BigQuery における、ベクトル検索とベクトルインデックス機能
はじめに
こんにちは。クラウドエース データソリューション部所属の 髙根 です。
クラウドエースの データソリューション部 では、IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門としています。
データソリューション部の活動の一環として、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。
新規リリースの中で、特に重要と考えるリリースを本ページ含め記事として公開しています。
今回ご紹介する内容は、2024年 1 月 31 日 にプレビュー段階となった BigQuery における ベクトル検索 と ベクトルインデックス の機能追加についてです。
BigQuery の概要
BigQuery は、Google Cloud が提供するフルマネージドでサーバーレスなデータウェアハウスです。ビッグデータの蓄積や分析を可能とし、Google Cloud を代表するプロダクトです。SQL を使用して、大規模なデータを処理することができ、高いコストパフォーマンスを可能とします。
ベクトル検索 とは
ベクトル検索 とは、最近傍検索を行う手法です。
あるベクトルが与えられた時に、そのベクトルに最も近い他のベクトルをデータベースから探索します。BigQuery では、VECTOR_SEARCH 関数 を用いて使用できるようになりました。
最近傍検索
多次元空間における特定の点に最も近い点を探すためのアルゴリズムです。例えば、ある商品の推奨アイテムを探す際に、その商品の特徴に 最も近い他の商品 を探す方法として 最近傍検索 が使用されます。
ベクトルインデックス とは
ベクトルインデックス とは、ベクトル検索 を高速に実行するためのオプションです。
ベクトルインデックス を使用することで、ベクトル検索 のパフォーマンスを向上させることができます。しかし、検索パフォーマンスが向上する代わりに再現率が低下し、より近似的な結果が返される、といったトレードオフがあります。
ベクトルインデックス
BigQuery で ベクトルインデックス を使用するには、ベクトル検索 を行うテーブルのカラムに対して、ベクトルインデックス を作成します。作成には、以下の設定を行います。
- ベクトル間の類似性の計算に使用する距離計算方法の指定
- ベクトルインデックス のタイプの指定
- 指定した ベクトルインデックス のタイプに関する設定
ベクトル検索 と ベクトルインデックス の料金
下記の 2点 の使用料金は、BigQuery の料金 に従います。CREATE VECTOR INDEX については、ベクトルインデックス が作成されたカラムのみが、処理バイト数に含まれます。
-
VECTOR_SEARCH: ベクトル検索関数 -
CREATE VECTOR INDEX: ベクトルインデックス作成文
ベクトル検索 を検証してみた
実際に、BigQuery テーブルに保存されているエンベディングに対して、下記の検証内容 1 , 2 , 3 を行います。
検証内容
- ベクトルインデックス を使用した ベクトル検索
- ベクトルインデックス を使用しない ベクトル検索
- ベクトル検索 の 検索時間 の比較
エンベディングとは
これは、テキストや画像などの複雑なデータを ベクトルで表現 したものです。
エンベディングを使用し、複雑なデータを数値データに変換することで、それに基づいてデータ間の類似性を計算することができます。
はじめる準備
はじめる準備として、下記手順を行う必要があります。
- Google Cloud コンソールの [プロジェクトセレクタ] ページで、Google Cloud プロジェクトを選択、または作成をします。
- Google Cloud プロジェクトの課金が有効になっていることを確認します。
- BigQuery API を有効にします。
必要な権限 の付与
ベクトル検索 と ベクトルインデックス を実行するには、
下記の Identity and Access Management (IAM) 権限が必要となります。
- データセット作成の権限
bigquery.datasets.create - テーブル作成の権限
bigquery.tables.create
bigquery.tables.updateData
bigquery.jobs.create - ベクトルインデックス を作成するための、インデックスを作成するテーブルへの権限
bigquery.tables.createIndex - ベクトルインデックス を操作するために必要な権限
roles/bigquery.dataOwner
roles/bigquery.dataEditor
データセットを 作成する
BigQuery データセットを作成します。
- Google Cloud コンソールで、BigQuery ページに移動します。
- [エクスプローラー] ペインで、[プロジェクト名] をクリックします。
- [アクション表示] > [データセットの作成]
-
[データセットの作成] で下記の操作を行います。
・ [データセット ID] に設定したい ID を入力します。
・ [ロケーション タイプ] は [マルチリージョン] を選択します。
・ [US (米国の複数の地域)] を選択します。
(公開データセットは US マルチリージョンに保存されているため、データセットを同じ場所に保存します。) - 残りの設定はそのままにして、[データセットの作成] をクリックします。
テストテーブル を作成する
今回は、 Google Patents public dataset に基づいて、特許の埋め込みを含むテーブルを作成します。下記 SQL をクエリエディタ実行し、patents(テーブル) を作成します。
CREATE TABLE vector_search.patents AS
SELECT * FROM `patents-public-data.google_patents_research.publications`
WHERE ARRAY_LENGTH(embedding_v1) > 0
AND publication_number NOT IN ('KR-20180122872-A');
上記の SQL は、patents-public-data.google_patents_research.publications(テーブル) から特定の条件を満たす行を選択し、それらを新しいテーブルとして patents を作成します。具体的な条件は下記の 3つ を設定します。
-
ARRAY_LENGTH(embedding_v1) > 0:embedding_v1という配列の長さが0より大きい(何かしらのデータが含まれている)行だけを抽出します。 -
publication_number NOT IN ('KR-20180122872-A'):publication_numberが'KR-20180122872-A'でない行だけを抽出します。
実行後、patents が作成されていることを確認します。作成した patents のレコード数は、150,893,272行 となります。

続いて、下記 SQL をクエリエディタ実行し、最近傍の探索を行う際の基準となる、特許の埋め込みを含む patents2(テーブル) を作成します。
CREATE TABLE vector_search.patents2 AS
SELECT * FROM `patents-public-data.google_patents_research.publications`
WHERE publication_number = 'KR-20180122872-A';
上記の SQL は、patents-public-data.google_patents_research.publications から publication_number が 'KR-20180122872-A' である行を選択し、新しいテーブルとして patents2 を作成します。具体的な条件は下記の 1つ を設定します。
-
WHERE publication_number = 'KR-20180122872-A': どの行を抽出するか指定します。ここでは、publication_numberが'KR-20180122872-A'である行を抽出します。
実行後、patents2 が作成されていることを確認します。

ベクトルインデックス を作成する
下記 SQL をクエリエディタ実行し、ベクトルインデックス を作成します。
CREATE VECTOR INDEX my_index ON vector_search.patents(embedding_v1)
OPTIONS(distance_type='COSINE', index_type='IVF', ivf_options='{"num_lists": 1000}');
上記の SQL は patents の embedding_v1 カラムに対して、ベクトルインデックス を作成します。
OPTIONS句 では、ベクトルインデックス の作成に関する下記 3つ のオプションを設定します。
-
distance_type='COSINE': ベクトル間の類似性を計算する際に使用する距離計算方法を指定します。 -
index_type='IVF': ベクトルインデックス のタイプを指定します。IVF(Inverted File)は、大規模なベクトルデータに対する検索を高速化するための手法です。 -
ivf_options='{"num_lists": 1000}': IVFインデックスの作成に関する設定を指定します。ここでは、IVFインデックスのリスト数を1000に設定します。

ベクトルインデックス の作成状況の確認
上記で作成した ベクトルインデックス の作成状況の確認を行います。
特に、coverage_percentage の値が 100 であることを確認します。これは、ベクトルインデックス が全ての行をカバーしていることを意味します。coverage_percentage は下記 SQL を実行することで確認が可能です。
coverage_percentage の値を確認する重要性
ベクトルインデックス の coverage_percentage は、そのインデックスがテーブルのどの程度をカバーしているかをパーセンテージで表したものです。値が 100 であるということは、全ての行が ベクトルインデックス によってカバーされている、インデックスが完全に作成されていることを意味します。
もし、coverage_percentage の値が 100未満 であれば、それはインデックスがまだ完全には作成されておらず、一部の行がインデックスに含まれていないことを示しています。その結果、インデックスを利用した検索や分析が不完全になり、期待した結果を得られない可能性があります。
したがって、ベクトルインデックス を作成した後は、coverage_percentage の値を確認して、インデックスが正しく完全に作成されたことを確認することが重要となります。
SELECT * FROM vector_search.INFORMATION_SCHEMA.VECTOR_INDEXES;

1. ベクトルインデックス を使用した ベクトル検索 の検証
ベクトルインデックス を使用した ベクトル検索の検証を行います。
作成した ベクトルインデックス を利用して、特定の特許( patents2 に格納されている特許)と、最も類似する特許( patents に格納されている特許)を検索します。
具体的には、BigQuery の VECTOR_SEARCH 関数 を使用します。この関数を使用し、指定したベクトル( 本検証の場合、patents2 の embedding_v1 カラム のエンベディング)と最も類似するベクトル( 本検証の場合、patents の embedding_v1 カラムのエンベディング)を探索します。
下記 SQL をクエリエディタ実行し、特許データベース内の 特定の特許(今回は、publication_number が KR-20180122872-A の特許)に最も類似した特許を探索します。
下記の SQL では、下記 2つ のオプションを設定します。
-
top_k => 5: 検索で返される、上位結果の数を設定します。 -
options => '{"fraction_lists_to_search": 0.005}': 検索の追加オプションを設定します。fraction_lists_to_searchでは、検索中の再現率と検索速度の間のトレードオフを制御するパラメーターです。値が小さいほど検索速度は速くなりますが、再現率が低くなる可能性があります。逆に、値を大きくすると検索速度が遅くなり、再現率は高くなります。
SELECT query.publication_number AS query_publication_number,
query.title AS query_title,
base.publication_number AS base_publication_number,
base.title AS base_title,
distance
FROM
VECTOR_SEARCH(
TABLE vector_search.patents,
'embedding_v1',
TABLE vector_search.patents2,
top_k => 5,
distance_type => 'COSINE',
options => '{"fraction_lists_to_search": 0.005}');
下記が、実行した SQL(赤枠) と結果(青枠)のテーブルになります。

テーブル内には、特許データベース内の 特定の特許 に、最も類似した特許に近い 5つ を抽出しており、特定の特許 と 各特許 のエンベディングの距離を昇順でリストしています。
distance カラムが、エンベディングの距離を示しています。この数値は 0 から 1 の範囲で表され、値が小さいほど 2つ の特許が類似している、という結果になります。
従って、本検証で最も近い特許(最も類似した特許)は、公開番号が KR-101967621-B1 の特許 となりました。
2. ベクトルインデックス を使用しないベクトル検索の検証
ベクトルインデックス を使用した ベクトル検索 と同一の内容で、ベクトルインデックス を 使用しない ベクトル検索を行います。
下記 SQL をクエリエディタ実行し、特許データベース内の 特定の特許 に最も類似した特許を探索します。
SELECT query.publication_number AS query_publication_number,
query.title AS query_title,
base.publication_number AS base_publication_number,
base.title AS base_title,
distance
FROM
VECTOR_SEARCH(
TABLE vector_search.patents,
'embedding_v1',
TABLE vector_search.patents2,
top_k => 5,
distance_type => 'COSINE',
options => '{"use_brute_force":true}');
下記が、実行した SQL(赤枠) と結果(青枠)のテーブルになります。

ベクトルインデックス を 使用しない ベクトル検索の結果は、ベクトルインデックス を使用した ベクトル検索と同一の結果となり、最も近い特許(最も類似した特許)は、公開番号が KR-101967621-B1 の特許 となりました。
3. ベクトル検索時間の比較
ベクトルインデックス を 使用した ベクトル検索と、ベクトルインデックス を 使用しない ベクトル検索の検索時間の比較を行います。
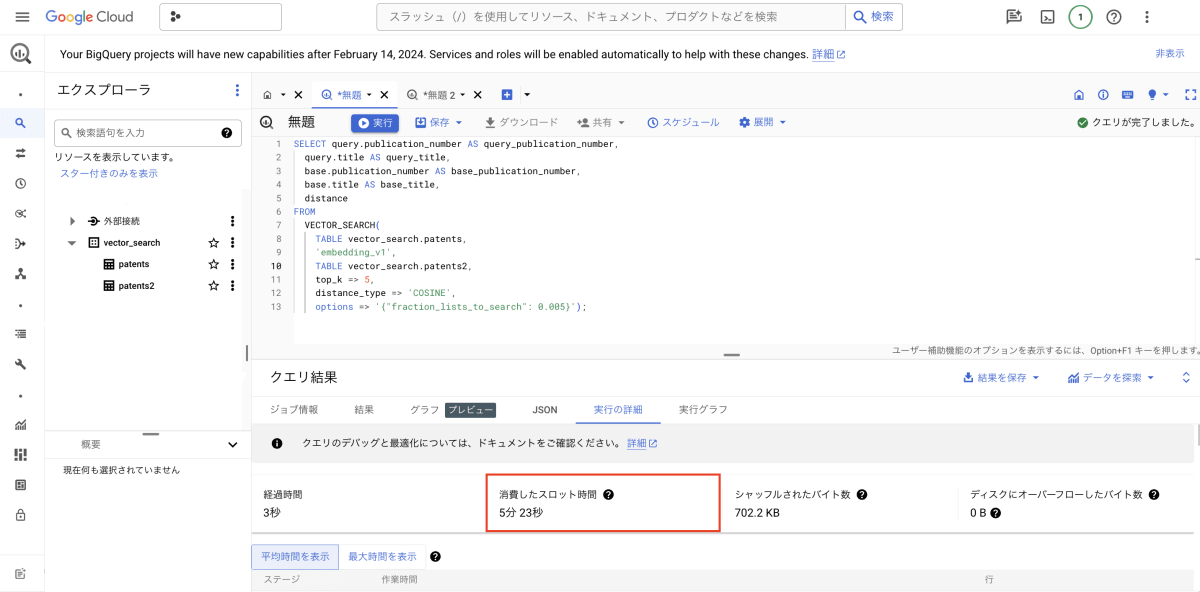
下記が、ベクトル検索の検索時間(赤枠)となっています。
ベクトルインデックス を 使用した ベクトル検索時間
ベクトルインデックス を 使用しない ベクトル検索時間

上記の結果から、ベクトルインデックス を 使用しない ベクトル検索と比べて、ベクトルインデックスを 使用した ベクトル検索の方が、消費したスロット時間が短くなっているのがわかります。
これは、効率的にスロットを使用できていると考えられます。また、BigQuery の新課金体系の場合、スロット使用量に対する課金となるため、ベクトルインデックスを 使用した ベクトル検索の方が、安く使用することができます。
まとめ
今回は、BigQuery における、ベクトルインデックス を使用した ベクトル検索 についてご紹介しました。検証を通し、ベクトル検索 に対し ベクトルインデックス を使用することで、消費したスロット時間が短くなることがわかりました。BigQuery で大量のデータを扱う際には、ベクトルインデックス の活用を推奨致します。
現在はプレビュー段階ですが、ぜひお試しください。
Discussion