Cloud SQLの変更データをKafka on GKE でキャプチャしてみませんか
はじめに
こんにちは。クラウドエース株式会社で SRE をしている間瀬です。
今回は Google Cloud上で Cloud SQL で更新されたデータを Apache Kafka(以下、Kafka) を経由して Pub/Sub や他のAPへ連携する方法を紹介したいと思います。
Cloud SQL と Kafka 間の連携は Debezium というOSSを利用して、Kafka は Google Kubernetes Engine (以下、GKE) へデプロイしていきます。
アーキテクチャ
今回紹介する方法を利用することで以下のようなアーキテクチャを実現することができます。

アーキテクチャのポイントは以下の通りです。
Debezium による Cloud SQL の変更データのキャプチャ
Debezium は Cloud SQL がサポートする Postgres, Mysql といった各種データベースに保管されているデータの変更をキャプチャして Kafka のトピックへ変更内容を連携します。
Debezium は Kafka Connector のソースコネクタとして使用します。
また、Kafka のトピックにメッセージが連携されたことをトリガーに自身で Consumer を実装したサービスを実行することができます。
Pub/Sub シンクコネクタによる Kafka から Pub/Sub へのデータ連携
Kafka Connector として提供されている Pub/Sub シンクコネクタを利用することで Kafka の特定のトピックに連携されたメッセージを Pub/Sub トピックへ連携することができます。これにより、Debezium から連携されたメッセージを Pub/Sub へ中継することが可能です。
Pub/Sub へ連携することで BigQuery, Cloud Run, Cloud Function などの各種 Google Cloud サービスと容易に連携することが可能です。
解決できる課題
データベースのトランザクションとメッセージ配信をアトミックに処理することが可能
Kafka 等でメッセージ配信を行う方式を採用する際に課題となるのが原子性の確保です。業務要件として、DBの更新とメッセージ配信の整合性を取る必要がある場合に課題になってきます。特にマイクロサービスアーキテクチャにおけるサービス間の連携において課題となるケースが多いです。
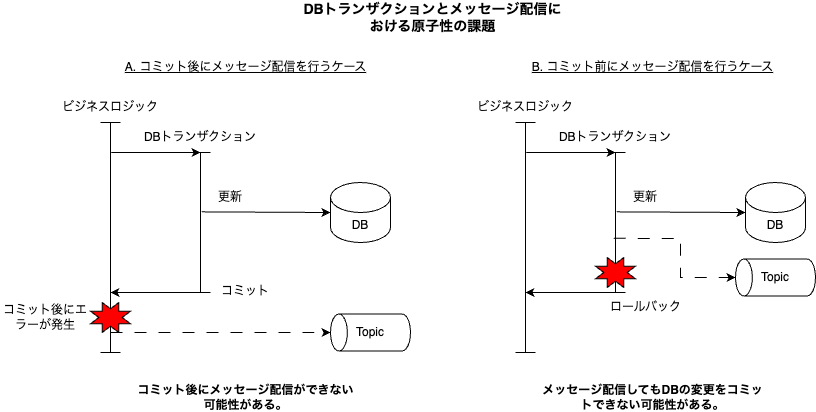
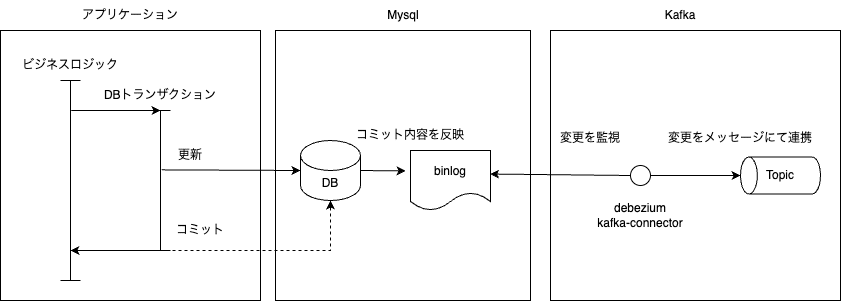
これに対して Debezium は DB において更新が確定したデータを抽出することが可能です。連携する DB によって方式は異なりますが、例えば Mysql であれば binlog という DB に対する変更が確定した情報が出力される領域からキャプチャする為、原子性を確保することが可能です。
BigQueryへのデータ連携を容易に実現することが可能
Cloud SQL 上のデータを利活用するために BigQuery へ同期するようなケースではバッチ等でパイプラインを構築する必要がありますが、本方式によって Cloud SQL から BigQuery への連携を AP を実装することなく実現することが可能です。テーブルの追加を行うような場合でも Kafka Connector や Pub/Sub の設定を追加するだけで実現することが可能です。
Google Cloudのイベント駆動サービスの拡張性を向上させることが可能
Kafka だけでは Google Cloud 上のサービスと連携する際に Kafka の Consumer AP を自前で開発する必要がありますが、Pub/Sub と連携することで連携用の AP を開発せずに他のサービスへ連携することが可能になります。これによって例えば業務の拡大による DB の拡張が行われることに伴う Cloud Run や Cloud Function などのイベント駆動サービスの追加が容易になります。
構築方法
今回紹介する構築範囲は Cloud SQL(Mysql) へ更新されたデータが Kafka を経由して BigQuery へ連携する範囲とします。
Cloud SQL
公式docを参考にインスタンスを作成します。今回紹介する機能を利用するためにはリソース等は最小構成で問題ありません。注意点としてポイントインタイムリカバリを有効化することを忘れないようにしてください。本設定を有効化することで Debezium が必要とする binlog が出力されるようになります。また、今回紹介する前提として GKE 上の Kafka Connector と Cloud SQL 間の接続は Private IP で行うため、Private IP を有効化するようにしてください。Private IP を有効化する方法はコチラを参照してください。
その他の設定についてはデフォルトのもので問題ありません。
GKE
クラスタの作成
公式docを参考にGKEを作成します。今回紹介する機能を検証する際はゾーンクラスタでノードは2台として、マシンタイプはe2-medium としています。クラスタのタイプは Standard としています。 Cloud SQL のPrivate IP を有効化する際に紐付けした VPC と同じ VPC 上にクラスタを作成するようにしてください。また、GKE と Pub/Sub 間の認証/認可は Workload Identity によるセキュアな方法で行うため、コチラを参考にクラスタ作成時または作成後に有効化するようにしてください。その他の設定についてはデフォルトのもので問題ありません。
参考までに gcloud コマンドでは以下のようになります。
gcloud beta container --project PROJECT_ID clusters create "kafka-gke" --zone "asia-northeast1-b" --no-enable-basic-auth --cluster-version "1.26.5-gke.1200" --release-channel "None" --machine-type "e2-medium" --image-type "COS_CONTAINERD" --disk-type "pd-balanced" --disk-size "100" --metadata disable-legacy-endpoints=true --scopes "https://www.googleapis.com/auth/cloud-platform" --num-nodes "1" --logging=SYSTEM,WORKLOAD --monitoring=SYSTEM --enable-ip-alias --network "projects/PROJECT_ID/global/networks/VPC_NAME" --subnetwork "projects/PROJECT_ID/regions/asia-northeast1/subnetworks/default" --no-enable-intra-node-visibility --default-max-pods-per-node "110" --security-posture=standard --workload-vulnerability-scanning=disabled --no-enable-master-authorized-networks --addons HorizontalPodAutoscaling,HttpLoadBalancing,GcePersistentDiskCsiDriver --no-enable-autoupgrade --enable-autorepair --max-surge-upgrade 1 --max-unavailable-upgrade 0 --no-enable-managed-prometheus --workload-pool "PROJECT_ID.svc.id.goog" --enable-shielded-nodes --node-locations "asia-northeast1-a","asia-northeast1-b"
クラスタ作成後は以下のコマンドで kube コンフィグを作成して接続できるようにします。
gcloud container clusters get-credentials kafka-gke --zone asia-northeast1-b --project PROJECT_ID
Workload Identity による認証/認可の準備
- GKEクラスタに namespace を作成
今回 Kafka をデプロイする名前空間を kafka として namespace を作成します。
kubectl create namespace kafka
- GKEクラスタにサービスアカウントを作成
Kafka Connector の Pod が使用することになるサービスアカウントを作成します。この後、Kafka を Strimzi という Kafka の Operator を使って構築する関係でサービスアカウント名には制約があります。
{KafkaConnectの名称}-connect というサービスアカウントになることに注意してください。ここでは名称を kafka-conn-cluster として以下のサービスアカウントを作成します。
kubectl create serviceaccount kafka-conn-cluster-connect \
--namespace kafka
- Google Cloud サービスアカウントを作成
上記で作成したサービスアカウントを紐づける Google Cloud のサービスアカウントを作成します。
gcloud iam service-accounts create pubsub-sink-connector@PROJECT_ID.iam.gserviceaccount.com \
--project=PROJECT_ID
- Google Cloud サービスアカウントへのロール付与
Pub/Sub へメッセージを配信するためのロールと Workload Identity を利用できるロールを付与します。
gcloud projects add-iam-policy-binding PROJECT_ID \
--member "serviceAccount:pubsub-sink-connector@PROJECT_ID.iam.gserviceaccount.com" \
--role "roles/pubsub.publisher"
gcloud iam service-accounts add-iam-policy-binding pubsub-sink-connector@PROJECT_ID.iam.gserviceaccount.com \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:PROJECT_ID.svc.id.goog[kafka/kafka-conn-cluster-connect]"
Kafka
今回は Kafka を Kubernetes 上で運用するための Operator である Strimzi というプロダクトを利用します。
Strimzi の Quick Starts ページを参考にインストールをしていきます。
Operator のインストール
まずは Operator 自体のインストールを行います。
kubectl create -f 'https://strimzi.io/install/latest?namespace=kafka' -n kafka
# 以下のコマンドで全ての Pod の Status が Running になることを確認してください。
kubectl get pod -n kafka --watch
Kafka Cluster の作成
以下の yaml ファイルで Kafka Cluster を作成します。
quickstart のコマンドで作成すると volumes のサイズが 100GiB になりますが、そこまで必要ないので 20GiB としています。
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.4.0
replicas: 1
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
inter.broker.protocol.version: "3.4"
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 20Gi
deleteClaim: false
zookeeper:
replicas: 1
storage:
type: persistent-claim
size: 20Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}
上記のコマンドの後に以下のコマンドでクラスタの状態が Ready になるまで待ちます。
kubectl wait kafka/my-cluster --for=condition=Ready --timeout=300s -n kafka
Kafka Connector のインストールについて
ここからやや複雑になってきます。Kafka Connector のインストールも Strimzi を利用することで可能ですが、今回利用する Debezium と Pub/Sub の Plugin を含めたコンテナイメージをビルドする必要があります。もちろん既にコンテナイメージを持っている場合は build の必要はありません。 Plugin をインストールする方法も複雑なので今回は Strimzi を利用していきます。尚、ビルドしたコンテナイメージは Google Cloud の Artifact Registry へプッシュします。
Artifact Registry へイメージを push するためのリポジトリと Secret を作成
Artifact Registry のリポジトリを公式docを参考に作成します。
作成したリポジトリへイメージを push するためには Artifact Registry に対する writer 権限が必要になりますが、 Strimzi の仕様でコンテナイメージを build する Pod のサービスアカウントに annotations が設定できない(正確には設定できるが、Operator によって上書きされ消えてしまう)ため、Workload Identity による認証/認可ができません。
今回は権限を付与した Google Cloud のサービスアカウントを用意して一時的にアカウントを使用することができるようにトークンを発行します。 その後、docker-registry の Secret を作成してビルドを行う Pod からイメージをプッシュできるようにします。
まずは以下の通り、Google Cloud のサービスアカウントを作成し、必要なロールを付与します。
gcloud iam service-accounts create kafka-connect-builder@PROJECT_ID.iam.gserviceaccount.com \
--project=PROJECT_ID
gcloud projects add-iam-policy-binding PROJECT_ID \
--member "serviceAccount:kafka-connect-builder@PROJECT_ID.iam.gserviceaccount.com" \
--role "roles/artifactregistry.writer"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member "serviceAccount:kafka-connect-builder@PROJECT_ID.iam.gserviceaccount.com" \
--role "roles/iam.serviceAccountTokenCreator"
以下のコマンドでサービスアカウントの token を発行します。
token の有効期限は 24h となることに注意してください。
TOKEN=`gcloud auth print-access-token \
--impersonate-service-account kafka-connect-builder@PROJECT_ID.iam.gserviceaccount.com`
上記の token を Pod で使用できるように Secret を作成します。
kubectl create secret docker-registry regcred --docker-server=https://LOCATION-docker.pkg.dev --docker-username=oauth2accesstoken --docker-password=$TOKEN --docker-email=<your-email>
KafkaConnectの作成
以下の yaml ファイルで KafkaConnect を作成します。プロジェクトIDやリージョンについては利用する際に修正してください。
ポイントとしては、本リソースを作成すると、Kafka Connector の Pod が利用するサービスアカウントが作成されるため、Workload Identity を利用できるようにするために最下部にてサービスアカウントの annotations へ必要な設定を加えています。
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: kafka-conn-cluster
annotations:
strimzi.io/use-connector-resources: "true"
spec:
version: 3.4.0
replicas: 1
bootstrapServers: my-cluster-kafka-bootstrap:9092
config:
config.providers: secrets
config.providers.secrets.class: io.strimzi.kafka.KubernetesSecretConfigProvider
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
# -1 means it will use the default replication factor configured in the broker
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1
build:
output:
type: docker
image: LOCATION-docker.pkg.dev/PROJECT_ID/kafka-cdc/kafka-connect-plugins:1.0.1
pushSecret: regcred
plugins:
- name: debezium-mysql-connector
artifacts:
- type: tgz
url: https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/2.3.0.Final/debezium-connector-mysql-2.3.0.Final-plugin.tar.gz
- name: pubsub-connector
artifacts:
- type: maven
repository: https://repo1.maven.org/maven2
group: com.google.cloud
artifact: pubsub-group-kafka-connector
version: 1.2.0
template:
serviceAccount:
metadata:
annotations:
iam.gke.io/gcp-service-account: pubsub-sink-connector@PROJECT_ID.iam.gserviceaccount.com
Debezium-connectorの有効化
有効化する際に幾つかのパラメータを設定します。Debezium から Cloud SQL へ接続するための情報もここで設定します。
データベースの接続情報は Secret に設定することが可能なのでこちらの機能を利用していきます。
以下のコマンドで Secret を作成します。
ユーザ名とパスワードは Cloud SQL 作成時に設定している情報を入力します。
kubectl create secret generic mysql-secret --from-literal=username=USERNAME --from-literal=password=PASSWORD
以下の yaml ファイルより Secret へアクセスできる Role を作成します。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: connector-configuration-role
namespace: kafka
rules:
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["mysql-secret"]
verbs: ["get"]
以下の yaml ファイルより Pod が利用するサービスアカウントが Role を利用できるよう Rolebinding を作成します。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: connector-configuration-role-binding
namespace: kafka
subjects:
- kind: ServiceAccount
name: kafka-conn-cluster-connect
namespace: kafka
roleRef:
kind: Role
name: connector-configuration-role
apiGroup: rbac.authorization.k8s.io
以下の yaml ファイルより Debezium を有効化します。
前提として database.include.list には キャプチャ対象とする database を設定します。
今回は Cloud SQL 上の shopping という database を対象としています。
その他のパラメータについては Debezium の 公式doc を参照してください。
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: debezium-connector-mysql
labels:
strimzi.io/cluster: kafka-conn-cluster
spec:
class: io.debezium.connector.mysql.MySqlConnector
tasksMax: 1
config:
database.hostname: xxx.xx.xx.xx
database.port: 3306
database.user: ${secrets:kafka/mysql-secret:username}
database.password: ${secrets:kafka/mysql-secret:password}
database.server.id: 184054
topic.prefix: mysql
database.include.list: shopping
schema.history.internal.kafka.bootstrap.servers: my-cluster-kafka-bootstrap:9092
schema.history.internal.kafka.topic: schema-changes.shopping
time.precision.mode: adaptive_time_microseconds
decimal.handling.mode: string
transforms: unwrap
transforms.unwrap.type: io.debezium.transforms.ExtractNewRecordState
KafkaTopic の作成
Debezium がキャプチャしたメッセージを受信する topic を作成します。
topic 名の前提として、shopping database に customer というテーブルが存在しているものとします。
各自作成したテーブル名に合わせて変更してください。
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: mysql.shopping.customer
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 1
replicas: 1
config:
retention.ms: 7200000
segment.bytes: 1073741824
キャプチャの確認
Cloud SQL のテーブル情報は以下の通りとします。mysql client は各自用意してください。
テーブルの DDL 等は ChatGPT が作ってくれるのでおすすめです。
# テーブルの一覧
MySQL [shopping]> show tables;
+--------------------+
| Tables_in_shopping |
+--------------------+
| customer |
+--------------------+
1 rows in set (0.002 sec)
# customer のテーブル構造
MySQL [shopping]> describe customer;
+--------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(255) | YES | | NULL | |
| mail_address | varchar(255) | YES | | NULL | |
| comment | text | YES | | NULL | |
+--------------+--------------+------+-----+---------+----------------+
4 rows in set (0.003 sec)
Kafka から Consume するための Pod を作成して mysql.shopping.customer に対して Consume を行います。
kubectl -n kafka run kafka-consumer -ti --image=quay.io/strimzi/kafka:0.35.1-kafka-3.4.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic mysql.shopping.customer --from-beginning
Consume しているウィンドウとは別のウィンドウで異なる customer テーブルに対して INSERT を行います。
INSERT INTO customer (name, mail_address, comment)
-> VALUES
-> ('Emily Johnson', 'emilyjohnson@example.com', 'This is Emily Johnson.');
INSERTと同時に Consume をしているウィンドウにて以下のようなメッセージが確認でき、変更内容がキャプチャされていることが分かります。
※ Debezium-connector-mysql の設定 (transforms.unwrap.type: io.debezium.transforms.ExtractNewRecordState) で変更後のデータのみ抽出していますが、変更前後のデータをキャプチャすることも可能です。
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"string","optional":true,"field":"name"},{"type":"string","optional":true,"field":"mail_address"},{"type":"string","optional":true,"field":"comment"}],"optional":false,"name":"mysql.shopping.customer.Value"},"payload":{"id":25,"name":"Emily Johnson","mail_address":"emilyjohnson@example.com","comment":"This is Emily Johnson."}}
pubsub-connectorの有効化
以下の yaml により、pubsub-connectorを有効化します。
PUBSUB_TOPIC はこの後作成する Pub/Sub トピック名を指定するようにしてください。
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: pubsub-connector
labels:
strimzi.io/cluster: kafka-conn-cluster
spec:
class: com.google.pubsub.kafka.sink.CloudPubSubSinkConnector
tasksMax: 1
config:
key.converter: org.apache.kafka.connect.storage.StringConverter
value.converter: org.apache.kafka.connect.converters.ByteArrayConverter
topics: mysql.shopping.customer
cps.project: PROJECT_ID
cps.topic: PUBSUB_TOPIC
Pub/Sub & BigQuery
ここからは Pub/Sub トピック、 BigQuery テーブル、BigQuery Subscriprion 、Pub/Sub スキーマを作成していきます。
Pub/Sub スキーマの作成は任意ですが、スキーマを用意するとメッセージデータの Json key 毎に BigQuery のテーブルカラムを割り当てることができます。
用意しない場合は data というカラムに全ての情報が格納されることになりますので、今回はスキーマを作成していきます。
Pub/Sub スキーマ
基本的な作成方法は公式docを参照してください。
今回は Apache Avro 形式で上記にて Consume したキャプチャデータを前提としたフォーマットを受信することとします。スキーマ定義は以下のようになります。
{
"type": "record",
"name": "Avro",
"fields": [
{
"name": "schema",
"type": {
"type": "record",
"name": "Schema",
"fields": [
{
"name": "type",
"type": "string"
},
{
"name": "fields",
"type": {
"type": "array",
"items": {
"type": "record",
"name": "Field",
"fields": [
{
"name": "type",
"type": "string"
},
{
"name": "optional",
"type": "boolean",
"default": true
},
{
"name": "field",
"type": "string"
}
]
}
}
},
{
"name": "optional",
"type": "boolean",
"default": false
},
{
"name": "name",
"type": "string"
}
]
}
},
{
"name": "payload",
"type": {
"type": "record",
"name": "Payload",
"fields": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "mail_address",
"type": "string"
},
{
"name": "comment",
"type": "string"
}
]
}
}
]
}
コンソールから作成することもできますが、コマンドラインで作成する場合、上記を json ファイルとして以下のコマンドで作成します。
以下の例ではファイルを schema.json としています。
gcloud pubsub schemas create shopping-customer \
--type=avro \
--definition-file=schema.json
BigQuery テーブルの作成
まずはテーブルを集約するデータセットを作成します。データセットの作成については公式docを参照してください。
コマンドで作成する場合は bq コマンドを利用します。
bq --location=asia-northeast1 mk -d \
--default_table_expiration 3600 \
--description "Change data capture for Cloud SQL" \
cloud_sql_cdc
データセットの作成後、以下の JSON を基にテーブルを作成します。テーブルの基本的な作成方法は公式docを参照してください。スキーマを指定する際に「テキストの編集」から入力すれば問題ありません。
[
{
"fields": [
{
"mode": "NULLABLE",
"name": "type",
"type": "STRING"
},
{
"fields": [
{
"mode": "NULLABLE",
"name": "type",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "optional",
"type": "BOOLEAN"
},
{
"mode": "NULLABLE",
"name": "field",
"type": "STRING"
}
],
"mode": "REPEATED",
"name": "fields",
"type": "RECORD"
},
{
"mode": "NULLABLE",
"name": "optional",
"type": "BOOLEAN"
},
{
"mode": "NULLABLE",
"name": "name",
"type": "STRING"
}
],
"mode": "NULLABLE",
"name": "schema",
"type": "RECORD"
},
{
"fields": [
{
"mode": "NULLABLE",
"name": "id",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "name",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "mail_address",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "comment",
"type": "STRING"
}
],
"mode": "NULLABLE",
"name": "payload",
"type": "RECORD"
},
{
"mode": "NULLABLE",
"name": "subscription_name",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "message_id",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "publish_time",
"type": "TIMESTAMP"
},
{
"mode": "NULLABLE",
"name": "data",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "attributes",
"type": "STRING"
}
]
コンソールから作成することもできますが、コマンドラインで作成する場合、上記を json ファイルとして以下のコマンドで作成します。
以下の例ではファイルを bq-schema.json としています。
bq mk \
--table \
cloud_sql_cdc.customer \
bq-schema.json
Pub/SubトピックとBigQuery Subscriptionの作成
Pub/Sub トピックとPub/Sub サブスクライバとなる BigQuery Subscription を作成していきます。
後者を利用することでトピックの情報を BigQuery テーブルへ書き込むことが可能です。
- Pub/Sub トピックの作成
公式docを参照して作成します。
トピックIDには pubsub-connector を有効化した際の TOPIC_ID と合わせるようにしてください。
コマンドラインで作成する場合は以下の通りです。
gcloud pubsub topics create shopping-customer \
--message-encoding=JSON \
--schema=projects/PROJECT_ID/schemas/shopping-customer
- BigQuery Subscription の作成
公式docを参照して作成します。
作成する中で、BigQuery テーブルは上記にて作成したテーブルを使用するように、Pub/Sub トピックスキーマについても上記で作成したスキーマを使用するようにしてください。
コマンドラインで作成する場合は以下の通りです。
gcloud pubsub subscriptions create shopping-customer-sub \
--topic=projects/ca-masem-zenn-kafka-cdc/topics/shopping-customer \
--bigquery-table=PROJECT_ID:cloud_sql_cdc.customer \
> --use-topic-schema --write-metadata --drop-unknown-fields
動作確認
ここまで作成した状態で今一度、Cloud SQL に対して更新を行うと、BigQuery テーブルへメッセージの内容が反映されていることが確認できるかと思います。

まとめ
構築手順が大変長くなりましたが、今回は Kafka を中心とした Cloud SQL の変更データをキャプチャして更に Pub/Sub へ連携する方法を紹介しました。本内容はBigQuery へのデータ連携やマイクロサービス間の連携、Google Cloud の他サービスへの連携に有効であるため、是非検討してみてください。
尚、今回は Kafka を GKE 上に構築しましたが、必ずしも GKE である必要はなく IaaS である Google Compute Engine 上に構築する方法でも実現は可能です。
Discussion