Devin の良い感じの使い方を模索する:草創編
こんにちは。クラウドエースの三原です。
運よく話題の Devin に触る機会があったので、備忘録もかねて整理したいと思います。
(公式ドキュメントから読み解ける内容以上のものは無いので公開の意義に悩みましたが、アウトプットの練習も兼ねて...)
この記事の目的
Devin の生成する成果物の品質やパフォーマンスを上げるための施策を考えます。
Devin is 何
Devin は生成 AI を活用して以下のような事が可能です。
・自律的なコードの修正
・ユニットテストコードの実行
・Git ホスティングサービスとの統合 (GitHub であれば Issue の切り出しや Pull Request 等が可能です)
開発プロセスをトータルにサポートしてくれる SaaS サービスです。
例えば以下は「特定のコンポーネントファイル内の関数の責務を分離したい」というタスクを与えたスクショですが、コードの修正後に静的解析チェックやプロジェクトのユニットテストが全てパスした事を確認した後に、Pull Request を出してくれています。

Devin はタスクをこなす上で仮想マシンの中でプロセスを遂行しますが、ワークスペースからどのような道筋でタスクをこなしているのか詳細を確認が可能です。

シェルコマンドの履歴を確認したり、

Devin が書いたソースコードを仮想マシンの中にインストールされた VSCode で直接閲覧、編集することも可能です。

タスクはセッションという概念で非同期的に遂行され、並列に依頼することが可能です。
朝の始業時に並列で Devin に開発タスクを与え、昼頃に Devin が提出した Pull Request をレビューするといった開発体験が可能です。
私個人の所感として、Cursor を始めとした生成 AI を活用した開発体験自体は浸透しつつある印象はありますが、開発者というコントローラー無しに自律的に開発タスクをこなすのは過去に例を見ない点で、今後の開発プロセスにおけるエポックメイキングに成り得るサービスのような気がします。
ただし、Devin は発展途上で良いパフォーマンスを得るためには指示に工夫が必要であることが公式に強調されており、野放図に利用しても上手く成果を得られない可能性があります。公式ドキュメントでは Devin を ジュニアエンジニア として扱い、TODO が明瞭で小さなタスクを与えることを推奨しております。そして Devin がタスクを遂行する中で作業時間が経過する程に性能は劣化していくため、大きいタスクは不向きであると説明されています。完成物の具体的なイメージを持ってプロンプトを与える必要がある点で、他の生成AIサービスとは異なる手触りであると言えます。
前置きが長くなりましたが、この記事の狙いとして Devin に如何にして上手に働いてもらうか、という命題に対しての基本的な考え方をまとめたい、というものになります。
課金体系と単位について
Devin を利用するにあたり、価格プランとして以下の2つが提供されています。
・Team
・Enterprise
Team プランでは月額$500から、Enterprise では価格が明示されていない点から、現状、一個人での契約は難しいと言えます。
本記事では料金が明示されている Team プランを前提に説明します。
まず Devin の料金はセッションの作業時間に相当する ACU という課金単位をベースに算出されます。(作業時間15分=1 ACU)
チーム向けのプランであれば月毎に250 ACU を与えられ、ACU が枯渇して継続利用した場合に1 ACU あたり2ドルの従量課金が発生します。
上述したように単一のセッションの中で ACU を消化する程、性能が劣化していくので、(公式には単一のセッションあたり、10 ACU(2.5時間)単位を超過しないようにタスクを与えることを推奨しています。)単一のセッションで大きな依頼を与えるよりは、低 ACU でおさまるようにセッションを分割するのが基本的な運用になります。
実際に Devin 触ってみる
実際に Devin にアンチパターン、ベストプラクティスに沿ったプロンプトを与えて、パフォーマンスを比べてみます。
まずは Devin がタスクを遂行するにあたってのフローを説明します。
Devin のライフサイクル
Devin にタスクを依頼してセッションがスタートし、成果物を提供するまでの具体的なフローは大まかに以下のようになっています(実際にはステップが前後する場合があります)。

着目すべきはplanの作成ステップで、planは Devin がタスクを遂行する上で必要な TODO アクションを定義しています。
plan の内容と進捗状況は Planner セクションで確認できます。
以下は先の「特定のコンポーネントファイルな内の関数の責務を分離したい」タスクを与えて生成された plan です。
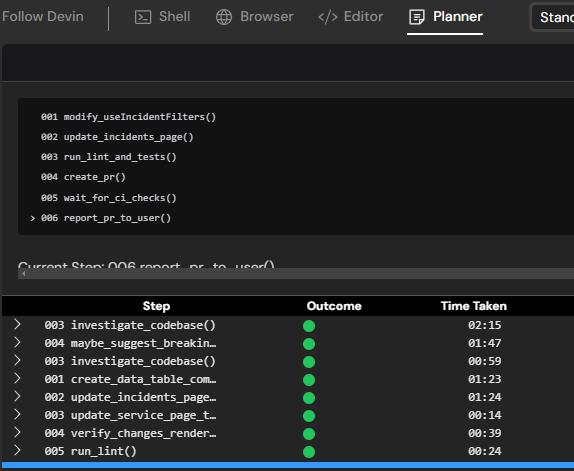
Devin は実際にこの plan に沿ってコードの修正やテストの実行等のタスクを実行していきます。
Devin のパフォーマンス観点で重要なのは Devin はタスクの状況に応じて、plan を適宜再構成する点です。
タスクに柔軟に対応できる点で良い側面とも言えますが、パフォーマンス観点では必ずしもそう言えない部分もあります。
実際にアンチパターンに相当するプロンプトを与えてみて、どのような挙動になるか見てみます。
よくないタスク指示
例えば以下のセッションでは上述の「特定のコンポーネントファイル内の関数の責務を分離したい」というタスクを与えてますが、一口に責務を分離したいといっても、どの関数をどのような観点で分離するのかを具体的な指示を与えていません。つまりは曖昧なタスクを与えてしまっている典型的なアンチパターンな指示なのですが、最初は以下のような plan を立てます。
001 clone_repos_if_needed()
002 maybe_provide_prompt_feedback_to_user()
003 investigate_codebase()
004 maybe_suggest_breaking_down_task()
005 plan_approved = suggest_plan()
006 if not plan_approved:
007 goto 002
008 execute_approved_plan()
003 の investigate_codebase() でコードを分析し、修正するべき箇所を特定しましたが

004 maybe_suggest_breaking_down_task() でユーザーに与えられたタスクを細かいサブタスクに分解するように提案しています。
これは与えられたタスクに対して調査結果から粒度が大きすぎて一度に解決するのが不可能だと判断したために発生しています。

提案されたサブタスクの一つを指示すると plan を以下のように再構成します。

001 create_data_table_component()
002 update_incidents_page_to_use_data_table()
003 update_service_page_to_use_data_table()
004 verify_changes_render_correctly()
005 run_lint()
006 run_tests()
007 create_pr()
008 report_pr_to_user()
001~004までが実際にコードの修正、005~006は lint チェックとテスト実行、007が Pull Request を作成しています。
一見すると計画を立てた上で自律的にタスクをこなしているように見えますが、サブタスクへの分解や plan の再構築そのものに ACU を無駄に消費してパフォーマンスの劣化を招き、且つ plan の実行可否に対してユーザーの判断が必要な点で Devin の自律実行できる利点が損なわれています。
いいタスク指示
では、成果物が明確で細かい粒度に分解した指示のケースを見てみます。
以下のプロンプトではアプリケーションで接続するデータベース内のテーブル定義を変更するタスクを与えています。
具体的に ItemMemo というテーブルを追加して、項目と型まで指定しています。
また、具体的な成果物である Prisma 定義ファイル、マイグレーション対象の ddl ファイルまで指定しています。
##Things you want to do
You will be given the task of changing the table definitions in the database.
Specifically, you will be asked to add a table definition called “ItemMemo”.
As table items, you will be asked to define the primary key as “id int”, “user_id” as another item, and the memo content as another item.
You will be asked to define the other items by referring to other tables.
##Assumptions
In this project, postgresql is used for the database,
and prisma is used for the ORM of the application.
The database tables are defined in prisma/schema.prisma.
As the first step of this task, you need to edit prisma/schema.prisma.
Next, you need to create migration ddl in prisma/migrations/* using the command “prisma migrate dev --create-only”.
##Deliverables
The deliverables are as follows.
1. Updated prisma/schema.prisma
2. prisma/migrations/*******/migration.sql
この場合はサブタスクが提案されることは無く PR まで一貫して自律的にタスクが遂行されます。

つまりはパフォーマンスを引き出す上では、何を以て成果物の品質を充足し得るかを明確にし、plan の実行可否を自律的に判断できる程度に Devin の認知負荷を排した上でお願いすることが肝要であると言えます。
ただ、単一のプロンプトで全てを詳らかに指示するのは中々骨が折れます。(自分でやった方が早いと判断してしまうぐらいには...)
そこで、ある程度前提のコンテクストを共通化する仕組みが提供されており、本記事では以下に関して説明します。
・ Playbook
・ Knowledge
・ Devian's Workspace
Playbook
Playbook は、共有・再利用可能なシステムプロンプトで、タスクの精度を高めるためにユーザが定義できるシステムプロンプトです。
Playbook には結果や手順、以下のようなセクション等を含めることを推奨するように公式ドキュメントに記載されています。
- Procedure: タスクの具体的な手順を記述
- Specifications: タスク完了時に満たすべき条件
- Advice: Devin へのアドバイスや注意点
- Forbidden Actions: 実行してはいけない操作等の制約事項
- Required from User: タスクを遂行するにあたり必要なユーザーから提供されているべき情報
例えば、上記のテーブル追加のタスクを「データベースのテーブル定義変更タスク」として抽象化し、Playbook に落とし込むと以下のような内容になります。
## Procedure
You will be given the task of changing the table definitions in the database.
1. **step 1**:As the first step of this task, you need to edit prisma/schema.prisma.
2. **step 2**: you need to create migration ddl in prisma/migrations/* using the command “prisma migrate dev --create-only”.
## Specification
The deliverables are as follows.
1. Updated prisma/schema.prisma
2. prisma/migrations/*******/migration.sql
## Advice & Pointers
If an operation is being performed on a table that is being modified by an application, the query within that operation also needs to be modified.
## Required from User
1. Table name to be modified
2. Item and type to be added or updated, and item length
## Forbidden actions
You do not need to run tests or static analysis when creating a plan.
タスクを遂行する手順と成果物として必要なものを具体的に定義している他、変更されているテーブルに対してアプリケーションで操作が実行されている場合、その操作のクエリも変更する必要がある旨、タスクを実行する際には静的解析やテストの実行は必要ない旨を記載しています。
セッションの開始時に当該 Playbook を指定した上でタスクの遂行に必要な最低限の情報を渡すことで、単一のプロンプトに詳細な情報を詰め込んだ場合と同じく、成果物や手順を明確化した上で自律的にタスクを遂行してくれます。

なので定型化可能な作業タスクはどんどん Playbook 化してチーム内で共有化すると諸々捗ると思います。
Knowledge
Knowledge は、Devin がタスクを遂行する上で重要なルールや技術的背景を登録できる機能です。
例えば、プロジェクトで採用しているブランチ戦略に関するルールなどは以下のようにナレッジ化してタスク遂行時に参照させることができます。

他にもコミットメッセージの規約として Conventional Commits を採用している等のルールや、インフラリソースや依存関係を勝手に追加してはならない等の制約事項も有効なように感じます。
実際に経験したこととして、Devin に「アプリケーションの特定の関数で大きいレイテンシが発生しているので原因箇所を特定して解消してほしい」という指示を与えたところ(これも Devin に想像力を要求している点でアンチパターンな指示ですが...)、Devin が出した回答は インフラに Redis を追加してキャッシュを参照させることでパフォーマンスを上げる という大胆なものでした。

油断して曖昧な指示を与えてしまうと、容赦なく実情にそぐわない回答を捻り出してくる可能性があるので制約事項は気づいたらどんどん増やすことをおすすめします。
Devian's Workspace
Devin はタスクを進行していく際に仮想マシン内で指定されたリポジトリからソースコードを取得しますが、それぞれリポジトリ単位でリポジトリを clone する時の振る舞い、依存関係の取得、静的解析、テストやローカルアプリケーションの実行手順まで任意に指定できます。
Devin の [Settings]→ [Devin's Workspace] で各リポジトリのセットアップが可能です。

例えば言語に Python を選択しているケースで、パッケージマネージャーに pip ではなく rye を利用したい場合は依存関係セクションにインストールコマンドを指定することができたり、

テスト結果を Devin に参照させる際に pytest-cov を使って各カバレッジまで詳細に取得するように指定することもできます。

タスクの達成条件として、テスト結果やローカルでの検証等を指定する場合にコンテクストとして重要になってきます。
まとめ
これまでの諸々をまとめると、Devin を活用する上で品質やパフォーマンスを上げるには、指示により多くのコンテクストを与える必要があるのはわかったと思います。その意味で Devin はプロダクト開発の、要件や仕様が固まり切っておらずドキュメンテーションや課題等が整備されていない黎明期よりは、技術要件、静的解析やテストコード等の品質チェックが確立された上で、タスクを小さく分解したり定型化可能な成熟した段階の方が上手く活用できる可能性があるように思います。また、要件を Playbook や Knowledge に落とし込む等のパフォーマンスを上げる仕組みづくりが、結果的に精緻なドキュメンテーション文化醸成を促したりする副次効果もあるようにも思います。
おわりに
Devin を利用するにあたり、個人利用向けのプランが存在しない点で導入の敷居が高いように感じますが開発プロセスに何かしらのメリットをもたらすのは間違いないように思います。
反応良さそうなら続きを書きたいと思います。それでは...!
Discussion