BigQuery ML を触ってみる
はじめに
こんにちは、クラウドエース データ ML ディビジョン所属の川人です。
クラウドエースの IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータ ML ディビジョンです。
以前はオンライン広告配信事業を行う会社でデータサイエンティストとして働いており、クラウドエースには今年 10 月 1 日から中途で入社しました。
前職から開発は Google Cloud(旧 Google Cloud Platform、以下「GCP」)上で行っていましたが、広告配信のモデルはローカルで学習したものを ONNX 形式に変換し、 Go 言語で書かれたバックエンドに載せるという方法を取っていました。
ただ、BigQuery ML を使用すると、学習から推論まで Google SQL クエリを使用して実装できるみたいなので、実際の業務をイメージして動かしつつ BigQuery ML のメリット・デメリットについてまとめていきたいと思います。
BigQuery ML とは
詳細については公式ドキュメントを参照してください。ここではその中からいくつかの特徴を簡単にまとめておきます。
特徴
- ML フレームワークに対するプログラミング知識を要しないメンバーでも、SQL のスキルさえあれば ML モデルを構築し、評価できる
- BigQuery をデータウェアハウスとして使用している場合、 データを BigQuery からエクスポートする必要がなくなるので、開発スピードを向上させることができる
サポートされているモデル
BigQuery ML のモデルは作成される場所によって「内部(BigQuery ML)でトレーニングされたモデル」、「外部(Vertex AI)でトレーニングされたモデル」、「リモートモデル」、「インポートされたモデル」の 4 種類に分類されており、それぞれ以下のモデルをサポートしています(2023 年 10 月現在)。
内部(BigQuery ML)でトレーニングされたモデル
外部(Vertex AI)でトレーニングされたモデル
リモートモデル
Vertex AI endpoint または remote_service_type のような API を BigQuery から呼び出して使用するようなモデル(公式ドキュメント)
- Vertex AI endpoint
- remote_service_type
- A Vertex AI large language foundation model
- Cloud Natural Language API
- Cloud Translation API
- Cloud Vision API
インポートされたモデル
他の機械学習フレームワークによって学習され、出力されたモデル
実践
それでは、実際に BigQuery ML でモデルを作っていきます。
今回は kaggle の Display Advertising Challenge というコンペで実際に使用されたデータを用いて、ロジスティック回帰のモデルを作成し、そのモデルによって予測された結果を kaggle に提出するところまでやってみようと思います。
データの準備
データはこちらの Kaggle Display Advertising Dataset のリンクからダウンロードできます(2023 年 10 月現在)。
ファイルがダウンロードできたら解凍し、Cloud Storage にアップロードします。
# データの解凍
mkdir kaggle-display-advertising-challenge-dataset
tar -zxvf kaggle-display-advertising-challenge-dataset.tar.gz \
-C kaggle-display-advertising-challenge-dataset
# kaggle への submission 用にテストデータに ID を振る
nl -v60000000 -w1 kaggle-display-advertising-challenge-dataset/test.txt \
> kaggle-display-advertising-challenge-dataset/tmp.txt \
&& mv kaggle-display-advertising-challenge-dataset/tmp.txt \
kaggle-display-advertising-challenge-dataset/test.txt
# バケットの作成
gcloud storage buckets create \
gs://<your-bucket> \
--default-storage-class=standard \
--location=asia-northeast1 \
--uniform-bucket-level-access
# 解凍したデータの移動
gcloud storage cp -r \
kaggle-display-advertising-challenge-dataset \
gs://<your-bucket>
Cloud Storage にデータが移動できたら、それを BigQuery のテーブルとして読み込みます。
ちなみに、タブ区切りのデータは --field_delimiter="\t" を指定することで読み込むことが可能です。
また、今回はschema はとくに指定せず --autodetect を用いています。
# データセットの作成
bq --location=asia-northeast1 mk -d kaggle_display_advertising_challenge_dataset
# テーブルの作成
## train
bq --location=asia-northeast1 load \
--autodetect \
--source_format CSV \
--field_delimiter="\t" \
kaggle_display_advertising_challenge_dataset.train \
gs://<your-bucket>/kaggle-display-advertising-challenge-dataset/train.txt
## test
bq --location=asia-northeast1 load \
--autodetect \
--source_format CSV \
--field_delimiter="\t" \
kaggle_display_advertising_challenge_dataset.test \
gs://<your-bucket>/kaggle-display-advertising-challenge-dataset/test.txt
BigQuery 上にテーブルが作成されているはずなので、確認します。
スキーマの確認
プレビューの確認
無事、BigQuery 上にテーブルが作成されていることを確認できました。
学習データでは int64_field_0 が目的変数の列で、それ以外の int64_field_n と string_field_n が説明変数の列になります。
データの前処理
データの前処理は、SQL のクエリを実行してデータを加工したり、各種プログラミング言語のライブラリの機能を用いて行うのが一般的です。しかしBigQuery ML では、実行モデル作成の際にオプションを選択するだけで one-hot encoding や標準化などの前処理を簡単に実行することが可能です。
BigQuery ML による前処理は自動前処理と手動前処理があります。今回は高い精度を出すことよりもモデルを動かしてみることが目的なので前処理は全て自動でやってしまいたいですが、いくつか必要な前処理を行います。
まずは学習データの前処理です。
/* 学習データを前処理し、ビューを作成 */
CREATE OR REPLACE VIEW
`kaggle_display_advertising_challenge_dataset.preprocessed_train` AS
SELECT
int64_field_0 AS label
, int64_field_1
, ... // 2 ~ 12 長くなるので省略
, int64_field_13
, CAST(ML.HASH_BUCKETIZE(string_field_14, 10000) AS STRING) AS string_field_14
, ... // 15 ~ 38 長くなるので省略
, CAST(ML.HASH_BUCKETIZE(string_field_39, 10000) AS STRING) AS string_field_39
FROM
`kaggle_display_advertising_challenge_dataset.train`
データには int64_field_n という数値列と string_field_n というカテゴリ列があります。
int64_field_0は 目的変数の列なので、列名をlabel という名前に書き換え、その他の数値列はモデル作成時に自動前処理を使用するため、SELECT するだけで何もしません。
一方カテゴリ列は、カーディナリティの高い列があり、そのまま前処理(one-hot encoding)にかけてしまうと列数が膨大になり BigQuery ML のモデルサイズ制限に引っかってしまうため、今回は簡単に ML.HASH_BUCKETIZE() を用いてカーディナリティを下げておきます。このとき ML.HASH_BUCKETIZE() は文字列データを数値に変換しますが、後に行われる自動前処理で数値列とカテゴリ列を区別させる目的で、CAST( AS STRING) で文字列に直しておきます。

ML.HASH_BUCKETIZE() しなかった際に出るエラー
次に、テストデータの前処理です。
/* テストデータを前処理し、ビューを作成 */
CREATE OR REPLACE VIEW
`kaggle_display_advertising_challenge_dataset.preprocessed_test` AS
SELECT
int64_field_0 AS Id
, int64_field_1
, ... // 2 ~ 12 長くなるので省略
, int64_field_12
, CAST(ML.HASH_BUCKETIZE(string_field_13, 10000) AS STRING) AS string_field_13
, ... // 15 ~ 38 長くなるので省略
, CAST(ML.HASH_BUCKETIZE(string_field_38, 10000) AS STRING) AS string_field_38
FROM
`kaggle_display_advertising_challenge_dataset.test`
こちらも学習データとほぼ同じ処理ですが、int64_field_0 列には目的変数ではなく順番に割り振られた番号が入るため列名を Id と書き換えておきます。
モデルの作成
それではモデルを作成していきます。
モデルを作成するクエリは以下のとおりです。
CREATE OR REPLACE MODEL
`kaggle_display_advertising_challenge_dataset.ctr_predictor`
OPTIONS(
MODEL_TYPE='LOGISTIC_REG'
, CATEGORY_ENCODING_METHOD='ONE_HOT_ENCODING'
, INPUT_LABEL_COLS=['label']
) AS
SELECT
*
FROM
`kaggle_display_advertising_challenge_dataset.preprocessed_train`
CREATE OR REPLACE MODEL 構文を使えばモデルが作成できます。
OPTIONS で、各種パラメータを定義できます。
MODEL_TYPE でモデルの種類で、今回は Logistic regression を選択しました。
CATEGORY_ENCODING_METHOD ではカテゴリ変数のエンコーディング手法を選べます。デフォルトでは one-hot encoding が自動的に選ばれるので今回は省略可能ですが、明示的に指定しておきます。
INPUT_LABEL_COLS では目的変数の列を指定します。
その他にも、モデルごとに OPTIONS でパラメータを細かく指定できます。使用可能なパラメータは公式ドキュメントを参照してください。
クエリを実行し学習が完了すると、モデルが作成され、モデルの詳細が見られるようになっています。
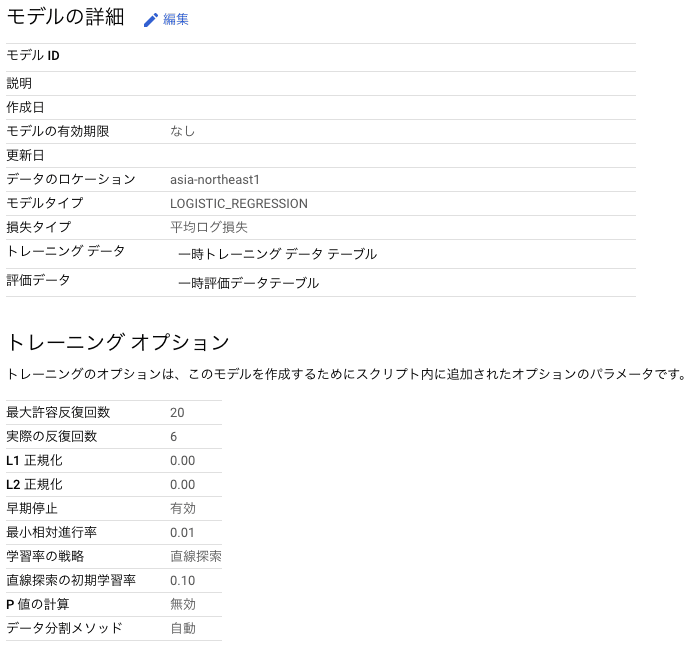
モデルの詳細
各種指標も確認できます。
モデルのパラメータと指標が一緒に保存されるので、実験管理しやすそうです。
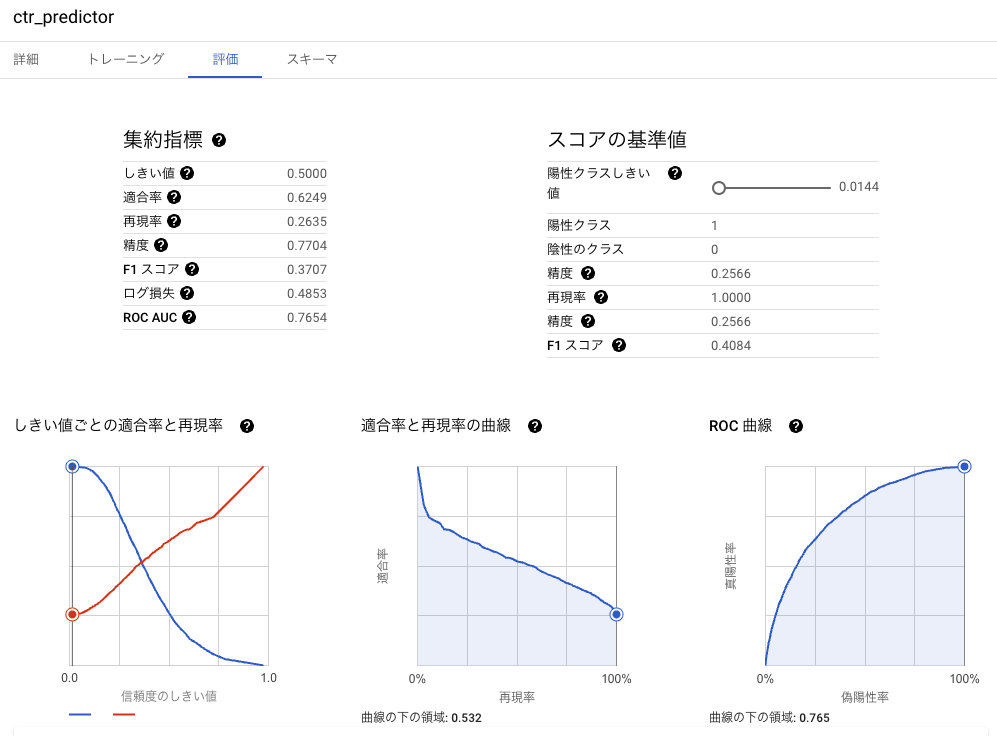
指標の確認
予測
モデルが作成できたので、テストデータに対して予測をしていきます。
今回のテストデータには正解ラベルがないので、kaggle の Display Advertising Challenge コンペ用の形式に出力して、そのまま kaggle に Submission してみましょう。
予測を行うクエリは以下のとおりです。
SELECT
Id
, (
SELECT
probs.prob
FROM
UNNEST(predicted_label_probs) AS probs
WHERE
probs.label=1
) AS Predicted
FROM
ML.PREDICT(
MODEL `kaggle_display_advertising_challenge_dataset.ctr_predictor`
, TABLE `kaggle_display_advertising_challenge_dataset.preprocessed_test`
)
ORDER BY
Id
作成したモデルを指定して ML.PREDICT を使用すると、予測値が出力されます。
今回は ID と label=1 の確率である Predicted のみ必要なので、SELECT 句の中でその部分だけを指定して出力しています。

予測結果
あとはこの結果をエクスポートし、kaggle に submission すれば完了です!
kaggle に予測結果を提出
スコアも確認してみましょう!
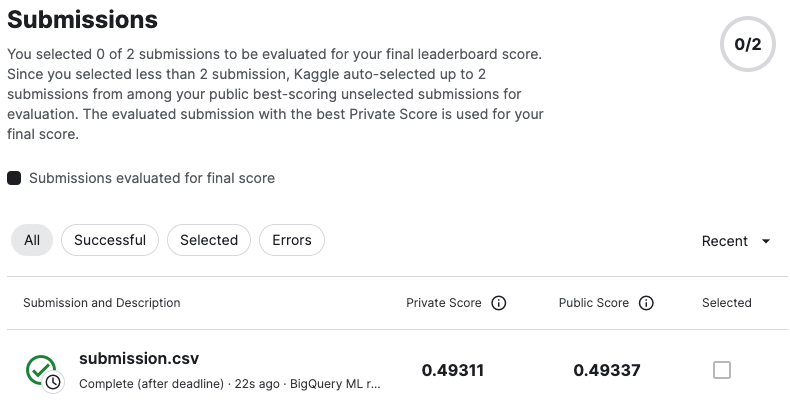
スコアの確認
まとめ
さいごに、BigQuery ML を使ってみて感じたメリットとデメリットについてまとめておきます。
あくまで 2023 年 10 月時点における個人の感想ですが、これから BigQuery ML を触ってみようと思っている方の参考になれば幸いです!
メリット
- 全て BigQuery(GCP) 上で完結するので、機械学習フレームワークの知識の習得や環境構築の作業が必要ない
- よく使う前処理はほとんど用意されていて、何も指定しなければデータの型にあったものを自動的に行ってくれる
- 学習パラメータや評価データに対する精度がモデルに紐づけられて保存される
デメリット
- 凝った前処理のオプションは用意されていない
- SQL で自力で実装するか、別の方法(Python とか)で前処理するしかない
- 使用料金がかかる
Discussion