batchについて試してみた
はじめに
こんにちは、クラウドエース データML ディビジョン所属のディエゴです。
クラウドエースのITエンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータML ディビジョンです。
データML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回紹介するリリースは2023年4月11日のBatchのリリースです。
本リリースでは Batch が asia-northeast1(東京) europe-west4 (オランダ)のリージョンで使用可能になりました。
このリリースにより、日本のリージョンでBatchが使用できます。
そこで今回は、そもそもBatchとは何かについての調査を行いたいと思います!
Batchとは
概要
Batch は、 Compute Engine VM 上ででバッチ処理ワークロードをスケジュールし、キューに入れて実行するフルマネージドバッチサービスです。
ユーザーに代わりBatchがリソースをプロビジョニングし、容量を管理することで、バッチワークロードを大規模に実行できます。
Batchは、次のコンポーネントで構成されています。
- ジョブ:計算ワークロードを処理するためのスケジュールされたプログラムであり、ユーザーの操作なしで一連のタスクを完了します。各ジョブは1つ以上のタスクの配列で構成され、ジョブの実行可能スクリプトとコンテナが実行されます。ジョブのタスクは、ジョブのリソースに対して並列に実行することも、順次実行することもできます
- タスク:ジョブの一部として定義され、ジョブの実行時に実行されるプログラムによるアクションのことです。
- リソース:ジョブは Compute Engine 仮想マシン(VM)インスタンスのリージョン マネージド インスタンス グループ(MIG)で実行されます。必要に応じて GPU の追加や、ローカル SSD や Cloud Storage などの追加のリソースを設定することもできます。
料金
料金はジョブの実行に必要な基盤となるリソース( Compute Engine, Cloud Storage 等)の費用のみが課金され、Batch を使用することによる追加料金は発生しません。
制限事項
- プロジェクトのバッチ割り当てと上限を超えることはできません。
- マシンタイプは、ジョブごとに1つ指定します。事前定義されたマシンタイプまたはカスタムマシンタイプを指定できます。
- ジョブに特定の VM イメージを使用したい場合には、インスタンス テンプレートを使用してジョブを作成する必要があります。
- ジョブごとに複数のタスクグループを指定することはできません。すべてのジョブに group0 という名前のタスクグループが1つ存在します。
試してみた
検証概要
今回は Google Cloud のチュートリアルを参考に、ワークフローを用いた Batch ジョブを実行したいと思います。このチュートリアルでは0から60000までの数から、素数を抜き出しテキストに書き出します。
チュートリアルを始める前の準備
- Google Cloud プロジェクトに対して課金を有効にします。
- Artifact Registry API、Batch API、Cloud Build API、Compute Engine API、Workflow Execution API、Workflows API を有効にします。
- サービス アカウントを作成し、バッチジョブ編集者、ログ書き込み、ストレージ管理者のロールを付与します。
- デフォルトのサービス アカウントに対する IAM サービス アカウント ユーザーのロールを、前の手順で作成したユーザー管理のサービス アカウントに付与します。
1. Artifact Registry リポジトリを作成する
Google Cloud コンソールで、[リポジトリ] ページに移動し、 [リポジトリを作成] をクリックします。
以下の図のように設定を行います。
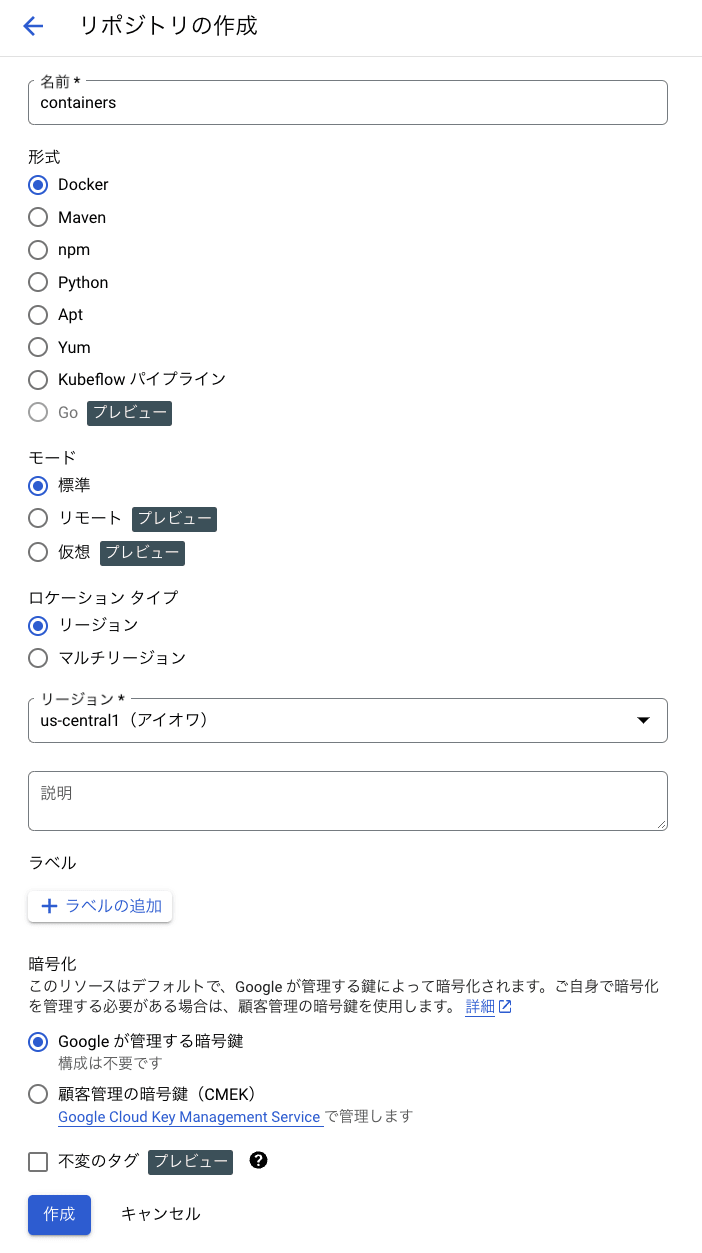
[作成] をクリックします。
2.コードサンプルを取得する
チュートリアル用のアプリケーション ソースコードが GitHub に保存されているので、対象のリポジトリのクローンを作成し、サンプルコードが入っているディレクトリに移動します。
コマンドは以下の通りに入力します。
$ git clone https://github.com/GoogleCloudPlatform/batch-samples.git
Cloning into 'batch-samples'...
remote: Enumerating objects: 159, done.
remote: Counting objects: 100% (26/26), done.
remote: Compressing objects: 100% (24/24), done.
remote: Total 159 (delta 7), reused 4 (delta 2), pack-reused 133
Receiving objects: 100% (159/159), 38.25 MiB | 15.90 MiB/s, done.
Resolving deltas: 100% (75/75), done.
$ cd batch-samples/primegen
/batch-samples/primegen$
3.Cloud Build を使用して Docker イメージをビルドする
Docker イメージをビルドするために、以下のコマンドを移動したディレクトリで実行します。
/batch-samples/primegen$ gcloud builds submit \
-t us-central1-docker.pkg.dev/ca-saduka/containers/primegen-service:v1 PrimeGenService/
成功すると以下のようなメッセージが表示されます。
DONE
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ID: 7afba69f-ae2d-4d94-bd3a-dc899c79dce0
CREATE_TIME: 2023-05-24T09:25:48+00:00
DURATION: 51S
SOURCE: gs://ca-saduka_cloudbuild/source/1684920345.092196-00948651f25348acae1e9b98035d6893.tgz
IMAGES: us-central1-docker.pkg.dev/ca-saduka/containers/primegen-service:v1
STATUS: SUCCESS
4.Batch ジョブをスケジュール設定して実行するワークフローをデプロイする
次に2つの Compute Engine VM で Docker コンテナを6つのタスクとして並列実行する Batch ジョブをスケジュール設定します。
実行すると、素数を書き出す6個のバッチが生成され、結果を Cloud Storage バケットに格納します。
Google Cloud コンソールの [ワークフロー] ページに移動し、[作成] をクリックします。
以下の図のような設定します。
サービス アカウントは先ほど作成したものを選択します。

[次へ] をクリックします。
ワークフローの定義画面が表示されるので、次のワークフローの定義を入力します。
main:
params: [args]
steps:
- init:
assign:
- projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- region: "us-central1"
- batchApi: "batch.googleapis.com/v1"
- batchApiUrl: ${"https://" + batchApi + "/projects/" + projectId + "/locations/" + region + "/jobs"}
- imageUri: ${region + "-docker.pkg.dev/" + projectId + "/containers/primegen-service:v1"}
- jobId: ${"job-primegen-" + string(int(sys.now()))}
- bucket: ${projectId + "-" + jobId}
- createBucket:
call: googleapis.storage.v1.buckets.insert
args:
query:
project: ${projectId}
body:
name: ${bucket}
- logCreateBucket:
call: sys.log
args:
data: ${"Created bucket " + bucket}
- logCreateBatchJob:
call: sys.log
args:
data: ${"Creating and running the batch job " + jobId}
- createAndRunBatchJob:
call: http.post
args:
url: ${batchApiUrl}
query:
job_id: ${jobId}
headers:
Content-Type: application/json
auth:
type: OAuth2
body:
taskGroups:
taskSpec:
runnables:
- container:
imageUri: ${imageUri}
environment:
variables:
BUCKET: ${bucket}
# Run 6 tasks on 2 VMs
taskCount: 6
parallelism: 2
logsPolicy:
destination: CLOUD_LOGGING
result: createAndRunBatchJobResponse
- getJob:
call: http.get
args:
url: ${batchApiUrl + "/" + jobId}
auth:
type: OAuth2
result: getJobResult
- logState:
call: sys.log
args:
data: ${"Current job state " + getJobResult.body.status.state}
- checkState:
switch:
- condition: ${getJobResult.body.status.state == "SUCCEEDED"}
next: returnResult
- condition: ${getJobResult.body.status.state == "FAILED"}
next: deleteBucket
next: sleep
- sleep:
call: sys.sleep
args:
seconds: 10
next: getJob
- deleteBucket:
call: googleapis.storage.v1.buckets.delete
args:
bucket: ${bucket}
- logDeleteBucket:
call: sys.log
args:
data: ${"Deleted bucket " + bucket}
next: failExecution
# You can delete the batch job or keep it for debugging
# - logDeleteBatchJob:
# call: sys.log
# args:
# data: ${"Deleting the batch job " + jobId}
# - deleteBatchJob:
# call: http.delete
# args:
# url: ${batchApiUrl + "/" + jobId}
# auth:
# type: OAuth2
# result: deleteBatchJob
- returnResult:
return:
jobId: ${jobId}
bucket: ${bucket}
- failExecution:
raise:
message: ${"The underlying batch job " + jobId + " failed"}
[デプロイ]をクリックします。
ワークフロー[batch-workflow]が作成されます。
5.ワークフローを実行する
先ほど作成した[batch-workflow]を選択すると、詳細が表示されます。[実行]クリックします。
ワークフローの実行画面が表示されるので、[実行]をクリックします。
成功すると以下のような画面が表示されます。

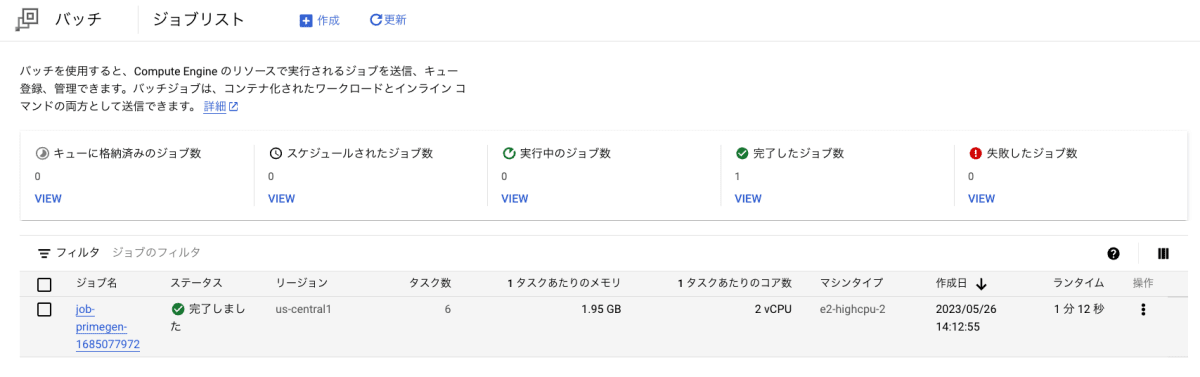
Google Cloud コンソールの [バッチ] ページに移動すると以下のような画面が表示され、ジョブが成功していることが確認できます。
今回のジョブでは6つのタスクが並列処理されていたことが確認できます。
6.結果を確認する
それでは結果を確認します。
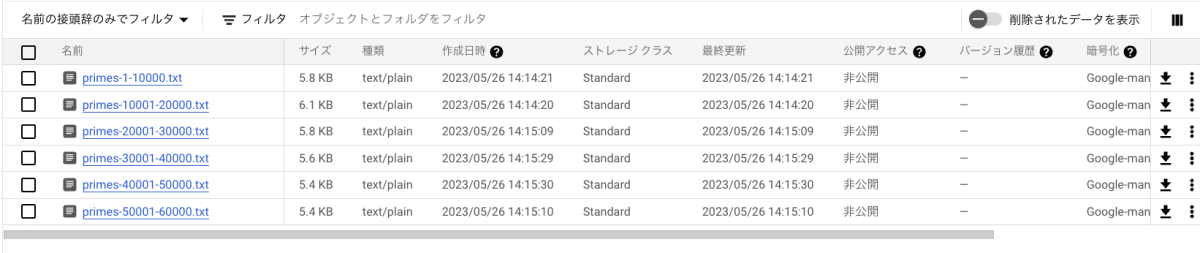
Google Cloud コンソールの [Cloud Storage] ページに移動します。
10000ごとに区切られたファイルが、6つあることが確認できます。
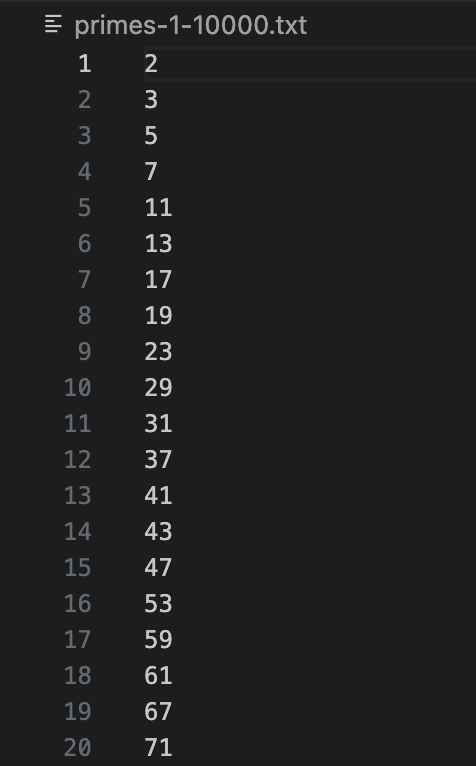
中身を確認すると構築通り、素数だけが書き込まれています。
まとめ
大規模なバッチ処理を構築する際に、自身でリソースの管理を行う場合、必要なリソースの予測や、場合に応じたスケールアップを行う必要があります。予測を見誤ると、実行時間が長くなったり、過剰なリソースの確保をしてしまう可能性があります。
今回の検証では Batch でバッチ処理を構築すると、規模に応じた リソースのプロビジョニングを行ってくれるため、自身はリソースの管理を気にする必要がないことが便利でした!
さらに大規模なバッチ処理を行う場合でも、自動的にリソースのプロビジョニングを行い、MIG の並列化を行うため処理時間は早くなりますが、その分料金は上がるので注意が必要です!
今回は日本のリージョンで使用可能になった Batch について紹介しました。
Batch は、大規模なバッチ処理をしたいときに自動でリソースの管理を行ってくれる便利なプロダクトです。 また Workflows や Cloud Scheduler とも組み合わせることができるためさまざまなユースケースにも対応が可能です。
比較的新しいプロダクトですので、さらなる進化に期待しましょう!
Discussion