Vertex AI の LLM 自動評価ツール AutoSxS(automatic side-by-side) 使ってみた!



1. はじめに
こんにちは、クラウドエース データソリューション部所属の泉澤です。
クラウドエースの IT エンジニアリングを担うシステム統括部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータソリューション部です。
データソリューション部では活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回紹介するリリースは、Vertex AI に AutoSxS (automatic side-by-side) という 大規模言語モデル (LLM: Large Lanuage Model) の自動評価ツールが追加された、という内容のものです。
このリリースは 2024/01/08 にありました。
本記事では AutoSxS の概要と使いかたを紹介したいと思います。
2. AutoSxS とは
2.1. 概要
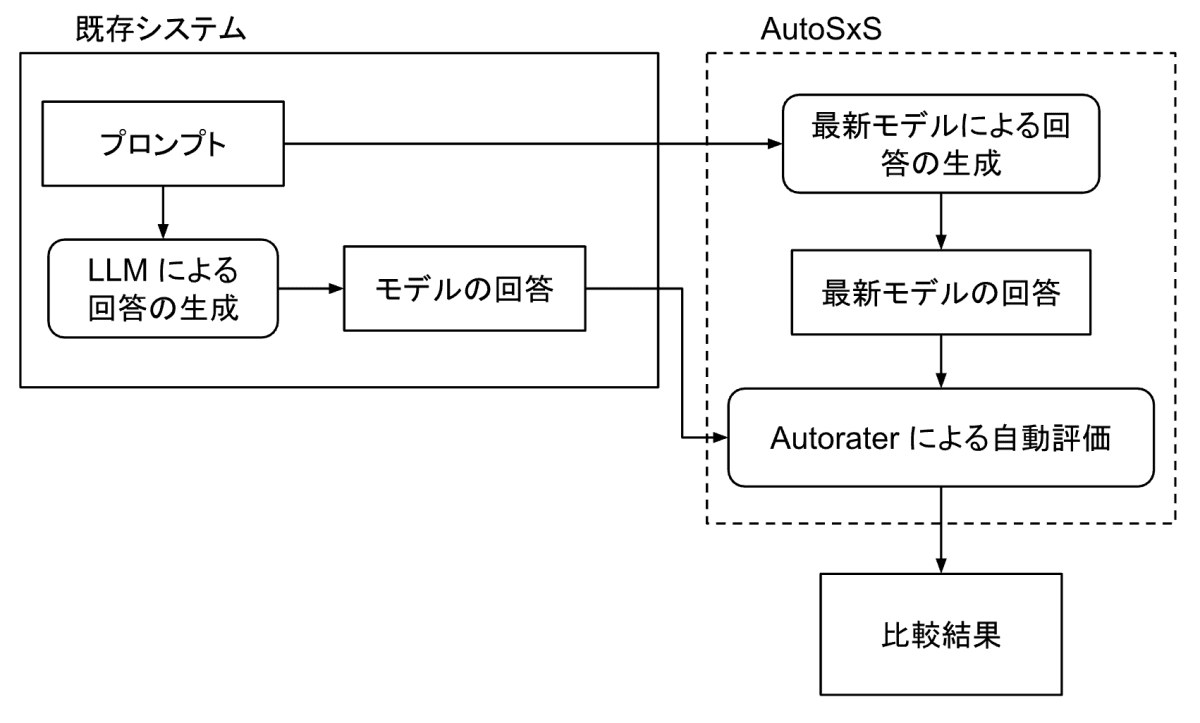
AutoSxS は、2 つの LLM の回答を並べて比較するモデル評価支援ツールです。AutoSxS は Autorater と呼ばれる第三のモデル(おそらく LLM)を使用して、どちらのモデルが質問やコンテキストに対してより適切な回答を提供しているかを判定します。
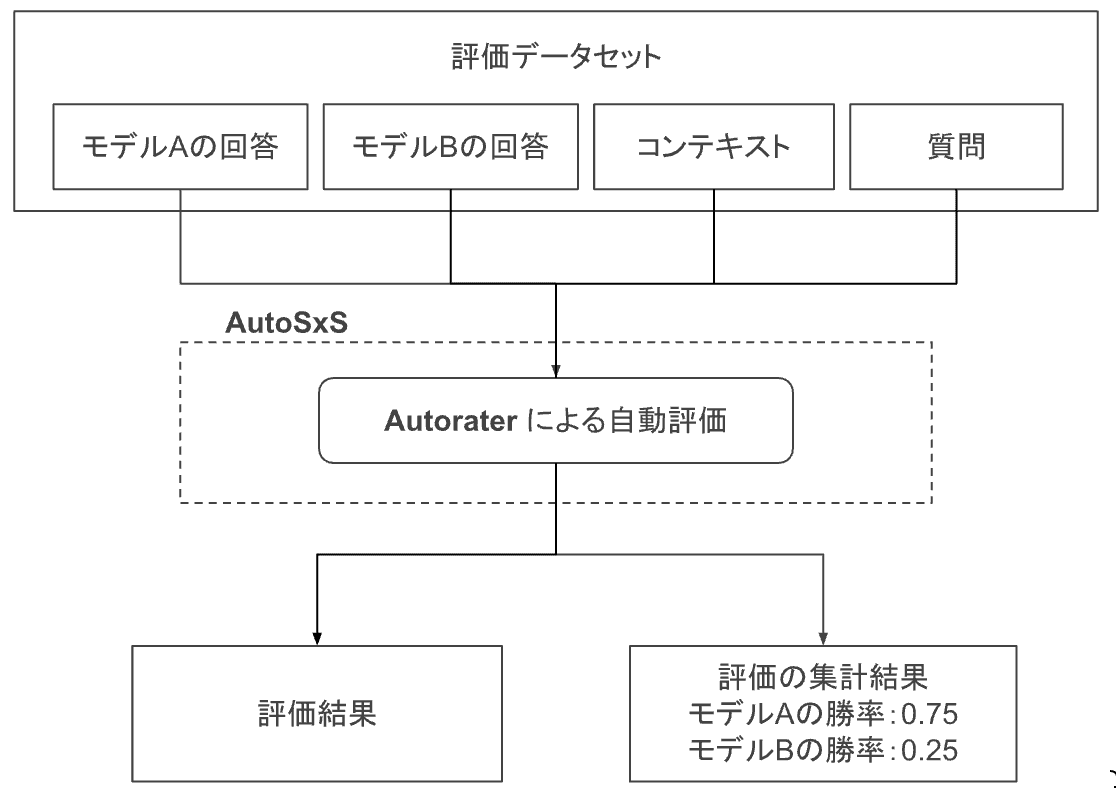
AutoSxS で行われる一連のジョブのイメージ図。点線部が AutoSxS によって自動化される箇所である。AutoSxS では BigQuery もしくは Cloud Storage からデータを取り込み、Cloud Storage に結果を出力することができる。
必ずしも回答を事前に用意する必要はなく、回答の生成から評価、結果の集計までを自動化します。
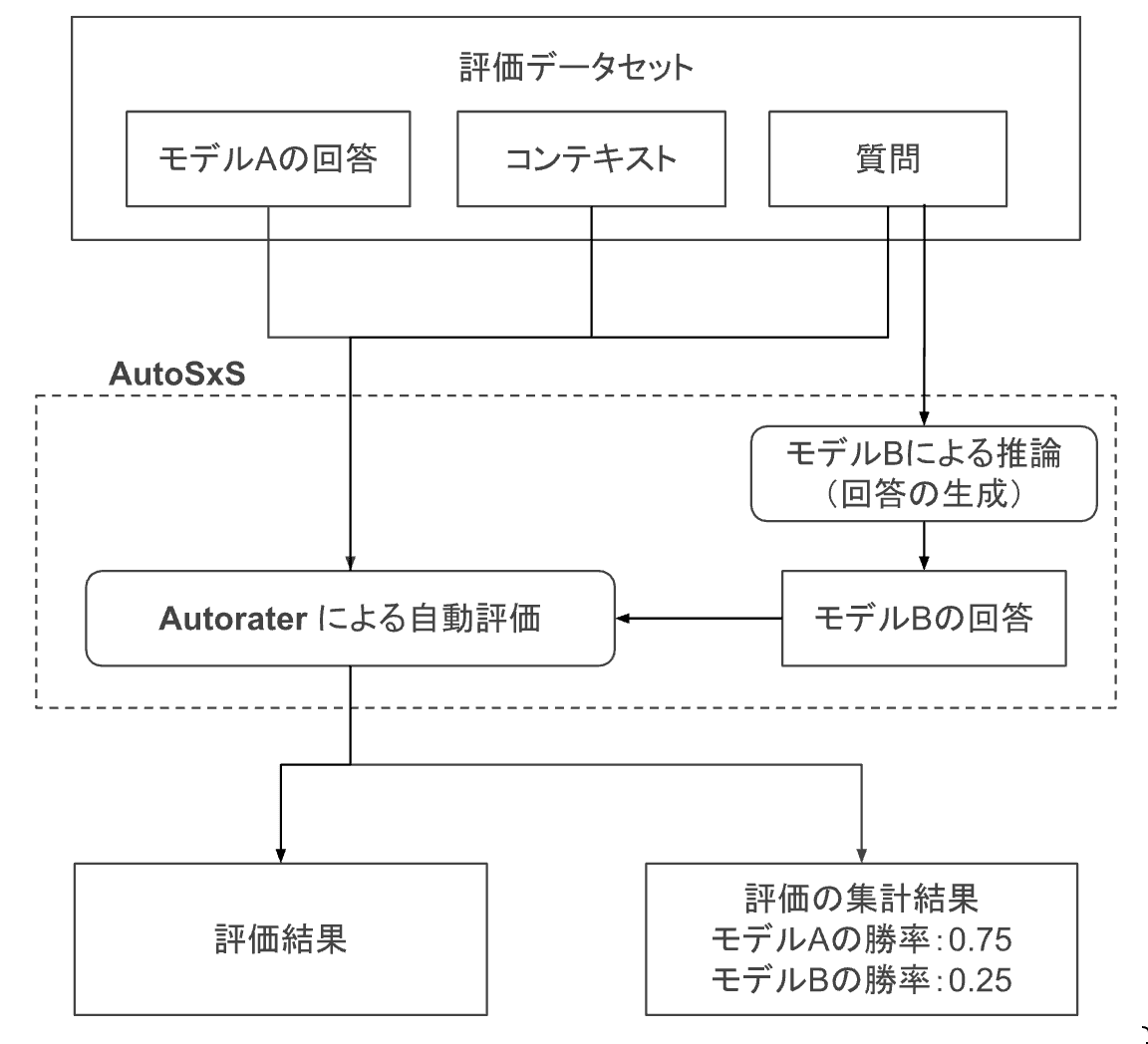
モデルBの出力を AutoSxS の一連のジョブの一つとして自動生成させた場合のイメージ図。点線部が AutoSxS によって自動化される箇所である。
2.2. 回答の入力方法と対応するモデル
先述の通り、評価対象となる LLM の回答を AutoSxS に渡す方法は2つあります。
- 事前に生成された回答を渡す
- モデルを指定し、回答を自動生成させる
回答を自動生成させる場合、指定できるモデルは Vertex AI Model Registry で管理されるモデルに限ります。Vertex AI Model Registry で管理されないモデルであっても、事前に生成された回答を渡せば良いので評価可能です。
2.3. サポートされるタスクと評価基準
AutoSxS を使用する際、評価対象となるモデルが実施したタスクの指定が必要です。指定されたタスクごとに評価基準が定められており、Autorater は基準を見てどちらの回答がより適切かを評価します。
現在、AutoSxS は Summarization タスクと Question answer タスクのモデルの評価をサポートしています。将来的にはサポートするタスクが増えることが予想されます。
評価基準は以下を参照してください。
AutoSxS の概要を掴んでいただいたところで、ここからは使用手順を説明します。
使用手順の説明後の「4. 実際に動かしてみた!」で具体的な検証を行なった時の手順を記載していますので、先にそちらを読んでいただいても構いません。
3. 使用手順
- プロンプトテンプレートを決める
- 評価データセットを準備する
- 自動評価ジョブを実行する
3.1. プロンプトテンプレートを決める
まず、各モデルに対して送る「指示書」の雛形となるプロンプトテンプレートを作成します。
AutoSxS では、評価データセットが持つデータをテンプレート内のパラメータに挿入し、モデルに渡すプロンプトを作成します。
プロンプトテンプレートが決まっていないと、評価データセットに含めるデータが決まらないため、先に決めておくのが良いと思います。
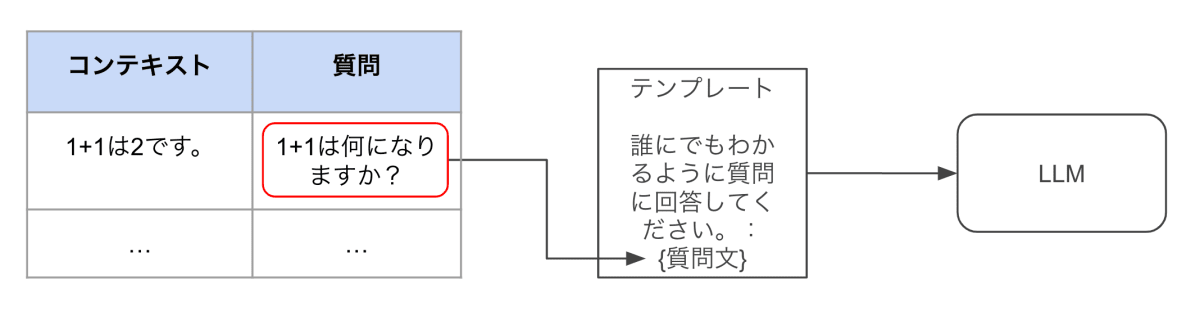
評価データセットからデータを取り出してテンプレートにデータを挿入するイメージ図
AutoSxS では Autorater に渡すプロンプトと、(事前生成された回答を渡さない場合には)評価対象のモデルに渡すプロンプトのテンプレートを事前に設定する必要があるのですが、そのプロンプトの意味合いは異なります。
Autorater に渡すプロンプトはモデルの評価を指示するものに対して、評価対象モデルに渡すプロンプトは評価したいタスクを指示するものになります。
そのため、評価対象モデルに渡すプロンプトには「行うべきタスクの指示」が含まれていれば良いのですが、Autorater に渡すプロンプトには、「評価対象のモデルが行なったタスクの説明」と「タスクを評価するために参考とするコンテキスト」が含まれている必要があります。
ここからは実例を見せながら説明したいと思います。
まず、評価対象モデルに渡すテンプレートですが、例として以下のように書けます。
# 評価対象のモデルに渡すプロンプトテンプレート
{
"prompt": {
"template": "小学生にもわかるようにわかりやすく質問に回答してください: {{ question }}"
}
}
"template"フィールドの値としてテンプレートを記載し、{{}}で囲まれたものを変数として指定できます。プロンプトとしてモデルに渡す際は、{{question}}変数に評価データセット内の同じ名前のカラム(ここではquestion)の要素が入ります。
次に Autorater に渡すテンプレートです。
# Autorater に渡すプロンプトテンプレート
{
'inference_instruction': {
'template': '小学生にもわかるようにわかりやすく質問に回答してください: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
先述の通り、Autorater に渡すプロンプトには「評価対象のモデルが行なったタスクの説明」と「タスクを評価するために参考とするコンテキスト」を含める必要があります。これをテンプレートでは inference_instruction フィールドと inference_context フィールドで指定します。 inference_instruction フィールドには、基本的に、「評価対象のモデルに渡すプロンプトテンプレート」と同じものを入れておくのが良いと思います。 inference_context フィールドについては、inference_instructionと同じようにtemplateを使ってテンプレートとして記述することもできますが、上記のように単に列を指定することもできます。この場合、'context'に評価データセット内のcontextカラムの要素が挿入され、モデルに渡されます。
より凝ったプロンプトやプロンプトテンプレートを設計する際はこちら や各所ブログ記事で学ぶと良いと思います。
3.2. 評価データセットの準備する
続いて、評価対象となるデータセットを用意します。
データセットは BigQuery テーブル、もしくは JSONL として Cloud Storage から入力することができます。
必要なデータが揃っていれば、スキーマに指定はありません。
評価データセットの各行は 1 つのタスクを表し、各カラムは次のいずれかに該当します。
- 各行を識別するための ID(必須)
各行を区別するために用意します。
値がユニークであれば、他のカラムの値を流用しても良いのですが、素直に通番を振るのが良いと思います。
例)
id: 1, 2, 3, …
- プロンプトテンプレートに入力するデータ(必須)
「3.1. プロンプトテンプレートを決める」で説明したプロンプトテンプレートに代入するテキストを用意します。先ほどのプロンプトテンプレートの例ですと、question カラムとcontext カラムを用意し、それぞれに適切なテキストが入れば OK です。
例)
question: "1 + 1 を計算すると何になりますか。"
context: "1 + 1 は 2 です。"
- 事前生成された回答(自動生成でない場合必須)
評価対象のモデルが生成した回答です。AutoSxS で自動生成させる場合、自分で用意する必要はありません。
- グラウンドトゥルース(任意)
こちらは AutoSxS のベンチマークテスト(定量的な処理性能の評価)を実施したいときに使用します。具体的には、評価者(人間)がより優れていると判断した回答を生成したモデルを"A"または"B"として表記します。このグラウンドトゥルースは AutoSxS の判定と比較され、Accuracy、Precision、Recall などの精度指標の計算に使用されます(そのほか計算される指標)。
ベンチマークテストを実施しない場合、グラウンドトゥルースを用意する必要はありません。
例)
ground_truth: A
または
ground_truth: B
上記を全て含んだデータセットの例は以下のとおりです。
{
"id": "1",
"question": "1 + 1 を計算すると何になりますか。",
"context": "1 + 1 は 2 です。",
"model_a": "2",
"model_b": "0です",
"ground_truth": "A"
}
上記の "id" が「各行を識別するための ID」、"question" と "context" が「プロンプトテンプレートに入力するデータ」、"model_a" と "model_b" が「事前生成された回答」、"ground_truth" が「グラウンドトゥルース」に該当します。
公式ドキュメントにベストプラクティスが載っていたのでそちらも参照すると良いでしょう。
3.3. 自動評価ジョブを実行する
REST API または Vertex AI SDK for Python を使用してモデルを評価します。
ここでは Python でのデータセットとモデルの指定方法を記載します。
公式ドキュメントから引用したコードが下記になります。
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'human_preference_column': 'HUMAN_PREFERENCE_COLUMN',
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
置換しなければならないパラメータの説明を表にまとめました。
| パラメータ名 | 詳細 |
|---|---|
| EVALUATION_DATASET(必須) | 評価データセットへのパス(BigQuery テーブルまたは JSONL 持つ Cloud Storage)。 例: 'gs://ca-izumisawa-test-autosxs/autosxs_dataset.jsonl' |
| ID_COLUMNS(必須) | 識別のための ID を含む評価データセットのカラム。複数列指定することも可能。 例: ['id'] や ['question', 'context'] |
| TASK(必須) | Summarization タスクもしくは Question answer タスクを指定する。 例: 'question_answer@001'もしくは'summarization@001' |
| AUTORATER_PROMPT_PARAMETERS(必須) | Autorater に渡すプロンプトのテンプレート。 例: {'inference_instruction': {'template': '小学生にもわかるようにわかりやすく質問に回答してください: {{ question }}.'}} |
| RESPONSE_COLUMN_A | 事前生成されたモデルAの回答を含む評価データセットのカラム。モデルAの回答を自動生成させる場合は不要。 例: 'model_a_response' |
| RESPONSE_COLUMN_B | 事前生成されたモデルBの回答を含む評価データセットのカラム。モデルBの回答を自動生成させる場合は不要。 例: 'model_b_response' |
| MODEL_A | 評価対象となるモデルA。事前生成された回答を指定する場合は不要。 公開モデルを指定する場合: 'publishers/<PUBLISHER>/models/<MODEL>'(例: 'publishers/google/models/text-bison') チューニングされたモデルなど、Model Registry 管理のモデルを指定する場合: 'projects/<PROJECT_NUMBER>/locations/<LOCATION>/models/<MODEL@VERSION> |
| MODEL_A_PROMPT_PARAMETERS | モデルAに渡すプロンプトテンプレート。事前生成された回答を指定する場合は不要。 例: {"prompt": {"template": "小学生にもわかるようにわかりやすく質問に回答してください: {{ question }}"}} |
| MODEL_B | 評価対象となるモデルB。事前生成された回答を指定する場合は不要。 公開モデルを指定する場合: 'publishers/<PUBLISHER>/models/<MODEL>'(例: 'publishers/google/models/text-bison') チューニングされたモデルなど、Model Registry 管理のモデルを指定する場合: 'projects/<PROJECT_NUMBER>/locations/<LOCATION>/models/<MODEL@VERSION> |
| MODEL_B_PROMPT_PARAMETERS | モデルBに渡すプロンプトテンプレート。事前生成された回答を指定する場合は不要。 例: {"prompt": {"template": "小学生にもわかるようにわかりやすく質問に回答してください: {{ question }}"}} |
| HUMAN_PREFERENCE_COLUMN | グラウンドトゥルースを含む評価データセットのカラム。ベンチマークテストを実施する際は必要だが、そうでない場合不要。 例: 'human_preference_column' |
| PROJECT_ID(必須) | AutoSxS を実行するプロジェクトの ID。 例: 'project_id' |
| LOCATION(必須) | AutoSxS を実行するリージョン。現状、他のリージョンはサポートされていない。 例: us-central1 |
| OUTPUT_DIR(必須) | 成果物をアウトプットするバケット。 例: 'test-bucket' |
| PIPELINEJOB_DISPLAYNAME(必須) | ジョブの表示名。 例: 'autosxs_test' |
上の表に習ってパラメータを指定し、Python コードを実行すれば自動評価ジョブが実行されます。
4. 実際に動かしてみた!
実際にデータを用意して AutoSxS を使用してみました!
今回は最近リブランドされた Gemini に評価データセットを用意してもらい、それを Cloud Storage に保存し、自動評価ジョブを実行しました。評価対象モデルのタスクは Question answer タスクを選択しました。
評価対象とするモデル(text-bison@001、text-bison@002)の回答の生成は AutoSxS 側に任せることにしました。
検証手順
- プロンプトテンプレートを決める
- 評価データセットを準備する
- 自動評価ジョブを実行する
- 評価結果を確認する
4.1. プロンプトテンプレートを決める
3 章にも登場しましたが、プロンプトテンプレートは以下のように決めました。
# Autorater に渡すプロンプトテンプレート
{
'inference_instruction': {
'template': '小学生にもわかるようにわかりやすく質問に回答してください: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
# 評価対象のモデルに渡すプロンプトテンプレート
{
"prompt": {
"template": "小学生にもわかるようにわかりやすく質問に回答してください: {{ question }}"
}
}
4.2. 評価データセットを準備する
今回は、両モデルとも自動生成で、ベンチマークテストも実施しないため、自分で用意するデータは以下になります。
- 識別のための ID
- プロンプトテンプレートに入力するデータ
- questiion
- context
Gemini によしなに生成してもらった結果が以下です。
(内容はあまり確認していないのでおかしなコンテキストがあっても気にしないでください。)
{"id": "1", "question": "水に溶かした食塩水は、加熱するとどのように変化しますか?", "context": "水は加熱すると蒸発しますが、食塩は蒸発しません。そのため、水蒸気がなくなるにつれて、食塩水の濃度が濃くなります。具体的には、加熱時間の経過とともに食塩水の濃度がどのように変化するか、沸騰点の変化についても説明します。また、食塩水の濃度を測定する方法や、濃度変化に影響を与える要因についても触れます。"}
{"id": "2", "question": "太陽の光が地球に届くまでの時間は何秒くらいですか?", "context": "太陽と地球の距離は約1億5千万キロメートルです。光の速さは秒速約30万キロメートルなので、太陽から地球に光が届くには約8分20秒かかります。太陽光の性質について、可視光線や紫外線、赤外線などの種類とそれぞれの性質、地球上の生物に与える影響などを説明します。また、地球以外の惑星への光の到達時間や、太陽光のエネルギー利用についても触れます。"}
{"id": "3", "question": "植物は光合成によって、二酸化炭素と水を何に変換しますか?", "context": "光合成は、植物が太陽光エネルギーを利用して、二酸化炭素と水を酸素と糖に変換する化学反応です。光合成の式は、6CO2 + 6H2O + 光エネルギー → C6H12O6 + 6O2です。光合成に関わる器官は、葉緑体です。光合成に必要な条件は、太陽光、二酸化炭素、水、葉緑素です。光合成の仕組みや、光合成の重要性、光合成に関わる酵素や色素についても説明します。"}
{"id": "4", "question": "人体で最も長い骨は?", "context": "大腿骨は、太ももの骨で、人間の骨の中で最も長いです。大人の大腿骨は約40~50cmあります。骨の種類は、206個です。骨の役割は、体を支える、筋肉の運動を支える、血液を造る、体内の臓器を守るなどがあります。骨の構造は、骨膜、骨格、骨髄などです。骨の形成や成長、骨粗しょう症などの病気についても説明します。"}
{"id": "5", "question": "地球の重力は、月にも影響を与えています。月は地球に対してどのように回転していますか?", "context": "月は地球に対して約27.3日で1回転し、約27.3日で地球を1周します。つまり、月は自転と公転の周期が同じであるため、常に同じ面を地球に向けています。この現象を同期回転といいます。月の満ち欠けは、月の自転と公転によって起こります。潮汐は、月の重力と太陽の重力によって起こります。月の表面の模様や、月の探査についても説明します。"}
{"id": "6", "question": "金属は、一般的にどのような性質を持っていますか?", "context": "金属は、光沢がある、電気を通しやすい、熱をよく通す、展延性がある、可塑性があるなどの性質を持っています。これらの性質を利用して、さまざまな製品に利用されています。具体的な例を挙げながら、それぞれの性質について詳しく説明しましょう。"}
{"id": "7", "question": "水は、どのように沸騰しますか?", "context": "水は、加熱すると沸騰します。沸騰点とは、液体の蒸気圧が液体の飽和蒸気圧と等しくなる温度です。水の沸騰点は、1気圧下では100℃です。沸騰すると、液体は気体になり、泡が発生します。沸騰の仕組みや、沸騰点に影響を与える要因、沸騰を利用した調理方法などを説明しましょう。"}
これを Cloud Storage にアップロードします。
自動評価用のバケットを作成し、ファイルにアップロードします。
このバケットは自動評価ジョブの中間データや最終結果を保存するのにも使います。
gsutil mb gs://<プロジェクト ID>-autosxs
gsutil cp <ローカルファイル名> gs://<プロジェクト ID>-autosxs/dataset.jsonl
4.3. 自動評価ジョブを実行する
Python コードを書き直して自動評価ジョブを実行します。
以下が実行したコードになります。
import os
from google.cloud import aiplatform
autorater_prompt_parameters = {
'inference_instruction': {
'template': '小学生にもわかるようにわかりやすく質問に回答してください: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
model_prompt_parameters = {
"prompt": {
"template": "小学生にもわかるようにわかりやすく質問に回答してください: {{ question }}"
}
}
parameters = {
'evaluation_dataset': 'gs://<プロジェクト ID>-autosxs/autosxs_dataset.jsonl',
'id_columns': ['id'],
'task': 'question_answer@001',
'autorater_prompt_parameters': autorater_prompt_parameters,
'model_a': 'publishers/google/models/text-bison@001',
'model_a_prompt_parameters': model_prompt_parameters,
'model_b': 'publishers/google/models/text-bison@002',
'model_b_prompt_parameters': model_prompt_parameters
}
aiplatform.init(project='<プロジェクト ID>', location='us-central1', staging_bucket='gs://<プロジェクト ID>-autosxs')
aiplatform.PipelineJob(
display_name='autosxs_doc',
pipeline_root=os.path.join('gs://<プロジェクト ID>-autosxs', 'autosxs_doc'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
Python スクリプトを実行します。
python3 autosxs.py
以下のように表示されたら自動評価ジョブは成功です!

コンソールの Vertex AI > パイプライン からも実行されたジョブのワークフローを確認することができます。
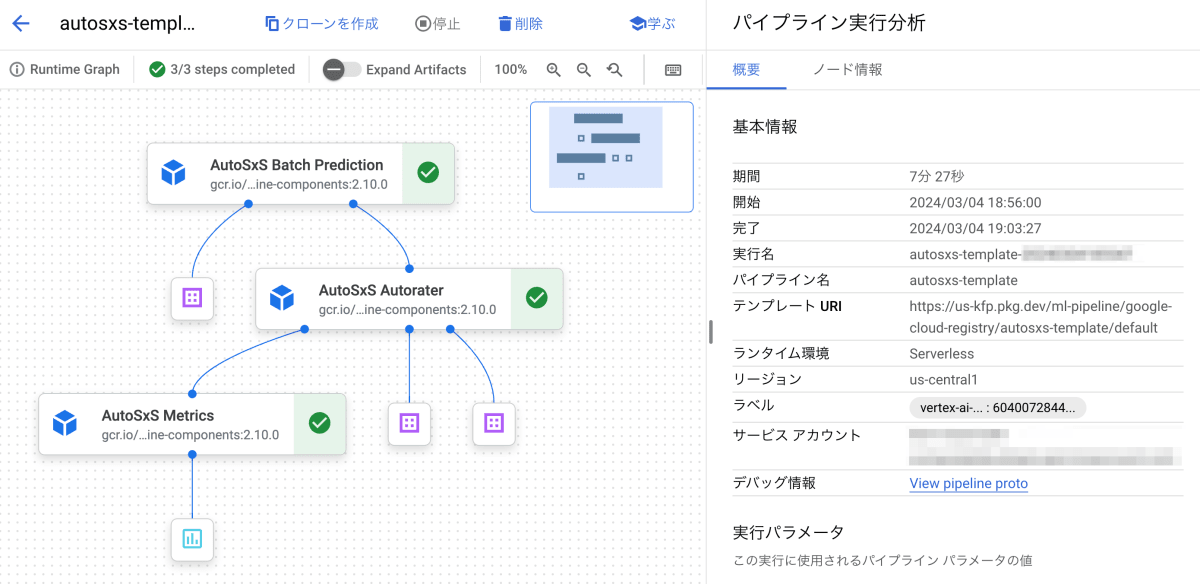
4.4. 評価結果を確認する
自動評価ジョブの成果物は Cloud Storage に保存されます。
色々とファイルが作成されていると思いますが、見るべきファイルは judgments.jsonl と executor_output.json です。
プレビュー機能なので結果の表示は控えますが、各ファイルには次の項目が記載されています。
judgments.jsonl には評価データセットの各レコードごとに、自動評価者が下した判定や判定の理由が記載されています。
フィールドは次のようになっています。
- id
- inference_context(タスクの説明)
- response_a(モデル A の回答)
- response_b(モデル B の回答)
- choice(判定)
- explanation(判定の理由)
- confidence(判定の確信度)
executor_output.json には、judgments.jsonl に記載された判定の各モデルの勝率が記載されています。
- AutoRater model A win rate
- AutoRater model B win rate
公式ドキュメントに言語の制限が書かれていなかったため、日本語で検証しましたが、きちんと評価が実施できているように見えました!
今回は Python でジョブを実行しましたが、Vertex AI Pipelines から UI でテンプレートを指定し、実行することもできそうだったため、気になる人は試してみていただけたらと思います。
5. ユースケース
最後にユースケースを紹介します。
LLM を組み込んだシステム導入前において、LLM の比較に使用するのはいうまでもなく、導入後に新モデルがリリース時にモデルの入れ替え検討にも便利ではないかと思いました。
5. まとめ
本記事では LLM の自動評価ツールである AutoSxS の紹介をしました。
現在は Summarization タスクと Question answer タスクの 2 つのみですが、今後タスクが増えていくことが予想されます。
各組織から新しい LLM が次々と公開されていますが、LLM の評価にお困りの方がいましたら使用を検討してみてください!
6. 参考
Discussion