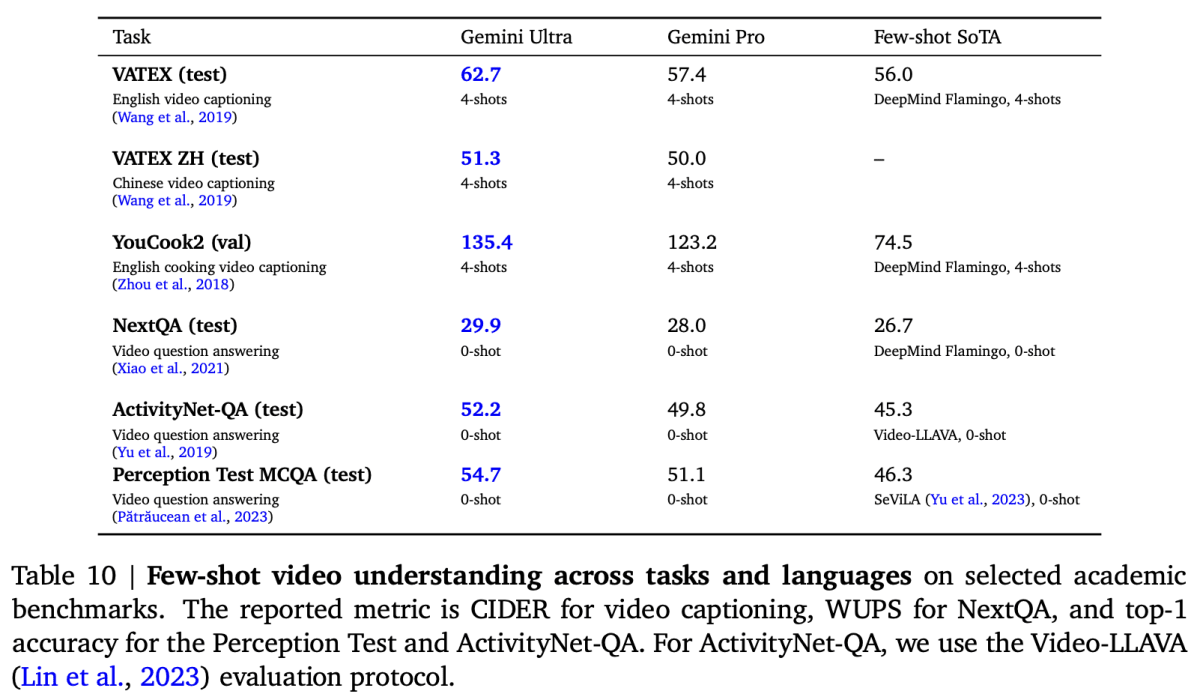
動画ベンチマークでは動画データに対して、キャプション生成タスクに対しては生成されたキャプションが人間が作成したキャプションとどれだけ一致しているか、質問回答タスクに対しては生成された回答が想定する回答とどれだけ一致しているかを評価し、スコアを測定します。
VATEX は、英語と中国語の両方で、41,250 以上のビデオと 825,000 のキャプションを含むデータセットです。
音声
音声ベンチマークでは音声データに対して、自動音声認識タスク、音声翻訳タスクを行い、スコアを測定します(Gemini Ultra に対してはまだ行ってないようです)。
ここでは、一般的なベンチマークに加え、YouTube から収集された音声データを用いたベンチマークも行っています。

機能
Gemini 1.0 の機能については、以下のハンズオン動画を見るとわかりやすいです。
責任と安全性
- AI 原則と製品全体にわたる堅牢な安全ポリシーに基づいた、Gemini のマルチモーダル機能を考慮した新しい保護機能の追加
- サイバー攻撃、扇動、自律性などの潜在的なリスク領域に関する新しい研究を実施し、Gemini の導入に先立って重大な安全上の問題を特定するために、Google Research のクラス最高の敵対的テスト技術を適用
- 内部評価アプローチの盲点を特定するために、外部の専門家やパートナーからなる多様なグループと協力して、さまざまな問題にわたってモデルのストレステストを実施
- モデルの学習段階でコンテンツの安全性の問題を診断し、その出力がポリシーに従っていることを確認するために、アレン研究所の専門家によって開発された Real Toxicity Prompts (ウェブから取得したさまざまな程度の有害性を持つ 100,000 のプロンプトのセット) などのベンチマークを使用
- MLCommons、Frontier Model Forum とその AI Safety Fund、および公共部門と民間部門にわたる AI システムに特有のセキュリティリスクを軽減するために設計された Google の Secure AI Framework (SAIF) とともに安全性とセキュリティのベンチマークとベストプラクティスを設定
- 著作権についての問題が発生した場合における、生成された出力に関する補償の提供
Gemini 1.0 (Gemini Pro)を Vertex AI Studio 上で実際に動かしてみる
記事執筆時点(2023 年 12 月)では、Gemini 1.0 は、Vertex AI(Console & SDK / API)、Bard(英語版のみ) によって Gemini Pro が、Google Pixel 8 Pro (日本語対応は未定)によって Gemini Nano が使用可能です。
よって今回は日本語がサポートされている Vertex AI の Vertex AI Studio 上で Gemini Pro を動かしてみようと思います。
Vertex AI Gemini API
サポートされるユースケース
現在、Vertex AI Gemini API は、モデルごとに次のユースケースをサポートしています。
| モデル | サポートされるユースケース |
|---|---|
| Gemini Pro | 自然言語タスク、マルチターンテキストとコードチャット、およびコード生成。 |
| Gemini Pro Vision | マルチモーダルプロンプトをサポート。プロンプトにテキスト、画像、動画を含めると、テキストまたはコードのレスポンスを取得可能。 |
モデルの長所と短所
長所
公式ドキュメントによると、Vertex AI Gemini API は以下のようなユースケースに適しているようです。
| 説明 | |
|---|---|
| 情報提供 | 一般知識と、画像や動画からの情報を組み合わせて、ユーザーが求めている情報を提供する。 |
| 物体認識 | 画像や動画内から、物体の詳細な識別に関する質問に答える。 |
| コンテンツの理解 | インフォグラフィック、チャート、図、表、Web ページなどのさまざまなコンテンツから情報を抽出する。 |
| 構造データの生成 | 提供されたプロンプト指示に基づいて、HTML や JSON などの形式で応答を生成する。 |
| キャプション・説明 | 画像・動画に関して、次のようなプロンプトから開始し、そこから繰り返してより具体的な説明を取得する。 - 画像: 「この画像についての説明を書いていただけますか?」 - 動画: 「この動画で何が起こっているかについて説明を書いていただけますか?」 |
| 推定 | 位置に基づいて他に見るべきもの、画像や動画の次・前・間で何が起こるかを提案し、視覚的な入力に基づいてストーリーを書くなどのクリエイティブな使用を可能にする。 |
短所
公式ドキュメントによると、Vertex AI Gemini API には以下のような短所があるようです。
| 説明 | |
|---|---|
| 空間推論 | 画像内の物体・テキストの位置を正確に特定するのに苦労する可能性がある。 回転した画像を理解する際の精度が低くなる可能性がある。 |
| カウント | 特に隠れた物体の場合、その数の大まかな近似値しか提供できない。 |
| 長い動画の理解 | 動画の 2 分を超える情報を抽出しない。 |
| 複雑な指示への回答 | 複数の推論ステップを必要とするタスクに苦労する可能性がある。より適切な回答を得るために、手順を細分化するか、いくつかの例を提供することを検討する。 |
| 幻覚 | 場合によっては、画像や動画に実際に含まれないものを推定したり、広範なテキスト解析のために不正確なコンテンツを生成したりすることがある。temperature を下げたり、短い説明を要求したりするとこれを軽減できる。 |
| 医療用途 | 医療画像(X 線、CT スキャンなど)の解釈や医学的アドバイスの提供には適さない。 |
| マルチターンチャット | チャットボットの機能や、おしゃべりな口調で質問に答えるためのトレーニングは受けていないため、複数ターンにわたる会話では精度が低下する。 |
現在のバージョンではサポートされていない機能
公式ドキュメントによると、Vertex AI Gemini API は現在、以下の機能をサポートしていません。
| 機能 | 説明 |
|---|---|
| メタデータ | 画像のファイル名やメタデータは考慮されない。 |
| 動画内の音声 | 動画入力からの音声を受信および処理しない。 |
| バウンディングボックスの物体検出 | バウンディングボックスによる物体検出はサポートされていない。 |
| 物体のセグメンテーション | 物体のセグメンテーションはサポートされていない。 |
さらに、実際に使用してみると以下のような制限もありました。
- Gemini Pro Vision
- テキスト以外のデータの生成
- 画像と動画が混在したデータの入力
- 10 MB を超える画像・動画データの入力
- 音声データの入力
料金
記事執筆時点(2023 年 12 月)では、料金は下記の通りです。
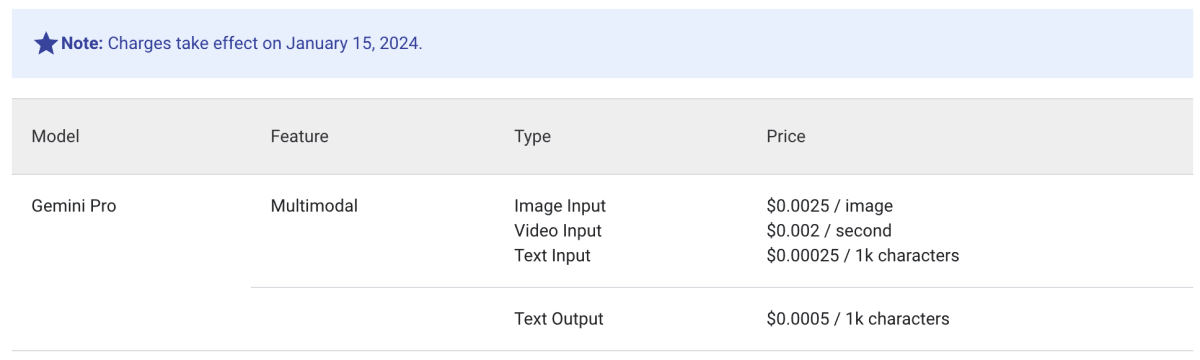
ちなみに、PaLM 2(Text Bison) の料金は以下の通りで、テキストデータの料金は全く同じです。

参考:Pricing for Generative AI on Vertex AI
Vertex AI Studio 上でのデモ
Gemini Pro
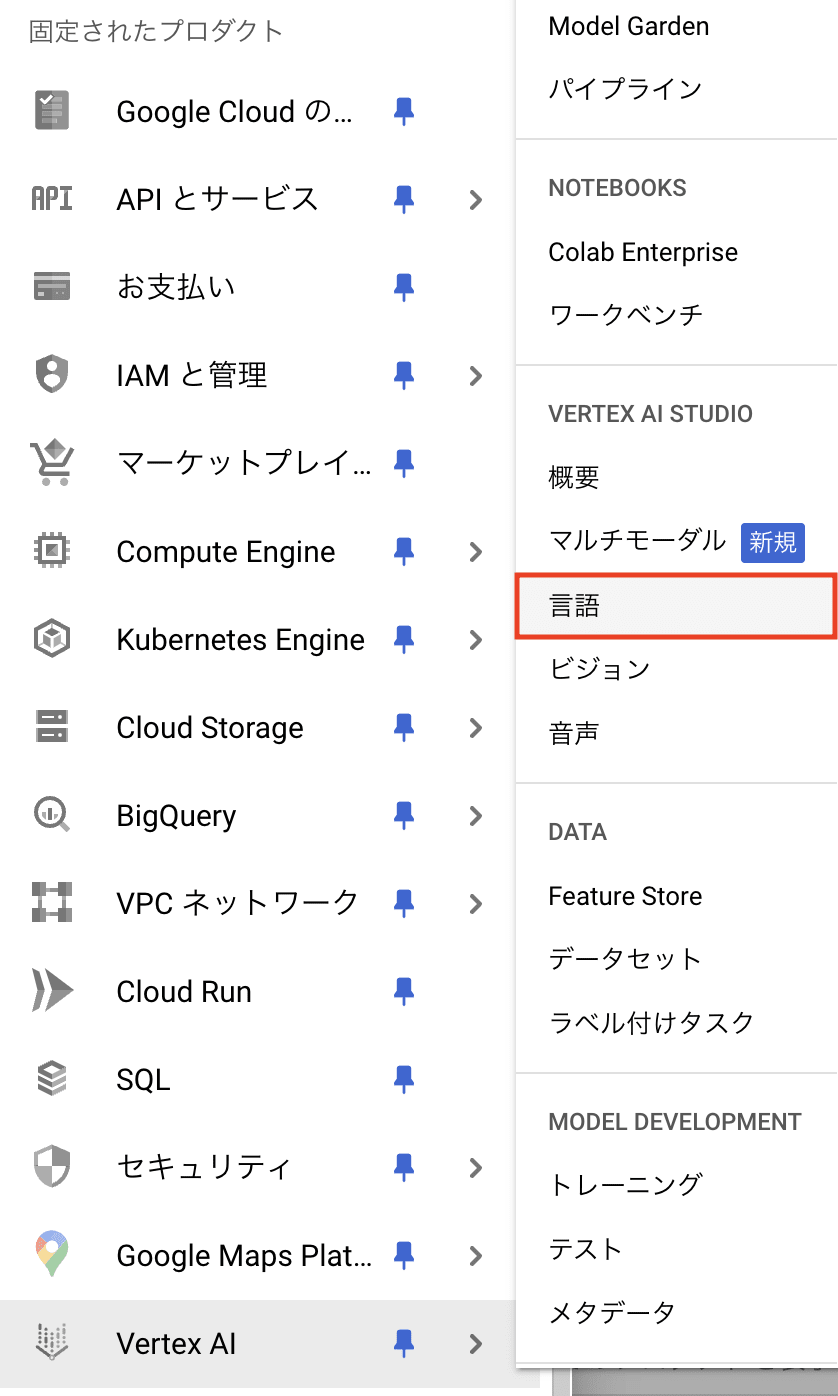
Vertex AI Studio 上で Gemini Pro のプロンプトを開くには、以下の手順を行います。
- Vertex AI Stusio の「言語」をクリック
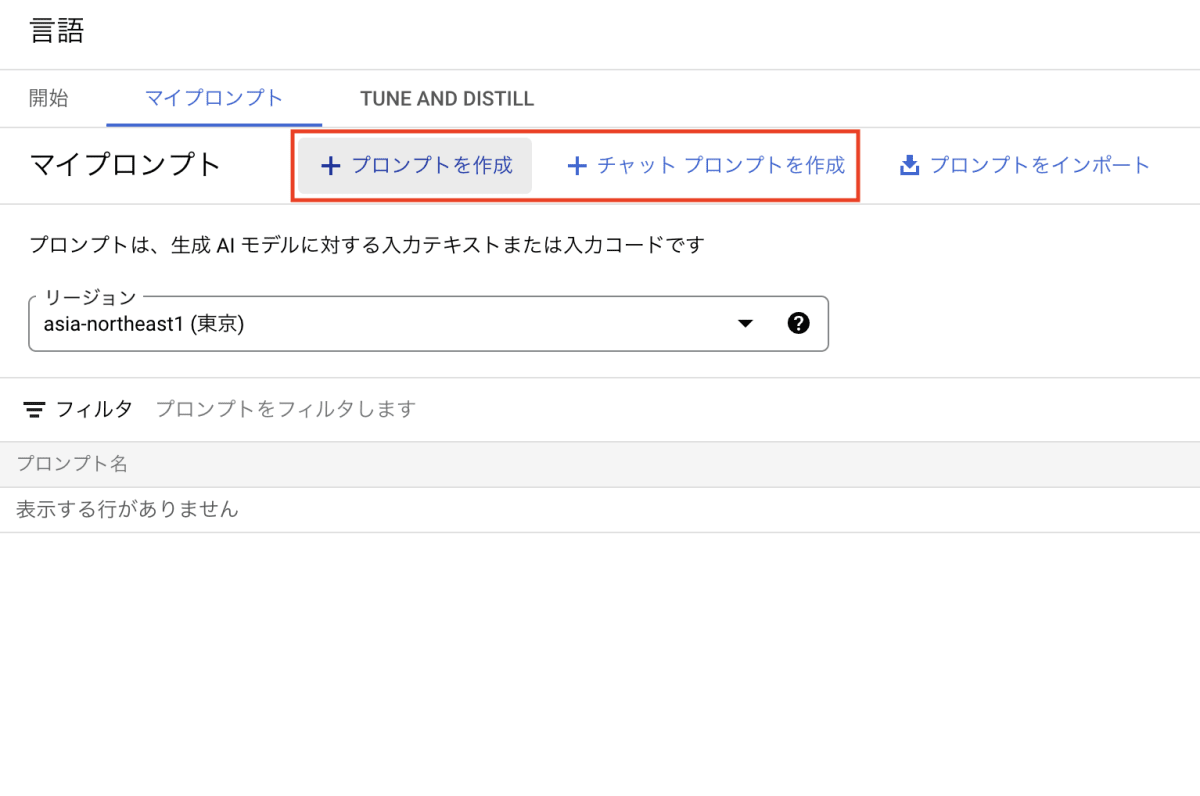
- 「マイプロンプト」から「リージョン」を選択してから「プロンプトを作成」および「チャットプロンプトを作成」をクリック(今回は「プロンプトを作成」を選択)
- 「モデル」から「Gemini Pro」を選択
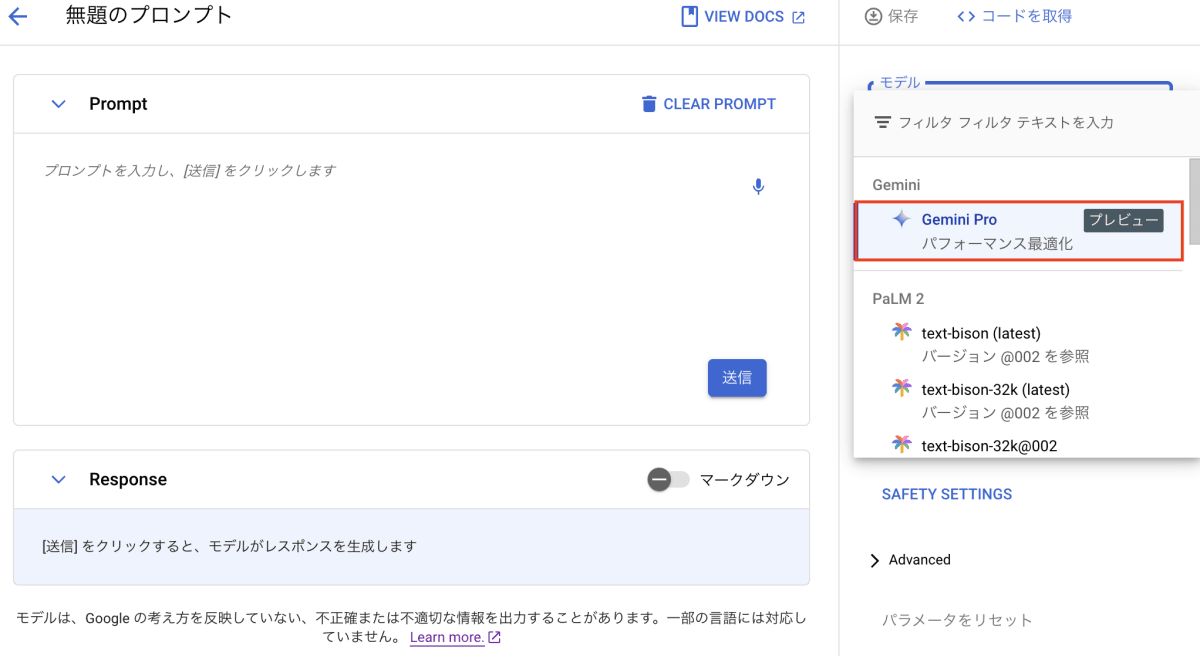
プロンプトは以下のように表示されます。

デモ
ストックホルムの旅行プランを考えてもらいましょう。

「送信」を押すと、ストックホルムの旅行プランが文章で返ってきました。
プロンプトの出力例
以下に、Gemini Ultra によるプロンプトとモデルの出力例を載せておきます(トグル)。
推論とコード生成
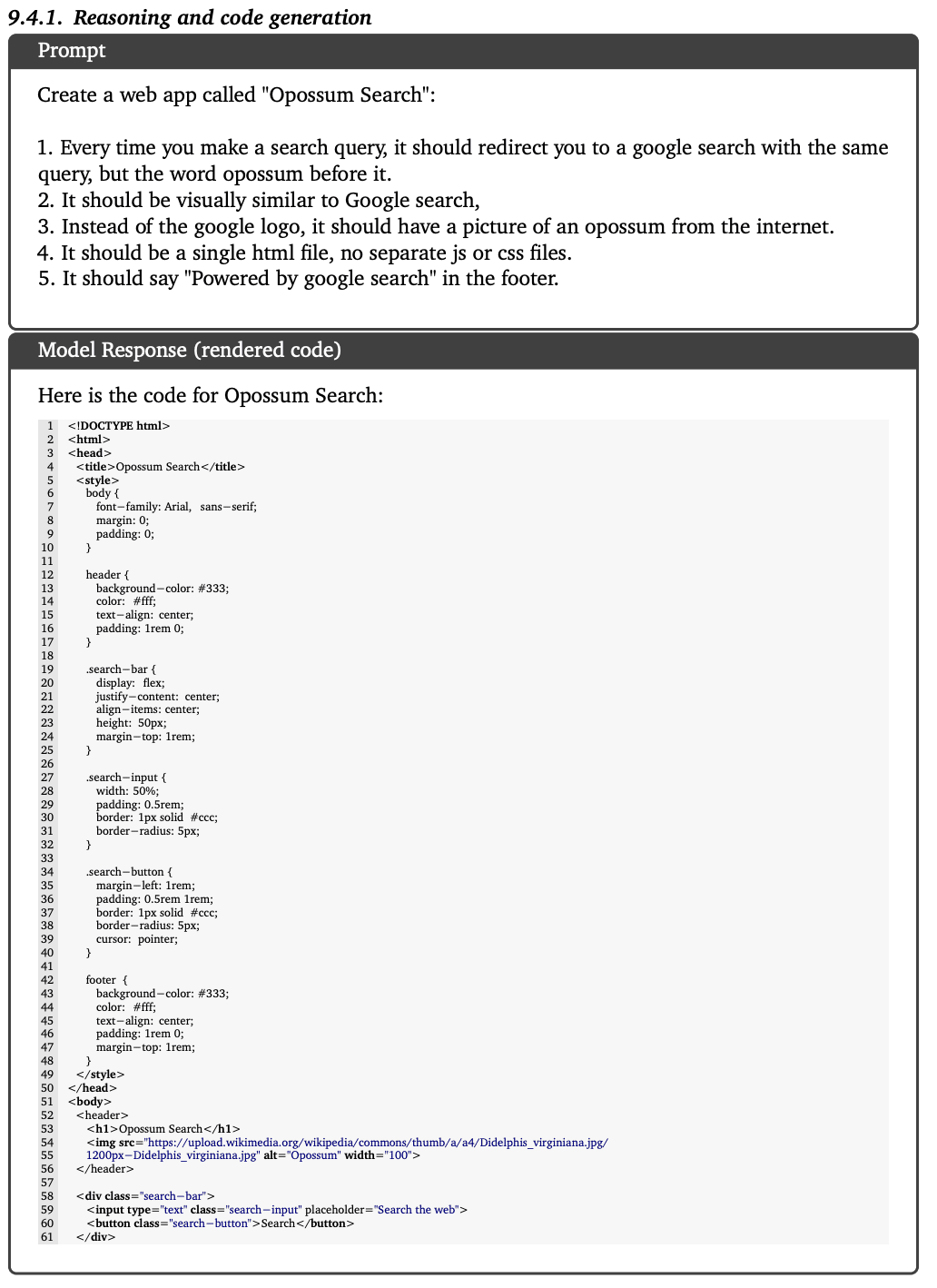
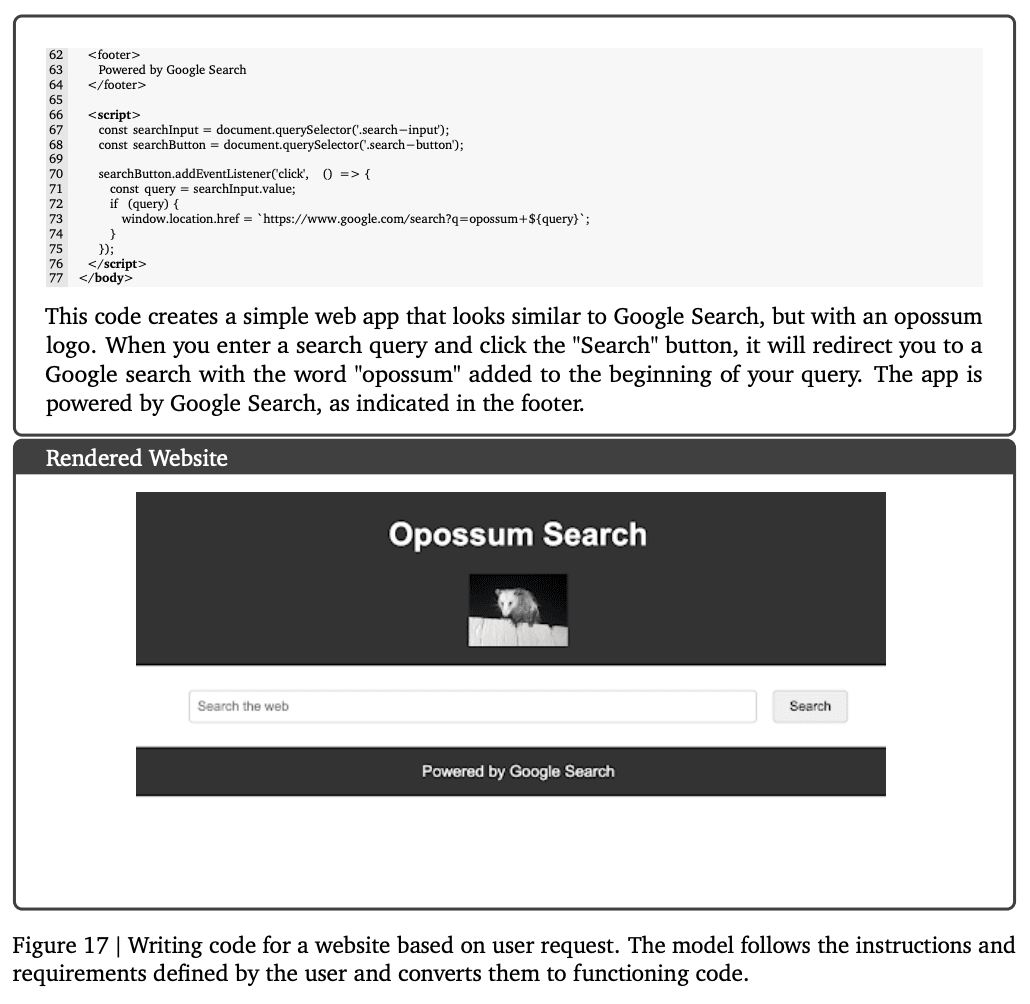
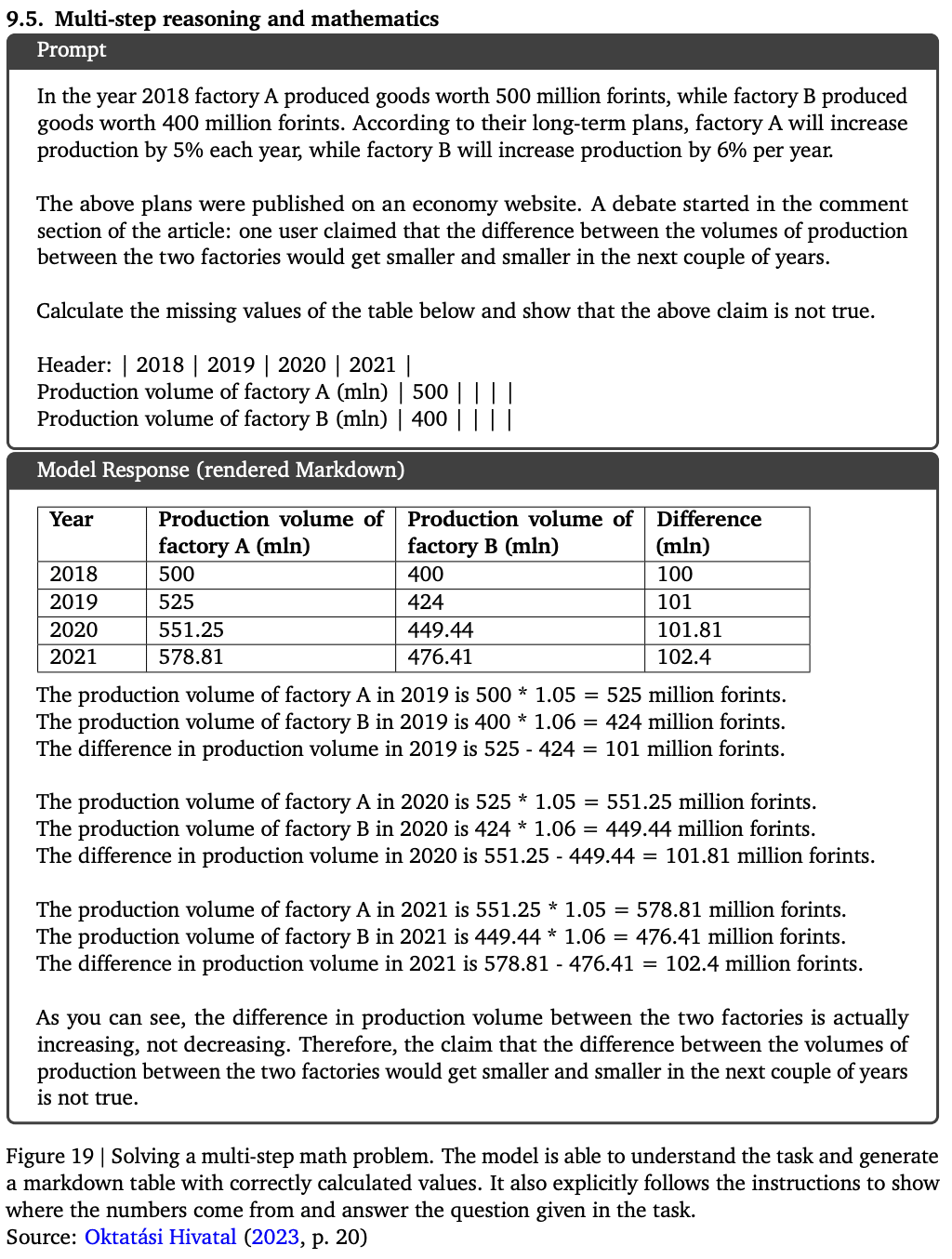
数学:微積分

多段階の推論と数学
Gemini Pro Vision
Vertex AI Studio 上で Gemini Pro Vision のプロンプトを開くには、以下の手順を行います。
- Vertex AI Stusio の「マルチモーダル」をクリック
- 「マイプロンプト」から「リージョン」を選択してから「プロンプトを作成」をクリック
プロンプトは以下のように表示されます。
画像デモ
筆者が好きなスウェーデンの工芸品の「ダーラナホース(ダーラヘスト)」のイラストを渡し、何が描かれているか聞いてみましょう。
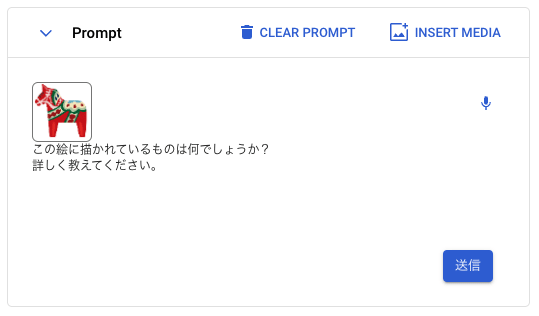
「送信」を押すと、質問の文章では触れていない、正しい絵の説明が文章で返ってきました。
プロンプトの出力例
以下に、Gemini Ultra によるプロンプトとモデルの出力例を載せておきます(トグル)。
チャートの理解とデータに関する推論
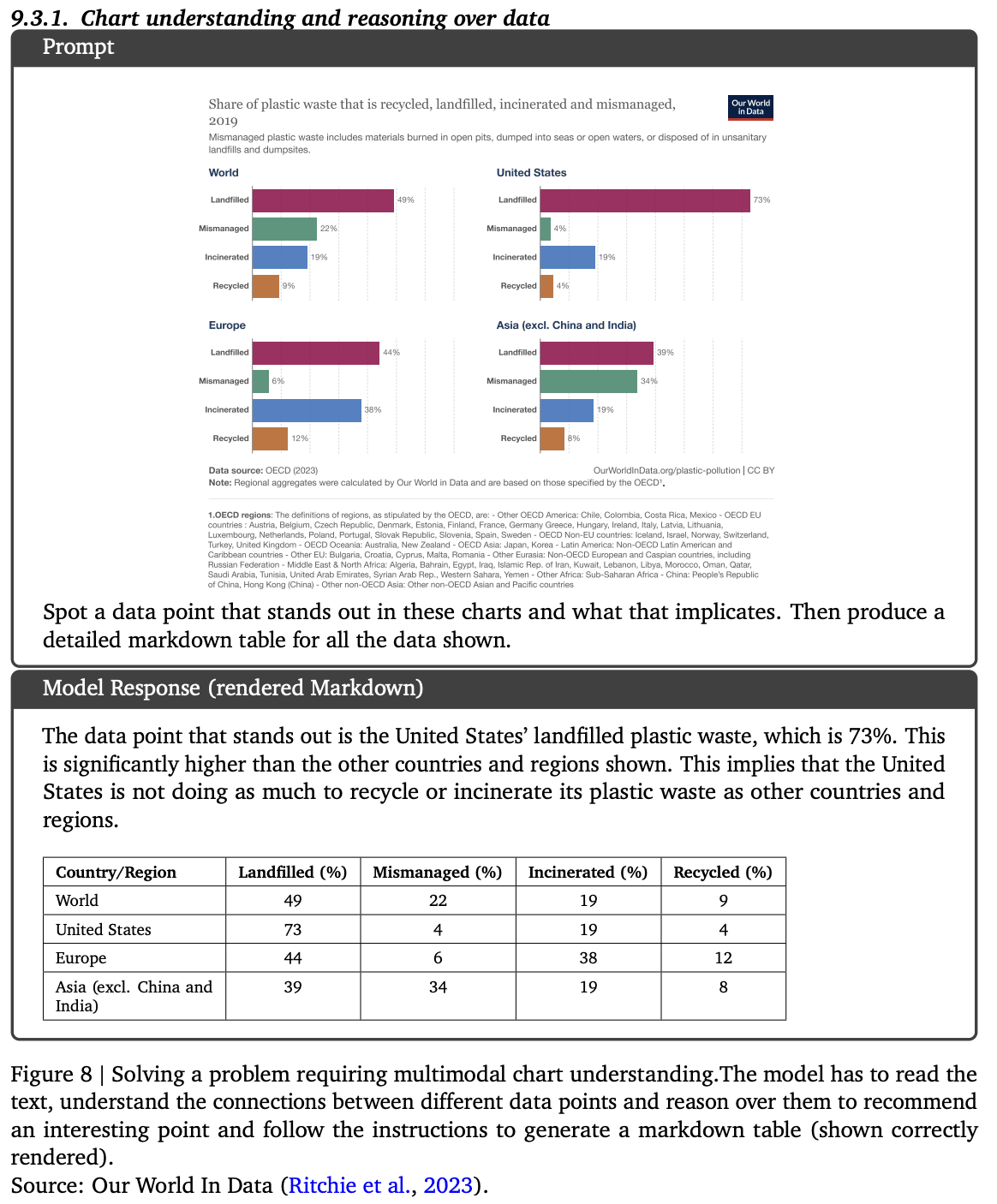
画像を用いた質疑応答

画像の理解と推論

幾何学的推論

物体に関する情報の探索

視覚的な手がかりに基づいた推論

ユーモアの理解

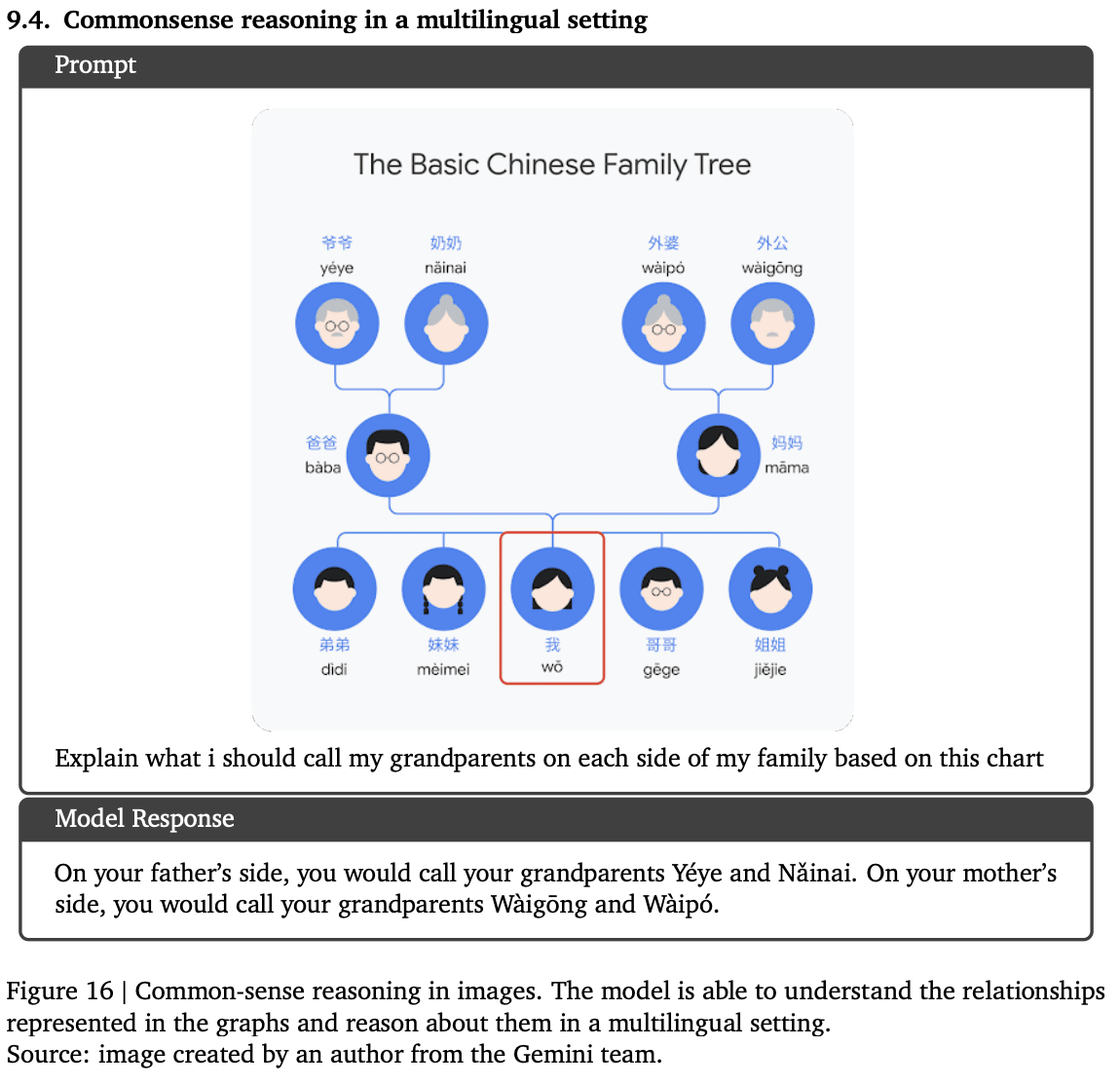
多言語環境における推論
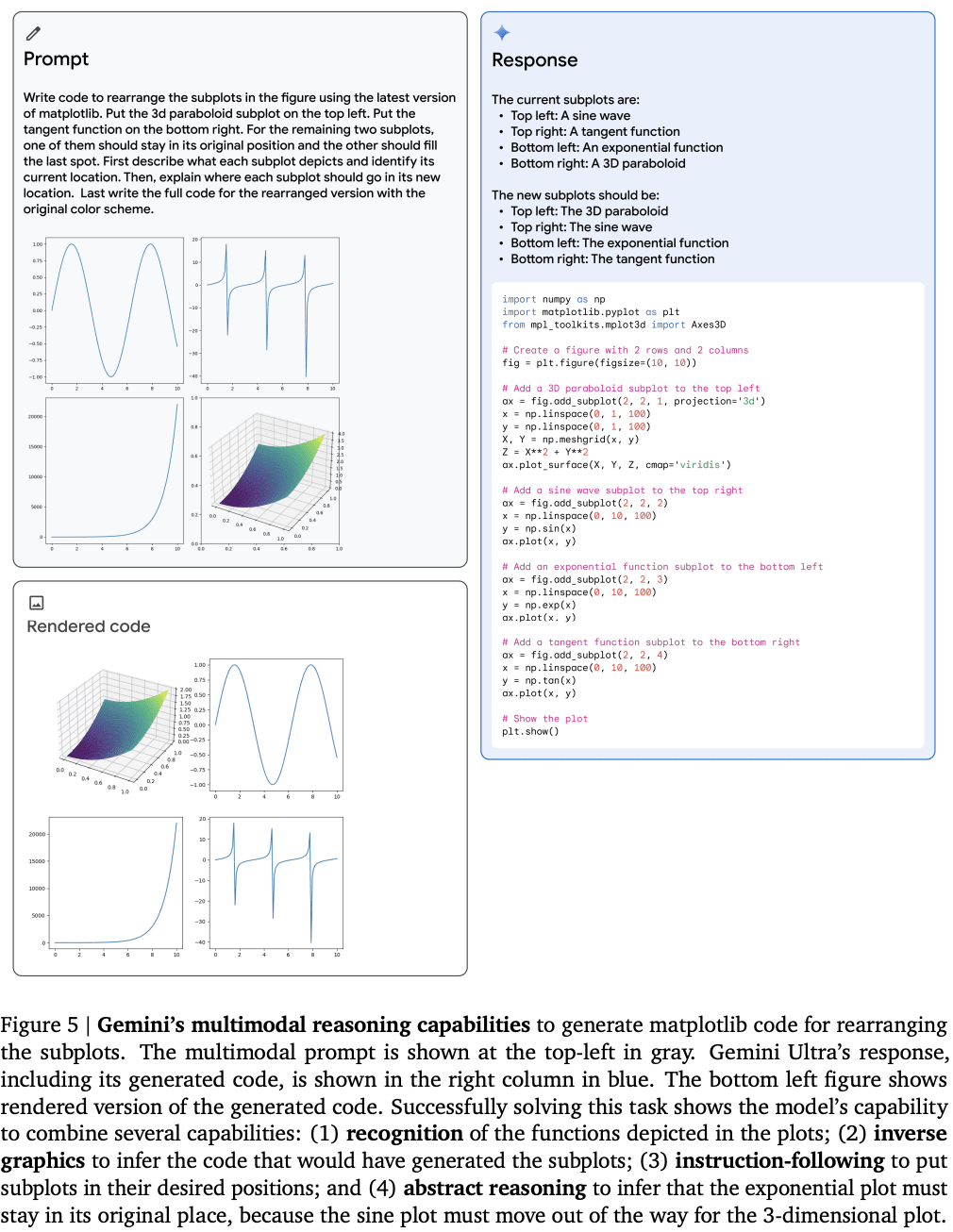
複雑な画像の理解、コード生成
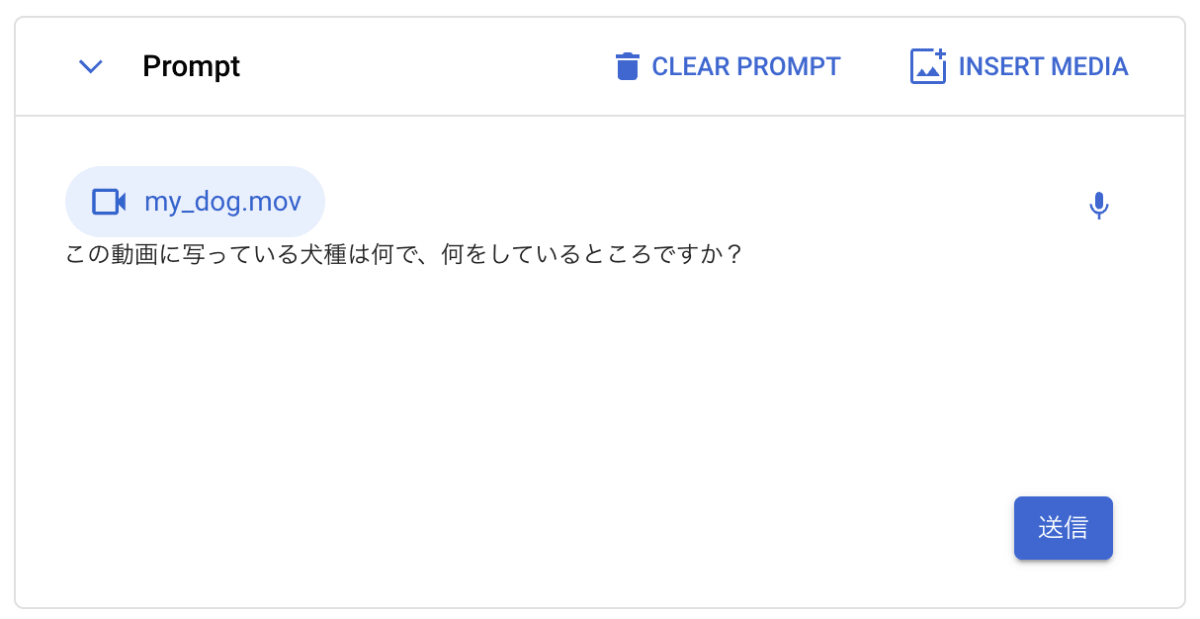
動画デモ
筆者の飼っている犬の動画を渡し、犬種と状況を聞いてみましょう。
「送信」を押すと、動画の状況を理解し、正しい回答が返ってきました。
プロンプトの出力例
以下に、Gemini Ultra によるプロンプトとモデルの出力例を載せておきます(トグル)。
動画の理解と推論

コードを取得
Vertex AI Studio 上で実行したプロンプトを SDK や API から実行するには、右上の「コードを取得」を押すと、各種言語のコードを取得することができます。
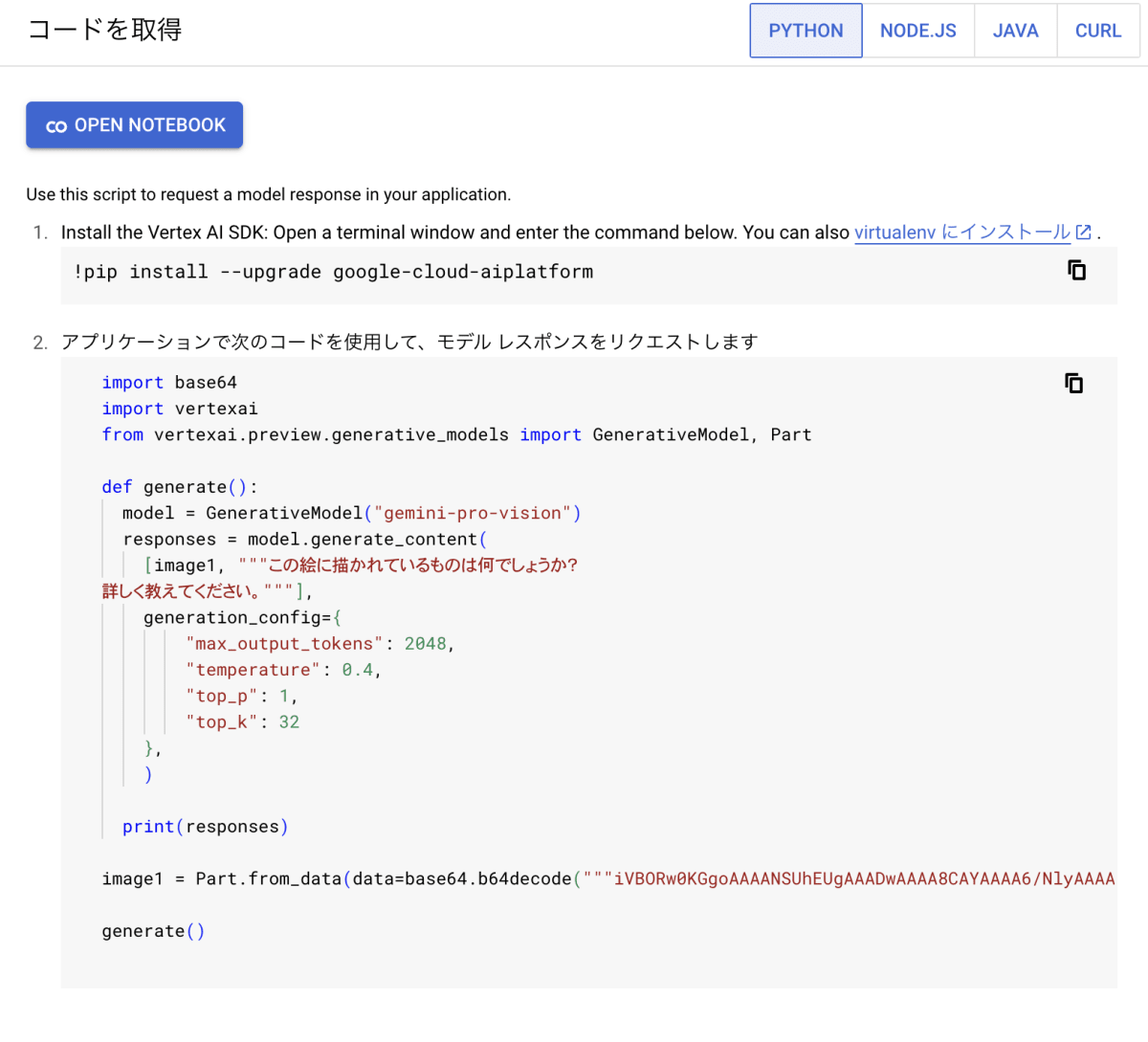
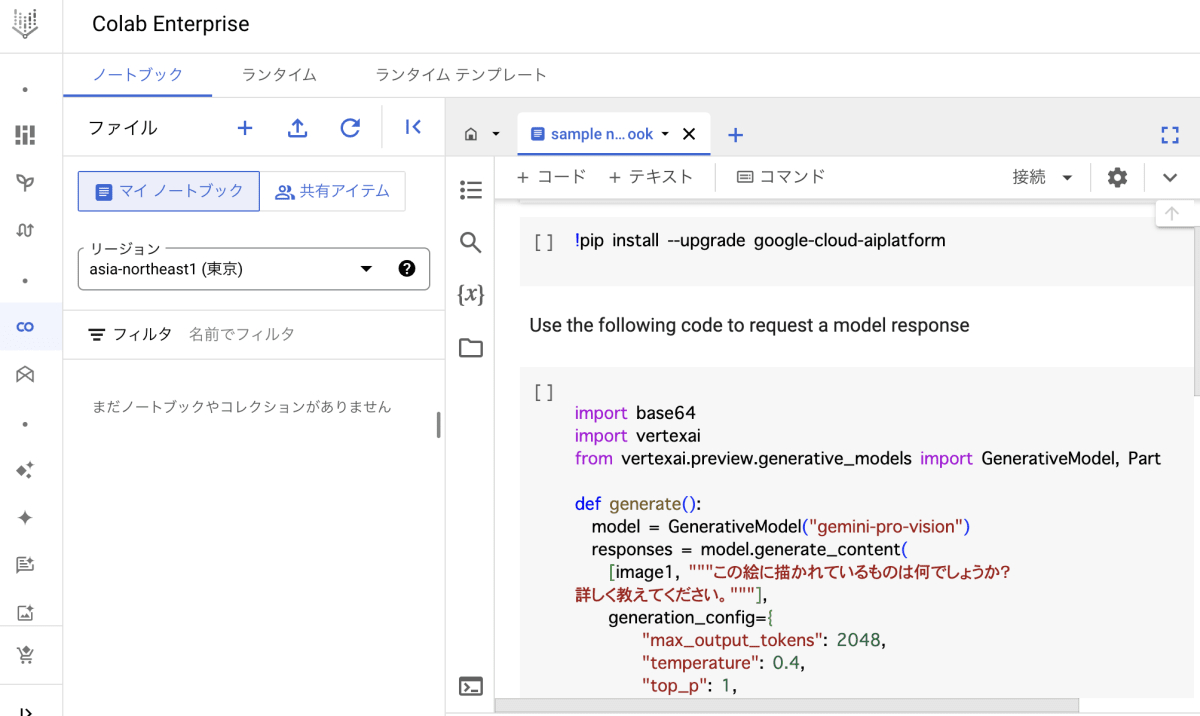
「PYTHON」を選んだ場合のみ、「OPEN NOTEBOOK」を押すと、Colab Enterprise が開きコードを実行することができます。
終わりに
今回は、Google が新しく発表したマルチモーダル生成 AI モデル Gemini 1.0 について紹介し、実際に Vertex AI Studio 上で動かしてみました。
ベンチマークテストをよく見ると、MMLU において、5-shot で計測されたスコアでは、Gemini Ultra は GPT-4 に勝ててなかったのが少し残念でした。また、Vertex AI 上で使えるようになった Pro においても、GPT-3.5 や PaLM 2 とほぼ同等のスコアのようなので、マルチモーダルなデータに対応したこと以外は少しインパクトに欠けてしまうような印象を受けました。
しかし、これまではタスクごとにそれに特化するモデルを作成し、それらが増えることによって管理コストが増えていってしまうという問題がありましたが、翻訳や画像認識などさまざまなタスクにおいて一つのモデルで好成績がだせる Gemini 1.0 のようなモデルを採用することによって、モデルの実装・管理コストを下げることができるのは素晴らしいことだと思います。
また、マルチモーダルなプロンプトを設計できるようになることで、画像自体を Retrieval-Augmented Generation(RAG) として利用することができたり、LangChain などのフレームワークからも、これまで以上の自由度を持って生成 AI アプリを実装できるようになることが期待できます。
検証においては、GPT-4 を超える性能の Gemini Ultra が公開されていないことや、日本語未対応の機能が多いこともあり、Gemini 1.0 の素晴らしさを十分に実感することはできませんでしたが、テキストだけに縛られず、画像や動画を用いて生成 AI を活用できるようになることを実感することができました。
参考資料
Discussion